本文主要记录利用sentinelsat包批量下载sentinel2数据。
转载:https://blog.csdn.net/mrzhy1/article/details/107044828
方法一:直接利用sentinelsat包
1.sentinelsat包介绍
Sentinelsat提供了一个Python API和一个命令行接口,用于搜索、下载和检索Sentinel产品的元数据。如果是online数据,使用download函数就可以直接下载;如果是offline数据,download函数会对该数据进行激活。
GitHub:https://github.com/sentinelsat/sentinelsat
官方文档:https://sentinelsat.readthedocs.io/en/stable/
PyPi sentinelsat网址:https://pypi.org/project/sentinelsat/
2.sentinelsat包安装pip install sentinelsat
https://sentinelsat.readthedocs.io/en/stable/install.html

表示安装成功。
3.批量下载sentinel3 数据
(1)获取感兴趣区域对应范围的geojson文件:http://geojson.io

导出保存为GeoJSON格式:

下载sentinel2代码:
from sentinelsat import SentinelAPI, read_geojson, geojson_to_wkt
from datetime import date
# connect to the API
api = SentinelAPI('user', 'password', 'https://apihub.copernicus.eu/apihub')
# download single scene by known product id
api.download(<product_id>)
# search by polygon, time, and Hub query keywords
footprint = geojson_to_wkt(read_geojson('map.geojson'))
products = api.query(footprint,
date = ('20151219', date(2015, 12, 29)),
platformname = 'Sentinel-2',
cloudcoverpercentage = (0, 30))
# download all results from the search
api.download_all(products)
# GeoJSON FeatureCollection containing footprints and metadata of the scenes
api.to_geojson(products)
# GeoPandas GeoDataFrame with the metadata of the scenes and the footprints as geometries
api.to_geodataframe(products)
# Get basic information about the product: its title, file size, MD5 sum, date, footprint and
# its download url
api.get_product_odata(<product_id>)
# Get the product's full metadata available on the server
api.get_product_odata(<product_id>, full=True)
代码来源:Github项目代码
或来自https://blog.csdn.net/lidahuilidahui/article/details/90486402的代码:
#sentinelsat中导入相关的模块
from sentinelsat import SentinelAPI, read_geojson, geojson_to_wkt
#创建SentinelAPI,请使用哥白尼数据开放获取中心自己的用户名及密码
api =SentinelAPI(‘用户名', ‘密码','https://scihub.copernicus.eu/apihub/')
#读入上海市的geojson文件并转换为wkt格式的文件对象,相当于足迹
footprint =geojson_to_wkt(read_geojson('map.geojson'))
#通过设置OpenSearch API查询参数筛选符合条件的所有Sentinel-2 L2A级数据
products =api.query(footprint, #Area范围
date=('20190510','20190512'), #搜索的日期范围
platformname='Sentinel-2', #卫星平台名,Sentinel-2
producttype='S2MSI2A', #产品数据等级,‘S2MSI2A’表示S2-L2A级产品
cloudcoverpercentage=(0,30)) # 云量百分比
#通过for循环遍历并打印、下载出搜索到的产品文件名
for product in products:
#通过OData API获取单一产品数据的主要元数据信息
product_info = api.get_product_odata(product)
#打印下载的产品数据文件名
print(product_info['title'])
#下载产品id为product的产品数据
api.download(product)
原文链接:https://blog.csdn.net/lidahuilidahui/article/details/90486402
注意:sentinelAPI的使用方法
class sentinelsat.SentinelAPI(user, password,
api_url=‘https://scihub.copernicus.eu/apihub/’, show_progressbars=True,
timeout=None)

注意:这里api_url虽然给出了两个URL,但建议使用后者,即 https://scihub.copernicus.eu/dhus ,因为前一个URL:https://scihub.copernicus.eu/apihub ,无法下载历史数据,即使在历史数据由“Offline”变为“Online”时,也无法下载。但 https://scihub.copernicus.eu/dhus , 在历史数据由“Offline”变为“Online”时,可以恢复下载。其中一个URL下载速度慢时,也可以换另一个。
转自:https://blog.csdn.net/lidahuilidahui/article/details/90486402
使用https://scihub.copernicus.eu/dhus 可以下载历史数据,历史数据通过激活offline到online,实现下载。
方法二:利用IDM + sentinelsat(避免上面方法出现网断重新下载等问题)
参考如何使用sentinelsat包和IDM批量下载offline的sentinel数据:
下面记录自己操作的过程,及遇到的问题。
1.下载IDM
IDM下载(试用30天):https://www.internetdownloadmanager.com/
2.批量获取哥白尼数据开放访问中心购物车里的数据下载链接
(1)根据条件筛选数据:
打开哥白尼数据官网:https://scihub.copernicus.eu/dhus/#/home,根据传感器类型、时间、区域、云量等信息设定检索条件,然后利用爬虫提取产品链接:可以看这篇博主的文章:https://blog.csdn.net/mrzhy1/article/details/107019960
(2)利用Python爬虫技术提取数据标签
因为我这里是将检索的数据全部下载下来,不用经过再次筛选,所以不需要加入购物车,直接保存检索到的页面到本地,然后利用爬虫技术提取数据的标签。
1)保存页面到本地;
2)Python爬虫获取数据链接号和ID:
查看网页中数据链接所在的节点:

爬虫代码:(下载所有数据,非cart数据)
from bs4 import BeautifulSoup
import pandas as pd
import requests
filepath='scihub.copernicus.eu.html'
with open(filepath,'rb') as f:
ss=f.read()
soup=BeautifulSoup(ss,'html.parser')
#获取所有class为list - link selectable的div标签下的a标签
divfind=soup.find_all('div',class_ = 'list-link selectable')
linklist=[]
idlist=[]
for df in divfind:
#获取满足条件的div下的a标签
#提取a标签的内容,即为数据链接
link=df.find('a').string
id=link.split('\'')[1]
linklist.append(link)
idlist.append(id)
linkdataframe=pd.DataFrame(linklist)
iddataframe=pd.DataFrame(idlist)
#将数据链接写出
with pd.ExcelWriter('Httpandid.xlsx') as hifile:
linkdataframe.to_excel(hifile,sheet_name='HTTP',header=False,index=False)
iddataframe.to_excel(hifile,sheet_name='ID',header=False,index=False)
爬虫代码:(下载cart中的数据)
from bs4 import BeautifulSoup
import pandas as pd
import requests
filepath='scihub.copernicus.eu.html'
with open(filepath,'rb') as f:
ss=f.read()
soup=BeautifulSoup(ss,'html.parser')
#获取所有id为cart-row-attributes的div标签
divfind=soup.find_all('div',id='cart-row-attributes')
linklist=[]
idlist=[]
for df in divfind:
#获取满足条件的div下的a标签
#提取a标签的内容,即为数据链接
link=df.find('a').string
id=link.split('\'')[1]
linklist.append(link)
idlist.append(id)
linkdataframe=pd.DataFrame(linklist)
iddataframe=pd.DataFrame(idlist)
#将数据链接写出
with pd.ExcelWriter('Httpandid.xlsx') as hifile:
linkdataframe.to_excel(hifile,sheet_name='HTTP',header=False,index=False)
iddataframe.to_excel(hifile,sheet_name='ID',header=False,index=False)
代码来源:https://blog.csdn.net/mrzhy1/article/details/107019960
但是这种方法只能下载本网页显示的个数,比如显示150个,那么下载的链接也是150个,无法将所有的数据链接进行下载。
爬虫技术中重要包:
BeautifulSoup:是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。
使用方法:BeautifulSoup(markup, “html.parser”)解析器为html.parser。
3.利用IDM下载sentinel3数据步骤
(1)打开IDM,下载——选项——站点管理,点击新建,添加路径(修改https,并添加scihub.copernicus.eu)、用户名和密码。

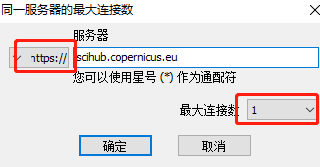
(2)设置IDM下载的属性:IDM支持对同一下载资源进行多连接下载,也能够同时下载多个资源。为了保护哨兵数据下载账号并正常下载数据,需要对IDM进行限制(设置为1),具体操作步骤:打开下载——选项——连接——新建,对话框输入网址https://scihub.copernicus.eu,最大连接数设为1。

(3)新建队列,命名为sentinel3
(4)数据批量下载
这里为了测试,先下载1个数据,将下载链接复制到txt文件中。全部选中数据,复制。

在IDM中,选择任务——从剪切板中批量下载

(注意需要科学上网才可以下载!)
如果出现显示超时,连接不上,在IDM中选择:选项——代理服务器——使用系统设置——确定,才可以下载数据。

4.IDM+sentinelsat结合批量下载sentinel3数据
思路:
(1)获取需要下载数据的链接和ID号;
(2)判断列表中第一个数据是online还是offline;
(3)如果是online数据,那就将数据链接添加到IDM的下载列表中,并进行下一次循环。
(4)如果是offline数据,那就使用download()函数对数据进行激活。并把该数据从列表的第一个位置删除,放在列表的最后一个位置。
这里直接利用使用sentinelsat包和IDM批量下载offline的sentinel数据的代码:
from subprocess import call
from sentinelsat import SentinelAPI
from datetime import date
import time
import xlrd
from tqdm import tqdm
IDM = "IDMan.exe" #你电脑中IDM的位置
DownPath='F:/Sentinel_offline/' #数据要下载的地址
api = SentinelAPI('ESA账号的账户名', '账号密码', 'https://scihub.copernicus.eu/dhus')
#用于读取数据的HTTP链接到列表中
filepath='HTTPandID.xlsx'
workbook = xlrd.open_workbook(filepath)
sheet1 = workbook.sheet_by_name('HTTP')
linklist=sheet1.col_values(0)
#开始下载
print('开始任务:..................')
n=0
while linklist:
print('---------------------------------------------------')
n=n+1
print('\n')
print('第'+str(n)+'次循环'+'\n\n')
id=linklist[0].split('\'')[1]
link=linklist[0]
product_info=api.get_product_odata(id)
print('检查当列表里的第一个数据:')
print('数据ID为:'+id)
print('数据文件名为:'+product_info['title']+'\n')
if product_info['Online']:
print(product_info['title']+'为:online产品')
print('加入IDM下载: '+link)
call([IDM, '/d',link, '/p',DownPath,'/n','/a'])
linklist.remove(link)
call([IDM,'/s'])
else:
print(product_info['title']+'为:offline产品')
print('去激活它')
api.download(id) #去激活它
print('检查任务列表里是否存在online产品: .........')
#等待激活成功的时候,检查现在的列表里还有没有online产品
#如果有online的产品那就下载
#首先检查列表中是否需要下载的数据
if len(linklist)>1:
#记录列表里可以下载的链接,并在最后把它们删除
ilist=[]
#开始寻找列表剩下的元素是否有online产品
for i in range(1,len(linklist)):
id2=linklist[i].split('\'')[1]
link2=linklist[i]
product_info2=api.get_product_odata(id2)
if product_info2['Online']:
print(product_info2['title']+'为在线产品')
print('ID号为:'+id2)
print('加入IDM下载: '+link2)
print('--------------------------------------------')
call([IDM, '/d',link2, '/p',DownPath,'/n','/a'])
#在列表中加入需要删除产品的HTTP链接信息
#直接在linklist中删除会linklist的长度会发生改变,最终造成i的值超过linklist的长度
ilist.append(link2)
else:
continue
#把已经下载的数据的链接给删除掉
if len(ilist)>0:
call([IDM,'/s'])
for il in ilist:
linklist.remove(il)
print('本轮次检查结束,开始等到40分钟')
#将该激活的产品删除,再加入到最后
linklist.remove(link)
linklist.append(link)
#两次激活offline数据的间隔要大于30分钟
for i in tqdm(range(int(1200)),ncols=100):
time.sleep(2)
报错:
1)问题1
利用anaconda安装的sentinelsat,在Spyder中无法正常使用,直接打开spyder,在命令窗口中直接安装,可以解决这个问题。
2)问题2

对输入的文件进行格式转换,即xlsx转xls。
参考资料:
Sentinelsat模块 - 批量下载Sentinel数据 - 哨兵数据下载方法合集:https://blog.csdn.net/summer_dew/article/details/99649878
Python中使用sentinelsat包自动下载Sentinel系列数据:https://blog.csdn.net/lidahuilidahui/article/details/90486402#sentinelsat_83