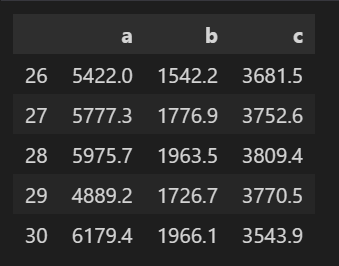
首先假设有 n 个样本,p 个特征,
x
i
j
x_{ij}
xij 表示第i个样本的第 j 个特征,这些样本构成的 n × p 特征矩阵 X 为:
X
=
[
x
11
x
12
⋯
x
1
p
x
21
x
22
⋯
x
2
p
⋮
⋮
⋱
⋮
x
n
1
x
n
2
⋯
x
n
p
]
=
[
x
1
,
x
2
,
⋯
,
x
p
]
X=\begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1p} \\ x_{21} & x_{22} & \cdots & x_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ x_{n1} & x_{n2} & \cdots & x_{np} \\ \end{bmatrix} = [x_1,x_2,\cdots,x_p]
X=⎣⎡x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1px2p⋮xnp⎦⎤=[x1,x2,⋯,xp]
我们的目的是找到一个转换矩阵,将 p 个特征转化为 m 个特征(m < p),从而实现特征降维。即找到一组新的特征 / 变量
z
1
z_1
z1,
z
2
z_2
z2, …,
z
m
z_m
zm(m ≤ p),满足以下式子:
{
z
1
=
l
11
x
1
+
l
12
x
2
+
⋯
+
l
1
p
x
p
z
2
=
l
21
x
1
+
l
22
x
2
+
⋯
+
l
2
p
x
p
⋮
z
m
=
l
m
1
x
1
+
l
m
2
x
2
+
⋯
+
l
m
p
x
p
\begin{cases} \begin{aligned} z_1&=l_{11}x_1+l_{12}x_2+\dots+l_{1p}x_p \\ z_2&=l_{21}x_1+l_{22}x_2+\dots+l_{2p}x_p \\ \vdots \\ z_m&=l_{m1}x_1+l_{m2}x_2+\dots+l_{mp}x_p \end{aligned} \end{cases}
⎩⎨⎧z1z2⋮zm=l11x1+l12x2+⋯+l1pxp=l21x1+l22x2+⋯+l2pxp=lm1x1+lm2x2+⋯+lmpxp
计算每个特征(共p个特征)的均值
x
j
‾
\overline{x_j}
xj 和标准差
S
j
S_j
Sj,公式如下:
x
j
‾
=
1
n
∑
i
=
1
n
x
i
j
\overline{x_j}=\frac{1}{n}\sum_{i=1}^nx_{ij}
xj=n1i=1∑nxij
S
j
=
∑
i
=
1
n
(
x
i
j
−
x
j
‾
)
2
n
−
1
S_j=\sqrt{\frac{\sum_{i=1}^n(x_{ij}-\overline{x_j})^2}{n-1}}
Sj=n−1∑i=1n(xij−xj)2
将每个样本的每个特征进行标准化处理,得到标准化特征矩阵
X
s
t
a
n
d
X_{stand}
Xstand:
X
i
j
=
x
i
j
−
x
j
‾
S
j
X_{ij}=\frac{x_{ij}-\overline{x_j}}{S_j}
Xij=Sjxij−xj
X
s
t
a
n
d
=
[
X
11
X
12
⋯
X
1
p
X
21
X
22
⋯
X
2
p
⋮
⋮
⋱
⋮
X
n
1
X
n
2
⋯
X
n
p
]
=
[
X
1
,
X
2
,
⋯
,
X
p
]
X_{stand}=\begin{bmatrix} X_{11} & X_{12} & \cdots & X_{1p} \\ X_{21} & X_{22} & \cdots & X_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ X_{n1} & X_{n2} & \cdots & X_{np} \\ \end{bmatrix} = [X_1,X_2,\cdots,X_p]
Xstand=⎣⎡X11X21⋮Xn1X12X22⋮Xn2⋯⋯⋱⋯X1pX2p⋮Xnp⎦⎤=[X1,X2,⋯,Xp]
3.2 计算协方差矩阵
协方差矩阵是汇总了所有可能配对的变量间相关性的一个表。
协方差矩阵 R 为:
R
=
[
r
11
r
12
⋯
r
1
p
r
21
r
22
⋯
r
2
p
⋮
⋮
⋱
⋮
r
p
1
r
p
2
⋯
r
p
p
]
R=\begin{bmatrix} r_{11} & r_{12} & \cdots & r_{1p} \\ r_{21} & r_{22} & \cdots & r_{2p} \\ \vdots & \vdots & \ddots & \vdots \\ r_{p1} & r_{p2} & \cdots & r_{pp} \\ \end{bmatrix}
R=⎣⎡r11r21⋮rp1r12r22⋮rp2⋯⋯⋱⋯r1pr2p⋮rpp⎦⎤
r
i
j
=
1
n
−
1
∑
k
=
1
n
(
X
k
i
−
X
i
‾
)
(
X
k
j
−
X
j
‾
)
=
1
n
−
1
∑
k
=
1
n
X
k
i
X
k
j
\begin{aligned} r_{ij}&=\frac{1}{n-1}\sum_{k=1}^n(X_{ki}-\overline{X_i})(X_{kj}-\overline{X_j})\\ &=\frac{1}{n-1}\sum_{k=1}^nX_{ki}X_{kj} \end{aligned}
rij=n−11k=1∑n(Xki−Xi)(Xkj−Xj)=n−11k=1∑nXkiXkj
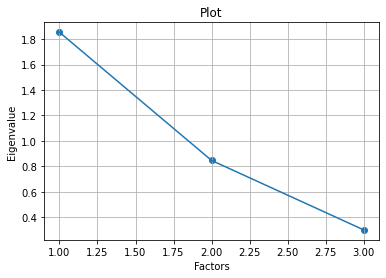
3.3 计算特征值和特征值向量
计算矩阵R的特征值,并按照大小顺序排列,计算对应的特征向量,并进行标准化,使其长度为1。R是半正定矩阵,且
t
r
(
R
)
=
∑
k
=
1
p
λ
k
=
p
tr(R) = \sum_{k=1}^p\lambda_k = p
tr(R)=∑k=1pλk=p。
特征向量:
L
1
=
[
l
11
,
l
12
,
…
,
l
1
p
]
T
…
L
p
=
[
l
p
1
,
l
p
2
,
…
,
l
p
p
]
T
L_1=[l_{11},l_{12},\dots ,l_{1p}]^T \dots L_p=[l_{p1},l_{p2},\dots ,l_{pp}]^T
L1=[l11,l12,…,l1p]T…Lp=[lp1,lp2,…,lpp]T
第 i 个主成分的贡献率为:
λ
i
∑
k
=
1
p
λ
k
\frac{\lambda_i}{\sum_{k=1}^p\lambda_k}
∑k=1pλkλi
前 i 个主成分的累计贡献率为:
∑
j
=
1
i
λ
j
∑
k
=
1
p
λ
k
\frac{\sum_{j=1}^i\lambda_j}{\sum_{k=1}^p\lambda_k}
∑k=1pλk∑j=1iλj
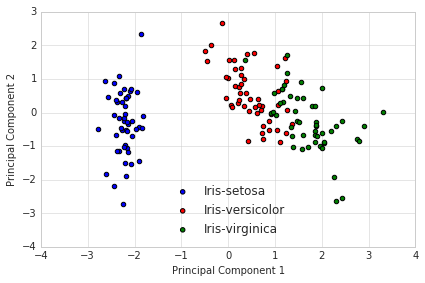
3.6 选取和表示主成分
一般取累计贡献率超过80%的特征值所对应的第一、第二、…、第m(m ≤ p)个主成分。Fi表示第i个主成分:
F
i
=
l
i
1
X
1
+
l
i
2
X
2
+
⋯
+
l
i
p
X
p
,
(
i
=
1
,
2
,
…
,
p
)
F_i=l_{i1}X_1+l_{i2}X_2+\dots+l_{ip}X_p,(i=1,2,\dots,p)
Fi=li1X1+li2X2+⋯+lipXp,(i=1,2,…,p)
3.7 系数的简单分析
对于某个主成分而言,指标前面的系数越大(即
l
i
j
l_{ij}
lij),代表该指标对于该主成分的影响越大。
##Python实现PCAimport numpy as np
defpca(X,k):#k is the components you want#mean of each feature
n_samples, n_features = X.shape
mean=np.array([np.mean(X[:,i])for i inrange(n_features)])#normalization
norm_X=X-mean
#scatter matrix
scatter_matrix=np.dot(np.transpose(norm_X),norm_X)#Calculate the eigenvectors and eigenvalues
eig_val, eig_vec = np.linalg.eig(scatter_matrix)
eig_pairs =[(np.abs(eig_val[i]), eig_vec[:,i])for i inrange(n_features)]# sort eig_vec based on eig_val from highest to lowest
eig_pairs.sort(reverse=True)# select the top k eig_vec
feature=np.array([ele[1]for ele in eig_pairs[:k]])#get new data
data = np.dot(norm_X,np.transpose(feature))return data
X = np.array([[-1,1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])print(pca(X,1))
(2)sklearn的PCA
##用sklearn的PCAfrom sklearn.decomposition import PCA
import numpy as np
X = np.array([[-1,1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
pca = PCA(n_components=1)pca.fit(X)print(pca.transform(X))