一、应用配置管理方案
应用配置管理方案是什么?
- 实际生产中,为了提高程序对配置文件的复用率需要把应用所需的配置信息和程序分离开,通过不同的配置实现更灵活的功能。
- 当把应用打包为镜像后,通过环境变量或者外挂文件的方式在创建容器时进行配置注入,K8s就给出了解决方案ConfigMap和Secret。
2个配置管理方案:
- ConfigMap存储配置文件信息,是应用程序需要的配置信息。
- Secret存储敏感数据,与ConfiMap相似,区别就是使用场景不一样,存敏感数据,比如账号密码、凭据等。
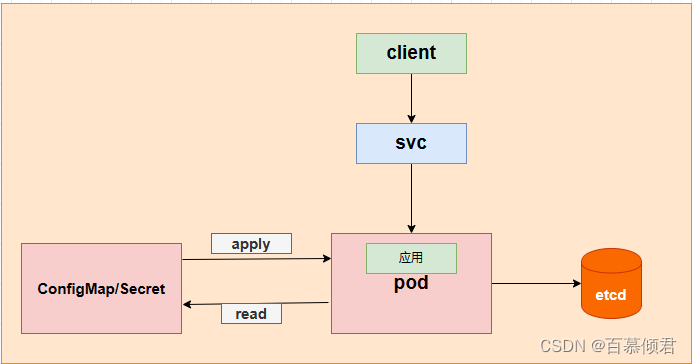
概念图:
1.1 ConfigMap
实现原理:
- 创建ConfigMap后,数据实际会存储在K8s中Etcd,然后通过创建Pod时引用该数据。
- 创建一个ConfigMap,在其里面定义其他对象所需要使用的配置信息,创建pod时引用该ConfigMap 中的数据配置pod中的容器。Pod 和 ConfigMap 必须要在同一个 名字空间 中。
Pod中使用configmap的2种方式:
- 变量注入。
- 数据卷挂载。
应用场景:
1.1.1 注入变量
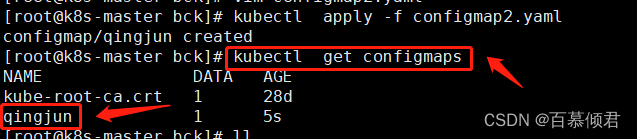
1.编辑yaml文件创建ConfigMap,名为qingjun,定义一个类属性链为abc=mq,再创建pod时引用ConfigMap,从而引用该变量。
[root@k8s-master bck]# cat configmap2.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: qingjun
data:
abc: "mq" #类属性链,每一个链都映射到一个简单的值。
2.创建pod,引用ConfigMap中刚设置的变量abc。
[root@k8s-master bck]# cat pods.yaml
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod ##pod名称。
spec:
containers:
- name: demo
image: nginx
env: ##定义环境变量。
- name: zhangsan ##变量名称,也就是$echo 【变量名】,这里和ConfigMap中的链名是不一样的。
valueFrom:
configMapKeyRef:
name: qingjun ##引用哪个ConfigMap。
key: abc ##需要取值的链。
[root@k8s-master bck]# kubectl apply -f pods.yaml

3.进入容器,查看引用的变量。

1.1.2 挂载数据卷
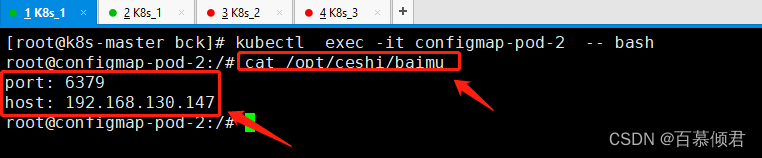
1.编辑yaml文件创建ConfigMap,定义一个类文件链,链名为baidu,再创建pod时引用ConfigMap,从而将其挂载到pod内的容器中。
[root@k8s-master bck]# cat configmap2.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: maq
data:
baimu: |
port: 6379
host: 192.168.130.147
[root@k8s-master bck]# kubectl apply -f configmap2.yaml

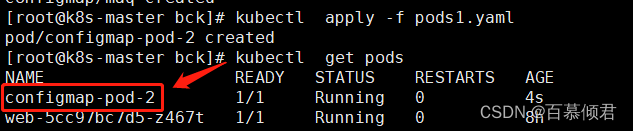
2.创建pod,将ConfigMap中刚设置的类文件链挂载到容器里。
[root@k8s-master bck]# cat pods1.yaml
apiVersion: v1
kind: Pod
metadata:
name: configmap-pod-2
spec:
containers:
- name: demo2
image: nginx
volumeMounts:
- name: config
mountPath: "/opt/ceshi" ##容器内的挂载路径。
readOnly: true
volumes: ##设置卷,将其挂载到pod内的容器中。
- name: config ##卷名,自定义。
configMap:
name: maq ##设置要挂载的ConfigMap的名字。
items: ##来自ConfigMap的一组链,将被创建为文件。
- key: "baimu" ##第一组类文件链名称。
path: "baimu" ##挂载到容器里创建的文件名称,可以自定义,一般都是写和类文件名称一样。
3.进入容器查看挂载文件内容。
1.2 Secret
基本概念:
- Secret是一个用于存储敏感数据的资源,所有的数据要经过base64编码,数据实际会存储在K8s中Etcd,然后通过创建Pod时引用该数据。
作用:
- 与ConfigMap类似,区别在于Secret主要存储敏感数据,所有的数据要经过base64编码。
Pod使用secret数据有两种方式:
- 变量注入。
- 数据卷挂载
应用场景:
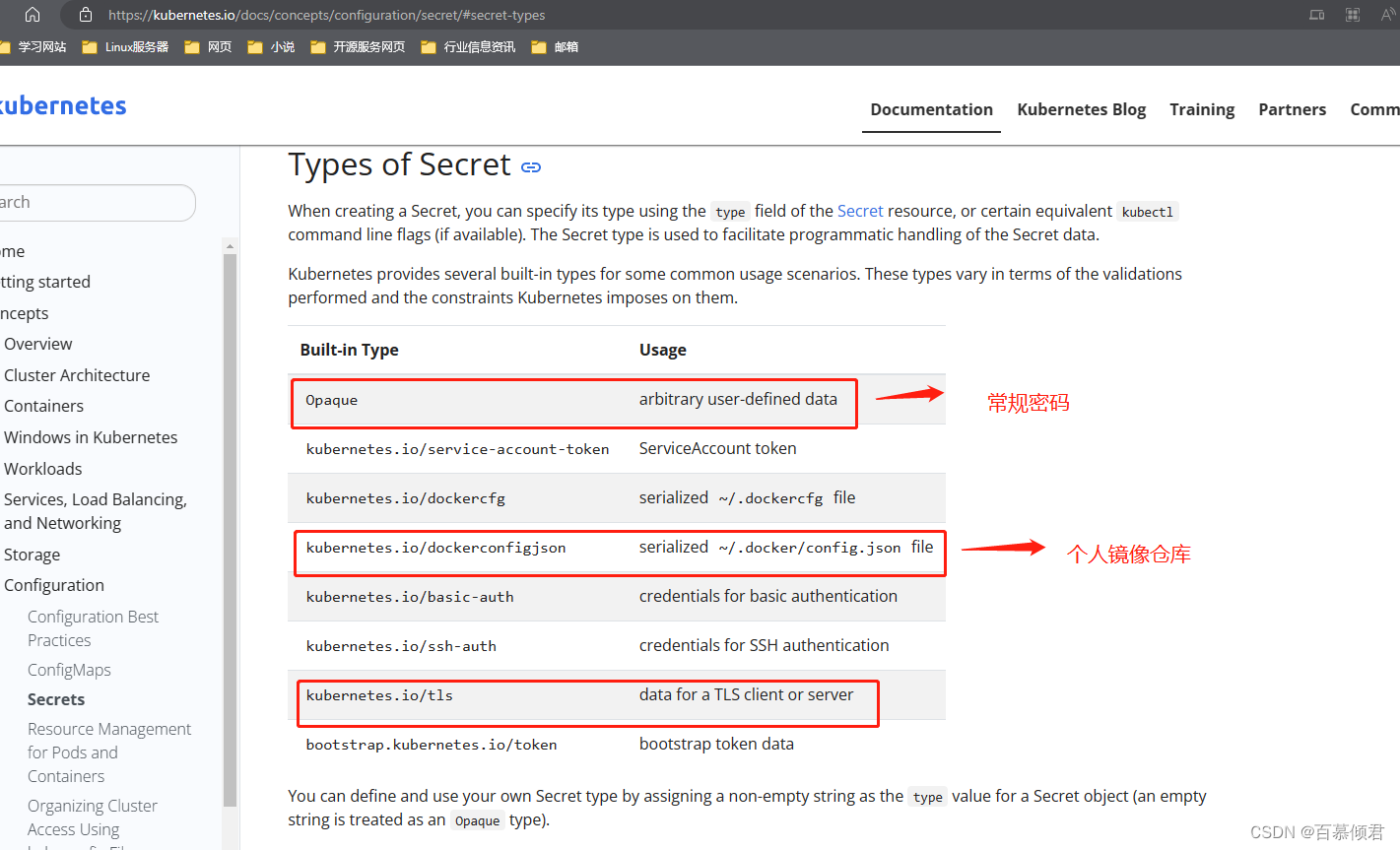
支持三种数据类型:
- docker-registry:存储镜像仓库认证信息
- generic:存储用户名、密码
- tls:存储证书
-
类型参考地址
1.2.1 数据卷挂载
1.将用户密码信息进行编码

2.创建Secret,名为ceshi。
[root@k8s-master bck]# cat configmap3.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceshi
type: Opaque
data:
username: YWRtaW4=
password: Y2l0bXNAMTIz
[root@k8s-master bck]# kubectl apply -f configmap3.yaml

3.创建pod,yaml文件里引用名为ceshi的Secret。
[root@k8s-master bck]# cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: secret-demo-pod
spec:
containers:
- name: demo
image: nginx
env: ##定义变量。
- name: user ##变量名,自定义,和Secret中的名不一样。
valueFrom:
secretKeyRef:
name: ceshi ##引用哪个Secret。
key: username ##引用该Secret中的哪个类属性链。
- name: password ##定义第二组变量。
valueFrom:
secretKeyRef:
name: ceshi
key: password
volumeMounts:
- name: config
mountPath: "/config" #挂载到容器内的路径。
readOnly: true ##容器内生成的文件状态,只读,一般不在容器内修改配置文件参数。
volumes:
- name: config ##自定义卷名。
secret:
secretName: ceshi #引用哪个Secret。
items: #引用该Secret中的哪个类文件链。
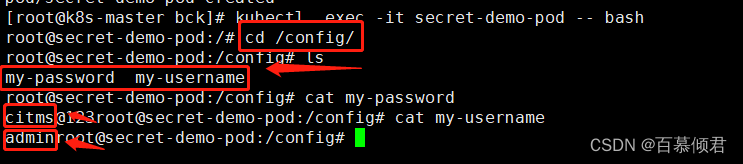
- key: username #链名。
path: my-username #挂载到容器内生成的文件名,自定义。
- key: password ##定义第二个链名。
path: my-password
[root@k8s-master bck]# kubectl apply -f pod.yaml
4.进入容器,查看挂载生成的链文件内容。
1.2.2 变量注入
引入mysql变量:
1.把要保存的密码用base64编码下,不显示明文。
[root@k8s-master1 secret]# echo citms@123 |base64
Y2l0bXNAMTIzCg==
## -n去除换行符
[root@k8s-master1 secret]# echo -n citms@123 |base64
Y2l0bXNAMTIz
2.定义secret把编码后的密码写进去,然后在创建pod时使用引用变量。
[root@k8s-master1 secret]# cat secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysql
type: Opaque
data:
mysql-root-password: "Y2l0bXNAMTIz" ##指定密码
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: db
image: mysql:5.7.30
env:
- name: MYSQL_ROOT_PASSWORD ##引用变量。
valueFrom:
secretKeyRef:
name: mysql
key: mysql-root-password ##读取密码。
[root@k8s-master1 secret]# kubectl apply -f secret.yaml
3.进入pod容器验证。
[root@k8s-master1 secret]# kubectl exec -it mysql-fd6d5d567-4pqgc -- bash
root@mysql-fd6d5d567-4pqgc:/# echo $MYSQL_ROOT_PASSWORD ##查看密码。
citms@123
root@mysql-fd6d5d567-4pqgc:/# mysql -uroot -pcitms@123
......
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
二、调度策略
为什么会有Pod调度?
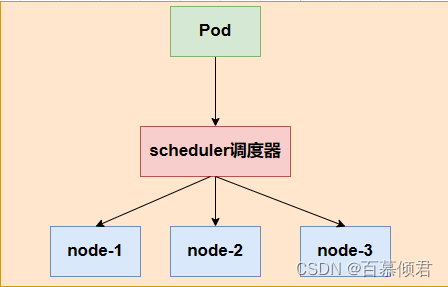
- 在前面的操作实验中,我们经常会用到deploy控制器,通过ReplicaSet自动部署一个容器应用的多份副本,持续监控副本的数量,集群内始终维持用户指定的副本数量。整个过程都是由系统全自动完成调度,pod最终运行在哪个节点上,完全由Master节点上的Scheduler调度器经过一系列算法计算得出,我们无法干预。用户无法干预调度过程和结果。
- 这样依赖就会出现很多弊端,比如我想把redis集群和es集群安装在不通的机器上,我要怎么去控制?像mysql、kafka等有状态集群启动停止顺序是有要求的,我要怎么实现?再比如需要收集每个节点上的日志和主机性能,要怎么玩呢?
- 根据实际的生产场景,K8s陆续推出了调度策略来一一实现以上情景功能。
Pod中影响调度的主要属性:
- 资源调度依据。比如容器资源限制值、容器最小资源需求值,这在后面资源配额和资源限制展开说。
- 调度策略。比如schedulerName自定义调度器、nodeName根据节点名称调度、nodeSelector:定向调度、affinity亲和力调度、污点驱逐,等等。
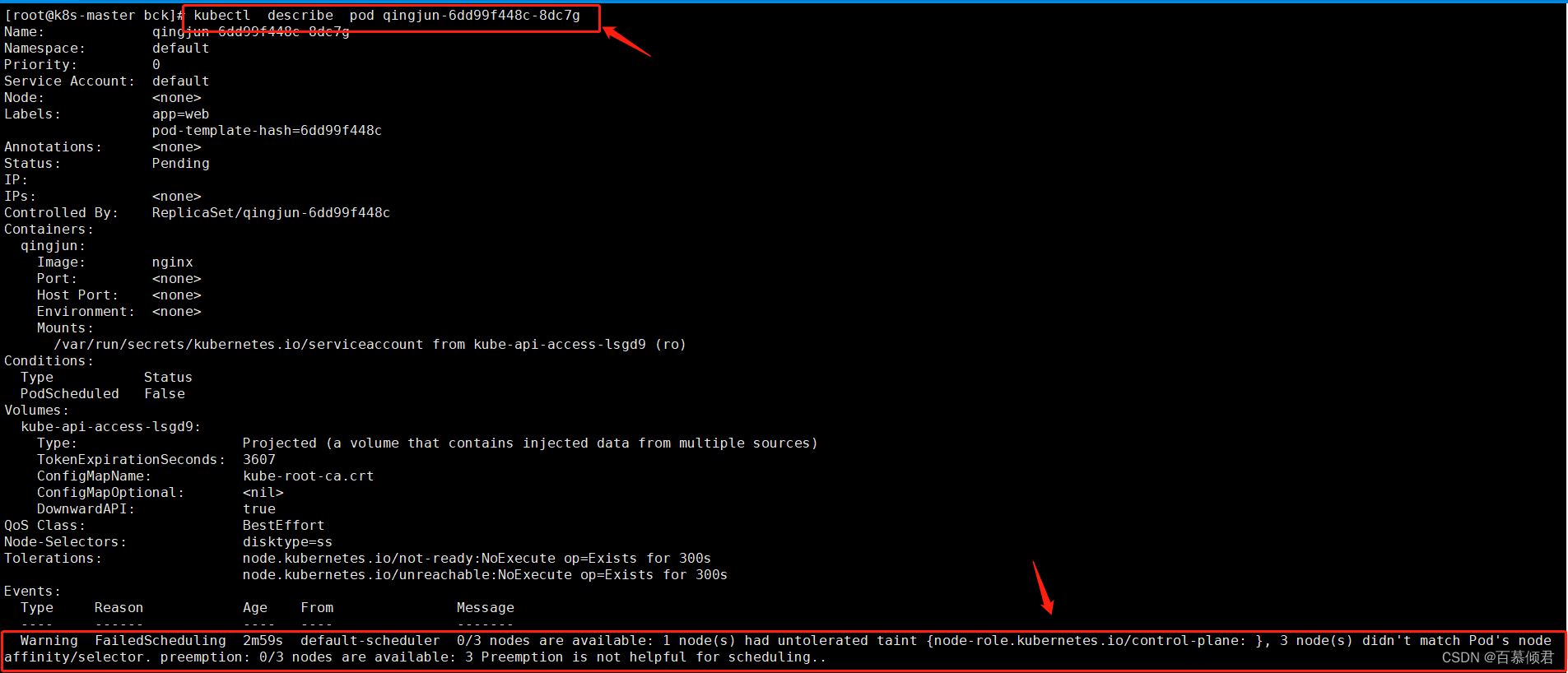
调度失败原因分析思路:
- 节点CPU/内存不足。
- 有污点,没容忍。
- 没有匹配到节点标签。
pod调度流程图:
2.1 nodeSelector定向调度
作用:
- 可以将Pod调度到匹配Label的Node节点上,如果没有匹配的标签会调度失败。
- 所以我们在玩nodeselector时,需要提前给节点打标签。
特点:
应用场景:
- 专用节点:根据业务线将Node分组管理。
- 配备特殊硬件:部分Node配有SSD硬盘、GPU。
命令格式:
-
节点打标签:kubectl label nodes < node-name > < label-key1 >=< label-value1 > < label-key2 >=< label-value2 >
-
删除节点标签:kubectl label node k8s-node1 < label-key >-
注意事项:
- 此种方式是完全匹配标签,缺少或多一个字符都匹配不上会报错。
- 可以同时设置多个标签。
2.1.1 正例
1.先查看节点默认标签。
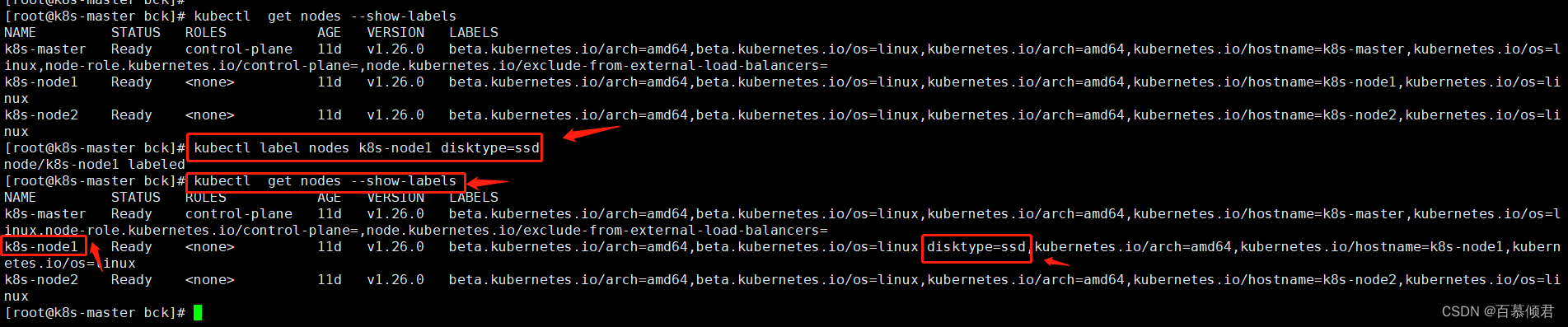
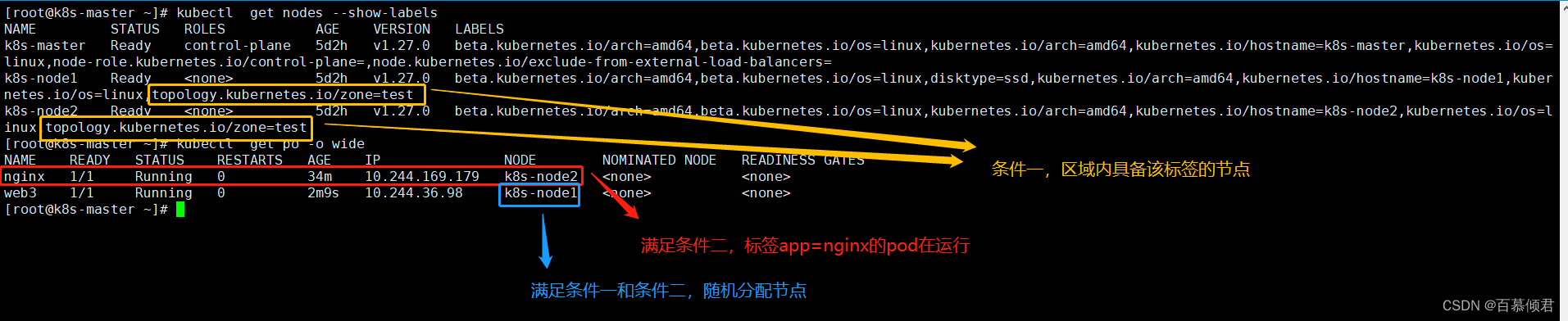
[root@k8s-master bck]# kubectl get nodes --show-labels

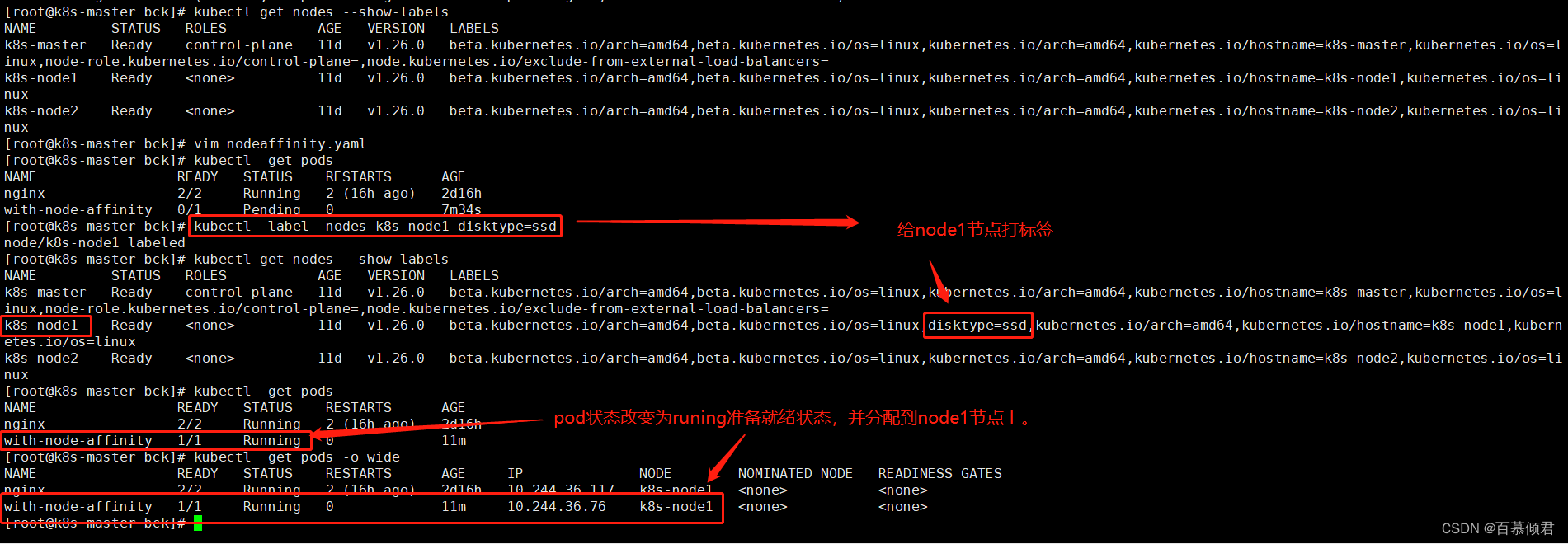
2.给node1节点添加标签,标签为disktype=ssd。
[root@k8s-master bck]# kubectl label nodes k8s-node1 disktype=ssd
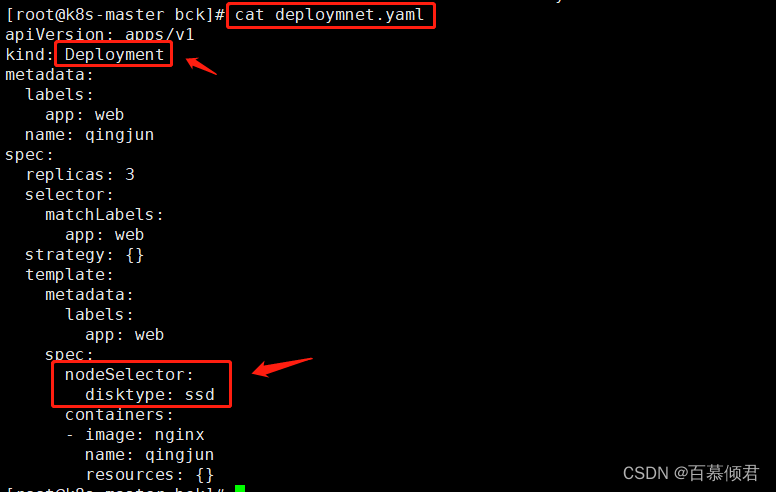
3.编辑pod.yaml文件,添加nodeSeletor字段,指定标签disktype=ssd,到创建pod时就会根据此标签完全匹配具有该标签的节点并完成创建。
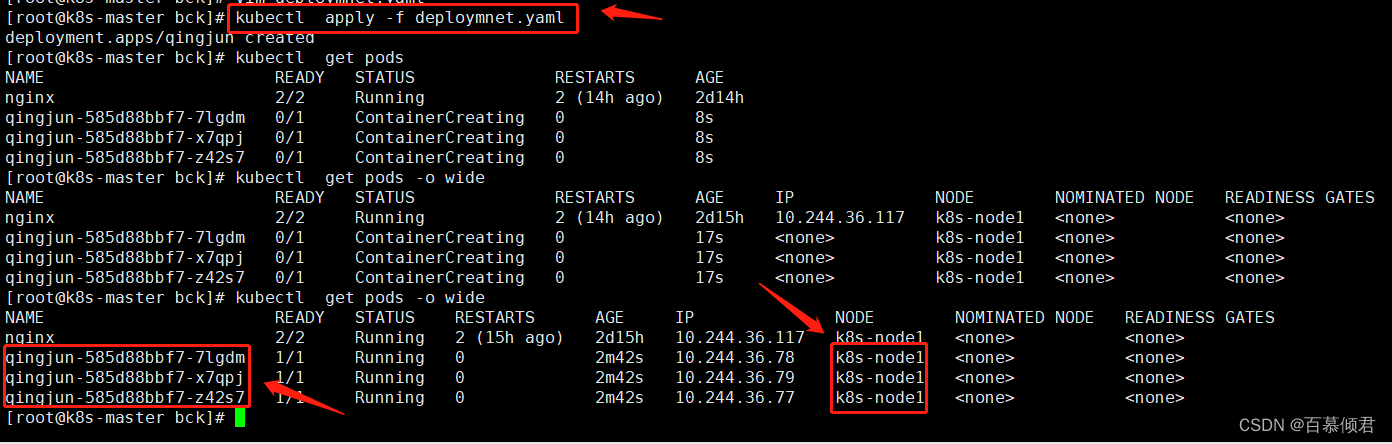
4.导入yaml文件,验证查看。此时的Pod是创建在node1节点,测试成功。
4.删除节点标签。
[root@k8s-master bck]# kubectl label node k8s-node1 disktype-

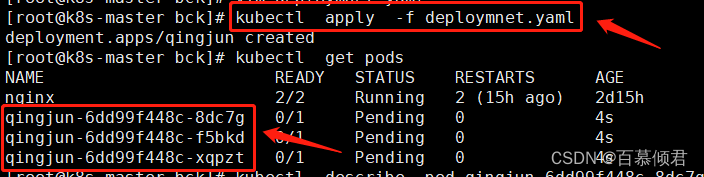
2.1.2 反例
- 若yaml文件里的标签不能完全匹配到给节点定义的标签内容,则会创建失败。
- 即时存在正常可用的node节点,在没有匹配对应的标签时,也会创建失败。
1.编辑yaml文件,修改标签内容为"ss",上文给Node1节点设置的标签为“ssd”,两边是没有完全匹配的,所以在后面创建Pod任务一直处于等待中。
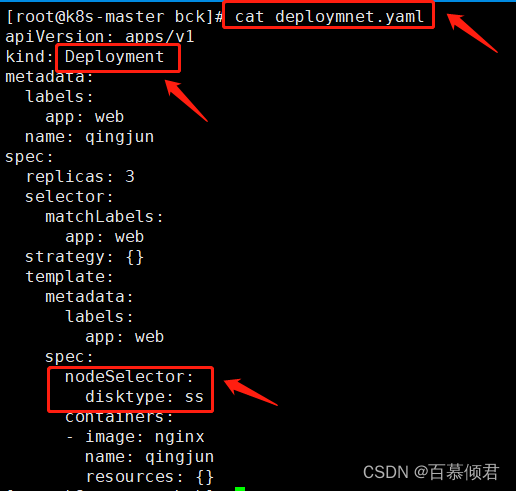
2.导入yaml标签,查看。
2.2 nodeAffinity亲和力调度
作用:
- 可以根据节点上的标签来约束Pod可以调度到哪些节点。
- 是定向调度的升级版,因为定向调度不能完全应付所有工作场景,所以支持的操作符很多样。
支持操作符:
- In:将pod调度到匹配具有定义标签的节点上。
- NotIn:将pod调度到,除具有定义标签的其他节点上。
- Exists:若label标签存在,则调度到具备该标签的节点上。
- DoesNotExist: 若label标签不存在,则调度到不具备该标签的节点上。
- Gt:label 的值大于某个值。
- Lt:label 的值小于某个值。
调度策略分类:
- 分为硬策略和软策略。
- required硬策略:必须满足指定的规则才可以调度Pod到指定Node节点上,功能与nodeSelector很像,但是使用的是不同的语法。
- preferred软策略:K8s调度背后是计分制,参考因素较多,软策略的存在就是多个权重值,在调度时把我们加进去的权重值累计上再进行调度,考量的是调度到某个节点上的欲望是否强烈。多个优先级规则还可以设置权重(weight)值,以定义执行的先后顺序。若Pod所在节点在Pod运行期间标签发生变更,不再符合该Pod的节点亲和性需求,则系统将忽略Node上Label的变化,该Pod能继续在该节点上运行。
注意事项:
-
若同时指定nodeSelector 和 nodeAffinity,两者必须满足才能将 Pod调度到候选节点上。
-
若在nodeAffinity策略中定义了多个nodeSelectorTerms条件,只要满足其中一个nodeSelectorTerms 条件,Pod就可以被调度到节点上。
-
若在nodeSelectorTerms 策略中,单个matchExpressions 字段下指定多个表达式, 则只有当所有表达式都满足时,Pod 才能被调度到节点上。
-
参考官网
2.2.1 In硬策略
1.先查看节点标签,此时节点只有默认标签。

2.编辑pod.yaml文件,添加标签。上面为硬策略,必须满足;下面为软策略,尽量满足,但不确定。此时先看硬策略,配有标签ssd。
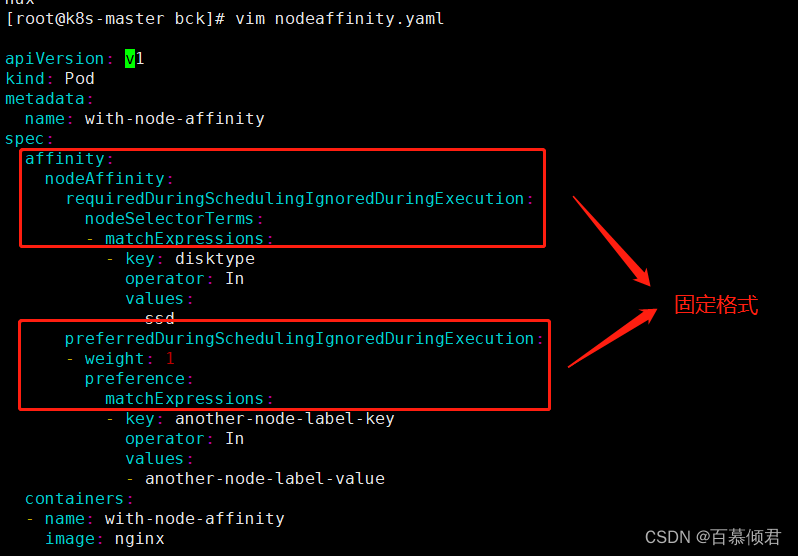
3.导入yaml文件,查看pod状态为等待状态。是因为我们两个node节点都没有设置标签,所有一直为pending。

4.此时再去给ndoe1节点打标签,之后再重新导入yaml文件,pod状态改变为runing状态,pod被调度到node1节点。
2.2.2 NotIn硬策略
1.将pod.yaml文件的操作符修改成NotIn,代表把pod创建到没有该标签的节点上。以下规则表示哪个节点标签没有disktype=ssd,则调度到那个节点上去。
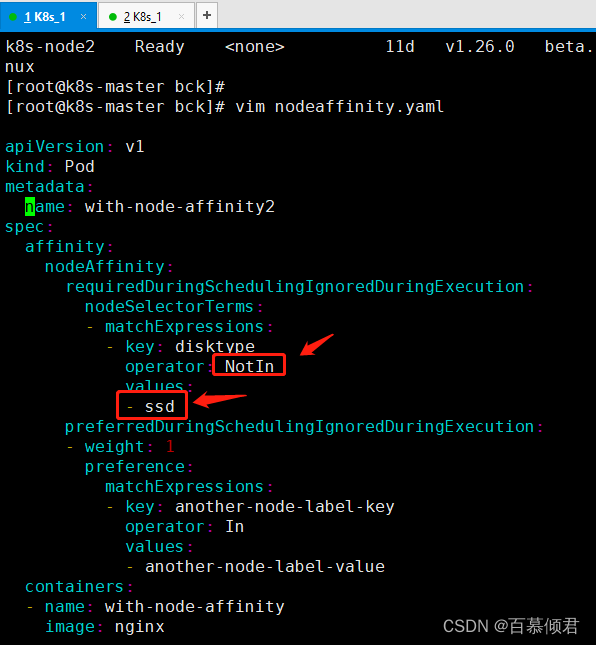
2.导入yaml文件,查看新pod在node2节点上创建完成。因为node1有ssd标签,所有就分配在除node1节点之外的节点上。

2.2.3 软策略
- 软策略主要讲究权重值(1~100),值越大,代表越能优先匹配到符合定义标签的节点上创建pod;若没有符合该标签的节点,则依然会创建pod,不会让其处于pending状态。
1.编辑pod.yaml文件,添加软策略,代表当调度pod时计算的分值+权重值=最后调度分值,分值越高则调度到匹配对应标签的欲望越大。
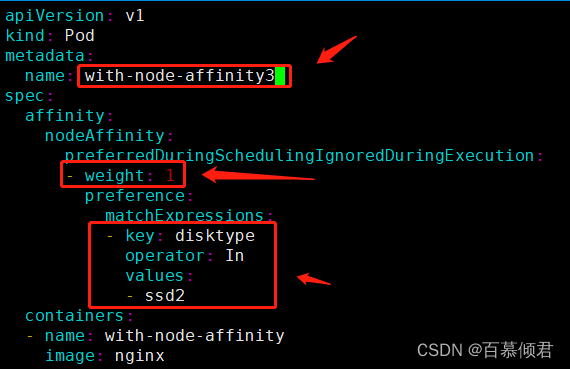
2.导入yaml文件,查看pod被创建在node2节点上。因为我的集群三个节点都没有disktype=ssd2标签,所以三个节点都有可能被分配,只是这里创建在node2节点上了。

2.3 PodAffinity亲和力调度
基本了解:
- pod亲和力调度更偏向于将pod调度到某一个拓扑域内,且具备某一标签的pod上。比如es集群和redis集群分别部署在不同机器上,这样就可以看作两个拓扑域,当我新增redis容器时,我想把它调度到redis集群所在的节点上,此时就需要满足两个条件:1.必须是redis集群形成的拓扑域;2.该拓扑域内有redis指定标签的pod。
- 此种调度略测同样具备硬策略和软策略之分。
- 不建议在包含数百个节点的集群中使用这类设置,因为需要大量计算量,显著降低调度速度。
拓扑域的概念:
- 一个拓扑域由一些Node节点组成。比如同一个机架、机房或地区的region拓扑域;地区级别的Zone拓扑域。
- 实际生活中我们更多的是根据机架规划拓扑域,数据库服务器在哪个机架上,应用服务器在哪个机架上,对应的服务器打上对应的拓扑域标签。
- K8s内置常用默认拓扑域:topology.kubernetes.io/zone、topology.kubernetes.io/region、kubernetes.io/hostname。
2种用法:
- Pod Affinity:相关联的两种或多种Pod可以在同一个拓扑域中共存。
- Pod AntiAffinity:相关联的两种或多种Pod可以在同一个拓扑域中互斥。
支持操作符:
- In:将pod调度到匹配具有定义标签的节点上。
- NotIn:将pod调度到,除具有定义标签的其他节点上。
- Exists:若label标签存在,则调度到具备该标签的节点上。
- DoesNotExist: 若label标签不存在,则调度到不具备该标签的节点上。
- Gt:label 的值大于某个值。
- Lt:label 的值小于某个值。
2.3.1 pod共存
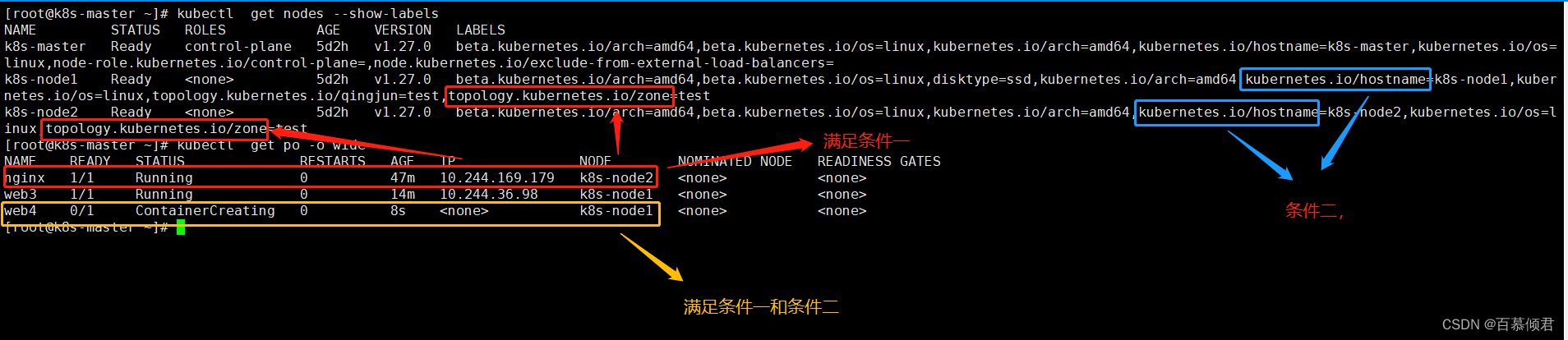
1.先创建一个参考pod1 nginx,比作后面新创建的pod需要调度到此pod所在的拓扑域节点上,此时参考pod在node2上。
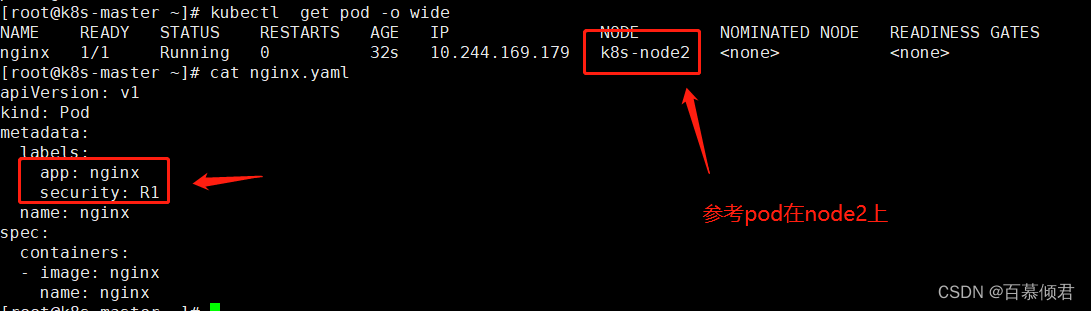
2.现在要新建第二个pod,要求是需要跟pod1在同一个区域。确切的讲,是仅当节点和至少一个已运行且有 app=nginx 或security=R1 的标签的 Pod 处于同一区域时,才可以将该新Pod 调度到节点上。
[root@k8s-master ~]# cat poaffinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: web3
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app ##条件二,该该区域内的集群节点上有标签app=nginx的pod在运行。
operator: In
values:
- nginx
topologyKey: topology.kubernetes.io/zone ##条件一,调度到具备此标签的拓扑域内。
containers:
- name: nginx
image: nginx
[root@k8s-master ~]# kubectl apply -f poaffinity.yaml
3.此时查看新pod就被分配在与nginx所在的同一个区域内,同时满足了以上2个条件。
2.3.2 pod互斥
1.同样还是以pod1 nginx为参考。
2.现在需要新建第二个Pod,调度条件是需要和app=nginx标签的pod所处在同一个zone区域中,且不能和security=R1标签的pod所在同一个hostname区域中。
[root@k8s-master ~]# cat poaffinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: web4
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- R1
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx
[root@k8s-master ~]# kubectl apply -f poaffinity.yaml
3.查看。此时nginx分配在node2上,node1和node2都有topology.kubernetes.io/zone标签,所以node1和node2组成了zone区域。两节点上都具备kubernetes.io/hostname标签,有各自组成了一个区域。所以条件一满足了就是要将Pod分配的node1或node2上,满足条件二就只能调度到node1上。
三、Taint与Tolerations
为什么会有taint污点的存在?
- 污点的作用类似与亲和力调度中的NotIn用法,只是亲和力调度是基于pod标签分配pod,而污点是基于Node层面来玩的,通过在Node上添加污点属性,来避免Pod被分配到不合适的节点上。
- 比如磁盘要满、资源不足、存在安全隐患的节点需要升级维护,此时希望新的Pod不会被调度过来这些节点上,不然会影响业务。若仍需将某些Pod调度到这些节点上时,可以通过使用Toleration属性来实现。
基本概念:
- Taints:污点,避免Pod调度到指定Node节点上。
- Tolerations:污点容忍,允许Pod调度到持有Taints的Node上。
master节点为什么会在搭建集群时就默认打污点?
- 提高安全性。当黑客入侵容器时,不会渗透到master节点控制整个k8s集群。
- 专门作为跑管理节点组件,方便管理。

相关命令:
- 添加命令: kubectl taint node [node] key=value:[effect]
- 验证命令:kubectl describe node k8s-node1 |grep Taint
- 删除污点:kubectl taint node [node] key:[effect]-
[effect] 可取值:
- NoSchedule :一定不能被调度。
- PreferNoSchedule:尽量不要调度,非必须配置容忍。
- NoExecute:不仅不会调度,还会驱逐Node上已有的Pod。可以设置tolerationSeconds参数,表明Pod可以在Taint添加到Node之后还能在这个Node上运行多久(单位为s),时间已过就被驱逐。
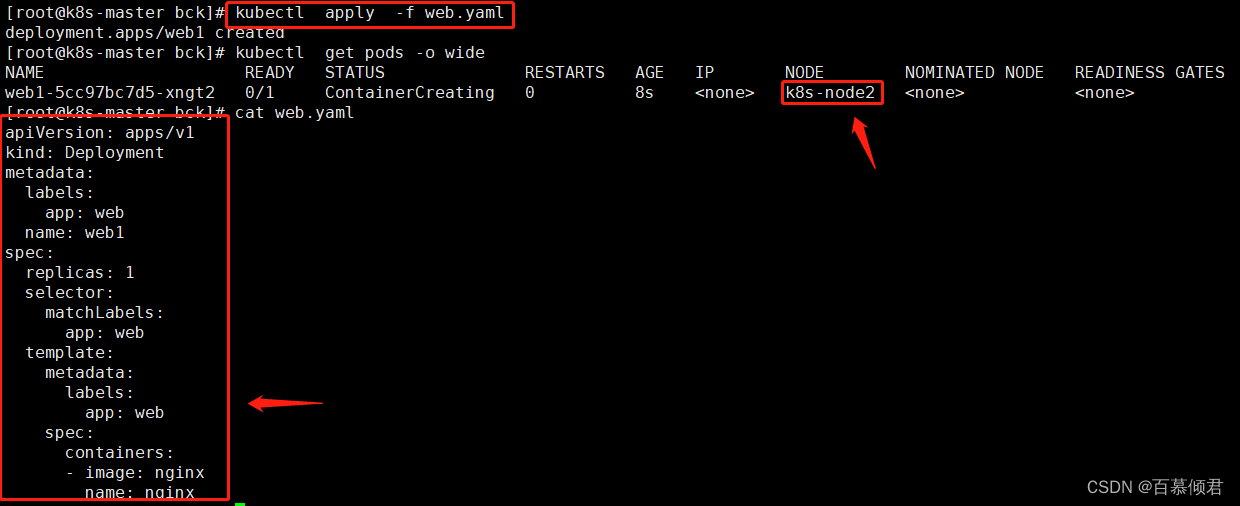
3.1 添加污点
1.给node1节点打污点,其中key=gpu,value=yes,eddect=NoSchedule。
[root@k8s-master bck]# kubectl taint node k8s-node1 gpu-yes:NoSchedule
2.查看节点污点。
#查看某一节点污点情况。
[root@k8s-master bck]# kubectl describe node k8s-node1|grep Taint
#查看集群所有节点污点情况。
[root@k8s-master bck]# kubectl describe nodes|grep Taint

3.此时常规pod就不会被调度创建在node1上了。
3.2 污点容忍
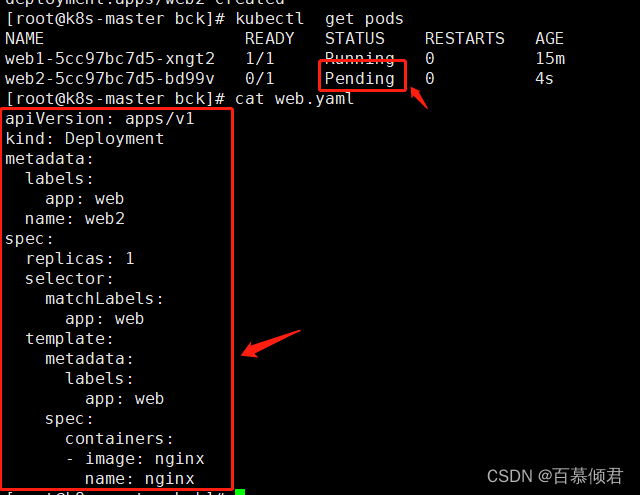
1.给node2节点打完污点后,再创建第二个pod ,此时该pod一直等待状态。要怎么解决呢?打污点容忍。
[root@k8s-master bck]# kubectl taint node k8s-node2 gpu=ok2:NoSchedule

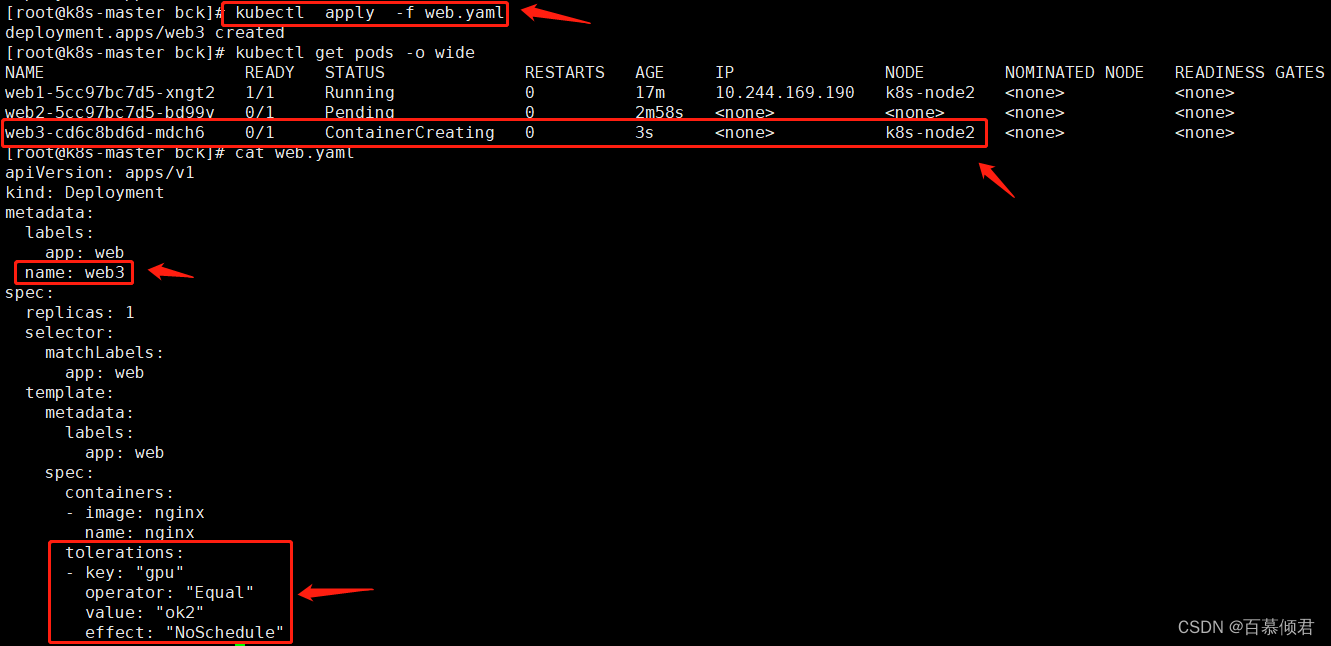
2.yaml文件添加污点容忍字段,导入yaml后pod被创建在node2节点上。容忍污点为gpu=ok2:NoSchedule的污点,也就是容忍在node2节点。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test
image: busybox
tolerations:
- key: "gpu"
operator: "Equal"
value: "yes"
effect: "NoSchedule"
3.删除Node2节点的污点。
[root@k8s-master bck]# kubectl taint node k8s-node2 gpu-
3.3 弹性驱逐调度
- K8s从1.6版本开始引入两个与Taint相关的新特性:TaintNodesByCondition和TaintBasedEvictions,用来改善异常情况下的Pod调度与驱逐问题,比如在节点内存吃紧、节点磁盘空间已满、节点失联等情况下,是否自动驱逐某些Pod或者暂时保留这些Pod等待节点恢复正常。
- 这两个特性现在已被默认启用。
- TaintNodesByCondition特性只会为节点添加NoSchedule效果的污点。
- TaintBasedEviction只为节点添加NoExecute效果的污点。在TaintBasedEvictions特性被开启之后,kubelet会在有资源压力时对相应的Node节点自动加上对应的NoExecute效果的Taint,例如node.kubernetes.io/memory-pressure、node.kubernetes.io/disk-pressure。如果Pod没有设置对应的Toleration,则这部分Pod将被驱逐,以确保节点不会崩溃。
流程逻辑:
- 不断地检查所有Node状态,设置对应的Condition。
- 不断地根据Node Condition设置对应的Taint。
- 不断地根据Taint驱逐Node上的Pod。
自动为Node节点添加Taint的几种情况:
- node.kubernetes.io/not-ready: 节点未就绪。对应NodeConditionOReady为False的情况
- node.kubernetes.io/unreachable:节点不可触达。对应NodeCondition Ready为Unknown的情况。
- node.kubernetes.io/out-of-disk: 节点磁盘空间已满。
- node.kubernetes.io/network-unavailable: 节点网络不可用。
- node.kubernetes.io/unschedulable: 节点不可调度。
- node.cloudprovider.kubernetes.io/uninitialized: 若kubelet是由“外部”云服务商启动的,则该污点用来标识某个节点当前为不可用状态。在云控制器 (cloud-controller-manager) 初始化这个节点以后,kubelet会将此污点移除。
四、优先级抢占调度
基本了解:
- 这种调度策略是为了提高资源利用率,但弊端颇多,只做了解。
- 当有大规模集群时,为了提高集群的资源利用率可以采用优先级方案,即不同类型的负载对应不同的优先级,同时允许集群中的所有负载所需的资源总量超过集群可提供的资源,在这种情况下,当发生资源不足的情况时,系统可以选择释放一些不重要的负载(优先级最低的) ,保障最重要的负载能够获取足够的资源稳定运行。
抢占式调度:
- Pod Priority Preemption抢占式调度策略,会尝试释放目标节点上低优先级的Pod,以腾出空间(资源 安置高优先级的Pod,这种调度方式被称为“抢占式调度”。
- 抢占式调度策略出来之前,若有优先级高的Pod被创建后只能处于pending状态,等待释放资源后才能创建,所以解决这个问题官方才会引出抢占式调度。
- 1.11版本已升级为Beta版本,默认开启。
衡量负载优先级指标:
- Priority: 优先级
- QoS: 服务质量等级
- 系统定义的其他度量指标。
驱逐、抢占:
- Eviction驱逐,是kubelet进程的行为。当一个Node资源不足时kubelet会执行驱逐动作,kubelet会综合考虑该节点上的Pod的优先级、资源申请量与实际使用量等信息来计算哪些Pod需要被驱逐。当同样优先级的Pod需要被驱逐时,实际使用的资源量超过申请量最大倍数的高耗能Pod会被首先驱逐。
- Preemption抢占,是Scheduler调度器执行的行为。当一个新的Pod因为资源无法满足而不能被调度时,Scheduler有权决定选择驱逐部分低优先级的Pod实例来满足此Pod的调度目标。
注意事项:
- 这种调度策略可能导致某些Pod永远无法被成功调度。优先级调度是一个复杂的玩法,可能会带来额外不稳定的因素。所以当出现资源紧张的局面时,首先要考虑的是集群扩容。
- 反观优先级调度策略初学者只做了解,实际应用中需要考量很多因素,比如批处理任务pod。
五、Nodename调度
- 可以在pod.yaml中指定节点名称,将Pod调度到指定的Node上,不经过调度器。
1.pod.yaml中添加nodeName参数,指定调度节点。
[root@k8s-master ~]# cat pos.yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
nodeName: k8s-node2 #指点调度节点。
containers:
- name: web3
image: nginx
[root@k8s-master ~]# kubectl apply -f pos.yaml
2.查看pod被调度到node2上。