section 0 preface
用户态的heap,是由glibc实现的,内核则自力更生的,所以内核的heap差别挺大的。
从最直观的角度去看,在进行内核模块编写的时候,我们可以调用的heap相关函数,是kmalloc()以及kfree(),那么我们就从kmalloc()函数出发吧。
本文会涉及kmalloc、linux的伙伴系统,涉及大量的kernel源码阅读。
linux/ Source Tree - Woboq Code Browsercode.woboq.org/linux
section I kmalloc()
/**
* kmalloc - allocate memory
* @size: how many bytes of memory are required.
* @flags: the type of memory to allocate.
*
* kmalloc is the normal method of allocating memory
* for objects smaller than page size in the kernel.
*
* The @flags argument may be one of the GFP flags defined at
* include/linux/gfp.h and described at
* :ref:`Documentation/core-api/mm-api.rst <mm-api-gfp-flags>`
*
* The recommended usage of the @flags is described at
* :ref:`Documentation/core-api/memory-allocation.rst <memory-allocation>`
*
* Below is a brief outline of the most useful GFP flags
*
* %GFP_KERNEL
* Allocate normal kernel ram. May sleep.
*
* %GFP_NOWAIT
* Allocation will not sleep.
*
* %GFP_ATOMIC
* Allocation will not sleep. May use emergency pools.
*
* %GFP_HIGHUSER
* Allocate memory from high memory on behalf of user.
*
* Also it is possible to set different flags by OR'ing
* in one or more of the following additional @flags:
*
* %__GFP_HIGH
* This allocation has high priority and may use emergency pools.
*
* %__GFP_NOFAIL
* Indicate that this allocation is in no way allowed to fail
* (think twice before using).
*
* %__GFP_NORETRY
* If memory is not immediately available,
* then give up at once.
*
* %__GFP_NOWARN
* If allocation fails, don't issue any warnings.
*
* %__GFP_RETRY_MAYFAIL
* Try really hard to succeed the allocation but fail
* eventually.
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
#ifndef CONFIG_SLOB
unsigned int index;
#endif
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);/* 分支1:之后将会使用
__get_free_pages()来获取页
*/
#ifndef CONFIG_SLOB
index = kmalloc_index(size); //计算出相应index
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(
kmalloc_caches[kmalloc_type(flags)][index],
flags, size);
#endif
}
return __kmalloc(size, flags);
}
kmalloc()并不是真正实现内存分配的地方,在此处仅仅是进行了一些判断,并形成了3个分支:
第一个分支,是size大于KMALLOC_MAX_CACHE_SIZE就会调用kmalloc_large(size, flags)来继续完成分配,其中这个MAX的值是(1UL << (12 + 1)),即8KB。当使用kmalloc申请大于8K的内存时,会进入这个分支,个分专门用于处理大块内存(以page为粒度)的申请。这支的内容与buddy system有关:
将会经kmalloc_large()->kmalloc_order_trace()->kmalloc_order()->alloc_pages(),最终通过Buddy伙伴算法申请所需内存
第二个分支,要求“ndef CONFIG_SLOB”,这个CONFIG_SLOB是一个编译时配置的选项,我们就默认这个选项没有定义好了。在此基础上,如果没有超过MAX,那就先调用kmalloc_index(size),(很容易让人联想到用户态的heap,确实有用到类似的思想):
/*
* Figure out which kmalloc slab an allocation of a certain size
* belongs to.
* 0 = zero alloc
* 1 = 65 .. 96 bytes
* 2 = 129 .. 192 bytes
* n = 2^(n-1)+1 .. 2^n
*/
static __always_inline unsigned int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8;
if (size <= 512) return 9;
if (size <= 1024) return 10;
if (size <= 2 * 1024) return 11;
if (size <= 4 * 1024) return 12;
if (size <= 8 * 1024) return 13;
if (size <= 16 * 1024) return 14;
if (size <= 32 * 1024) return 15;
if (size <= 64 * 1024) return 16;
if (size <= 128 * 1024) return 17;
if (size <= 256 * 1024) return 18;
if (size <= 512 * 1024) return 19;
if (size <= 1024 * 1024) return 20;
if (size <= 2 * 1024 * 1024) return 21;
if (size <= 4 * 1024 * 1024) return 22;
if (size <= 8 * 1024 * 1024) return 23;
if (size <= 16 * 1024 * 1024) return 24;
if (size <= 32 * 1024 * 1024) return 25;
if (size <= 64 * 1024 * 1024) return 26;
BUG();
/* Will never be reached. Needed because the compiler may complain */
return -1;
}
之后则根据获得的index,调用:
kmem_cache_alloc_trace(kmalloc_caches[kmalloc_type(flags)][index], flags, size);
值得注意的是,这里将index作为一个二维数组kmalloc_caches的第二个序号,而第一个则是一个由flag确定的类别。类比用户态的bin,猜想这个kmalloc_caches数组,用于维护一个类似bin的池子,这个池子的分类标准除了size以外,还有一个由flag确定的类别,每一个类别中,都有不同size对应的池子,不妨瞥一眼这些池子对于flag的分类标准吧:
static __always_inline enum kmalloc_cache_type kmalloc_type(gfp_t flags)
{
#ifdef CONFIG_ZONE_DMA
/*
* The most common case is KMALLOC_NORMAL, so test for it
* with a single branch for both flags.
*/
if (likely((flags & (__GFP_DMA | __GFP_RECLAIMABLE)) == 0))
return KMALLOC_NORMAL;
/*
* At least one of the flags has to be set. If both are, __GFP_DMA
* is more important.
*/
return flags & __GFP_DMA ? KMALLOC_DMA : KMALLOC_RECLAIM;
#else
return flags & __GFP_RECLAIMABLE ? KMALLOC_RECLAIM : KMALLOC_NORMAL;
#endif
}
对于这些分类,我暂时没打算细究。进入kmem_cache_alloc_trace()之后,使用slab_alloc()分配地址。
至于第三个分支,一般只有在定义了CONFIG_SLOB时才会执行到,在此就先不细究了。
以上仅仅是宏观的看看kmalloc的实现。可以发现,针对大size的请求,最后我们会使用alloc_pages()完成请求,小size则使用slab_alloc()完成,这两个申请则对应伙伴系统和slab分配机制,我们先从大的,从开始alloc_pages()这边开始吧。
section II buddy system相关
先大致浏览一下这部分的源码:
static __always_inline void *kmalloc_large(size_t size, gfp_t flags)
{
unsigned int order = get_order(size);
return kmalloc_order_trace(size, flags, order);
}
其中,需要先计算一个order,然后再使用order去申请内存,这是一个看上去有点乱的宏定义,好在注释很清楚doge:
/**
* get_order - Determine the allocation order of a memory size
* @size: The size for which to get the order
*
* Determine the allocation order of a particular sized block of memory. This
* is on a logarithmic scale, where:
*
* 0 -> 2^0 * PAGE_SIZE and below
* 1 -> 2^1 * PAGE_SIZE to 2^0 * PAGE_SIZE + 1
* 2 -> 2^2 * PAGE_SIZE to 2^1 * PAGE_SIZE + 1
* 3 -> 2^3 * PAGE_SIZE to 2^2 * PAGE_SIZE + 1
* 4 -> 2^4 * PAGE_SIZE to 2^3 * PAGE_SIZE + 1
* ...
*
* The order returned is used to find the smallest allocation granule required
* to hold an object of the specified size.
*
* The result is undefined if the size is 0.
*
* This function may be used to initialise variables with compile time
* evaluations of constants.
*/
#define get_order(n) \
( \
__builtin_constant_p(n) ? ( \
((n) == 0UL) ? BITS_PER_LONG - PAGE_SHIFT : \
(((n) < (1UL << PAGE_SHIFT)) ? 0 : \
ilog2((n) - 1) - PAGE_SHIFT + 1) \
) : \
__get_order(n) \
)
继续深入,其主干在于kmalloc_order():
void *kmalloc_order_trace(size_t size, gfp_t flags, unsigned int order)
{
void *ret = kmalloc_order(size, flags, order);
trace_kmalloc(_RET_IP_, ret, size, PAGE_SIZE << order, flags);
return ret;
}
终于找到了这个大块内存分配的重要函数,alloc_pages():
void *kmalloc_order(size_t size, gfp_t flags, unsigned int order)
{
void *ret;
struct page *page;
flags |= __GFP_COMP;
page = alloc_pages(flags, order);
ret = page ? page_address(page) : NULL;
ret = kasan_kmalloc_large(ret, size, flags);
/* As ret might get tagged, call kmemleak hook after KASAN. */
kmemleak_alloc(ret, size, 1, flags);
return ret;
}
alloc_pages()再往里面的代码不全贴出来了,实在是太多了...
alloc_pages()的分配的实现,靠的是__alloc_pages_nodemask(gfp_mask, order, preferred_nid, NULL);
该函数的分配实现,又靠的是page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
再进一步,靠的是page = rmqueue(ac->preferred_zoneref->zone, zone, order, gfp_mask, alloc_flags, ac->migratetype);
终于,在这个rmqueue()函数,我可以看出一些buddy system的逻辑了:
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
if (likely(order == 0)) { //Use pcplists for order-0 allocations.
page = rmqueue_pcplist(preferred_zone, zone, order,
gfp_flags, migratetype, alloc_flags);
goto out;
}
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);//偷取机制
} while (page && check_new_pages(page, order));//一页一页检查,看是不是有了足够个连续的page
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order);
zone_statistics(preferred_zone, zone); //更新zone信息
local_irq_restore(flags);
out:
/* Separate test+clear to avoid unnecessary atomics */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}
buddy system分配内存的源头,在于zone结构体的free_area域:
struct zone {
/* Read-mostly fields */
...
struct per_cpu_pageset __percpu *pageset; //针对单个cpu的冷热页
...
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
...
}____cacheline_internodealigned_in_smp;
zone是一个非常复杂的结构体,负责管理内存分配,其中也包含了提供给buddy system的内存池,也就是free_area:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free; //用于表示当前order下空闲内存块的数量
};
可以看出,每一个不同的order,都会对应一个free_area,然后同一个order,同一个free_area下,再有每一个不同的 MIGRATE_TYPES ,都会对应一个free_list,即一个链表,我们可以视为一个内存池,这个链表具体是指向struct page的lru域。
也就是说,同一个链表上的内存区域,都是order(即对应的size)相同,迁移类型也相同的。
zone中还维护了一个pageset 域,用于管理per cpu的冷热页:
struct per_cpu_pageset {
struct per_cpu_pages pcp;
#ifdef CONFIG_NUMA
s8 expire;
u16 vm_numa_stat_diff[NR_VM_NUMA_STAT_ITEMS];
#endif
#ifdef CONFIG_SMP
s8 stat_threshold;
s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
#endif
};
struct per_cpu_pages {
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[MIGRATE_PCPTYPES];
};
所谓的冷热页,是指:
冷页表示该空闲页已经不再高速缓存中了(一般是指L2 Cache),热页表示该空闲页仍然在高速缓存中。冷热页是针对于每CPU的,每个zone中,都会针对于所有的CPU初始化一个冷热页的per-cpu-pageset,即pcp。
可以类比用户态中的fastbin或者tcachebin,将处在高速缓存中的页单独拎出来,优先分配,从而提高了工作效率。
pageset中的冷热页链表元素数量是有限制的,由per_cpu_pages的high成员控制,毕竟如果热页太多,实际上最早加进来的页已经不热了。
当一次释放1个page的时候,会优先将这个page放到pcp链表中,这和fastbin也是类似的。如果释放超过一个page,则会使用正常的buddy算法。
此时回看rmqueue()函数,可以看出,在order为0,即申请一个页的时候,会调用针对pcp链表的申请,与此吻合。
接着就是针对order>=1的情况,调用__rmqueue_smallest(),将会在zone中寻找能够满足order要求的,存在的,最小的对应内存块。即如果order对应链表里的内存不足,则到order+1处继续寻找,如此往复,直到找到为止:
/*
* Go through the free lists for the given migratetype and remove
* the smallest available page from the freelists
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
//将根据buddy算法 调整更新后的free_area
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
如果__rmqueue_smallest()的分配失败了, 即当前migratetype所对应的池子里面没有满足要求的。则会进入__rmqueue()函数,在该函数中,将会从别的迁移类型中,偷取page,即一次fallback的分配。
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
retry:
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page)) {
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
section III coda
这篇文章先到这里吧,已经一路顺藤摸瓜的逐渐摸到了buddy system的实现了,下一篇文章将会继续深入分析buddy system的实现细节,比如偷取机制的__rmqueue_fallback()到底如何实现的,分配成功后,对buddy系统的重新整理的expand()是如何实现的,并且结合整体的buddy system的思想、概念、原理,综合性的回顾整个分配系统。
然后估计再下一篇文章,会是slab分配机制的实现分析。然后才算是对于内核的heap内存分配有了一点点概念,然后还需要对释放部分再做一些研究,然后才能试着接触一些算是入门级的kernel pwn吧...
########################################################################
深入浅出内存管理--kmalloc支持的最大内存分配
首先我们来看下kmalloc的实现,本文基于kernel 4.0版本:
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) { -----------(1)
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags); --------------(2)
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace(kmalloc_caches[index], -----------------(3)
flags, size);
}
#endif
}
return __kmalloc(size, flags);------------------(4)
}
(1) __builtin_constant_p表示传入的是否为一个实数,gcc编译器会做这个判断,如果是一个确定的实数而非变量,那么它返回true,主要用于编译优化的处理。
(2) 如果是实数,那么会判断size是否大于KMALLOC_MAX_CACHE_SIZE,此值表示的是系统创建的slab cache的最大值,系统为kmalloc预先创建了很多大小不同的kmem cache,用于内存分配(HY:start_kernel——mm_init——kmem_cache_init中预先创建)。这里的含义就是如果内存申请超过此值,那么直接使用 kmalloc_large进行大内存分配,实际上最终会调用页分配器去分配内存,而不是使用slab分配器。
(3) kmalloc_large分配大内存,后面会讲到,实际上也就是调用页分配器(HY:alloc_pages)去分配内存。
(4) 最后如果是一个变量,那么会调用__kmalloc来进行分配(HY:代码有改变,当前是在定义了CONFIG_SLOB或者flag为申请DMA时,才会运行到这里)。
和此函数相关的宏定义有如下几个:
#define MAX_ORDER 11
#define PAGE_SHIFT 12
#define KMALLOC_SHIFT_HIGH ((MAX_ORDER + PAGE_SHIFT - 1) <= 25 ? \
(MAX_ORDER + PAGE_SHIFT - 1) : 25)
#define KMALLOC_SHIFT_MAX KMALLOC_SHIFT_HIGH
/* Maximum allocatable size */
#define KMALLOC_MAX_SIZE (1UL << KMALLOC_SHIFT_MAX)
/* Maximum size for which we actually use a slab cache */
#define KMALLOC_MAX_CACHE_SIZE (1UL << KMALLOC_SHIFT_HIGH)
/* Maximum order allocatable via the slab allocagtor */
#define KMALLOC_MAX_ORDER (KMALLOC_SHIFT_MAX - PAGE_SHIFT)
这里可能每个平台定义不同,以我的arm32为例,经过换算可知,KMALLOC_MAX_SIZE是4M(HY:8k)。
KMALLOC_MAX_SIZE = (1<<22) = 4M
KMALLOC_MAX_CACHE_SIZE = (1<<22) = 4M
KMALLOC_SHIFT_HIGH = 22
KMALLOC_SHIFT_MAX = 22
__kmalloc路径
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
struct kmem_cache *cachep;
void *ret;
cachep = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
ret = slab_alloc(cachep, flags, caller);
trace_kmalloc(caller, ret,
size, cachep->size, flags);
return ret;
}
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, _RET_IP_);
}
当代码跑到__kmalloc之后,我们继续跟进,发现会先查找kmalloc_slab,然后在对应的slab kmem cache中去申请内存来使用,采用slab_alloc来申请内存。那么内存大小的限制在如下代码中得以体现:
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{
int index;
if (unlikely(size > KMALLOC_MAX_SIZE)) {
WARN_ON_ONCE(!(flags & __GFP_NOWARN));
return NULL;
}
if (size <= 192) {
if (!size)
return ZERO_SIZE_PTR;
index = size_index[size_index_elem(size)];
} else
index = fls(size - 1);
#ifdef CONFIG_ZONE_DMA
if (unlikely((flags & GFP_DMA)))
return kmalloc_dma_caches[index];
#endif
return kmalloc_caches[index];
}
在这里判断了size大小是否超过KMALLOC_MAX_SIZE,也就是前面定义的4M,如果超过了就返回NULL,最终kmalloc申请失败。
kmalloc_large
想象一下,如果我们调用了一次内存分配函数,代码跑到了kmalloc_large,并且此size超过了伙伴系统能够支持的最大申请大小,比如order>11个page大小的内存,那么系统会在哪里判断返回呢?带着这个问题,我们看一下它的实现过程:
static __always_inline void *kmalloc_large(size_t size, gfp_t flags)
{
unsigned int order = get_order(size);
return kmalloc_order_trace(size, flags, order);
}
get_order返回值如下:
0 -> 2^0 * PAGE_SIZE and below
1 -> 2^1 * PAGE_SIZE to 2^0 * PAGE_SIZE + 1
2 -> 2^2 * PAGE_SIZE to 2^1 * PAGE_SIZE + 1
3 -> 2^3 * PAGE_SIZE to 2^2 * PAGE_SIZE + 1
4 -> 2^4 * PAGE_SIZE to 2^3 * PAGE_SIZE + 1
紧接着,函数调用到kmalloc_order:
void *kmalloc_order(size_t size, gfp_t flags, unsigned int order)
{
void *ret;
struct page *page;
flags |= __GFP_COMP;
page = alloc_kmem_pages(flags, order);
ret = page ? page_address(page) : NULL;
kmemleak_alloc(ret, size, 1, flags);
kasan_kmalloc_large(ret, size);
return ret;
}
进一步调用到alloc_kmem_pages:
struct page *alloc_kmem_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
struct mem_cgroup *memcg = NULL;
if (!memcg_kmem_newpage_charge(gfp_mask, &memcg, order))
return NULL;
page = alloc_pages(gfp_mask, order);
memcg_kmem_commit_charge(page, memcg, order);
return page;
}
最终调用到了alloc_pages,看过我前面文章的应该很熟悉了,这个就是页分配器的接口了,最终是会利用伙伴系统算法进行页的分配。看下伙伴系统核心:
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype]))
continue;
page = list_entry(area->free_list[migratetype].next,
struct page, lru);
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_freepage_migratetype(page, migratetype);
return page;
}
return NULL;
}
终于在这里有个current_order < MAX_ORDER的限制,这里也就是限制伙伴系统能够分配的内存大小最大不超过2^(MAX_ORDER-1)个page,经过计算可知:
2 ^ 10 * 4K = 4M
因此在我的平台上最大使用kmalloc申请不能超过4M大小。
————————————————
原文链接:https://blog.csdn.net/rikeyone/article/details/85766256
#######################################################################
1.CPU是如何访问内存的?
内存管理可以说是一个比较难学的模块,之所以比较难学。一是内存管理涉及到硬件的实现原理和软件的复杂算法,二是网上关于内存管理的解释有太多错误的解释。希望可以做个内存管理的系列,从硬件实现到底层内存分配算法,再从内核分配算法到应用程序内存划分,一直到内存和硬盘如何交互等,彻底理解内存管理的整个脉络框架。本节主要讲解硬件原理和分页管理。
CPU通过MMU访问内存
我们先来看一张图:

从图中可以清晰地看出,CPU、MMU、DDR 这三部分在硬件上是如何分布的。首先 CPU 在访问内存的时候都需要通过 MMU 把虚拟地址转化为物理地址,然后通过总线访问内存。MMU 开启后 CPU 看到的所有地址都是虚拟地址,CPU 把这个虚拟地址发给 MMU 后,MMU 会通过页表在页表里查出这个虚拟地址对应的物理地址是什么,从而去访问外面的 DDR(内存条)。
所以搞懂了 MMU 如何把虚拟地址转化为物理地址也就明白了 CPU 是如何通过 MMU 来访问内存的。
MMU 是通过页表把虚拟地址转换成物理地址,页表是一种特殊的数据结构,放在系统空间的页表区存放逻辑页与物理页帧的对应关系,每一个进程都有一个自己的页表。
CPU 访问的虚拟地址可以分为:p(页号),用来作为页表的索引;d(页偏移),该页内的地址偏移。现在我们假设每一页的大小是 4KB,而且页表只有一级,那么页表长成下面这个样子(页表的每一行是32个 bit,前20 bit 表示页号 p,后面12 bit 表示页偏移 d):

CPU,虚拟地址,页表和物理地址的关系如下图:

页表包含每页所在物理内存的基地址,这些基地址与页偏移的组合形成物理地址,就可送交物理单元。
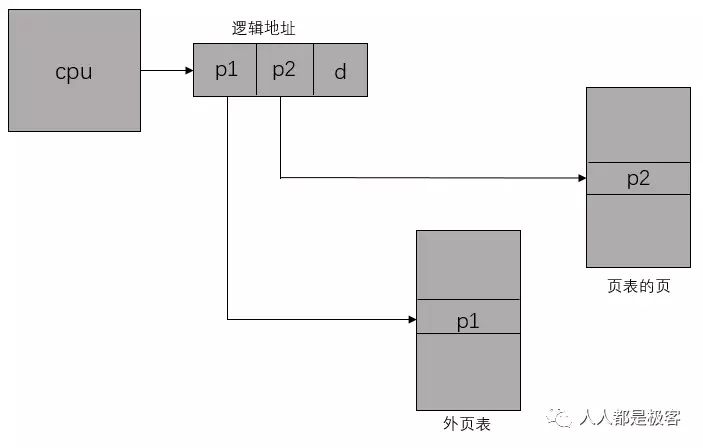
上面我们发现,如果采用一级页表的话,每个进程都需要1个4MB的页表(假如虚拟地址空间为32位(即4GB)、每个页面映射4KB以及每条页表项占4B,则进程需要1M个页表项(4GB / 4KB = 1M),即页表(每个进程都有一个页表)占用4MB(1M * 4B = 4MB)的内存空间)。然而对于大多数程序来说,其使用到的空间远未达到4GB,何必去映射不可能用到的空间呢?也就是说,一级页表覆盖了整个4GB虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有20%的一级页表项被用到了,那么页表占用的内存空间就只有0.804MB(1K * 4B + 0.2 * 1K * 1K * 4B = 0.804MB)。除了在需要的时候创建二级页表外,还可以通过将此页面从磁盘调入到内存,只有一级页表在内存中,二级页表仅有一个在内存中,其余全在磁盘中(虽然这样效率非常低),则此时页表占用了8KB(1K * 4B + 1 * 1K * 4B = 8KB),对比上一步的0.804MB,占用空间又缩小了好多倍!总而言之,采用多级页表可以节省内存。
二级页表就是将页表再分页。仍以之前的32位系统为例,一个逻辑地址被分为20位的页码和12位的页偏移d。因为要对页表进行再分页,该页号可分为10位的页码p1和10位的页偏移p2。其中p1用来访问外部页表的索引,而p2是是外部页表的页偏移。

2.物理地址和虚拟地址的分布
内容的学习我们知道了CPU是如何访问内存的,CPU拿到内存后就可以向其它人(kernel的其它模块、内核线程、用户空间进程、等等)提供服务,主要包括:
- 以虚拟地址(VA)的形式,为应用程序提供远大于物理内存的虚拟地址空间(Virtual Address Space)
- 每个进程都有独立的虚拟地址空间,不会相互影响,进而可提供非常好的内存保护(memory protection)
- 提供内存映射(Memory Mapping)机制,以便把物理内存、I/O空间、Kernel Image、文件等对象映射到相应进程的地址空间中,方便进程的访问
- 提供公平、高效的物理内存分配(Physical Memory Allocation)算法
- 提供进程间内存共享的方法(以虚拟内存的形式),也称作Shared Virtual Memory
在提供这些服务之前需要对内存进行合理的划分和管理,下面让我们看下是如何划分的。
物理地址空间布局
Linux系统在初始化时,会根据实际的物理内存的大小,为每个物理页面创建一个page对象,所有的page对象构成一个mem_map数组。进一步,针对不同的用途,Linux内核将所有的物理页面划分到3类内存管理区中,如图,分别为ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM。
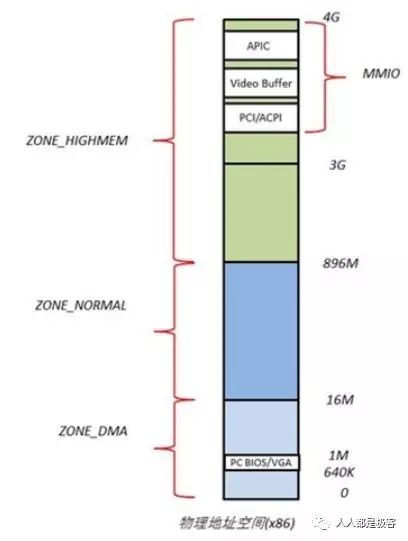
- ZONE_DMA 的范围是 0~16M,该区域的物理页面专门供 I/O 设备的 DMA 使用。之所以需要单独管理 DMA 的物理页面,是因为 DMA 使用物理地址访问内存,不经过 MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于 DMA。
- ZONE_NORMAL 的范围是 16M~896M,该区域的物理页面是内核能够直接使用的。
- ZONE_HIGHMEM 的范围是 896M~结束,该区域即为高端内存,内核不能直接使用。
Linux内核空间虚拟地址分布

在 Kernel Image 下面有 16M 的内核空间用于 DMA 操作。位于内核空间高端的 128M 地址主要由3部分组成,分别为 vmalloc area、持久化内核映射区、临时内核映射区。
由于 ZONE_NORMAL 和内核线性空间存在直接映射关系,所以内核会将频繁使用的数据如 Kernel 代码、GDT、IDT、PGD、mem_map 数组等放在 ZONE_NORMAL 里。而将用户数据、页表(PT)等不常用数据放在 ZONE_HIGHMEM 里,只在要访问这些数据时才建立映射关系(kmap())。比如,当内核要访问 I/O 设备存储空间时,就使用 ioremap() 将位于物理地址高端的 mmio 区内存映射到内核空间的 vmalloc area 中,在使用完之后便断开映射关系。
Linux用户空间虚拟地址分布
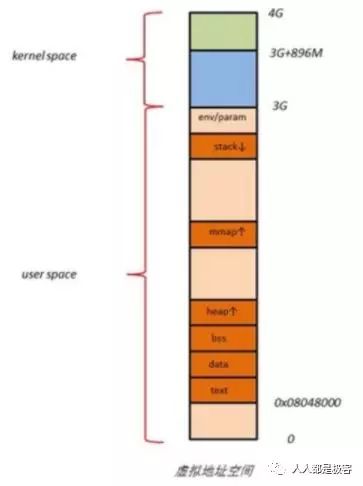
用户进程的代码区一般从虚拟地址空间的 0x08048000 开始,这是为了便于检查空指针。代码区之上便是数据区,未初始化数据区,堆区,栈区,以及参数、全局环境变量。
Linux物理地址和虚拟地址的关系

Linux 将 4G 的线性地址空间分为2部分,0~3G 为 user space,3G~4G 为 kernel space。
由于开启了分页机制,内核想要访问物理地址空间的话,必须先建立映射关系,然后通过虚拟地址来访问。为了能够访问所有的物理地址空间,就要将全部物理地址空间映射到 1G 的内核线性空间中,这显然不可能。于是,内核将 0~896M 的物理地址空间一对一映射到自己的线性地址空间中,这样它便可以随时访问 ZONE_DMA 和 ZONE_NORMAL 里的物理页面;此时内核剩下的 128M 线性地址空间不足以完全映射所有的 ZONE_HIGHMEM,Linux 采取了动态映射的方法,即按需的将 ZONE_HIGHMEM 里的物理页面映射到 kernel space 的最后 128M 线性地址空间里,使用完之后释放映射关系,以供其它物理页面映射。虽然这样存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了。
到这里我们应该知道了 Linux 是如何用虚拟地址来映射物理地址的,最后我们用一张图来总结一下:

3.Linux内核内存管理算法Buddy和Slab
Linux内核内存管理算法Buddy和Slab - 知乎
Buddy分配算法

假设这是一段连续的页框,阴影部分表示已经被使用的页框,现在需要申请一个连续的5个页框。这个时候,在这段内存上不能找到连续的5个空闲的页框,就会去另一段内存上去寻找5个连续的页框,这样子,久而久之就形成了页框的浪费。为了避免出现这种情况,Linux内核中引入了伙伴系统算法(Buddy system)。把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍,如图:

假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个页框的链表中找,找到了则将页框块分为2个256个页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页框的链表查找,如果仍然没有,则返回错误。页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
从上面可以知道Buddy算法一直在对页框做拆开合并拆开合并的动作。Buddy算法牛逼就牛逼在运用了世界上任何正整数都可以由2^n的和组成。这也是Buddy算法管理空闲页表的本质。 空闲内存的信息我们可以通过以下命令获取:

也可以通过echo m > /proc/sysrq-trigger来观察buddy状态,与/proc/buddyinfo的信息是一致的:

CMA
细心的读者或许会发现当Buddy算法对内存拆拆合合的过程中会造成碎片化的现象,以至于内存后来没有了大块的连续内存,全是小块内存。当然这对应用程序是不影响的(前面我们讲过用页表可以把不连续的物理地址在虚拟地址上连续起来),但是内核态就没有办法获取大块连续的内存(比如DMA, Camera, GPU都需要大块物理地址连续的内存)。
在嵌入式设备中一般用CMA来解决上述的问题。CMA的全称是contiguous memory allocator, 其工作原理是:预留一段的内存给驱动使用,但当驱动不用的时候,CMA区域可以分配给用户进程用作匿名内存或者页缓存。而当驱动需要使用时,就将进程占用的内存通过回收或者迁移的方式将之前占用的预留内存腾出来,供驱动使用。
Slab
在Linux中,伙伴系统(buddy system)是以页为单位管理和分配内存。但是现实的需求却以字节为单位,假如我们需要申请20Bytes,总不能分配一页吧!那岂不是严重浪费内存。那么该如何分配呢?slab分配器就应运而生了,专为小内存分配而生。slab分配器分配内存以Byte为单位。但是slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配。我们先来看一张图:

kmem_cache是一个cache_chain的链表,描述了一个高速缓存,每个高速缓存包含了一个slabs的列表,这通常是一段连续的内存块。存在3种slab:
- slabs_full(完全分配的slab)
- slabs_partial(部分分配的slab)
- slabs_empty(空slab,或者没有对象被分配)。
slab是slab分配器的最小单位,在实现上一个slab有一个货多个连续的物理页组成(通常只有一页)。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从slabs_partial中被删除,同时插入到slabs_full中去。
为了进一步解释,这里举个例子来说明,用struct kmem_cache结构描述的一段内存就称作一个slab缓存池。一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个object。分配内存的时候,就相当于从牛奶箱中拿一瓶。总有拿完的一天。当箱子空的时候,你就需要去超市再买一箱回来。超市就相当于partial链表,超市存储着很多箱牛奶。如果超市也卖完了,自然就要从厂家进货,然后出售给你。厂家就相当于伙伴系统。
可以通过下面命令查看slab缓存的信息:

总结
从内存DDR分为不同的ZONE,到CPU访问的Page通过页表来映射ZONE,再到通过Buddy算法和Slab算法对这些Page进行管理,我们应该可以从感官的角度理解了下图:
这篇博客的精髓在于这幅图

4.Linux用户态进程的内存管理
4.我们了解了内存在内核态是如何管理的,本篇文章我们一起来看下内存在用户态的使用情况,如果上一篇文章说是内核驱动工程师经常面对的内存管理问题,那本篇就是应用工程师常面对的问题。
相信大家都知道对用户态的内存消耗对象是进程,应用开发者面对的所有代码操作最后的落脚点都是进程,这也是说为什么内存和进程两个知识点的重要性,理解了内存和进程两大法宝,对所有软件开发的理解都会有了全局观(关于进程的知识以后再整理和大家分享)。
下面闲话少说,开始本篇的内容——进程的内存消耗和泄漏
进程的虚拟地址空间VMA(Virtual Memory Area)
在linux操作系统中,每个进程都通过一个task_struct的结构体描叙,每个进程的地址空间都通过一个mm_struct描叙,c语言中的每个段空间都通过vm_area_struct表示,他们关系如下 :

上图中,task_struct中的mm_struct就代表进程的整个内存资源,mm_struct中的pgd为页表,mmap指针指向的vm_area_struct链表的每一个节点就代表进程的一个虚拟地址空间,即一个VMA。一个VMA最终可能对应ELF可执行程序的数据段、代码段、堆、栈、或者动态链接库的某个部分。
VMA的分布情况可以有通过pmap命令,及maps,smaps文件查看,如下图:

另,VMA的具体内容可参考下图。

page fault的几种可能性
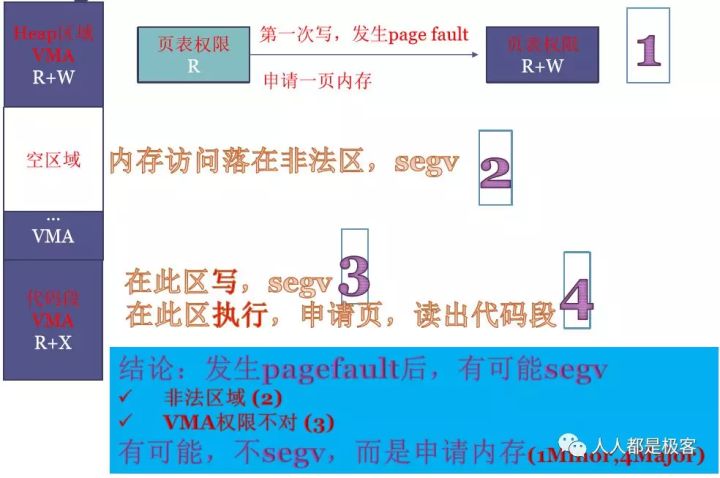
- 如,调用malloc申请100M内存,IA32下在0~3G虚拟地址中立刻就会占用到大小为100M的VMA,且符合堆的定义,这一段VMA的权限是R+W的。但由于Lazy机制,这100M其实并没有获得,这100M全部映射到一个物理地址相同的零页,且在页表中记录的权限为只读的。当100M中任何一页发生写操作时,MMU会给CPU发page fault(MMU可以从寄存器读出发生page fault的地址;MMU可以读出发生page fault的原因),Linux内核收到缺页中断,在缺页中断的处理程序中读出虚拟地址和原因,去VMA中查,发现是用户程序在写malloc的合法区域且有写权限,Linux内核就真正的申请内存,页表中对应一页的权限也修改为R+W。
- 如,程序中有野指针飞到了此程序运行时进程的VMA以外的非法区域,硬件就会收到page fault,进程会收到SIGSEGV信号报段错误并终止。如,程序中有野指针飞到了此程序运行时进程的VMA以外的非法区域,硬件就会收到page fault,进程会收到SIGSEGV信号报段错误并终止。
- 如,代码段在VMA中权限为R+X,如果程序中有野指针飞到此区域去写,则也会发生段错误。(另,malloc堆区在VMA中权限为R+W,如果程序的PC指针飞到此区域去执行,同样发生段错误。)
- 如,执行代码段时会发生缺页,Linux申请1页内存,并从硬盘读取出代码段,此时产生了IO操作,为major主缺页。如,执行代码段时会发生缺页,Linux申请1页内存,并从硬盘读取出代码段,此时产生了IO操作,为major主缺页。
综上,page fault后,Linux会查VMA,也会比对VMA中和页表中的权限,体现出VMA的重要作用。
malloc分配的原理
malloc的过程其实就是把VMA分配到各种段当中,这时候是没有真正分配物理地址的。malloc 调用后,只是分配了内存的逻辑地址,在内核的mm_struct 链表中插入vm_area_struct结构体,没有分配实际的内存。当分配的区域写入数据时,引发页中断,建立物理页和逻辑地址的映射。下图表示了这个过程。

从操作系统角度来看,进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap(不考虑共享内存)。
- malloc小于128k的内存,使用brk分配内存,将_edata往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系)
- malloc大于128k的内存,使用mmap分配内存,在堆和栈之间找一块空闲内存分配(对应独立内存,而且初始化为0)
内存的消耗VSS RSS PSS USS
首先,我们评估一个进程的内存消耗都是指用户空间的内存,不包括内核空间的内存消耗 。这里我们用工具 procrank先来看下Linux进程的内存占用量 。

- VSS -Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)
- RSS -Resident Set Size 实际使用物理内存(包含共享库占用的内存)
- PSS -Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)
- USS -Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)
下面再用一张图来更好的解释VSS,RSS,PSS,USS之间的区别:

(HY:内存耗用:VSS/RSS/PSS/USS 的介绍 - 简书)
有了对VSS,RSS,PSS,USS的了解,我们趁热打铁来看下内存在进程中是如何被瓜分的:
(HY:Linux内存工具解析之RSS/VSS/USS/PSS区别于联系_飞翔de刺猬-CSDN博客)
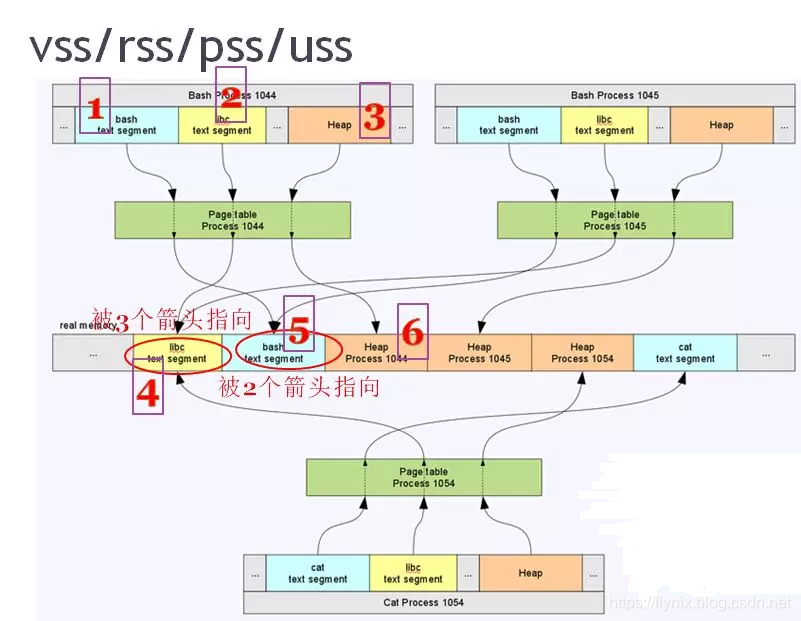
1044,1045,1054三个进程,每个进程都有一个页表,对应其虚拟地址如何向real memory上去转换。
process 1044的1,2,3都在虚拟地址空间,所以其VSS=1+2+3。
process 1044的4,5,6都在real memory上,所以其RSS=4+5+6。
分析real memory的具体瓜分情况:
4 libc代码段,1044,1045,1054三个进程都使用了libc的代码段,被三个进程分享。
5 bash shell的代码段,1044,1045都是bash shell,被两个进程分享。
6 1044独占
所以,上图中4+5+6并不全是1044进程消耗的内存,因为4明显被3个进程指向,5明显被2个进程指向,衍生出了PSS(按比例计算的驻留内存)的概念。进程1044的PSS为4/3 +5/2 +6。
最后,进程1044独占且驻留的内存USS为 6。
一般来说内存占用大小有如下规律:VSS >= RSS >= PSS >= USS
5.面对内存,告别“一页障目”
没有宏观概念,上来通过撸代码来理解简直就是耍流氓,效率极低。为了更有效的理解内存管理的来龙去脉很有必要先了解一些基础概念,然后再去撸代码。来,先一起看看那些内存里的各种页的含义和应用场景。

用户进程的内存页分为两种:
- file-backed pages(文件背景页)
- anonymous pages(匿名页)
比如进程的代码段、映射的文件都是file-backed,而进程的堆、栈都是不与文件相对应的、就属于匿名页。
file-backed pages在内存不足的时候可以直接写回对应的硬盘文件里,称为page-out,不需要用到交换区(swap);而anonymous pages在内存不足时就只能写到硬盘上的交换区(swap)里,称为swap-out。
file-backed pages(文件背景页)
对于有文件背景的页面,程序去读文件时,可以通过read也可以通过mmap去读。当你通过任何一种方式从磁盘读文件时,内核都会给你申请一个page cache,来缓存硬盘上的内容。这样的话,读过一遍的数据,本进程或其他进程下次再读的时候就直接从page cache里去拿,就很快了,提升系统的整体性能。因此用户的read/write实际上是跟page cache的相互拷贝。
而用户的mmap则会将一段虚拟地址(3G)以下映射到page cache上,这样的话,用户就可以通过读写这段虚拟地址来修改文件内容,省去了内核和用户之间的拷贝。
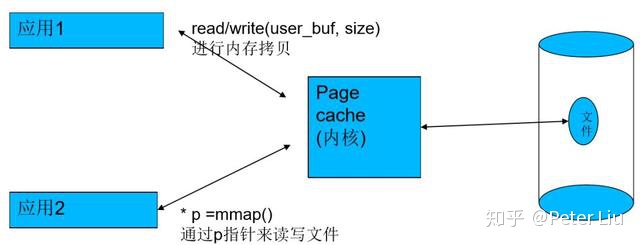
所以文件对于用户程序来讲其实只是内存,page cache就是磁盘中文件的一个副本。可以通过 “echo 3 > /proc/sys/vm/drop_cache” 来清cache。清掉之后,进程第一次读文件就会变慢。
通过free命令可以看到当前page cache占用内存的大小,free命令中会打印buffers和cached(有的版本free命令将二者放到一起了)。通过文件系统来访问文件(挂载文件系统,通过文件名打开文件)产生的缓存就由cached记录,而直接操作裸盘(打开/dev/sda设备去读写)产生的缓存就由buffers记录。

实际上文件系统本身再读写文件就是操作裸分区的方式,用户态也可以直接操作裸盘,像dd命令操作一个设备名也是直接访问裸分区。那么,通过文件系统读写的时候,就会既有cached又有buffers。从图中可以看到,文件名等元数据和文件系统相关,是进cached,实际的数据缓存还是在buffers。例如,read一个文件(如ext4文件系统)的时候,如果文件cache命中了,就不用走到ext4层,从vfs层就返回了。
当然,还可以在open的时候加上O_DIRECT标记,做直接IO,就连buffers都不进了,直接读写磁盘。
anonymous pages(匿名页)
没有文件背景的页面,即匿名页(anonymous page),如堆,栈,数据段等,不是以文件形式存在,因此无法和磁盘文件交换,但可以通过硬盘上划分额外的swap分区或使用swap文件进行交换。swap分区可以将不活跃的页交换到硬盘中,缓解内存紧张。swap分区可以当做针对匿名页伪造的文件背景。

页面回收(reclaim)
- 有文件背景的数据实际上就是page cache,但page cache不能无限增加,不能说慢慢的所有文件都缓存到内存了。肯定要有一个机制,让不常用的文件数据从page cache刷出去。内核中有一个水位控制的机制,在系统内存不够用的时候,会触发页面回收。
- 对于没有文件背景的页面即匿名页,比如堆、栈、数据段,如果没有swap分区,不能与磁盘交换,就要常驻内存了。但是常驻内存的话,就会吃内存,可以通过给硬盘搞一个swap分区或硬盘中创建一个swap文件让匿名页也能交换到磁盘上。可认为是为匿名页伪造的文件背景。swap分区或swap文件实际上最终是到达了增大内存的效果。当然,如果频繁交换的话,被交换出去的数据的访问就会慢一些,因为要有IO操作了。
1. 水位(watermark)控制:
内核中有三个水位:
- min:如果剩余内存减少到触及这个水位,可认为内存严重不足,当前进程就会被堵住,kernel会直接在这个进程的进程上下文里面做内存回收(direct reclaim)。
- low:当剩余内存慢慢减少,触到这个水位时,就会触发kswapd线程的内存回收。
- high: 进行内存回收时,内存慢慢增加,触到这个水位时,就停止回收。
由于每个ZONE是分别管理各自内存的,因此每个ZONE都有这三个水位

2. swapness:
回收的时候,是回收有文件背景的页还是匿名页还是都会回收呢,可通过/proc/sys/vm/swapness来控制让谁回收多一点点。swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。当然,它们的回收方法都是一样的LRU算法,即最近最少使用的页会被回收。

3. 如何计算水位:
/proc/sys/vm/min_free_kbytes 是一个用户可配置的值,默认值是min_free_kbytes = 4 * sqrt(lowmem_kbytes)。然后根据min算出来low和high水位的值:low=5/4*min,high=6/4*min。
脏页的写回
sync是用来回写脏页的,脏页不能在内存中呆的太久,因为如果突然断电没有写到硬盘的话脏数据就丢了,另一方面如果攒了很多一起写回也会明显占用CPU时间。
那么脏页时候写回呢?脏页回写的时机由时间和空间两方面共同控制:
时间:
- dirty_expire_centisecs: 脏页的到期时间,或理解为老化时间,单位是1/100s,内核中的flusher thread会检查驻留内存的时间超过dirty_expire_centisecs的脏页,超过的就回写。
- dirty_writeback_centisecs:内核的flusher thread周期性被唤醒(wakeup_flusher_threads())的时间间隔,每次被唤醒都会去检查是否有脏页老化了。如果将这个值置为0,则flusher线程就完全不会被唤醒了。
空间:
- dirty_ratio: 一个写磁盘的进程所产生的脏页到达这个比例时,这个进程自己就会去回写脏页。
- dirty_background_ratio: 如果脏页的数量超过这个比例时,flusher线程就会启动脏页回写。
所以:
- 即使只有一个脏页,那如果它超时了,也会被写回。防止脏页在内存驻留太久。dirty_expire_centisecs这个值默认是3000,即30s,可以将其设置得短一些,这样掉电后丢失的数据会更少,但磁盘写操作也更密集。
- 不能有太多的脏页,否则会给磁盘IO造成很大压力,例如在内存不够做内存回收时,还要先回写脏页,也会明显耗时。
需要注意的是,在达到dirty_background_ratio后,flusher线程(名为“[flush-devname]”)开始回写,但由于写磁盘速度慢,如果此时应用进程还在不停地写磁盘,flusher线程回写没那么快,那么就会导致进程的脏页达到dirty_ratio,这时这个进程就会去回写脏页而导致write被堵住。也就是说dirty_background_ratio通常是比dirty_ratio小的。
脏页都是指有文件背景的页面,匿名页不会存在脏页。从/proc/meminfo的’Dirty’一行可以看到当前系统的脏页有多少,用sync命令可以刷掉。
zRAM机制
不用swap分区,也可以用zRAM机制来缓解内存紧张:从内存里拿出一段内存空间(compressed block),作为交换空间模拟硬盘的交换分区,用来交换匿名页,并且让kernel看到的物理内存大小不包括这段内存。而这段交换空间自带透明压缩功能,即交换到这块zRAM分区时,Linux会自动将这块匿名页压缩存放。系统访问这块页面的内容时,产生page fault后从交换分区去拿,这时Linux给你透明解压再交换出来。
使用zRAM的好处,就是访存比访问硬盘或flash的速度提高很多,且不用考虑寿命问题,并且由于这段内存是压缩后存储的,因此可以存更多的数据,虽然占用了一段内存,但实际可以存更多的数据,也达到了增加内存的效果。缺点就是压缩要占用CPU时间。
Android里面普遍使用了zRAM技术,由于zRAM牺牲了CPU时间,所以交换次数还是越少越好。像Android和windows,内存越大越好,因为发生交换的几率就小。这样两个进程相互切换(如微博和微信)时就会变得流畅,因为内存足够的话,后台进程无需被换进swap分区或被OOM杀掉。当然如果你只打打电话,就没必要大内存啦。