
提出稀疏架构是为了打破具有密集架构的DNN模型中模型大小和计算成本之间的连贯关系的——最著名的MoE。
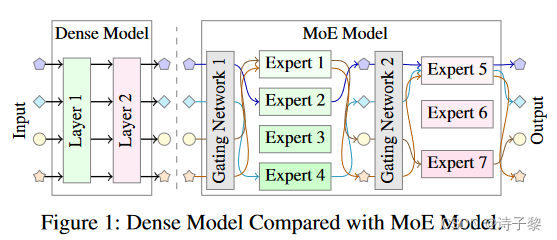
MoE模型将传统训练模型中的layer换成了多个expert sub-networks,对每个输入,都有一层special gating network 来将其分配到最适合它的expert中,然后被expert处理。于此对应,很多expert会不得不处理多个输入,但另一些则几乎不处理输入——data-sensitive (数据敏感的)
但现有的并行方法无法解决MoE遇到的问题,有以下两个原因:
Limited Optimization Space
当前工作并没有充分利用MoE模型的不同expert工作负载的差异,并且甚至假设子网络上的工作负载是相同的,从而排除了很多优化空间。
Large Searching Overhead
我没看懂这段对应的话与这个题目有什么关系。
然后提出了SMARTMoE – an automatic parallelization training system for sparsely activated models.
(稀疏激活模型的自动并行化训练系统)。
内容
模型基于两步:
static pool:基于离线构建的可相互转换的并行策略组成的静态池
dynamic adaption 动态自适应:运行时在构建的池内进行快速动态自适应 在线
两者结合来选择适合当前工作负载的策略。
2 Background and Motivation
MoE:Misture-of-Experts
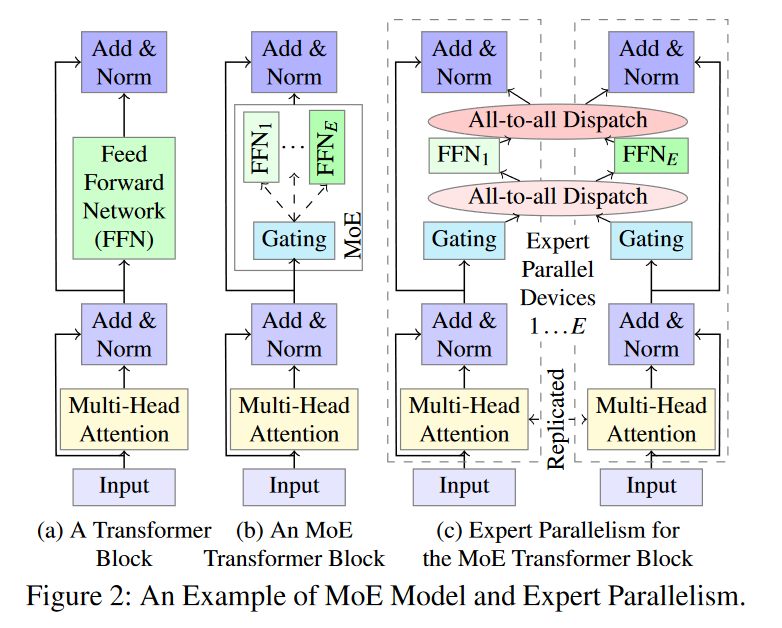
FFN为MoE模型中的专家,多个FFN和一个Gating组成了基本的MoE模型。
2.2 混合和自动并行化
训练密集型深度学习网络的常见的三种并行方式:
Data Parallelism(DP)
每个worker均存储一个完整的参数副本,分配给每个worker的训练样本都不同,并且前向传播和反向传播是在每个worker上独立完成的, then gradients on different workers will be aggregated before being used in the optimization of the model.
disadvantages: 由于参数需要在每个workder中同步和复制,因此会造成内存浪费和communication overhead.
Pipeline Model Parallelism(PP)
参见之前的DSP的文章,就用的PP这个思路:将训练过程分为多个阶段:Sampling,loading and training。
然后每个worker负责一个,会导致communication过程的时间花销变大。
Tensor Model Parallelism(TP)
张量模型并行(Tensor Model Parallelism,TP)是一种人工智能领域的技术。模型的单个运算符被分割成多个工作节点(workers)。每个工作节点存储运算符参数的一部分,并执行其中一部分的计算,例如矩阵的一个瓦片(tile)。不同运算符的TP需要由专家专门设计,分割方法对分布式训练性能至关重要。Megatron [35] 提供了在Transformer模型上使用TP的最佳实践。其他研究[36, 38]探讨了TP的统一表示和最高效分割的自动生成。
最后,总结了任何自动并行化训练系统的三个关键挑战:
- Space of Hybrid Parallelism(混合并行空间)
不同策略的混合使用可能会带来适应的问题
- Performance Modeling 性能建模
性能建模有助于有效探索巨大的混合并行空间。
- Searching Algorithm 搜索算法
因为搜索空间巨大,因此要找一个好的搜索算法。
2.3 Challenges of Automatic Parallelization for MoE Models
用下图解释自动并行MoE模型的挑战性:

- 更大的混合并行空间。
因为模型要额外考虑不同expert之间的组合差异,如E0与E1组合还是E0与E3组合。(一个MoE layer 有四个expert)
- 工作负载感知性能建模
传统的性能建模方式仅使用模型结构和硬件信息来估计性能,缺乏对工作负载的考虑。因为在上图中,上下两个工作负载使得同一个方案出现了效率上的差异。
- 自适应动态并行化
由于MoE训练过程会出现不同工作负载,因此我们需要自适应自动并行化,该方法采用运行时执行方案搜索和切换来保持训练过程高效率。训练系统可以在每次迭代时更新执行计划,以实现最终的高性能。
3 Overview——SmartMoE
以往的自动并行系统仅在训练前搜索最佳执行计划。SmartMoE则采用两阶段方法:
他们使用了更大的混合并行空间来搜索最优执行计划,并且把自动并行过程分为了两阶段:offline and online,具体见图4:

阶段1:offline pool construction
SmartMoE将一些执行计划划分为一个聚类,作为一个pool(一共就构建这一个),他们彼此之间进行切换的代价适中。该模型会在训练之前构建一个较好的pool,并使其保持在线适应能力。
怎么构建?设计了一个数据敏感的性能模型,利用模型规范来估计工作负载,然后再借助传统的搜索算法在运行前就划分出良好的pool。
此处为为池子选择合适的并行策略组合。
阶段2:online adaptive parallelization
阶段1使得在SmartMoE模型进行训练之前就找到一个良好的pool,但这个pool往往很大,在具体训练时候我们需要再极短的时间内在pool中选择出合适的execution plan(执行方案)。因此作者开发了轻量级算法来完成这个任务。
此处为:pool中给定的并行策略组合,expert placement有多种方案,在在线阶段,依据工作负载的不同,切换合适的expert placement。
4
SmartMoE支持混合并行:支持任意的 数据和张量,管道和expert并行,此外还支持expert placement(专家分布)
expert placement:通常指的是将具有不同领域知识和技能的专家(此处专家通常指具有特定领域知识或技能的实体,可以是机器学习模型、算法、软件程序,较少指人类专家等)或者算法分配到合适的任务或者问题上,以最大程度地发挥其潜力和效率。
SmartMoE使用“expert slot”概念来支持现有并行性的任意组合。专家槽为worker上存储专家子网络参数的基本单元。
"Expert slot"是一种在自然语言处理中使用的概念。它是指一个特定的语言模型中,专门用于识别特定类型的实体或信息的插槽。例如,一个旅游应用程序可能会使用一个专家插槽来识别用户输入中的日期、地点、酒店名称等信息。这些插槽可以帮助应用程序更好地理解用户的意图,并提供更准确的响应。
此处使用三个属性来表示专家槽的配置:
- 每个槽位的容量(Capacity):一个0到1的分数,表示存储了专家子网络的多少
- 每个worker上专家槽的数量(Slots):应该为正数。
- 每个worker上MoE层的数量(Layers)。
举例:假设有一个模型,有
L
L
L层MoE层,每层MoE层有
E
E
E个专家,训练在一个有
N
N
N个worker的集群上,
D
、
T
、
P
D、T、P
D、T、P分别代表数据,张量和管道并行方式,则表1展示了如何为不同的并行策略设置属性:

具体实例:
(
L
,
E
,
N
)
=
(
2
,
4
,
4
)
(L, E, N) = (2, 4, 4)
(L,E,N)=(2,4,4) ,两个MoE层,每层有4个专家,在有4个worker的集群上训练。

- EP:expert parallelism:专家并行:同时运行多个专家或者算法,每个专家或算法都负责处理任务的一部分,并在某种程度上独立工作。比如:在分布式计算中,多个计算节点(worker)可以并行地运行不同的任务,每个节点都具有一定的专业知识或者算法来处理特定类型的数据或问题。
- TP:task parallelism任务并行:任务并行是将一个大任务分解成多个较小的子任务,然后并行执行这些子任务的策略。每个子任务可以在不同的处理器核心、线程或计算节点上执行。这种并行策略特别适用于处理大规模数据集或执行多步骤的计算任务。此处应该指上文的Tensor Model parallelism
- DP:data parallelism数据并行:数据并行是将相同的操作应用于多个数据元素的并行策略。通常,多个处理单元会同时处理不同的数据元素,以加速数据处理过程。这种策略常见于并行计算中,如图像处理、矩阵运算等领域。
- PP:pipeline parallelism管道并行:管道并行是将一个任务分成多个阶段,每个阶段由不同的处理单元并行执行。每个处理单元完成其特定阶段的任务,然后将结果传递给下一个处理单元。这种策略通常用于流式数据处理,如编译器优化、音频处理和图像处理。
expert placement plan 指的是从专家子网络到专家槽的一个映射,如图5中的(d),专家槽中指明了设备A,C和则个紫色专家,图则说明了他们的3中不同分布方法。
5 offline pool constrution
5.1 design principle of a pool
- pool产生于训练之前,借助性能模型来完成pool的划分
- pool在整个训练过程中保持不变,在训练时在这个pool中切换执行计划
在SmartMoE中,作者将pool定义为一组执行计划,其中expert placement(这本质上是一种expert到设备dev的映射,即哪些专家放在哪些设备上)是唯一可变的并行策略。
SmartMoE在离线池构建阶段,寻找典型并行策略的优秀组合,在线阶段,再进行组合内部专家分布计划的切换。
优点
1: 灵活性高
2: 切换执行方案时候开销小。因为不同方案仅体现为expert placement的不同,他们具有相同的expert slot,切换时无需内存的变动,而仅需worker之间进行参数交换。
5.2 工作负载感知的性能模型 Workload-Aware Performance Modeling
**性能模型使得在训练之前就能评估不同pool的性能,**但动态工作负载使得我们在实际运行之前无法得知。
因此要估计训练工作量:在训练之前估计专家选择的输出,具体来说,是估计门控(gating)网络(见下图2)的输出。
然后我们将该性能模型应用于候选池,并在开始分布式训练之前枚举搜索空间。