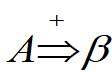自下而上分析方法:从输入串开始,逐步进行规约,直至文法的开始符号。是指根据文法的产生式规则,把产生式的右部替换成左部符号。
因此自上而下分析法的核心问题为识别可规约串。
G是一个文法,S是文法的开始符号,假定 α \alpha α β \beta β δ \delta δ是文法G的一个句型,如果有且 则称 β \beta β是句型 α \alpha α β \beta β δ \delta δ相对于非终结符A的短语。
如果有A⇒ β \beta β,则称 β \beta β是句型 α \alpha α β \beta β δ \delta δ相对于规则A→ β \beta β的直接短语。
一个句型的最左直接短语称为该句型的句柄。
这样一个短语,至少含有一个终结符,并且,除自身之外不再含任何更小的素短语。
处于句型最左边的素短语
在一个句型对应的语法树中,以某非终结符为根的一颗子树的所有叶子自左至右排列起来形成一个相对于子树根的短语。 仅有父子两代的一棵子树,它的所有叶子自左至右排列起来所形成的符号串为直接短语。 语法树中最左那棵只有父子两代的子树的所有叶子的自左至右排列形成的字符串为句柄。
如图所示,将修建语法树的过程倒过来,即得到S⇒aAcBe⇒aAcde⇒aAbcde⇒abbcde,这显然是一个最右推导,规范规约是关于一个最右推导的逆过程。
我们将输入串一一移入至栈中,当栈内形成可规约串时,就进行规约。这种规约可能出现多次,一直归约直至栈顶不再出现可规约串。然后,我们继续向栈内移入符号,直至输入串仅剩 # ,栈内内容变为 #S 。
在上述过程中,分析器共产生4中动作:
在移进规约过程中,可能会出现移进-归约冲突和归约-归约冲突,不同的分析方法有不同的处理冲突的技术。
我们首先对终结符a与b的优先关系进行定义:
此外,算符优先文法句型扩在两个#之间,形如#E#,因此
注:算符优先分析只关心句型中自左向右的终结符序列的优先关系,不涉及终结符之间可能存在的非终结符,因此可以认为这些非终结符是同一个符号。
优点:能用LL(1)分析法分析的所有文法都能使用LR分析法来进行分析。 LR分析法在自左至右扫描输入串的过程中能发现其中的任何错误,并能准确指出出错位置。 缺点:手工构造分析表工作量太大,需使用自动生成器。
LR分析法通过求句柄逐步归约进行语法分析。其中句柄是通过求活前缀而求得。
我们通过下图过程,可以得到:
分析表(分析函数):不同的文法分析表不同,同一个文法采用的LR分析器不同时,分析表也不同,分析表又可分为动作(ACTION)表和状态转换(GOTO)表两个部分,它们都可用二维数组表示。
ACTION[s,a]:当状态s面临输入符号a时,应采取什么动作。 每一项ACTION[s,a]所规定的四种动作:
GOTO[s,X]:状态s面对文法符号X时,下一状态是什么。 对于如下分析表: Si:把当前输入符号移进栈,第i个状态进状态栈。 ri:按第i个产生式进行规约。 i:第i个状态进栈。
对于一个文法,如果能够构造一张分析表,使得它的每个入口均是唯一确定的,则这个文法就称为LR文法。 一个文法,如果能用一个每步顶多向前检查k个输入符号的LR分析器进行分析,则这个文法就称为LR(k)文法。
对于一个文法G,我们可以构造一个有限自动机,它能识别G的所有活前缀。 由于产生式右部的符号就是句柄,若这些符号串都已进栈,则表示它已处于“归态活前缀”,若只有部分进栈,则表示它处于“非归态活前缀”。要想知道活前缀有多大部分进栈了,可以为每个产生式构造一个自动机,由它的状态来记住这些情况,此“状态”称为“项目”。这些自动机的全体就是识别所有活前缀的有限自动机。 构成识别一个文法活前缀的DFA的项目集(状态)的全体称为文法的LR(0)项目集规范族。
由于以下结论,我们可以构建一个项目闭包,避免需要将NFA确定化。
当发生移进-规约冲突时,如果出现以下情况:
按上述方法构造出的ACTION与GOTO表如果不含多重入口,则称该文法为SLR(1)文法。 使用SLR表的分析器叫做一个SLR分析器。 每个SLR(1)文法都是无二义的。但也存在许多无二义文法不是SLR(1)的。
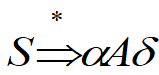 且
且