一1,Solr环境安装
1、安装Jdk1.8(solr6.6是 1.8编译的) / Tomcat8 / Solr6.6 各软件
2、 下载 : 下载 solr 6.6 版本:http://www.apache.org/dyn/closer.lua/lucene/solr/6.6.0
3、将 solr 压缩包中 solr 6.6 下的server\solr-webapp\文件夹下有个webapp文件夹,将之复制到Tomcat\webapps\目录下,并改成solr (名字随意,通过浏览器进行访问solr管理界面时要用到)
4、将 solr 压缩包中 solr 6.6\server\lib\ext 中的 jar 全部复制到 Tomcat\ webapps\solr\WEB-INF\lib 目录中, solr 6.6\server\lib\中以metrics开头的jar复制到 Tomcat\ webapps\solr\WEB-INF\lib 中
5、将 solr 压缩包中 solr 6.6/ server/resources /log4j.properties 复制到Tomcat\ webapps\solr\WEB-INF\lib 目录中
6、将 solr 压缩包中 solr 6.6/server/solr/ 目录下的solr.xml,zoo.cfg,README.txt复制到计算机某个目录下,如D:\solr_home
在solr_home目录下新建一个文件建solr_core,
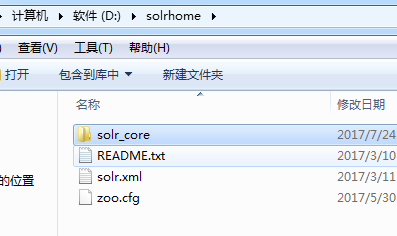
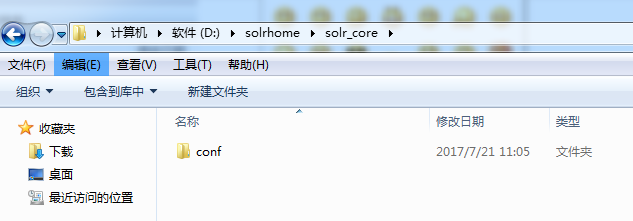
将 solr 压缩包中 solr 6.6/server/solr/ configsets/basic_configs目录下conf目录复制到复制到上一步新建的文件solr_core内 即:D:\solr_home\solr_core
7、打开Tomcat/webapps/solr/WEB-INF下的web.xml,找到如下配置内容(初始状态下该内容是被注释掉的):
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/put/your/solr/home/here</env-entry-value>
<env-entry-type>Java.lang.String</env-entry-type>
</env-entry>
将<env-entry-value>中的内容改成你的solr_home路径,这里是D:/solr_home
注释权限控制
- <!--
- <security-constraint>
- <web-resource-collection>
- <web-resource-name>Disable TRACE</web-resource-name>
- <url-pattern>/</url-pattern>
- <http-method>TRACE</http-method>
- </web-resource-collection>
- <auth-constraint/>
- </security-constraint>
- <security-constraint>
- <web-resource-collection>
- <web-resource-name>Enable everything but TRACE</web-resource-name>
- <url-pattern>/</url-pattern>
- <http-method-omission>TRACE</http-method-omission>
- </web-resource-collection>
- </security-constraint>
- -->
8、保存关闭,而后启动tomcat,我这里改的是8081的端口,所以在浏览器输入http://localhost:8080/solr/index.html即可出现Solr的管理界面如下:

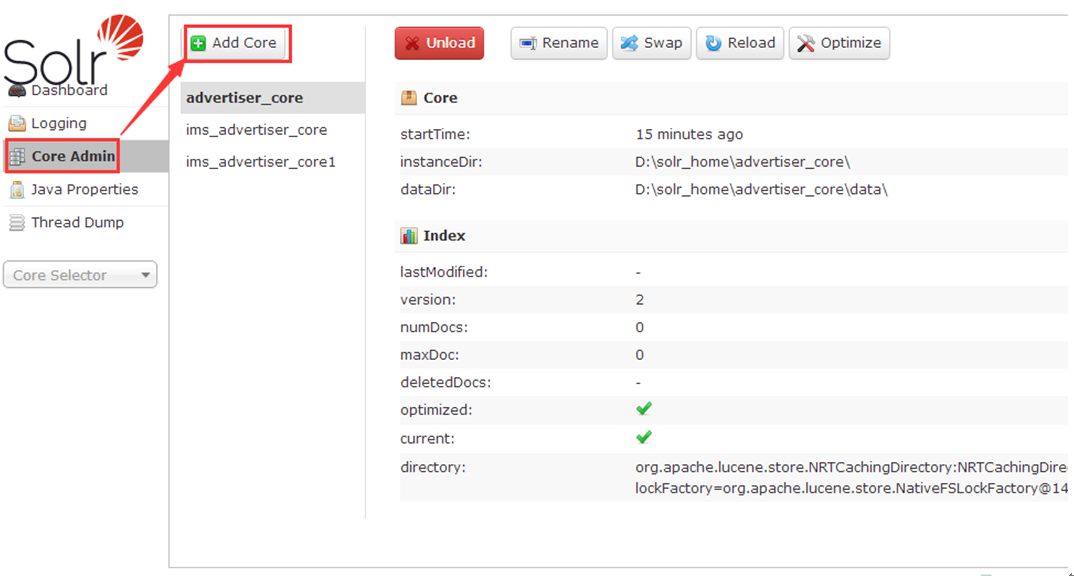
2 coreAdmin 管理
主要有Add Core(添加核心), Unload(卸载核心),Rename(重命名核心),Reload(重新加载核心),Optimize(优化索引库)
Add Core是添加core:
1 新建文件夹:将 solr 压缩包中 solr 6.6/server/solr/ configsets/basic_configs目录下conf目录复制到复制到上一步新建的文件solr_core内 即:D:\solr_home\solrname
2 在操作界面上直接按照选项确定add core即可。
主要是在instanceDir对应的文件夹里生成一个core.properties文件
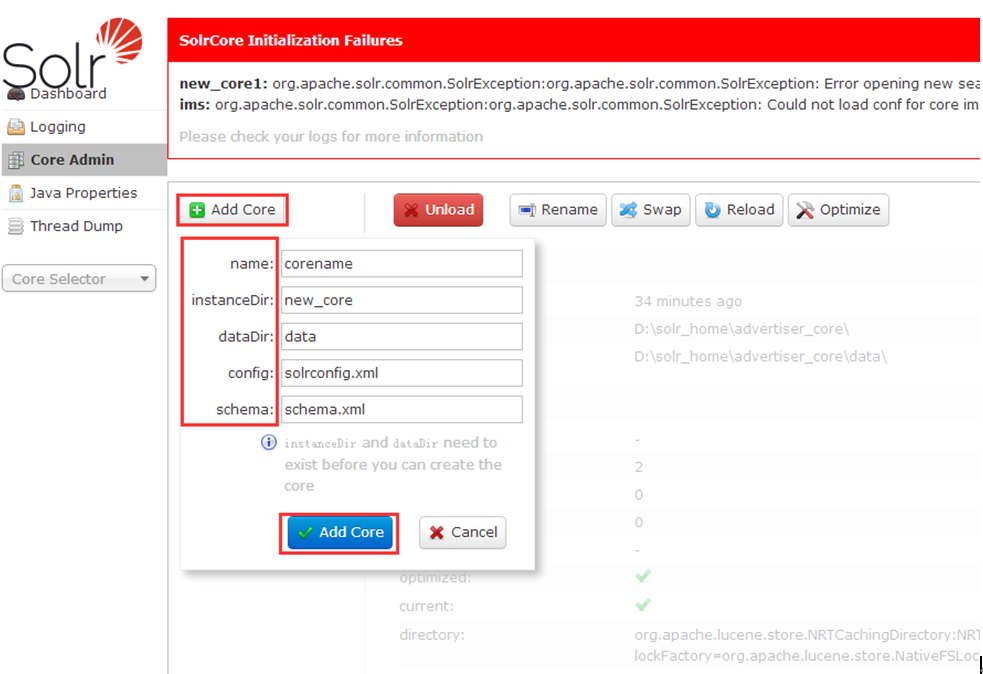
name:给core起的名字;
instanceDir:与我们在配置solr到tomcat里时的solr_home里新建的core文件夹名一致;
dataDir:确认Add Core时,会在new_core目录下生成名为data的文件夹
config:new_core下的conf下的config配置文件(solrconfig.xml)
schema: new_core下的conf下的schema文件(schema.xml)
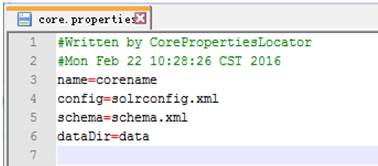
确认Add Core时,会在new_core下生成data文件夹,与core.properties文件。core.properties文件里内容如下:
2 solr管理界面介绍
原文地址:http://blog.csdn.net/zcl_love_wx/article/details/52092098
solr 服务器管理界面可以查看系统状态、solr设置、分词检测、查询索引、增减core、查看日志等
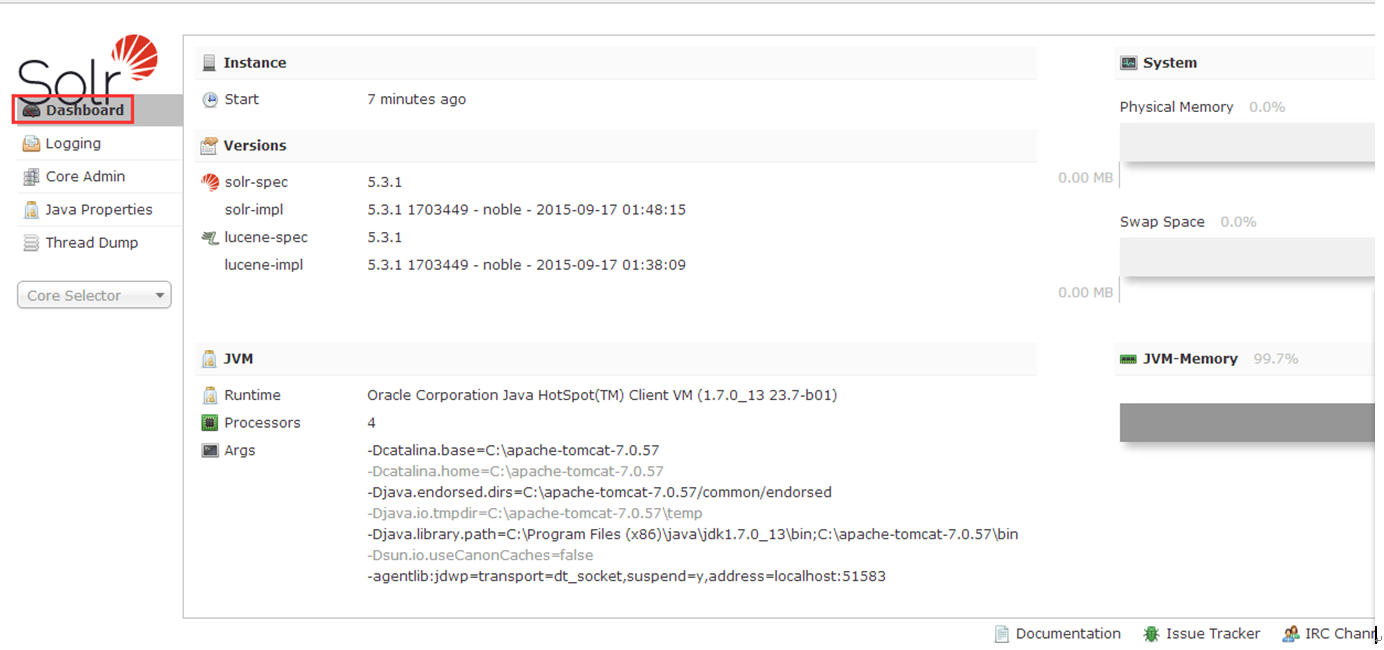
1.Dashboard(仪表盘)
访问http://localhost:8080/solr时,出现该主页面,可查看到solr运行时间、solr版本,系统内存、虚拟机内存的使用情况
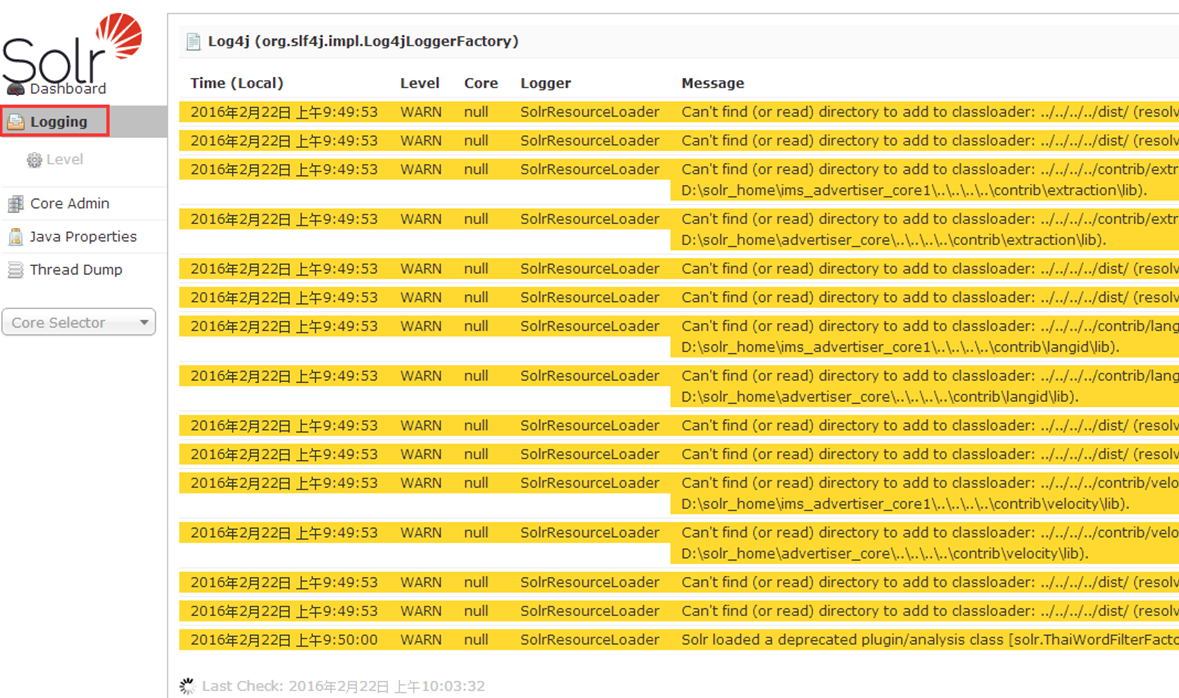
2.Logging(日志)
显示solr运行出现的异常或错误
3.Core Admin (core管理)
主要有Add Core(添加核心), Unload(卸载核心),Rename(重命名核心),Reload(重新加载核心),Optimize(优化索引库)
Add Core是添加core:主要是在instanceDir对应的文件夹里生成一个core.properties文件
name:给core起的名字;
instanceDir:与我们在配置solr到tomcat里时的solr_home里新建的core文件夹名一致;
dataDir:确认Add Core时,会在new_core目录下生成名为data的文件夹
config:new_core下的conf下的config配置文件(solrconfig.xml)
schema: new_core下的conf下的schema文件(schema.xml)
确认Add Core时,会在new_core下生成data文件夹,与core.properties文件。core.properties文件里内容如下:
4.Java Properties
可查看到java相关的一些属性的信息
5. Core Selecter(core选择器)
需要在Core Admin里添加了core后才有可选项,这里以已经添加好的ims_advertiser_core为例。
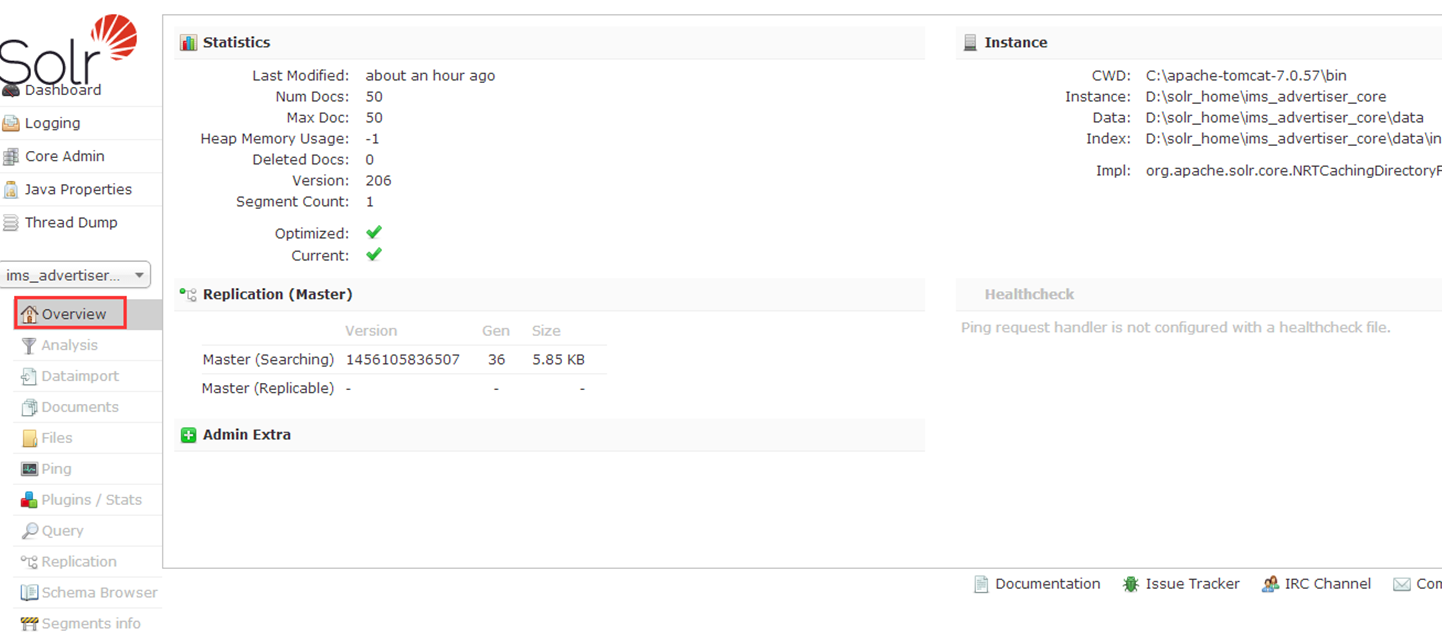
5.1 overview(概览)
包含基本统计如当前文档数;和实例信息如当前核心的配置目录;
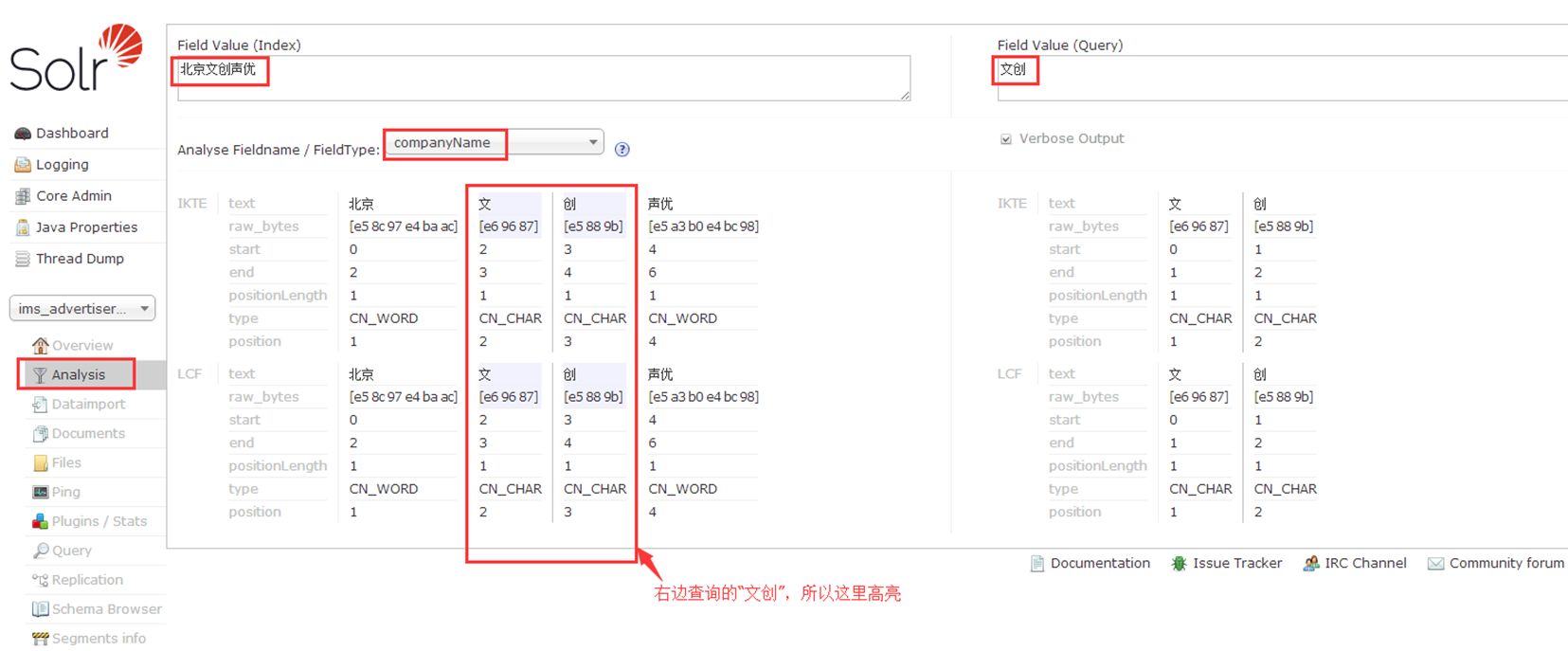
5.2 Analysis(分析)
检验分词效果,如图,我们对companyName字段进行了分词 ( 至于哪些字段能分词,取决于在schema.xml文件里配置该字段时的type是否为配置的分词器类型text_ik)
<field name="companyName" type="text_ik" indexed="false" stored="true" multiValued="false" />
//这里的text_ik就是下面name属性的值
<!-- 配置IK分词器start -->
<fieldType name="text_ik" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" isMaxWordLength="false"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里的高亮就是背景色是灰色
5.3 Dataimport(从数据库导入数据)
前提是已经配置好了相关的配置,详情参见:Solr从数据库导入数据
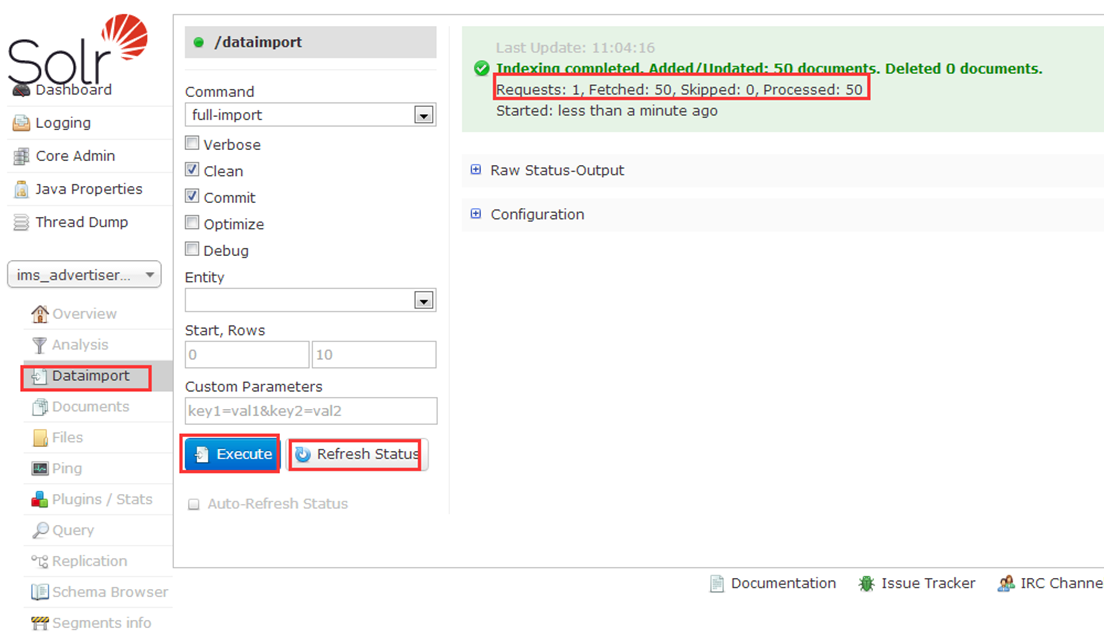
Comman选项:full_import:全导入;delta_import:增量导入。
所谓delta-import主要是对于数据库(也可能是文件等等)中增加或者被修改的字段进行导入。主要原理是利用率每次我们进行import的时候在solr.home\conf下面生成的dataimport.properties文件,此文件里面有最近一次导入的相关信息。这个文件如下:
#Tue Jul 19 10:15:50 CST 2016
advertiser.last_index_time=2016-07-19 10:15:49
last_index_time=2016-07-19 10:15:49
其实last_index_time是最近一次索引(full-import或者delta-import)的时间。
通过比较这个时间和我们数据库表中的timestamp列即可得出哪些是之后修改或者添加的。
Verbose:
Clean: 在索引开始构建之前是否删除之前的索引,默认为true
Commit: 在索引完成之后是否提交。默认为true
Optimize: 是否在索引完成之后对索引进行优化。默认为true
Debug: 是否以调试模式运行,适用于交互式开发(interactive development mode)之中。
请注意,如果以调试模式运行,那么默认不会自动提交,请加参数“commit=true”
Entity: entity是document下面的标签(data-config.xml)。使用这个参数可以有选择的执行一个或多个entity 。使用多个entity参数可以使得多个entity同时运行。如果不选择此参数那么所有的都会被运行。
Start,Rows:
Custom Parameters:
Excute:执行导入。
Refresh Status:刷新后才能看到数据发生了变化,如果刷新后数据还是0,说明未导入。
5.4 Documents
Documents (索引文档)索引的相关操作,如:增加,修改,删除等,例如我们要增加一个索引(companyName)的办法:
a. 先要在solr 的D:\solr_home\mycore1\conf 的 schema.xml配置文件下,增加相关的字段field
<field name="companyName" type="text_ik" indexed="false" stored="true" multiValued="false" />
否则会出现如下错误:
Status: error
Error: Bad Request
Error:
{
"responseHeader": {
"status": 400,
"QTime": 1
},
"error": {
"msg": "ERROR: [doc=126] unknown field 'companyName'",
"code": 400
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
b. 在如下页面,选择/update ,文档格式选择json ,然后submit 提交。这样 索引就增加上了。修改与增加一样,都是/update ,删除为/delete 。
成功之后,我们去query里查询数据就能查到我们刚添加的数据.
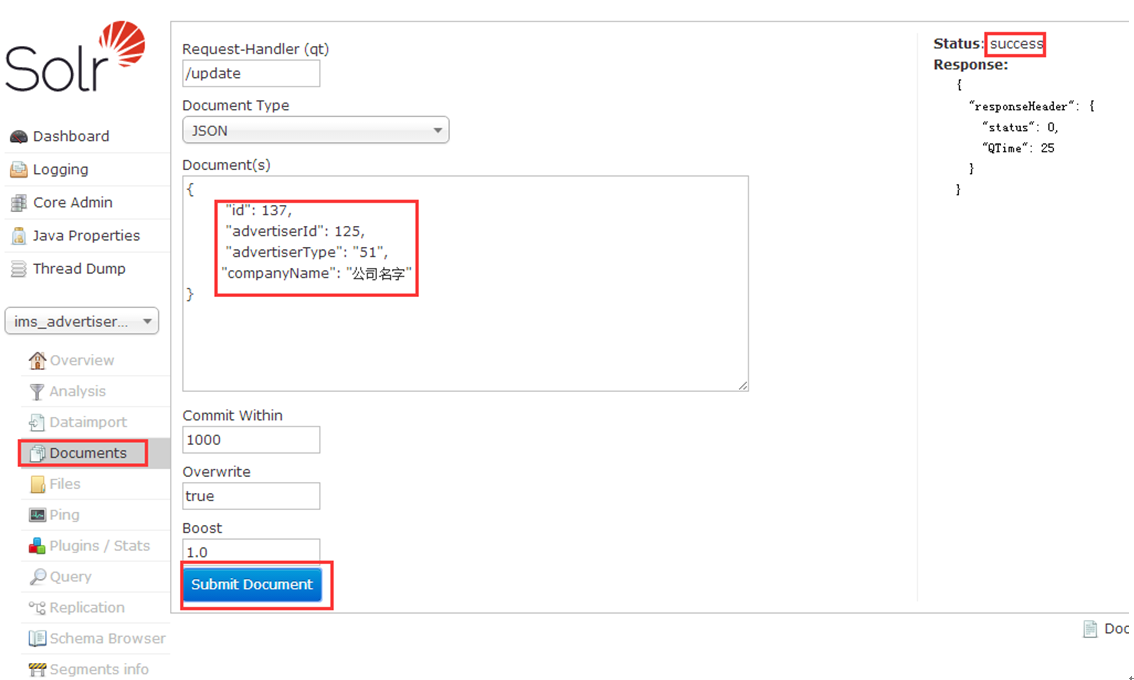
Request-Handler(qt): 要进行的操作(update\delete)
Document Type:类型,有JSON、XML等格式
Document(s): 内容,手动写的内容。
Commit Within:
Overwrite: 为true,说明如果id重复则覆盖以前的值;为false说明如果id重复不覆盖以前的值.
Boost: 好像是什么版本,没用过
5.5 Files文件夹
solr_home下的core下的conf下的相关文件,可单击查看里面的内容.
5.6 Query(查询页面),查询的结果要显示哪个字段,就得将schema.xml文件配置字段时的stored属性设为true.
查询索引的文档,包含是否存在,排序是否正确等
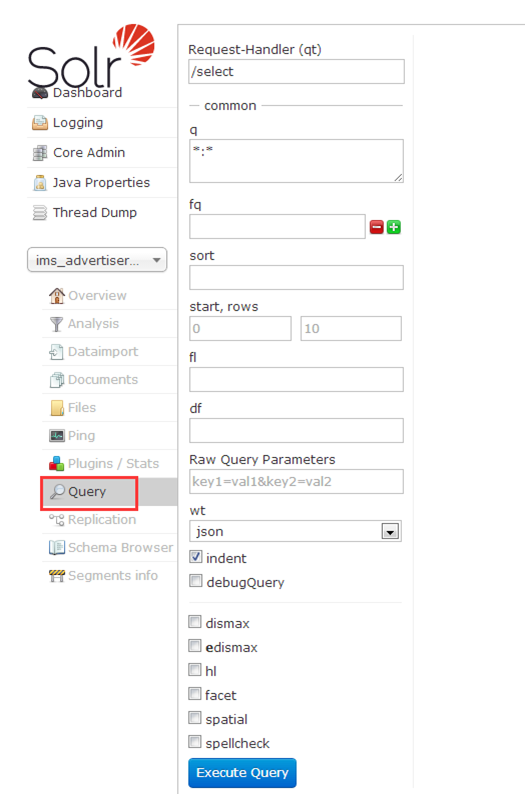
进入该页面后,直接点击Execute Query时,在右侧会生查回数据:
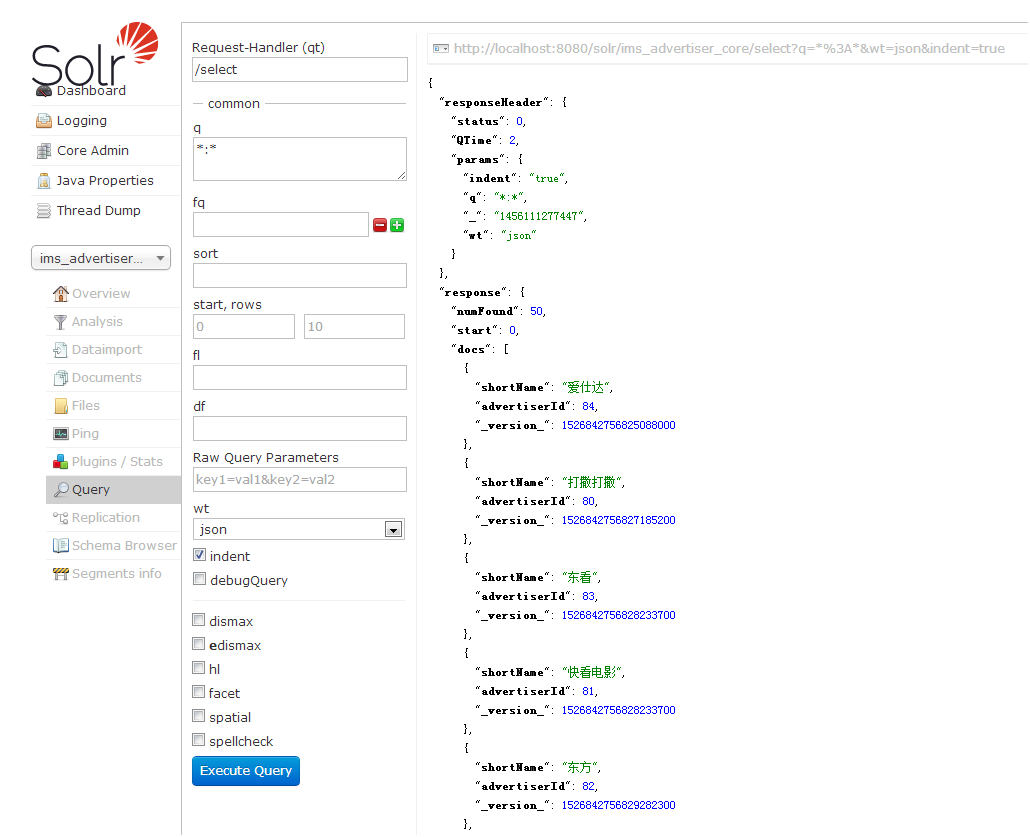
Request-Handler(qt):
q: 查询字符串(必须的)。:表示查询所有;keyword:东看 表示按关键字“东看”查询
fq: filter query 过滤查询。使用Filter Query可以充分利用Filter Query Cache,提高检索性能。作用:在q查询符合结果中同时是fq查询符合的(类似求交集),例如:q=mm&fq=date_time:[20081001 TO 20091031],找关键字mm,并且date_time是20081001到20091031之间的。
sort: 排序。格式如下:字段名 排序方式;如advertiserId desc 表示按id字段降序排列查询结果。
start,rows:表示查回结果从第几条数据开始显示,共显示多少条。
fl: field list。指定查询结果返回哪些字段。多个时以空格“ ”或逗号“,”分隔。不指定时,默认全返回。
df: default field默认的查询字段,一般默认指定。
Raw Query Parameters:
wt: write type。指定查询输出结果格式,我们常用的有json格式与xml格式。在solrconfig.xml中定义了查询输出格式:xml、json、python、ruby、php、phps、custom。
indent: 返回的结果是否缩进,默认关闭,用 indent=true | on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
debugQuery: 设置返回结果是否显示Debug信息。
dismax:
edismax:
hl: high light 高亮。hl=true表示启用高亮
hl.fl : 用空格或逗号隔开的字段列表(指定高亮的字段)。要启用某个字段的highlight功能,就得保证该字段在schema中是stored。如果该参数未被给出,那么就会高 亮默认字段 standard handler会用df参数,dismax字段用qf参数。你可以使用星号去方便的高亮所有字段。如果你使用了通配符,那么要考虑启用 hl.requiredFieldMatch选项。
hl.simple.pre:
hl.requireFieldMatch: 如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数。尽管如此,如果你的查询是all字段(可能是使用 copy-field 指令),那么还是把它设为false,这样搜索结果能表明哪个字段的查询文本未被找到
hl.usePhraseHighlighter:如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮。
hl.highlightMultiTerm:如果使用通配符和模糊搜索,那么会确保与通配符匹配的term会高亮。默认为false,同时hl.usePhraseHighlighter要为true。
facet:分组统计,在搜索关键字的同时,能够按照Facet的字段进行分组并统计。
facet.query:Facet Query利用类似于filter query的语法提供了更为灵活的Facet.通过facet.query参数,可以对任意字段进行筛选。
facet.field:需要分组统计的字段,可以多个。
facet.prefix: 表示Facet字段值的前缀。比如facet.field=cpu&facet.prefix=Intel,那么对cpu字段进行Facet查询,返回的cpu都是以Intel开头的, AMD开头的cpu型号将不会被统计在内。
spatial:
spellcheck: 拼写检查。
3 利用java添加文档
代码
/**
* Project Name: solr
* File Name: SolrCoreAdd.java
* Package Name: solruse
* Date: 2018年2月27日下午4:17:59
* All rights Reserved, Designed By MiGu. Copyright: Copyright(C) 2018-2020. Company MiGu Co., Ltd.
*
*/
package solruse;
/**
* Name: SolrCoreAdd <br/>
* Description: TODO ADD Description. <br/>
* Date: 2018年2月27日 下午4:17:59 <br/>
*
* @author Administrator
* @version
* @since JDK 1.8
* @see
*/
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.HttpSolrServer;
import org.apache.solr.common.SolrInputDocument;
import org.slf4j.LoggerFactory;//需要在pom添加spring依赖,spring自带。而不是java自带的。
import ch.qos.logback.classic.Logger;
public class SolrCoreAdd {
private static final Logger LOG=(Logger) LoggerFactory.getLogger(SolrCoreAdd.class);
public static void main(String[] args) throws Exception {
LOG.info("test1");
String serverUrl = "http://localhost:8080/solr/solr_core0"; //易错点,中间没有/index.html
SolrServer solrServer = new HttpSolrServer(serverUrl);
LOG.info("test2");
SolrInputDocument doc1 = new SolrInputDocument();
doc1.setField("id", "solrJTest3");
doc1.setField("ContentCode", "zcl");
doc1.setField("ProvisionCode", "baoweiluobo");
doc1.setField("Topic", "lishi");
solrServer.add(doc1);
LOG.info("test21"); //断点测试之用
SolrInputDocument doc2 = new SolrInputDocument();
doc2.setField("id", "solrJTest4");
doc2.setField("ContentCode", "cxl");
doc2.setField("ProvisionCode", "dazhanjinagshi");
doc2.setField("Topic", "wenxue");
solrServer.add(doc2);
LOG.info("test3");
solrServer.commit(true,true);
LOG.info("test4");
System.out.println("Documents added");
LOG.info("test5");
}
}
pom配置:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.migu</groupId>
<artifactId>solr</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>solr</name>
<description>solr</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.10.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Spring依赖 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.1.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>4.1.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.1.3.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>4.1.3.RELEASE</version>
</dependency>
<!--solr客户端solrj的依赖 -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>4.10.1</version>
</dependency>
<!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>