中间件
-
作用:批量拦截请求和响应
-
爬虫中间件
-
下载中间件(推荐)
详解:
我们创建个工程middlePro,爬取百度和搜狗。
import scrapy
class MiddleSpider(scrapy.Spider):
name = 'middle'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.baidu.com/', 'https://www.sogou.com']
def parse(self, response):
print(response)
然后我们看下中间件这个文件middlewares.py
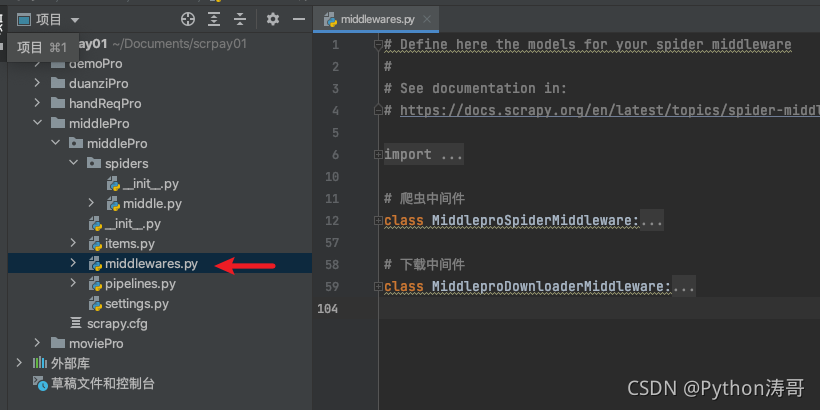
这里我们不需要爬虫中间件,把它删除。主要看下载中间件里的内容:
下载中间件MiddleproDownloaderMiddleware中也有一个不需要的方法和注释,删除掉,只需留下下面三个需要重写的方法:

# 拦截所有(正常&异常)的请求
# 参数:request就是拦截到的请求,spider就是爬虫类实例化的对象
def process_request(self, request, spider):
return None
# 拦截所有的响应对象
# 参数:respone拦截到的响应对象,request响应对象对应的请求对象
def process_response(self, request, response, spider):
return response
# 拦截异常的请求
# 参数:request就是拦截到的发生异常的请求
# 作用:想要将异常的请求进行修正,将其变成正常的请求,然后对其进行重新发送
def process_exception(self, request, exception, spider):
pass
打印之前,需要在配置文件settings.py中设置中间件:
# 打开下载中间件
DOWNLOADER_MIDDLEWARES = {
'middlePro.middlewares.MiddleproDownloaderMiddleware': 543,
}

管道也打开。但这里先不设置UA和ROBOTSTXT_OBEY = True。
运行下:
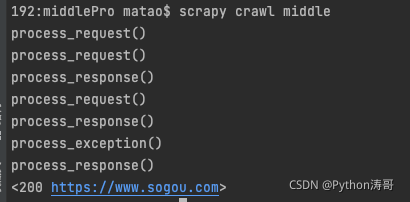
我们看到网页被请求中间件和响应中间件正常拦截了(不然不会打印)。其中搜狗没有异常拦截,百度有异常拦截。
我们设置ROBOTSTXT_OBEY = False,再去运行下:

这时,因为我们忽略了robots协议,就都没有异常拦截了
举例:
process_exception:
# 代理的话,需要写在process_exception方法中
def process_exception(self, request, exception, spider):
# 请求的ip被禁掉,该请求就会变成一个异常单 请求
# request.meta['proxy']='http://ip:port' # 设置代理
print('process_exception()')
return request # 将异常单 请求修正后将其进行重新发送
process_response:
def process_response(self, request, response, spider):
print('process_response()')
# 请求头伪装,一般不用,只是举例
request.headers['User-Agent']='xxx'
request.headers['Cookie'] = 'xxx'
return response