

论文链接:
https://arxiv.org/pdf/2306.02763.pdf
代码链接:
https: //github.com/ZhenglinZhou/STAR
要解决的问题:人脸关键点检测标注中存在语义歧义问题。语义歧义是指不同的标注者对同一个面部特征点的位置有不同的理解,导致标注结果不一致,影响模型的收敛和准确性。

解决方案:提出一种自适应各向异性方向损失(STAR loss,Self-adapTive Ambiguity Reduction loss),利用预测分布的各向异性程度来表示语义歧义。STAR loss 能够自适应地减小语义歧义的影响,提高面部特征点检测的性能。
效果:在三个人脸关键点数据集上超越了现有方法,实现 SOTA。
相似工作:存在几项工作解决面部关键点检测中的语义歧义问题。SBR 使用相邻帧之间光流的一致性作为监督,但对照明和遮挡敏感。LAB 使用面部边界线作为结构约束,这在实践中可行但计算开销大。此外,SA 提出潜在变量优化策略来找到语义一致的注释,并在训练阶段减轻随机噪声的影响。
然而,复杂的训练策略限制了其应用。与本文工作最相关的是 ADNet,它提出了两个关键模块,即各向异性方向损失(ADL)和各向异性注意力模块(AAM),以处理模棱两可的注释问题。其中,ADL 在面部边界上的关键点的法向施加更多约束,但方向和约束权重是手工设计的,这种粗糙的设计降低了其性能。
前言
简要介绍当前广泛使用的回归方法的流程。
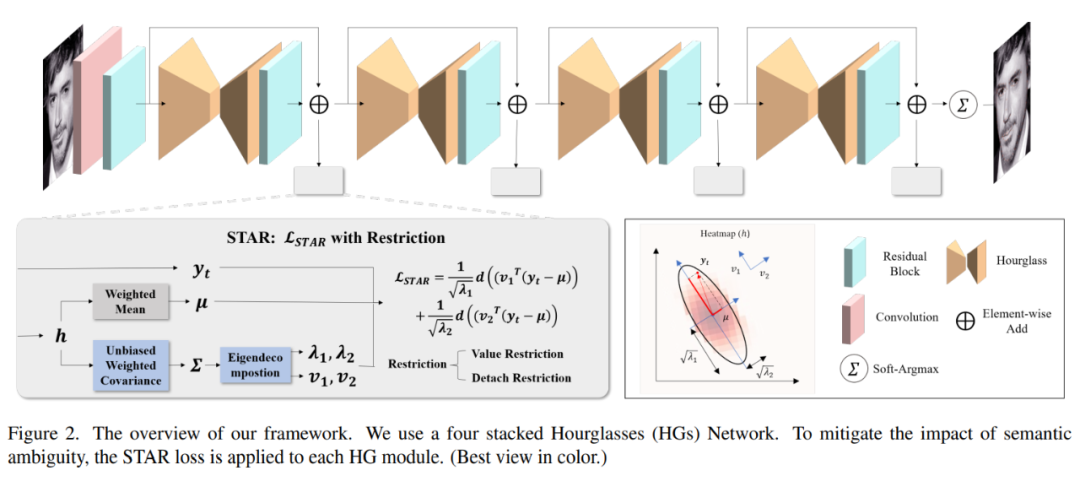
如图 2 顶部所示,回归方法的基本模型由四个 Hourglass Networks(HGs)堆叠而成。每个 HG 为 N 个关键点生成 N 个热力图,其中 N 是预定义关键点的数量。归一化后的热力图可以看作是预测关键点位置的概率分布。预测的坐标从热力图中通过 soft-Argmax 解码。形式上,给定一个离散概率分布 ,将值 定义为关键点定位在 的概率。期望坐标 μ 通过 soft-Argmax 解码:
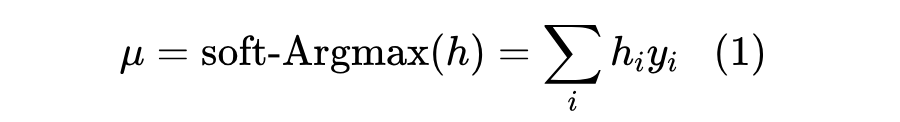
基于这些预测坐标,可以使用回归损失来学习模型的参数。回归损失可以看作是预测坐标 μ 和手动注释 之间的距离 。l1 距离、l2 距离、smooth-l1 距离和 Wing 距离等都是常用的距离度量。所以,回归损失可以公式化为:
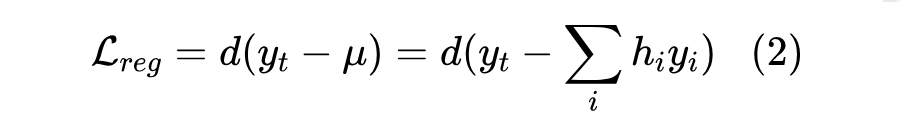
手动注释遭受语义歧义问题。如图 2 灰色框所示,问题的关键在于回归损失。

方法
语义歧义问题极大地降低了检测性能。为处理这个问题,设计了一种新的自适应歧义减少方法 STAR 损失,它受预测分布的影响。具体来说,当预测分布各向异性时,STAR 损失倾向于变小。
为表示预测分布的形状,首先引入了一种自定义的 PCA,应用于离散概率分布。然后,可视化在预测分布上计算的 PCA 结果,并讨论其第一主成分与语义歧义的相关性。基于此,详细介绍 STAR 损失,它适应性地抑制第一主成分方向上的预测误差,以在训练阶段减轻歧义注释的影响。
1.1 语义歧义分析
离散概率分布的 PCA。首先设计了一种自定义的 PCA,应用于离散概率分布,它由两步组成:
(1)近似均值和协方差矩阵;
(2)计算协方差矩阵的特征值分解。
步骤 1:类似于式(1)中的加权均值,加权协方差矩阵给出如下:
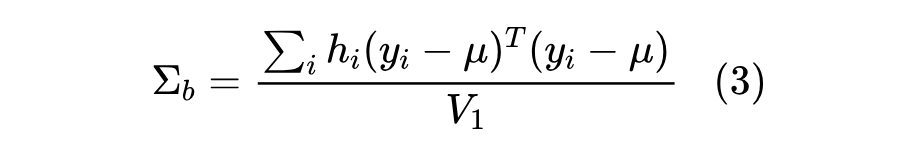
其中 。为了更精确地逼近,确定一个校正因子以获得无偏估计器。校正因子为 ,其中 。
因此,考虑贝塞尔校正的加权协方差矩阵无偏估计如式(4)。通常使用 。
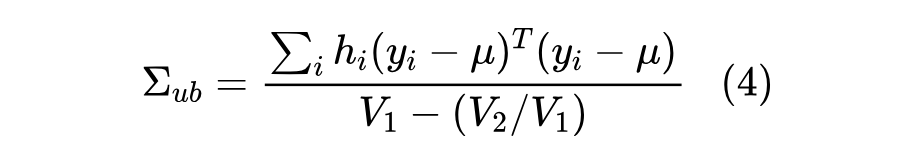
步骤2:计算协方差矩阵的特征值分解,表示为:
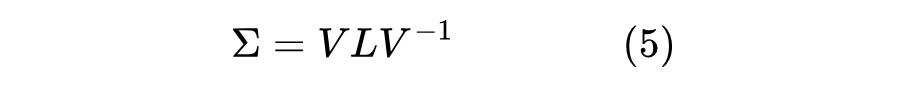
其中 , 是特征向量矩阵,, 是对应的特征值矩阵。称 , 和 , 为第一和第二主成分。
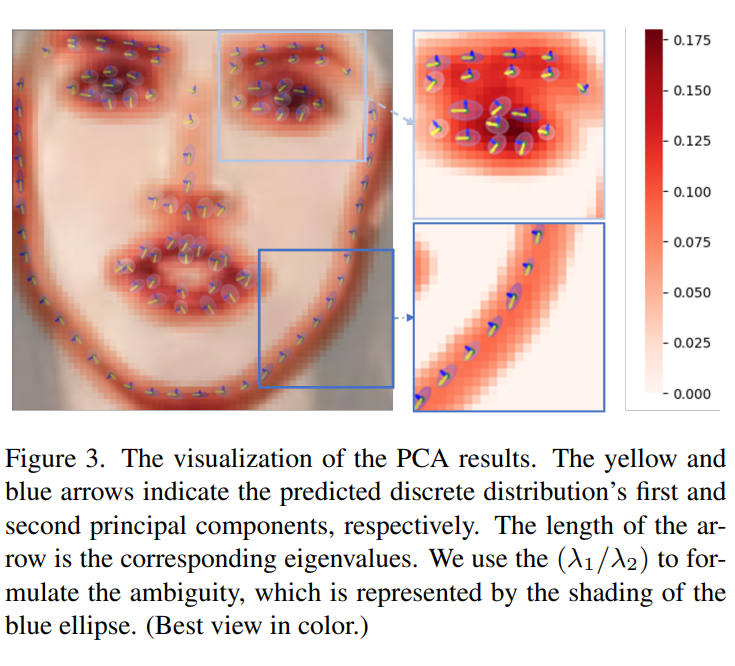
相关性讨论。在图 3 中,可视化了预测离散概率分布的 PCA 结果。一方面,轮廓关键点的一个显著特征是它们的第一主成分方向与面部轮廓一致。同时,如上所述,轮廓关键点的歧义方向也与面部轮廓一致。也就是说,对于具有各向异性预测分布的面部关键点,第一主成分方向与它们的歧义方向高度一致。
另一方面,通过蓝色阴影可视化椭圆离心率()。与近乎白色的眼角相比,轮廓点的颜色为蓝色。这表明当歧义更严重时,离心率更高。进一步推断,相应的能量可以表示歧义强度。因为在各向异性预测分布中,高方差主要是由语义歧义导致的不一致注释造成的。基于这两个观察结果,引入 STAR 损失。
1.2 STAR损失
提出的 STAR 损失属于一种自适应的歧义减少回归损失。通过歧义引导分解来实现它。同时,提出了两种特征值约束方法,以避免 STAR 损失异常减少。
歧义引导分解。根据上述动机,STAR 损失将预测误差分解成两个主成分方向,并除以相应的能量值,以自适应减少歧义的影响。因此,STAR 损失可以表示为:
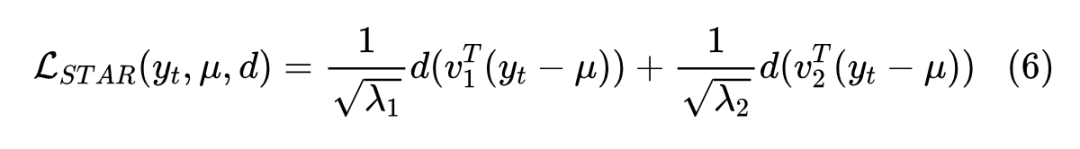
其中 和 根据歧义方向投影预测误差 , 和 自适应施加约束,d 表示距离函数。因为分解操作不会影响误差指标,STAR 损失可以与任意距离函数一起使用,并从 distance 函数的改进中获益,例如 smooth-l1、Wing 等。
拿一个具有各向异性预测分布的面部关键点为例,其中 远大于 。这样, 导致第一主成分方向 上的预测误差很小。它使模型关注第一主成分方向 上的预测误差变小,这主要是由不一致的手动注释引起的。因此,在 的帮助下,检测模型可以减轻语义歧义的影响,从而取得更好的收敛性。
特征值约束。根据实验,发现特征值 λ 异常增加会导致模型过早收敛。为解决这个问题,认为主要原因是特征值 λ 是 中的分母。为最小化 ,模型倾向于增加特征值 λ。因此,提出了两种对特征值的约束,以避免 异常减少。第一种是损失约束项,即值约束,形式化如下:
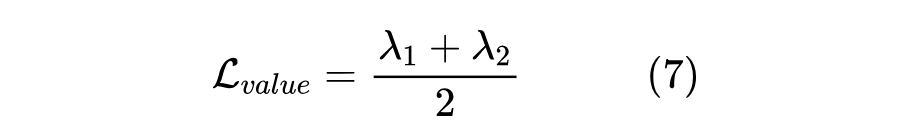
它直接约束特征值的异常增加。另一方面,提出解耦特征值和特征向量的梯度,即解耦约束。切断了从特征值和特征向量到 STAR 损失的反向传播,使它们在 STAR 损失中充当常量值。因此,STAR 损失可以使用它们但不直接影响预测分布的形状。消融实验表明,两种约束都有助于缓解异常增加问题。后续使用值约束作为默认设置(除非另有说明)。

实验
首先介绍实验设置,包括训练详细信息、模型设置、数据集和评估指标。其次,通过广泛的实验来研究 STAR 损失的优势。
2.1 实验设置
数据增强。对所有实验使用相同的数据增强策略。输入图像的生成分两步进行:(1)裁剪面部区域并调整大小为 256×256。(2)执行增强,包括随机旋转(18°)、随机缩放(±10%)、随机裁剪(±5%)、随机灰度(20%)、随机模糊(30%)、随机遮挡(40%)和随机水平翻转(50%)。
模型设置。使用四堆叠 hourglass 模型作为骨干网络。HG 中的递归步数设置为 3。每个 hourglass 模块输出一个 64×64 的特征图。训练策略:采用 Adam 优化器和初始学习率 1×10−3。训练模型 500 个 epoch,并在第 200、350 和 450 个 epoch 时学习率下降 10 倍。模型在四个 GPU(32GB NVIDIA Tesla V100)上训练,每个 GPU 的 batch size 为 16。还研究了一些常用的技巧,如分布正则化(DR)和各向异性注意力模块(AAM),这些技巧可以进一步提高性能。
数据集。在三个常用公开数据集上评估,包括 COFW、300W 和 WFLW。同时,使用基于视频的数据集 300VW 进行跨数据集验证。COFW 包含 1345 张训练图像和 507 张测试图像,包含 29 个关键点。
300W 包含 3148 张训练图像和 689 张测试图像。所有图像标注了 68 个关键点。在 300-W 上使用常见的设置,其中测试集分为常见集(554 张图像)和挑战集(135 张图像)。WFLW 目前是面部标志检测中使用最广泛的数据集,其中包含 7500 张训练图像和 2500 张测试图像,具有 98 个标志点。
300VW:使用测试集来验证在 300W 上训练的模型。它提供了三个测试集:Category-A(光照良好,31个视频,共62135帧)、Category-B(轻度非约束,19 个视频,共 32805 帧)和 Category-C(有挑战性,14 个视频,共 26338 帧)。
评估指标。使用三个常用的评估指标:归一化平均误差(NME)、失败率(FR)和曲线下面积(AUC),来评估关键点检测性能。具体来说,(1)NME:在 300W、WFLW 数据集上使用眼睛间距离进行归一化;在 COFW 数据集上使用瞳孔间距离进行归一化;(2)FR:在 WFLW 上将阈值设置为 10%;(3)AUC:在 WFLW 上将阈值设置为 10%。
比较方法。将 STAR 损失与 14 种最新技术进行了比较。为了公平比较,这些方法的结果来自相应的论文。
2.2 准确性评估
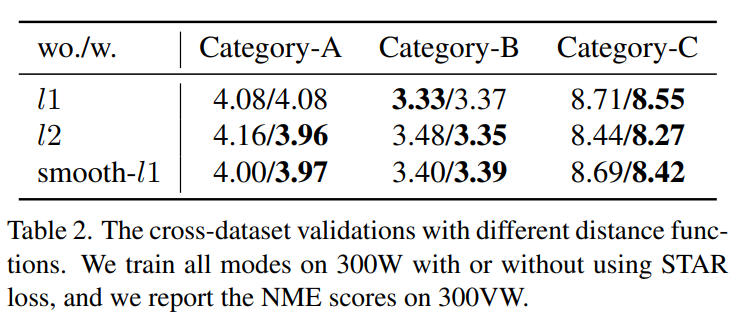
将 STAR 损失与 14 种最新技术进行了比较(如表 1 所示)。在 300W 上设计了两个有趣的实验,包括数据集内验证和跨数据集验证。首先,数据集内验证的结果如表 1 所示。本文方法在所有测试集上都能达到最先进的性能。主要是,与最先进的方法相比,本文在挑战子集上有 0.2 的改进。其次,对于跨数据集验证,模型在 300W 上训练,在 300VW 上评估。同时,跨数据集验证的结果如表 2 所示。评估了不同距离函数与 STAR 损失的组合。
结果表明,与基准相比,在 Category-C上获得了 0.2 的平均改进。值得注意的是,Category-C 子集是最具挑战性的,其中视频帧模糊且遮挡严重。观察到在数据集内和跨数据集验证的挑战测试中都取得了显著提高,这验证了方法的有效性。同时,本文方法在 COFW 数据集上也达到了最先进的性能。
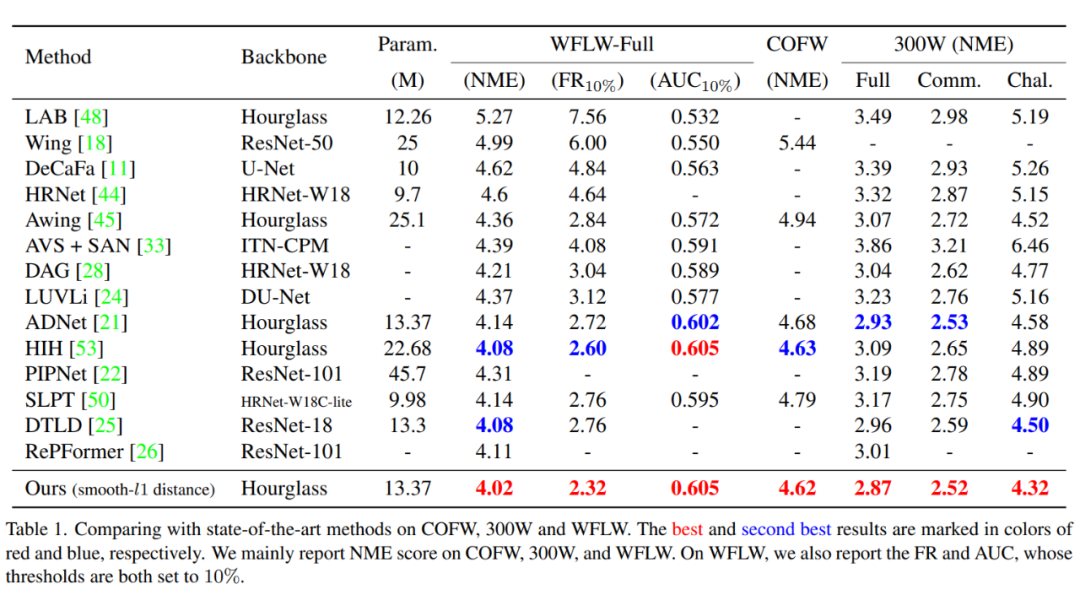
WFLW 是一个非常有挑战性的基准,因为它包含了许多恶劣条件下的图像,如姿势、化妆、照明、模糊和表情。在表 1 中报告了结果,其中 STAR 损失仍然取得了最佳结果。
具体来说,与最先进的方法相比,STAR 损失在整个测试集的 NME 和 FR10% 指标上分别改进了 0.06 和 0.28。与 COFW 和 300-W 数据集的提高相比,STAR 损失在 WFLW 数据集中取得的改进是充分的。可以得出结论,STAR 损失在大数据集上表现更好,即所提出的STAR损失将减轻注释错误的影响,并从大量噪声数据中获益。
2.3 消融实验
评估不同距离函数。为研究距离函数的影响,在 COFW、300W 和 WFLW 数据集上分别测试 STAR 损失与常用距离函数(如 l1 距离、l2 距离、smooth-l1 距离和 Wing 距离)的组合。注意这里使用的 smooth-l1 距离形式化为:
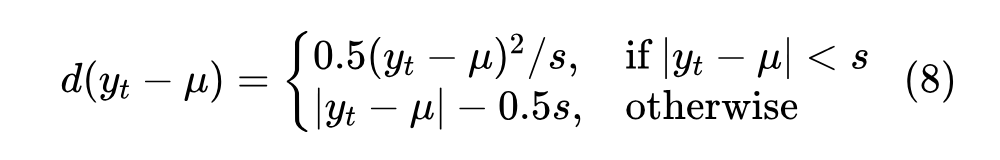
其中 s 是阈值,通常设置为 s = 0.01。称式(2)中定义的回归损失为基准。结果如表 3 所示。与基准相比,STAR 损失在不同距离函数之间在 COFW、300W 和 WFLW 数据集上分别获得了平均 0.34、0.19 和 0.25 的改进,计算量可忽略。同时,发现 STAR 损失与 l2 距离函数的组合效果显著。
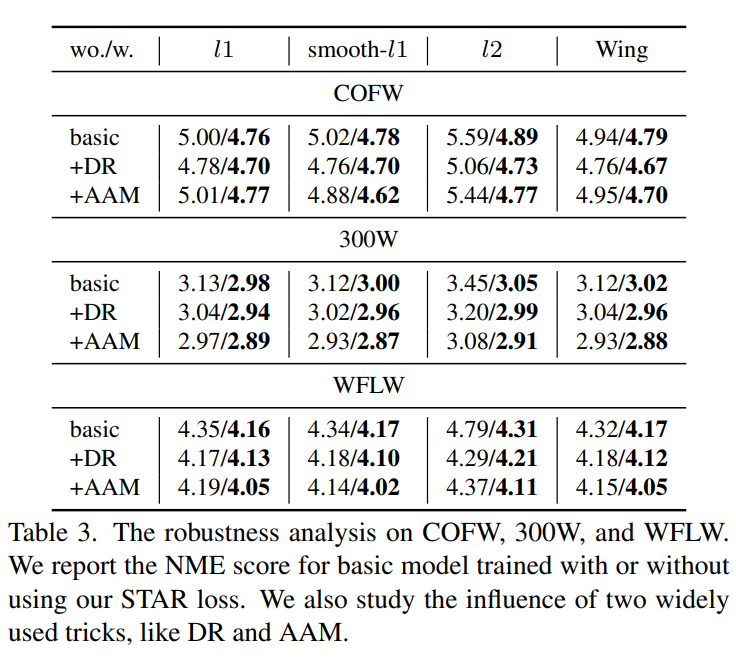
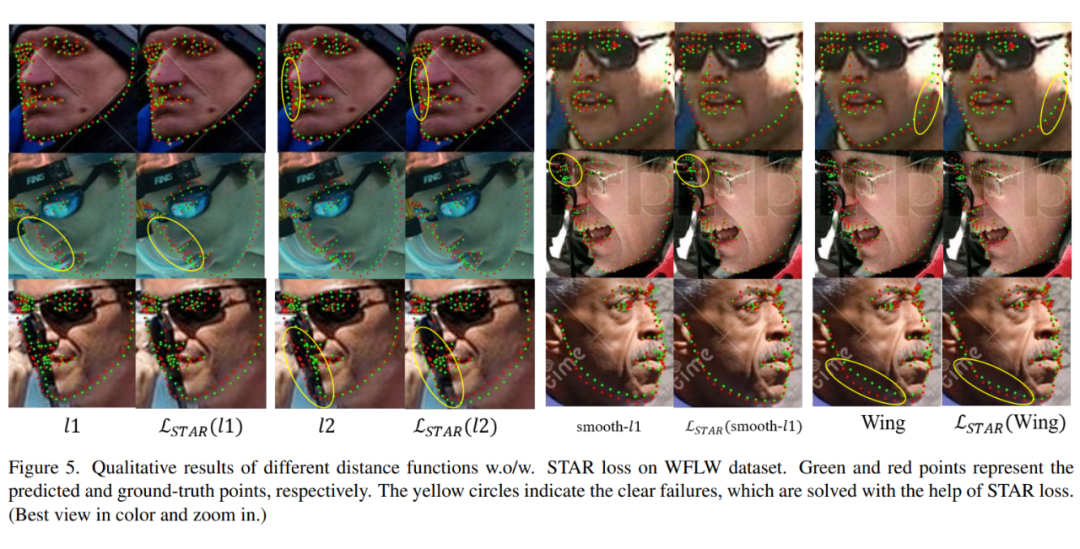
此外,可视化了不同距离函数与/或无 STAR 损失在 WFLW 数据集上的失败案例。如图 5 所示,STAR 结果展示了更好的结构约束。推断 STAR 充当标签正则化,帮助模型避免过度拟合歧义注释,并更注意关键点之间的关系。
评估不同分布归一化。用不同的分布归一化评估提出的 STAR 损失,如分布正则化(DR)和各向异性注意力模块(AAM)。DR 是一种更严格的正则化,迫使热图类似高斯分布。AAM 是一个注意力模块,学习点边热图作为注意力掩码,迫使热图类似于高斯分布和相邻边界分布的混合。在 DR 中,使用 Jensen-Shannon 散度作为散度度量,并将高斯 σ 设置为 1.0。
在表 3 中,两者都有积极的效果:1)在 WFLW 数据集上,STAR 损失在 DR 和 AAM 上的平均改进分别为 0.07 和 0.16;2)在 COFW 数据集上,改进分别为 0.14 和 0.35;3)在 300W 数据集上,改进分别为 0.11 和 0.09;观察到 AAM 与 STAR 损失更匹配,因为 AAM 中的边界信息进一步有助于减轻歧义。
在三个数据集中,smooth-l1 距离、AAM 和 STAR 损失的组合取得了最佳结果,这也是准确性评估中默认的模型设置。注意,用于图 1 和图 3 可视化的模型是用 L2 和 DR 的组合训练。
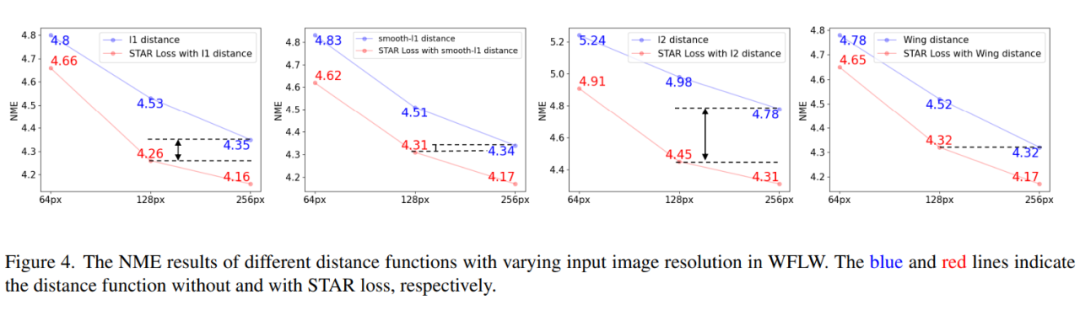
评估不同输入图像分辨率。调查不同输入图像分辨率(64px、128px 和 256px)的影响。结果如图 4 所示,STAR 损失对所有输入图像分辨率都具有积极影响。具体来说,STAR 损失在 64px、128px 和 256px 的不同距离函数上获得了平均 0.20、0.30 和 0.25 的改进。值得注意的是,128px 的基准与 STAR 损失相当于或优于 256px 的基准。这意味着 STAR 损失对输入图像大小不太敏感,这促使在小模型中使用 STAR 损失。

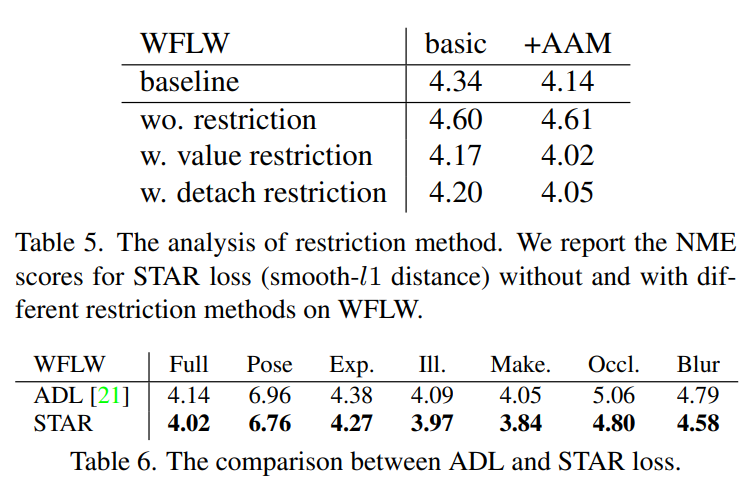
评估不同约束。首先,研究值约束及其权重 w 在 STAR 损失中的效果。如表 4 所示,STAR 损失对 w 并不敏感,将 w = 1 作为默认设置。然后,分析解耦约束。如表 5 所示,约束对获得改进至关重要,解耦约束的效果与值约束相当。这种观察表明,改进主要来自于 STAR 损失本身,而不是值约束项。
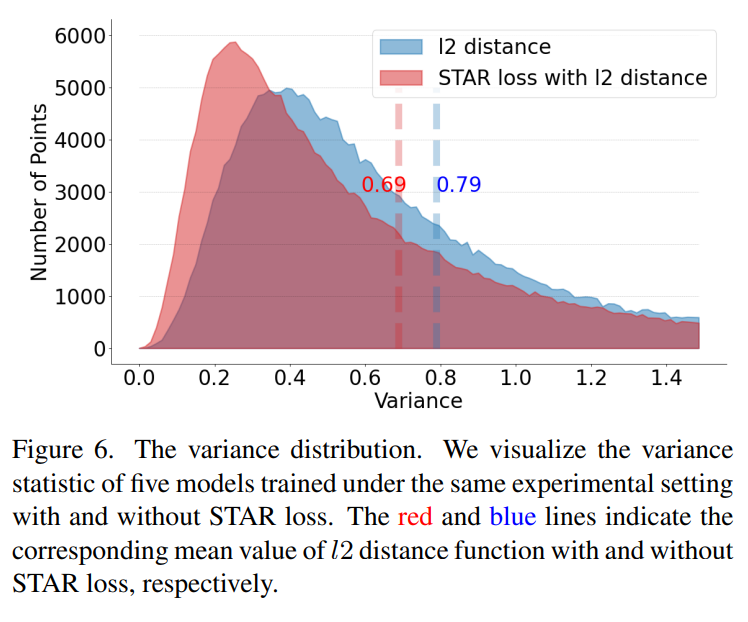
评估稳定性。评估 STAR 损失对稳定性的影响。为定量分析稳定性,设计了一个玩具实验:1)在相同的实验设置下,分别与/无 STAR 损失训练 N=5 个模型;2)在 WFLW 测试集上计算 N 个模型预测的方差。如图 6 所示,带 STAR 损失训练的模型预测分布更集中在一个小的方差范围内。同时,预测方差的平均值从 0.79 下降到 0.69。这表明 STAR 损失确实减轻了模糊注释的影响,使预测更稳定。

结论
本文研究了面部关键点检测中的语义歧义问题,并提出了一种自适应的歧义减少方法 STAR 损失。文章方法在三个基准测试中都取得了 SOTA。在工程实践中有较大帮助。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)