我正在尝试从头开始构建一个神经网络。
所有人工智能文献都一致认为,权重应该初始化为随机数,以便网络更快地收敛。
但为什么神经网络初始权重被初始化为随机数呢?
我在某处读到这样做是为了“打破对称性”,这使得神经网络学习得更快。打破对称性如何让它学得更快?
将权重初始化为 0 不是一个更好的主意吗?这样权重就能更快地找到它们的值(无论是正值还是负值)?
除了希望权重在初始化时接近最佳值之外,随机权重背后是否还有其他一些基本原理?
打破对称性在这里至关重要,而不是出于性能原因。想象一下多层感知器的前两层(输入层和隐藏层):

在前向传播过程中,隐藏层中的每个单元都会收到信号:
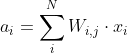
也就是说,每个隐藏单元的输入总和乘以相应的权重。
现在假设您将所有权重初始化为相同的值(例如零或一)。在这种情况下,每个隐藏单元都会得到完全相同的信号。例如。如果所有权重都初始化为 1,则每个单元获得的信号等于输入(和输出)之和sigmoid(sum(inputs)))。如果所有权重都为零,更糟糕的是,每个隐藏单元将得到零信号。无论输入是什么 - 如果所有权重都相同,则隐藏层中的所有单元也将相同.
这是对称性的主要问题,也是您应该随机初始化权重(或者至少使用不同值)的原因。请注意,此问题会影响使用each-to-each连接的所有体系结构。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)