Hudi Log 文件格式与读写流程
背景
对 Hudi 有一定了解的读者应该知道,Hudi 有 COW 和 MOR 两种表类型。其中的 MOR 表会通过日志文件记录文件,写入一个 MOR 表后产生的文件可以观察到,一个 MOR 表数据存储在3种文件中:Log File(.*log.*),分区元数据(.hoodie_partition_metadata),数据文件(.*parquet)。期间查阅了大量的相关资料,发现发现鲜有文章对 Log 日志数据文件的具体内容与结构做详细的介绍。原因之一可能是:虽然 Log 文件使用了 Avro 序列化的行式存储,但其仅在对 records 的序列化时使用了原生 avro 的标准,文件其余部分的编码为 Hudi 自己的格式,进而导致其无法使用avro-tools.jar对其进行查看。本文介绍内容如下:
Log 文件读写流程
本文基于 Hudi 0.9.0 版本进行分析。形如Log File(.*log.*)的日志文件,由于无法直接使用工具查看内容,所以主要从源码的层面分析日志文件的写入和读取内容。
写入流程
整个写入流程的代码实现在:org.apache.hudi.common.table.log.HoodieLogFormatWriter#appendBlocks
for (HoodieLogBlock block: blocks) {
long startSize = outputStream.size();
// 1. Write the magic header for the start of the block
outputStream.write(HoodieLogFormat.MAGIC);
// bytes for header
byte[] headerBytes = HoodieLogBlock.getLogMetadataBytes(block.getLogBlockHeader());
// content bytes
byte[] content = block.getContentBytes();
// bytes for footer
byte[] footerBytes = HoodieLogBlock.getLogMetadataBytes(block.getLogBlockFooter());
// 2. Write the total size of the block (excluding Magic)
outputStream.writeLong(getLogBlockLength(content.length, headerBytes.length, footerBytes.length));
// 3. Write the version of this log block
outputStream.writeInt(currentLogFormatVersion.getVersion());
// 4. Write the block type
outputStream.writeInt(block.getBlockType().ordinal());
// 5. Write the headers for the log block
outputStream.write(headerBytes);
// 6. Write the size of the content block
outputStream.writeLong(content.length);
// 7. Write the contents of the data block
outputStream.write(content);
// 8. Write the footers for the log block
outputStream.write(footerBytes);
// 9. Write the total size of the log block (including magic) which is everything written
// until now (for reverse pointer)
// Update: this information is now used in determining if a block is corrupt by comparing to the
// block size in header. This change assumes that the block size will be the last data written
// to a block. Read will break if any data is written past this point for a block.
outputStream.writeLong(outputStream.size() - startSize);
// Fetch the size again, so it accounts also (9).
sizeWritten += outputStream.size() - startSize;
}
总结为流程图如下:
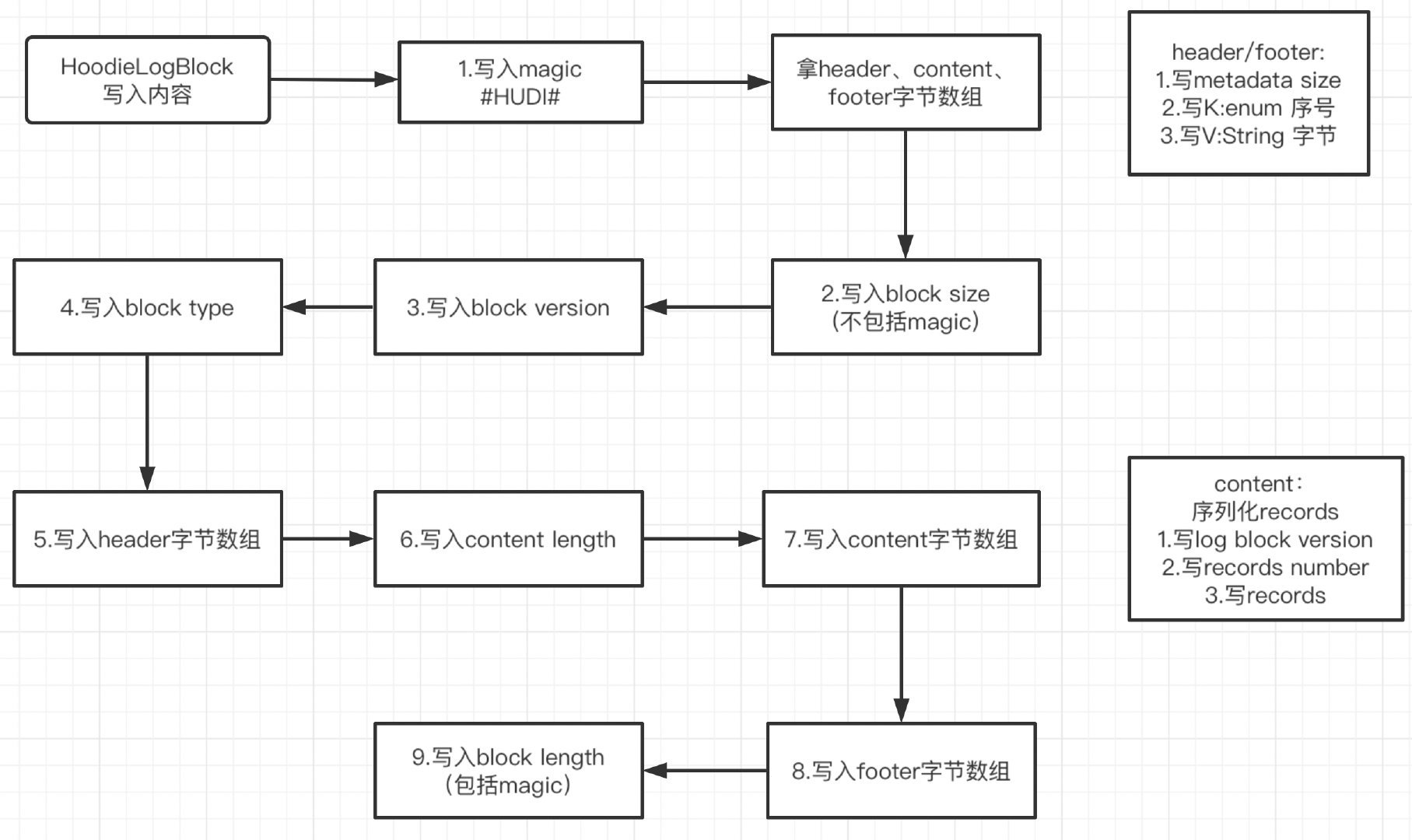
从图中可以看出,写入内容逻辑比较清晰:
- 写入Magic,内容为
#HUDI#。
- 拿到header,footer的字节数组。header/footer类型为Map。字节数组中会写入此Map的size,Map的Key(enum类型)的序号,Value为String类型
- 拿到content的字节数组。会序列化records,字节数组中会写入log block version,records的数量和avro序列化后的records
- 写入block size,不包括Magic的6个字节。
- 写入log format version。
- 写入block type,为枚举类型,写入的是枚举的序号转化为字节数组。
- 写入header字节数组。
- 写入content length。
- 写入content字节数组。
- 写入footer字节数组。
- 写入block length,包括Magic的6个字节。
读取流程
整个读取流程的代码实现在:org.apache.hudi.common.table.log.HoodieLogFileReader#readBlock
总结为流程图如下:
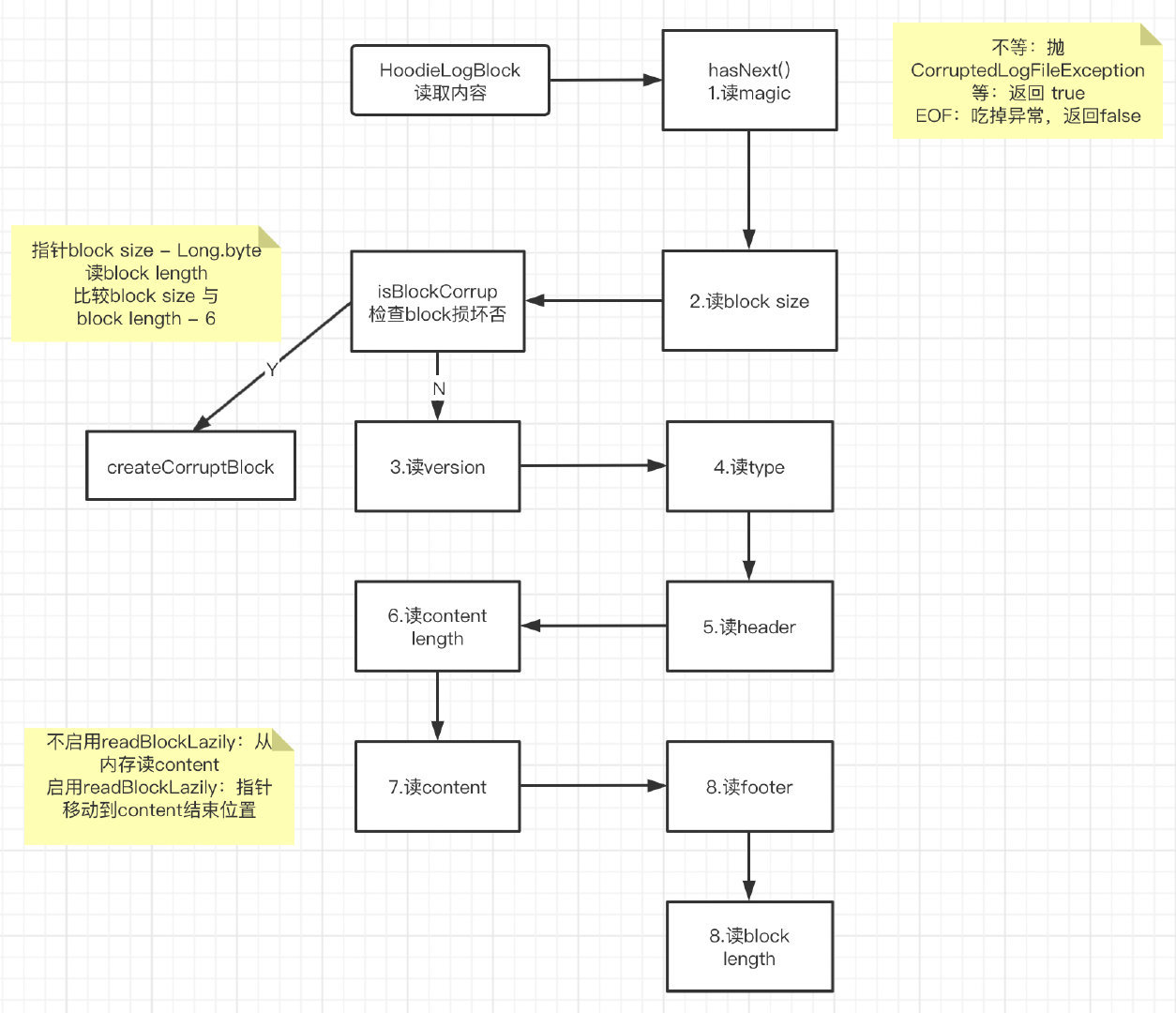
在读取流程中,会涉及一些校验的动作:
- 在hasNext()方法中,读取Magic。
- 校验Magic。不相等,抛CorruptedLogFileException异常;相等,返回true;EOF到达文件尾部,吃掉异常,返回false。
- 读block size。
- 校验block是否损坏。方式为指针移动 block size减去long类型字节长度 的位置,读取block length,比较 block size与block length减去Magic字节长度 是否相等。不相等,createCorruptBlock;相等继续。
- 读log format version。
- 读block type。
- 读header。
- 读content length。
- 读content。
- 不启用readBlockLazily,从内存度content;启用readBlockLazily,指针移动到content结束位置。
- 读footer。
- 读block length。
Log 文件结构分析
Hudi 中与日志文件有关类的继承关系可以看下图: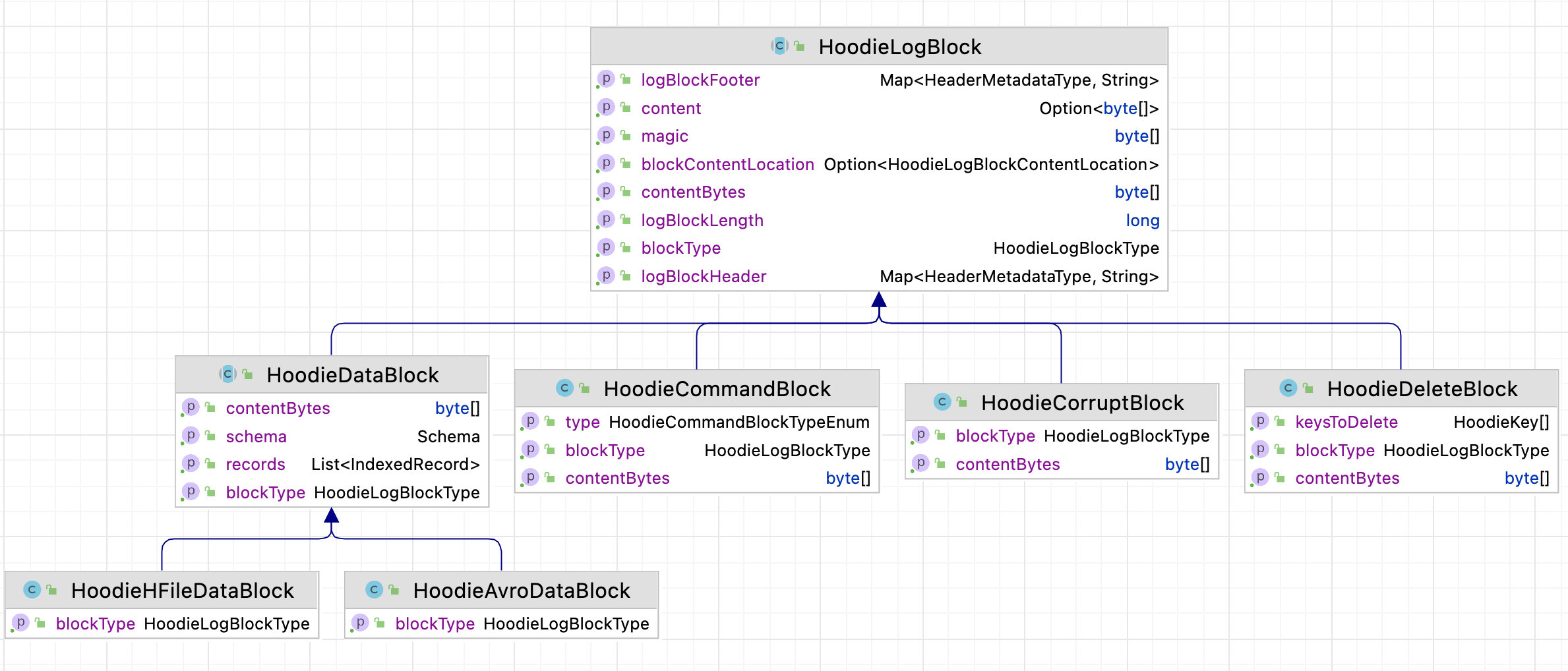
可以看出,Log 文件的公共部分属性主要在HoodieLogBlock中进行定义,数据部分的属性主要在HoodieLogBlock中进行定义,数据部分content的序列化与反序列化实现在HoodieAvroDataBlock中定义。
从上述读写流程,也可以总结出 Log 文件结构:
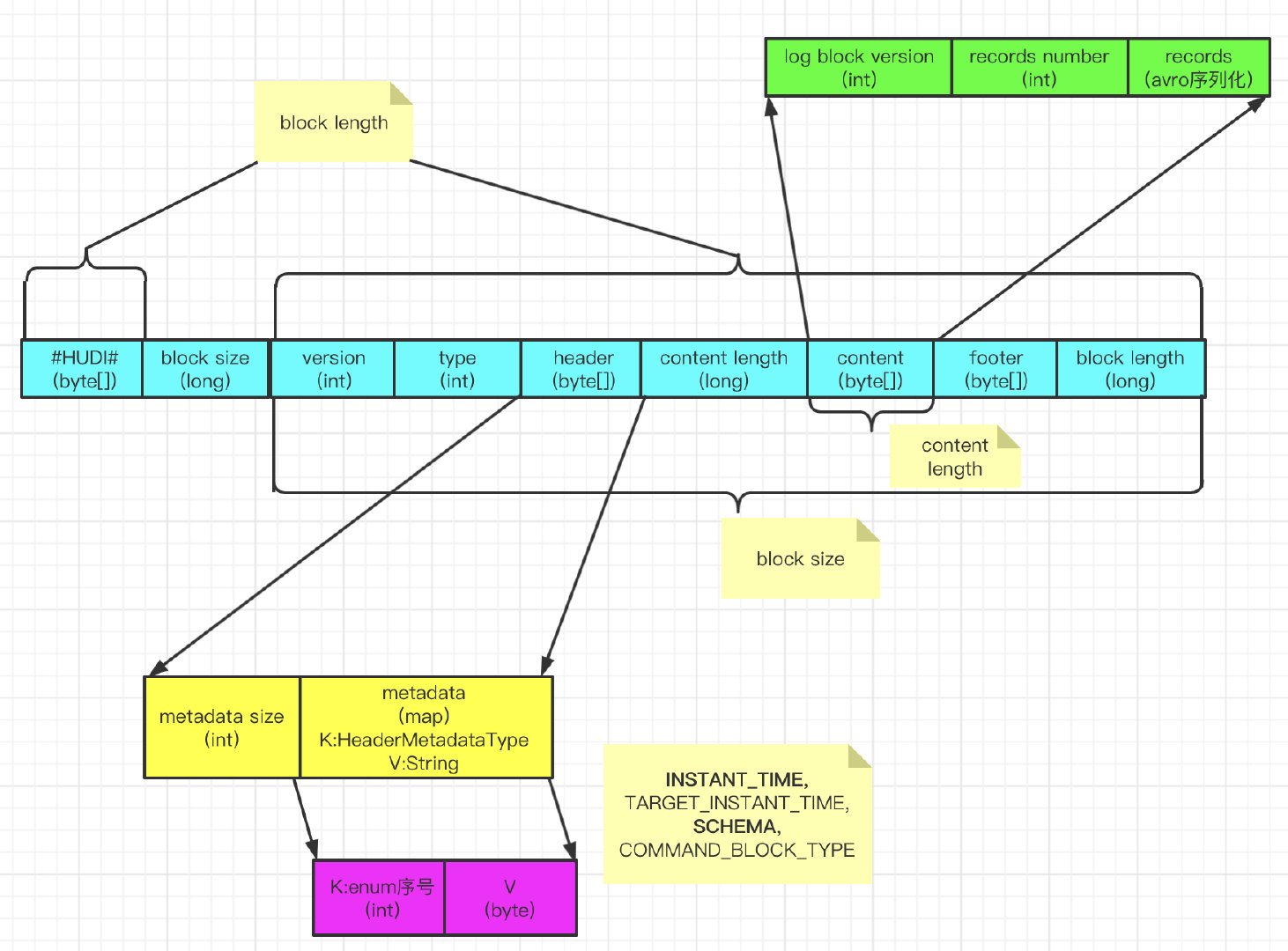
-
Magic:#HUDI#,字节数组类型。
-
blcok size:除了Magic的6字节长度和自身long类型8字节长度,long类型。
-
log format version:日志格式版本,现在是1,int类型。
-
block type:本身是枚举类型,有
COMMAND_BLOCK, DELETE_BLOCK, CORRUPT_BLOCK, AVRO_DATA_BLOCK, HFILE_DATA_BLOCK,这里为枚举的序号,int类型。
-
header:字节数组,本身是Map,转换为字节数组时会将map的size写入字节数组。map的Key为HeaderMetadataType类型,是个枚举,有
INSTANT_TIME, TARGET_INSTANT_TIME, SCHEMA, COMMAND_BLOCK_TYPE,Value为String类型。
-
content length:content字节数组的长度,long类型。
-
content:字节数组。其中内容为,log block version,int类型;records number,int类型;records序列化的字节数组。
-
footer:字节数组,和header一样,本身是Map,现在版本还没有内容。
-
block length:block size 加上6(Magic的字节数组长度),long类型。
根据 Log 文件的读取逻辑,不难写出解析 Log 日志文件的程序代码。将 Log 文件解析出来后,可以观察到 block length 的数值相较于文件本身大小,相差了8个字节,这8个字节就是 block size 本身long类型的字节长度,进一步证明了上述分析的正确性
总结
至此,对 MOR 表的Log File(.*log.*)文件分析已经全部结束,文章着重分析了文件结构,对读写流程中额外的异常处理没有进一步深入。文中如有遗漏或错误,欢迎指出讨论。
若读完有所收获,欢迎点赞吖~