


inner join: select * from user a inner join grade b on a.gid = b.id; 只返回两个表中联结字段相等的行

left join:select * from user a left join grade b on a.gid = b.id; 返回包括左表中的所有记录和右表中联结字段相等的记录
左表(user)的记录将会全部表示出来,而右表(grade)只会显示符合搜索条件的记录(例子中为: a.gid = b.id).
grade表记录不足的地方均为NULL.
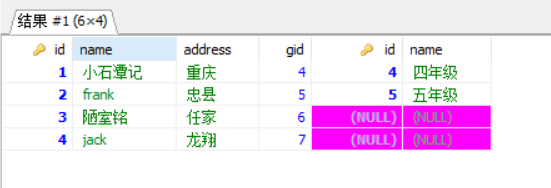
right join: select * from user a right join grade b on a.gid = b.id; 返回包括右表中的所有记录和左表中联结字段相等的记录
以右表(grade)为基础的,user表不足的地方用NULL填充.

union与union all的区别
UNION用的比较多union all是直接连接,取到得是所有值,记录可能有重复 union 是取唯一值,记录没有重复
1、UNION 的语法如下:
[SQL 语句 1]
UNION
[SQL 语句 2]
2、UNION ALL 的语法如下:
[SQL 语句 1]
UNION ALL
[SQL 语句 2]
效率:
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
1、对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
2、对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
<![CDATA []]>的用法
在使用mybatis 时我们sql是写在xml 映射文件中,如果写的sql中有一些特殊的字符的话,在解析xml文件的时候会被转义,但我们不希望他被转义,所以我们要使用<![CDATA[ ]]>来解决。
<![CDATA[ ]]> 是什么,这是XML语法。在CDATA内部的所有内容都会被解析器忽略。
如果文本包含了很多的"<"字符 <=和"&"字符——就象程序代码一样,那么最好把他们都放到CDATA部件中。
但是有个问题那就是 <if test=""> </if> <where> </where> <choose> </choose> <trim> </trim> 等这些标签都不会被解析,所以我们只把有特殊字符的语句放在 <![CDATA[ ]]> 尽量缩小 <![CDATA[ ]]> 的范围。
实例如下:
<select id="allUserInfo" parameterType="java.util.HashMap" resultMap="userInfo1">
<![CDATA[
SELECT newsEdit,newsId, newstitle FROM shoppingGuide WHERE 1=1 AND newsday > #{startTime} AND newsday <= #{endTime}
]]>
<if test="etidName!=''">
AND newsEdit=#{etidName}
</if>
</select>
因为这里有 ">" "<=" 特殊字符所以要使用 <![CDATA[ ]]> 来注释,但是有<if> 标签,所以把<if>等 放外面。