原创作者:峰哥ge
原创地址:
https://www.cnblogs.com/FengGeBlog/p/10305318.html
logstash过滤器插件filter
grok正则捕获
grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。他是目前logstash 中解析非结构化日志数据最好的方式
grok的语法规则是:
%{语法:语义}
“语法”指的是匹配的模式。例如使用NUMBER模式可以匹配出数字,IP模式则会匹配出127.0.0.1这样的IP地址。
例如:
我们的试验数据是:
172.16.213.132 [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039
我们举个例子来讲解过滤IP
input {
stdin {
}
}
filter{
grok{
match => {"message" => "%{IPV4:ip}"}
}
}
output {
stdout {
}
}
现在启动一下:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l2.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET /HTTP/1.1" 403 5039 #手动输入此行信息
{
"message" => "172.16.213.132 [07/Feb/2018:16:24:19 +0800]\"GET /HTTP/1.1\" 403 5039",
"ip" => "172.16.213.132",
"@version" => "1",
"host" => "ip-172-31-22-29.ec2.internal",
"@timestamp" => 2019-01-22T09:48:15.354Z
}
举个例子来讲解过滤时间戳
input与output字段信息这里省略不写了。
filter{
grok{
match => {"message" => "%{IPV4:ip}\ \[%{HTTPDATE:timestamp}\]"}
}
}
接下来我们过滤一下:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l2.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 [07/Feb/2018:16:24:19 +0800]"GET /HTTP/1.1" 403 5039 手动输入此行信息
{
"@version" => "1",
"timestamp" => "07/Feb/2018:16:24:19 +0800",
"@timestamp" => 2019-01-22T10:16:14.205Z,
"message" => "172.16.213.132 [07/Feb/2018:16:24:19 +0800]\"GET /HTTP/1.1\" 403 5039",
"ip" => "172.16.213.132",
"host" => "ip-172-31-22-29.ec2.internal"
}
可以看到我们已经过滤成功了,在配置文件中grok其实是使用正则表达式来进行过滤的。我们做个小实验,比如我现在在例子中的数据ip后面添加两个“-”。如图所示:
172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039
那么此时在配置文件中我就需要这样子来写:
filter{
grok{
match => {"message" => "%{IPV4:ip}\ -\ -\ \[%{HTTPDATE:timestamp}\]"}
}
}
那么此时在match行我就要匹配两个“-”,否则grok就不能正确匹配数据,从而不能解析数据。
启动一下来查看一下结果:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l2.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行内容,然后按下enter键。
{
"@timestamp" => 2019-01-22T10:25:46.687Z,
"ip" => "172.16.213.132",
"message" => "172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] \"GET /HTTP/1.1\" 403 5039",
"timestamp" => "07/Feb/2018:16:24:19 +0800",
"@version" => "1",
"host" => "ip-172-31-22-29.ec2.internal"
}
这时候我们就得到了信息,我这里是匹配IP和时间,当然你也可以直接匹配时间即可:
filter{
grok{
match => {"message" => "\ -\ -\ \[%{HTTPDATE:timestamp}\]"}
}
}
这个时候我们更加能理解grok使用正则匹配数据了。
需要注意的是:正则中,匹配空格和中括号要加上转义符。
过滤出报文头信息
首先来写匹配的正则模式
filter{
grok{
match => {"message" => "\ %{QS:referrer}\ "}
}
}
启动一下看看结果:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l2.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039
{
"@timestamp" => 2019-01-22T10:47:37.127Z,
"message" => "172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] \"GET /HTTP/1.1\" 403 5039",
"@version" => "1",
"host" => "ip-172-31-22-29.ec2.internal",
"referrer" => "\"GET /HTTP/1.1\""
}
举一反三,我们尝试输出一下/var/log/message字段的时间信息。
例子的数据:
Jan 20 11:33:03 ip-172-31-22-29 systemd: Removed slice User Slice of root.
我们的目的是输出时间,也就是前三列而已。
这个时候我们可以去找匹配的正则有哪些,要去这个路径下找:/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns目录下的grok-patterns这个文件,我们发现了这个:
正好非常符合上面输出的信息。
首先写好配置文件
filter{
grok{
match => {"message" => "%{SYSLOGTIMESTAMP:time}"}
remove_field => ["message"]
}
}
启动一下看看情况:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l4.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
Jan 20 11:33:03 ip-172-31-22-29 systemd: Removed slice User Slice of root. #手动输入此行信息。
{
"@timestamp" => 2019-01-22T11:54:26.646Z,
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1",
"time" => "Jan 20 11:33:03"
}
看到结果已经转换成功了,非常好用的工具。
date插件
在上面我们有个例子是讲解timestamp字段,表示取出日志中的时间。但是在显示的时候除了显示你指定的timestamp外,还有一行是@timestamp信息,这两个时间是不一样的,@timestamp表示系统当前时间。两个时间并不是一回事,在ELK的日志处理系统中,@timestamp字段会被elasticsearch用到,用来标注日志的生产时间,如此一来,日志生成时间就会发生混乱,要解决这个问题,需要用到另一个插件,即date插件,这个时间插件用来转换日志记录中的时间字符串,变成Logstash::Timestamp对象,然后转存到@timestamp字段里面
接下来我们在配置文件中配置一下:
filter{
grok{
match => {"message" => "\ -\ -\ \[%{HTTPDATE:timestamp}\]"}
}
date{
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
注意:时区偏移量需要用一个字母Z来转换。还有这里的“dd/MMM/yyyy”,你发现中间是三个大写的M,没错,这里确实是三个大写的M,我尝试只写两个M的话,转换失败
启动一下我们看看效果:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l2.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行信息
{
"host" => "ip-172-31-22-29.ec2.internal",
"timestamp" => "07/Feb/2018:16:24:19 +0800",
"@timestamp" => 2018-02-07T08:24:19.000Z,
"message" => "172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] \"GET /HTTP/1.1\" 403 5039",
"@version" => "1"
}
会发现@timestamp时间转换成功,因为我写这篇博客是在2019年1月22日写的。还有一点就是在时间少8个小时,你发现了吗?继续往下看
remove_field的用法
remove_field的用法也是很常见的,他的作用就是去重,在前面的例子中你也看到了,不管是我们要输出什么样子的信息,都是有两份数据,即message里面是一份,HTTPDATE或者IP里面也有一份,这样子就造成了重复,过滤的目的就是筛选出有用的信息,重复的不要,因此我们看看如何去重呢?
我们还是以输出IP为例:
filter{
grok{
match => {"message" => "%{IP:ip_address}"}
remove_field => ["message"]
}
}
启动服务查看一下:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l5.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行内容并按enter键
{
"ip_address" => "172.16.213.132",
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1",
"@timestamp" => 2019-01-22T12:16:58.918Z
}
这时候你会发现没有之前显示的那个message的那一行信息了。因为我们使用remove_field把他移除了,这样的好处显而易见,我们只需要日志中特定的信息而已。
在上面的几个例子中我们是把message一行的信息一个一个分开演示了,现在我想在一个logstash中全部显示出来。
我们先在配置文件中配置一下:
filter{
grok{
match => {"message" => "%{IP:ip_address}\ -\ -\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:status}\ %{NUMBER:bytes}"}
}
date{
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
}
}
启动一下,看看情况:
[root@172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l5.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行内容
{
"status" => "403",
"bytes" => "5039",
"message" => "172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] \"GET /HTTP/1.1\" 403 5039",
"ip_address" => "172.16.213.132",
"timestamp" => "07/Feb/2018:16:24:19 +0800",
"@timestamp" => 2018-02-07T08:24:19.000Z,
"referrer" => "\"GET /HTTP/1.1\"",
"@version" => "1",
"host" => "ip-172-31-22-29.ec2.internal"
}
在这个例子中,你能感受到输出内容的臃肿,相当于输出了两份的内容,因此我们很有必要将原始内容message的这一行给去掉。
使用remove_field去掉message这一行的信息
首先我们修改一下配置文件:
filter{
grok{
match => {"message" => "%{IP:ip_address}\ -\ -\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:status}\ %{NUMBER:bytes}"}
}
date{
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate{
remove_field => ["message","timestamp"]
}
启动一下看看
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l5.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行内容尝试一下
{
"referrer" => "\"GET /HTTP/1.1\"",
"bytes" => "5039",
"host" => "ip-172-31-22-29.ec2.internal",
"@timestamp" => 2018-02-07T08:24:19.000Z,
"status" => "403",
"ip_address" => "172.16.213.132",
"@version" => "1"
}
看到了吗这就是我们想要的最终结果
时间处理(date)
上面有几个例子已经讲到了date的用法。date插件对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成Logstash::timestamp对象,然后转存到@timestamp字段里面。
为什么要使用这个插件呢?
1、一方面由于Logstash会给收集到的每条日志自动打上时间戳(即@timestamp),但是这个时间戳记录的是input接收数据的时间,而不是日志生成的时间(因为日志生成时间与input接收的时间肯定不同),这样就可能导致搜索数据时产生混乱。
2、另一方面,在上面那段rubydebug编码格式的输出中,@timestamp字段虽然已经获取了timestamp字段的时间,但是仍然比北京时间晚了8个小时,这是因为在Elasticsearch内部,对时间类型字段都是统一采用UTC时间,而日志统一采用UTC时间存储,是国际安全、运维界的一个共识。其实这并不影响什么,因为ELK已经给出了解决方案,那就是在Kibana平台上,程序会自动读取浏览器的当前时区,然后在web页面自动将UTC时间转换为当前时区的时间。
如果你要解析你的时间,你要使用字符来代替,用于解析日期和时间文本的语法使用字母来指示时间(年、月、日、时、分等)的类型。以及重复的字母来表示该值的形式。在上面看到的"dd/MMM/yyy:HH:mm:ss Z",他就是使用这种形式,我们列出字符的含义:
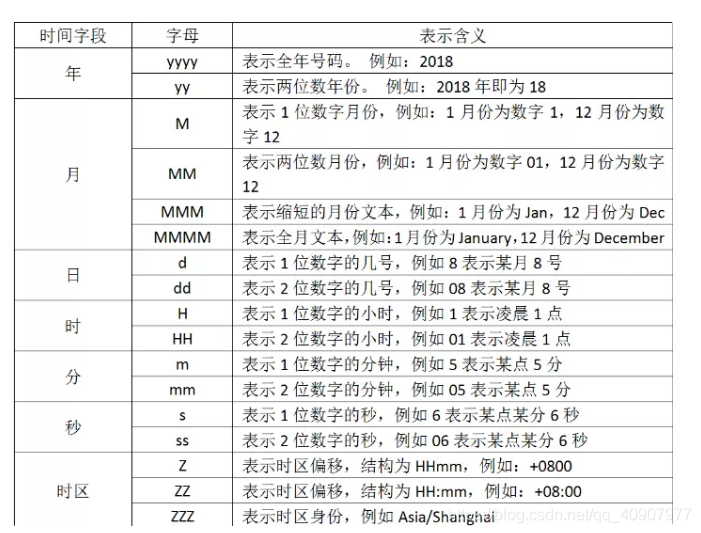
那我们是依据什么写出“dd/MMM/yyy:HH:mm:ss Z”这样子的形式的呢?
这一点不好理解,给大家尽量说清楚。比如上面的试验数据是
172.16.213.132 - - [07/Feb/2018:16:24:19 +0800] "GET /HTTP/1.1" 403 5039
现在我们想转换时间,那就要写出"dd/MMM/yyy:HH:mm:ss Z",你发现中间有三个M,你要是写出两个就不行了,因为我们查表发现两个大写的M表示两位数字的月份,可是我们要解析的文本中,月份则是使用简写的英文,所以只能去找三个M。还有最后为什么要加上个大写字母Z,因为要解析的文本中含有“+0800”时区偏移,因此我们要加上去,否则filter就不能正确解析文本数据,从而转换时间戳失败。
数据修改mutate插件
mutate插件是logstash另一个非常重要的插件,它提供了丰富的基础类型数据处理能力,包括重命名、删除、替换、修改日志事件中的字段。我们这里举几个常用的mutate插件:字段类型转换功能covert、正则表达式替换字段功能gsub、分隔符分隔字符串为数值功能split、重命名字段功能rename、删除字段功能remove_field
字段类型转换convert
先修改配置文件:
filter{
grok{
match => {"message" => "%{IPV4:ip}"}
remove_field => ["message"]
}
mutate{
convert => ["ip","string"]
}
}
或者这样子写也行,写法区别较小:
filter{
grok{
match => {"message" => "%{IPV4:ip}"}
remove_field => ["message"]
}
mutate{
convert => {
"ip" => "string"
}
}
}
现在我们启动服务查看一下效果:
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l6.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties172.16.213.132 - - [07/Feb/2018:16:24:9 +0800] "GET /HTTP/1.1" 403 5039
{
"@timestamp" => 2019-01-23T04:13:55.261Z,
"ip" => "172.16.213.132",
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1"
}
在这里的ip行中,效果可能不太明显,但是确实是已经转化成string模式了。
正则表达式替换匹配字段
gsub可以通过正则表达式替换字段中匹配到的值,但是这本身只对字符串字段有效。
首先把修改配置文件看看
filter{
grok{
match => {"message" => "%{QS:referrer}"}
remove_field => ["message"]
}
mutate{
gsub => ["referrer","/","-"]
}
}
启动一下看看效果:
172.16.213.132 - - [07/Feb/2018:16:24:9 +0800] "GET /HTTP/1.1" 403 5039
{
"host" => "ip-172-31-22-29.ec2.internal",
"@timestamp" => 2019-01-23T05:51:30.786Z,
"@version" => "1",
"referrer" => "\"GET -HTTP-1.1\""
}
很不错,确实对QS的部分的分隔符换做横杠了
分隔符分隔字符串为数组
split可以通过指定的分隔符分隔字段中的字符串为数组。
首先配置文件
filter{
mutate{
split => ["message","-"]
add_field => ["A is lower case :","%{[message][0]}"]
}
}
这里的意思是对一个字段按照“-”进行分隔为数组
启动一下
a-b-c-d-e-f-g #手动输入此行内容,并按下enter键。
{
"A is lower case :" => "a",
"message" => [
[0] "a",
[1] "b",
[2] "c",
[3] "d",
[4] "e",
[5] "f",
[6] "g"
],
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1",
"@timestamp" => 2019-01-23T06:07:18.062Z
}
重命名字段
rename可以实现重命名某个字段的功能
filter{
grok{
match => {"message" => "%{IPV4:ip}"}
remove_field => ["message"]
}
mutate{
convert => {
"ip" => "string"
}
rename => {
"ip"=>"IP"
}
}
}
rename字段使用大括号{}括起来,其实我们也可以使用中括号达到同样的目的
mutate{
convert => {
"ip" => "string"
}
rename => ["ip","IP"]
}
启动后检查一下:
172.16.213.132 - - [07/Feb/2018:16:24:9 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此内容
{
"@version" => "1",
"@timestamp" => 2019-01-23T06:20:21.423Z,
"host" => "ip-172-31-22-29.ec2.internal",
"IP" => "172.16.213.132"
}
删除字段,这个不多说,我们上面已经有例子了
添加字段add_field
添加字段多用于split分隔中,主要是对split分隔后的字段中指定格式输出。
filter {
mutate {
split => ["message", "|"]
add_field => {
"timestamp" => "%{[message][0]}" } }}
添加字段后,该字段会与@timestamp一样同等格式显示出来。
geoip地址查询归类
geoip是常见的免费的IP地址归类查询库,geoip可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等等,此插件对于可视化地图和区域统计非常有用。
首先我们修改一下配置文件来看看
filter{
grok {
match => {
"message" => "%{IP:ip}"
}
remove_field => ["message"]
}
geoip {
source => "ip"
}
}
中间match的部分也可以替换成下图例子:
grok {
match => ["message","%{IP:ip}"]
remove_field => ["message"]
}
启动一下看看效果
[root@:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l7.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
114.55.68.111 - - [07/Feb/2018:16:24:9 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行信息
{
"ip" => "114.55.68.111",
"geoip" => {
"city_name" => "Hangzhou",
"region_code" => "33",
"location" => {
"lat" => 30.2936,
"lon" => 120.1614
},
"longitude" => 120.1614,
"latitude" => 30.2936,
"country_code2" => "CN",
"timezone" => "Asia/Shanghai",
"ip" => "114.55.68.111",
"country_code3" => "CN",
"continent_code" => "AS",
"country_name" => "China",
"region_name" => "Zhejiang"
},
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1",
"@timestamp" => 2019-01-23T06:47:51.200Z
}
成功了。
但是上面的内容并不是每个都是我们想要的,因此我们可以选择性的输出。
继续修改内容如下:
filter{
grok {
match => ["message","%{IP:ip}"]
remove_field => ["message"]
}
geoip {
source => ["ip"]
target => ["geoip"]
fields => ["city_name","region_name","country_name","ip"]
}
}
启动一下看看:
114.55.68.111 - - [07/Feb/2018:16:24:9 +0800] "GET /HTTP/1.1" 403 5039 #手动输入此行信息
{
"@timestamp" => 2019-01-23T06:57:29.955Z,
"ip" => "114.55.68.111",
"geoip" => {
"city_name" => "Hangzhou",
"ip" => "114.55.68.111",
"country_name" => "China",
"region_name" => "Zhejiang"
},
"@version" => "1",
"host" => "ip-172-31-22-29.ec2.internal"
}
发现输出的内容果然变少了,我们想输出什么他就输出什么内容。
filter插件综合应用
我们的业务例子如下所示:
112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] "GET / HTTP/1.1" 200 190 "-" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36" "-"
日志中的双引号、单引号、中括号等不能被正则解析的都要加上转义符号,详情可见这里:https://www.cnblogs.com/ysk123/p/9858387.html
现在我们修改配置文件进行匹配
filter{
grok {
match => ["message","%{IPORHOST:client_ip}\ -\ -\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:status}\ %{NUMBER:bytes}\ \"-\"\ \"%{DATA:browser_info}\ %{GREEDYDATA:extra_info}\"\ \"-\""]
}
geoip {
source => ["client_ip"]
target => ["geoip"]
fields => ["city_name","region_name","country_name","ip"]
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
remove_field => ["message","timestamp"]
}
}
然后启动一下看看效果:
[root@:vg_adn_tidbCkhsTest:23.22.172.65:172.31.22.29 /etc/logstash/conf.d]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/l9.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] "GET / HTTP/1.1" 200 190 "-" "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36" "-"
{
"referrer" => "\"GET / HTTP/1.1\"",
"bytes" => "190",
"client_ip" => "112.195.209.90",
"@timestamp" => 2018-02-20T04:12:14.000Z,
"browser_info" => "Mozilla/5.0",
"extra_info" => "(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36",
"status" => "200",
"host" => "ip-172-31-22-29.ec2.internal",
"@version" => "1",
"geoip" => {
"city_name" => "Chengdu",
"region_name" => "Sichuan",
"country_name" => "China",
"ip" => "112.195.209.90"
}
}
上面红色字体的是我们手动输入进去的内容,下面金色字体是系统反馈给我们的信息。
通过信息我们可以查看信息已经过滤成功了。非常好。
注意:有一点需要注意:在匹配信息的时候,GREEDYDATA与DATA匹配的机制是不一样的,GREEDYDATA是贪婪模式,而DATA则是能少匹配一点就少匹配一点。通过上面的例子大家再体会一下。
最后给大家提供一个可以快速调试grok正则表达式的网站:http://grokdebug.herokuapp.com/ 。目的就是帮助万魔门编写grok正则匹配组合语句。
转载来源 :
原创作者:峰哥ge
原创地址:
https://www.cnblogs.com/FengGeBlog/p/10305318.html
logstash过滤器插件filter详解及实例 : https://mp.weixin.qq.com/s/9nOFgtlasc-kse-bwA9ABA