1、数据的可分析度
我们需要判断这个数据的分析是否是有价值的,在可分析度方面,需要一些判断的维度,主要是企业数据量、数据复杂度还有数据颗粒度。
数据量比较大的、复杂度比较高的、颗粒度比较细的数据,就有比较高的分析和利用价值。衡量数据复杂度我们应该看剔除相关性之后的列数;数据的颗粒度越细越好,有了细颗粒度的数据,我们就可以自行组合成颗粒度比较“粗”的数据,就比如知道了全国各个区的GDP数据,我们就可以推算出市、省、全国的数据,但是反向的操作无法实现。
2、重复数据删除
第一种方法Excel中“删除重复项”

选择判断是否重复的项

如果编号和成绩都相同、都重复了,那么就是重复值

第二种方法:高级筛选

“选择不重复的记录”

可以看到在D1-E31显示了删除重复值后的结果

第三种方法:使用SPSS
数据->标识重复个案
 设置如下
设置如下
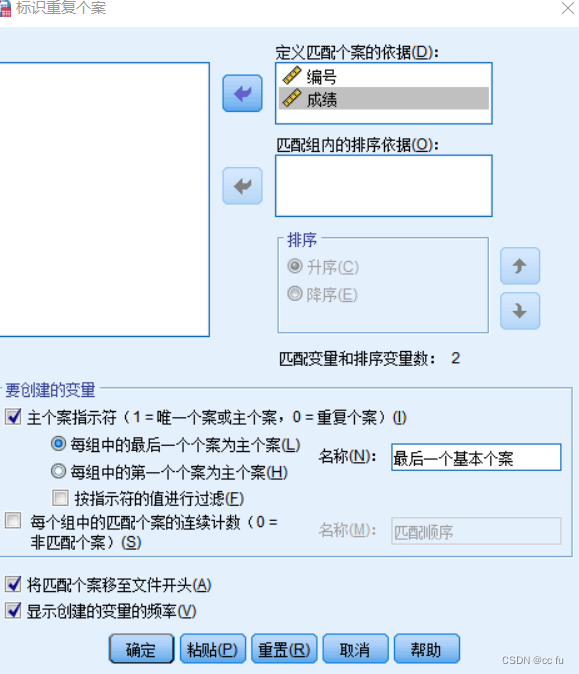
可以看到显示的结果如下,1=唯一个案或主个案,0=重复个案


3、删除空行
先进行排序

可以删除空行了
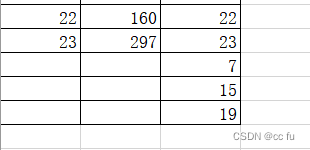
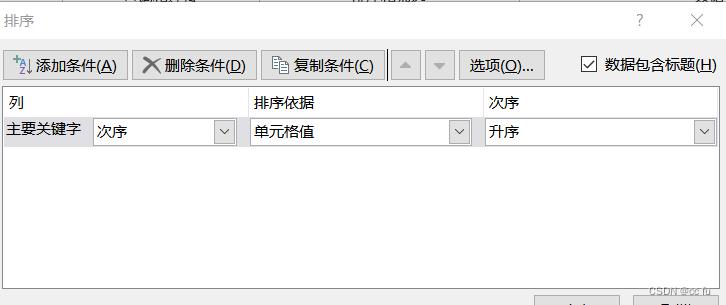
不打乱数据的排序对空行进行删除,使用辅助列的方法,添加次序,然后第一步按照编号进行排序,删除空行之后再按照次序进行排序就行
4、缺失值的填充和分析
第一种方法使用手工填充,我们可以使用平均值进行填充,在Excel里面直接使用average函数就行
第二种方法使用SPSS“替换缺失值”进行填充

有多种方法可以选择,通常选择序列缺失值

可以看到结果对比

缺失值分析
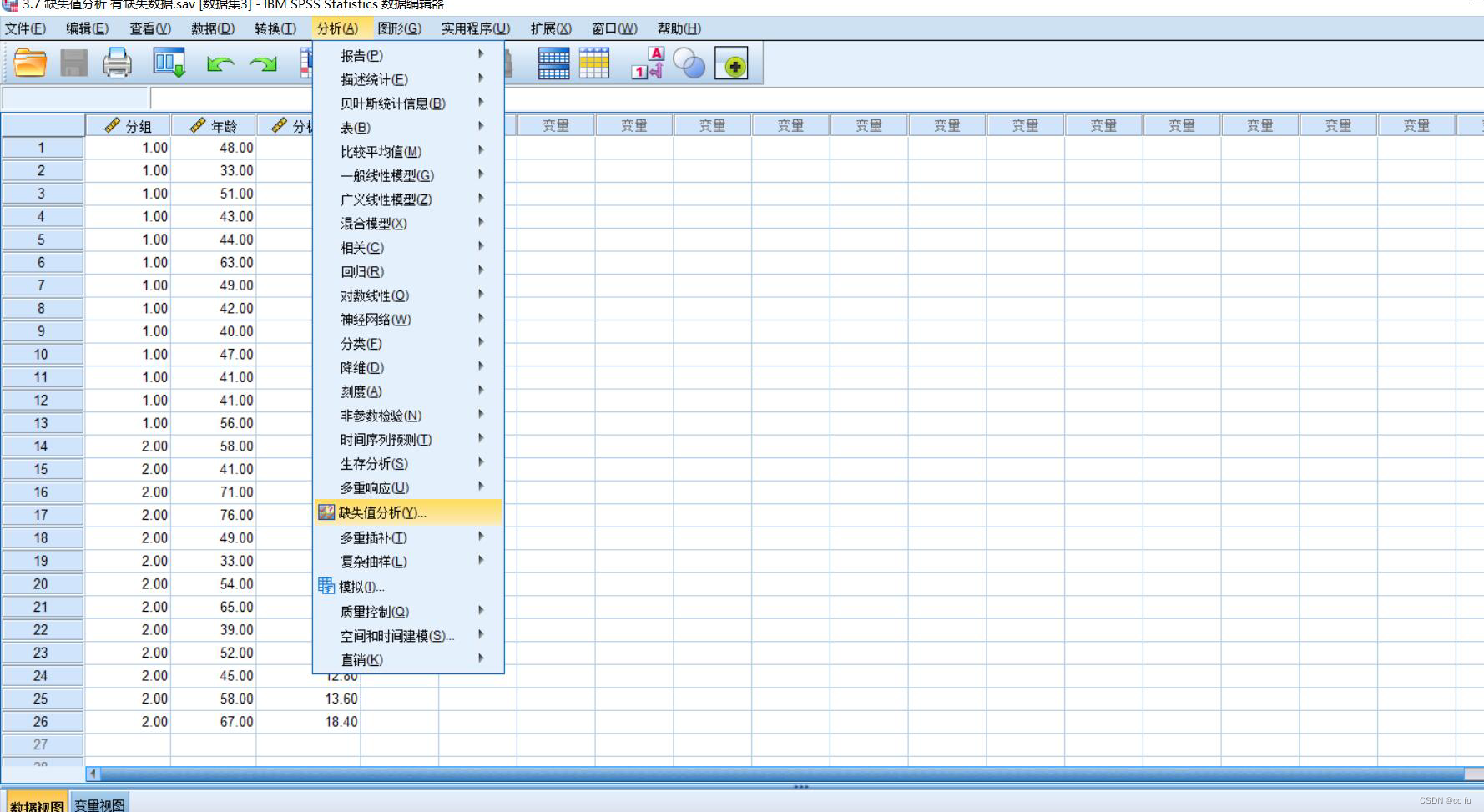
分析指标选择

选择EM,点击下方EM...进入设置

可以看到新数据集f

5、SPSS处理大数据量
使用SPSS打开两个数据超过60万条的文件

 在打开的第一个数据中点击合并文件->添加个案
在打开的第一个数据中点击合并文件->添加个案

选择第二个数据集进行合并

添加要合并的变量
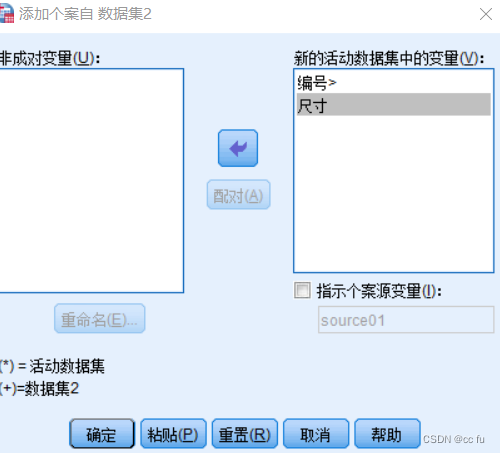
对合并之后的数据集进行分析,点击描述统计->描述

点击变量尺寸

我们可以看到结果N=1378832,已经超过Excel的最大最大容量。

6、数据抽样
SPSS打开文件,在数据主标签中选择“选择个案”

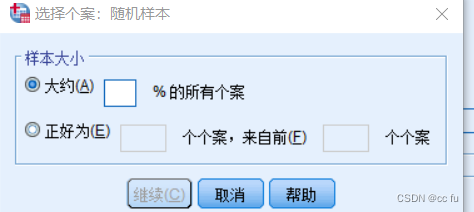
点击随机个案样本,也可以根据要求选择别的

点击样本,选择要抽取的样本大小
在Excel中进行数据抽样可以使用函数randbetween,比如要500个随机数,即randbetween(1,500)。