Docs https://laiye-tech.feishu.cn/docx/XRKldiRcZoMDomxwrKtcWD8EnQb基于Diffusion的典型可控图片生成模型在上文扩散模型原理的基础上,本文对目前最前沿的几个可控图像生成模型如DALL-E-2,ImaGen,Stable Diffusion做了详细介绍。
https://laiye-tech.feishu.cn/docx/XRKldiRcZoMDomxwrKtcWD8EnQb基于Diffusion的典型可控图片生成模型在上文扩散模型原理的基础上,本文对目前最前沿的几个可控图像生成模型如DALL-E-2,ImaGen,Stable Diffusion做了详细介绍。 https://mp.weixin.qq.com/s/qJweKUrwLcOjXQatE3VHlQdiffusion model 最近在图像生成领域大红大紫,如何看待它的风头开始超过 GAN ? - 知乎最近在做和扩散模型相关的项目,希望边学习边探索,能圆满完成这个工作。DDPM (NeurIPS-20)DDPM正向的扩…
https://mp.weixin.qq.com/s/qJweKUrwLcOjXQatE3VHlQdiffusion model 最近在图像生成领域大红大紫,如何看待它的风头开始超过 GAN ? - 知乎最近在做和扩散模型相关的项目,希望边学习边探索,能圆满完成这个工作。DDPM (NeurIPS-20)DDPM正向的扩… https://www.zhihu.com/question/536012286/answer/2516184924diffusion model 最近在图像生成领域大红大紫,如何看待它的风头开始超过 GAN ? - 知乎更新:我在第4章增加了离散时间的diffusion model的最新研究进展,欢迎大家关注!======================…https://www.zhihu.com/question/536012286/answer/2533146567
https://www.zhihu.com/question/536012286/answer/2516184924diffusion model 最近在图像生成领域大红大紫,如何看待它的风头开始超过 GAN ? - 知乎更新:我在第4章增加了离散时间的diffusion model的最新研究进展,欢迎大家关注!======================…https://www.zhihu.com/question/536012286/answer/2533146567

通过AE模型可以看到,只要有有效的数据的Latent Attribute表示,那么就可以通过Decoder来生成新数据,但是在AE模型中,Latent是通过已有数据生成的,所以没法生成已有数据外的新数据。
所以我们设想,是不是可以假设Latent 符合一定分布规律,只要通过有限参数能够描述这个分布,那么就可以通过这个分布得到不在训练数据中的新Latent ,利用这个新Latent就能生成全新数据,基于这个思路,有了VAE(Variational AutoEncoder 变分自编码器)
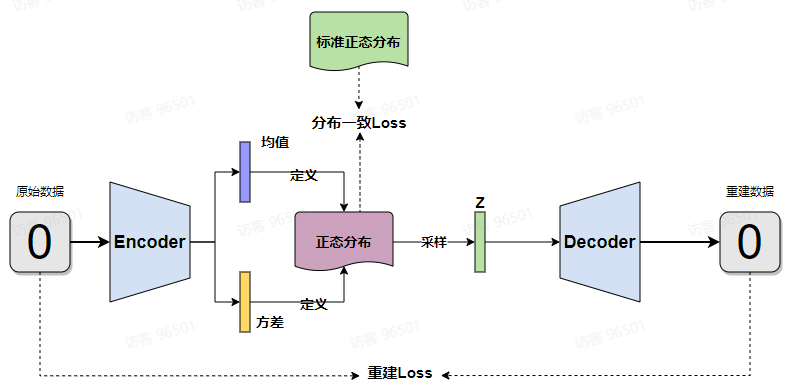

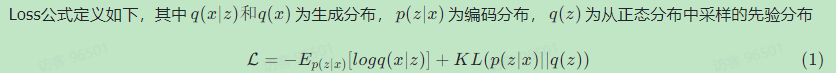


图片的上面部分是去噪,上面部分是加噪。
1.前向加噪
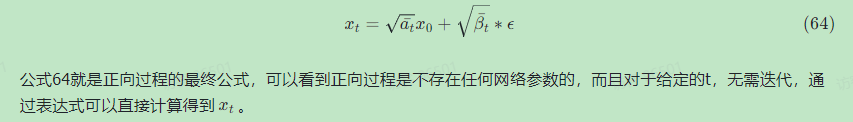
加噪过程就是简单的变分后验过程。
2.后向去噪

常见的DDPM都是unet实现的。

这里的扩散的思路和vae是一致的,vae通过变分后验(学出来的)将样本数据转到高斯分布,再通过生成器将高斯分布转到生成样本,扩散的核心思路就是通过一种简单的变分后验将样本转到高斯,再慢慢一步一步的将高斯转到原始数据空间,一种简单的变分后验对应的就是去噪过程,生成器的一步一步扩散对应的就是加噪过程,无参的加噪过程非常容易,把数据分布映射到高斯分布非常容易,我们只需要构造一个平稳分布是标准高斯分布的马尔科夫链即可。我们可以适当构造马尔科夫链,使得不管从什么分布出发,沿着马尔科夫链一致采样下去最终可以得到某个你想要的平稳分布。
使用DDPM的时候,我们依然希望可以通过条件控制生成,如前边提到的DALLE-2,Stable Diffusion都是通过条件(文本prompt)来控制生成的图像,为了实现这个目的,就需要采用Conditional Diffusion Model。
目前主流的condition diffusion model主要有两种实现方式,classifier-guidance和classifier-free,前者需要一个分类模型,后者无须分类器模型。分类器模型对前向过程融入噪音的数据很好的分类,在扩散模型求梯度的阶段,融入这个分类模型对当前噪音数据的梯度即可。free就是对特征学习一个embedding表示,然后采样性的加入unet的encoder的阶段。
后续的几篇文章包括:
DDIM:
classifier-free guidance diffusion
Glide
Dalle-1
Dalle-2
Imagen

ldm
controlnet