上一篇总结了原著的第六章有关pgsql的函数的用法,本篇将总结pgsql的增删改功能以及相关的sql语句。
插入、更新与删除数据
存储在系统中的数据是数据库管理系统的核心。数据库被设计用来管理数据的存储、访问,维护数据的完整性。PostgreSql中提供了功能丰富的数据库管理语句,包括有效地向数据库中插入数据的INSERT语句、更新数据的UPDATE语句以及当数据不再使用时删除数据的DELETE语句。
目录
插入、更新与删除数据
插入数据
1.为表的所有字段插入数据
2.为表的指定字段插入数据
3.同时插入多条记录
4.将查询结果插入列表中
更新数据
删除数据
综合案例——记录的插入,更新和删除
插入数据
在使用数据库之前,数据库中必须要有数据。在PostgreSql中,使用INSERT语句向数据库中插入新的数据记录,可以插入的方式有插入完整的记录、插入记录的一部分、插入多条记录以及插入另一个查询的结果。
1.为表的所有字段插入数据
使用基本的INSERT语句插入数据要求指定表名名称和插入到新记录中的值,基本语法格式为:
insert into table_name(column_list)values(value_list);
插入 进 表名 (那些列) 值(对应前面列所插入的值)
table_name指定要插入的是哪一个表,column_list指定你要插入的列,value_list指定每个列所对应插入的数据。注意,使用该语句时字段列和数据值的数量必须相同。
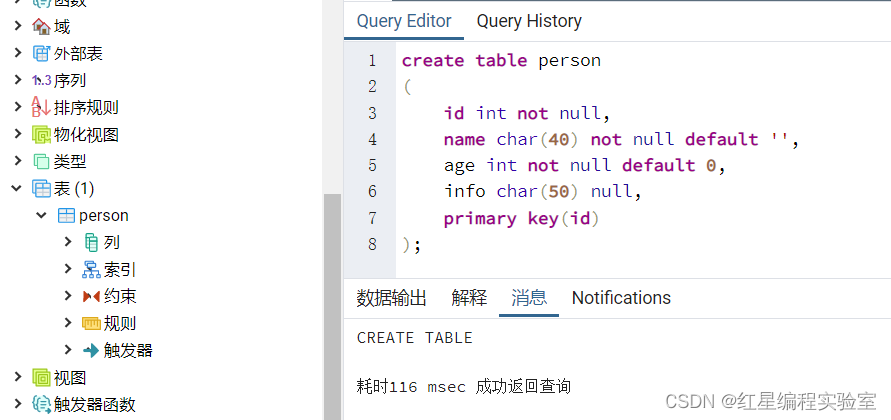
本章会使用以下创建的表(person)来演示本章的sql示例
create table person
(
id int not null,
name char(40) not null default '',
age int not null default 0,
info char(50) null,
primary key(id)
);
向表中所有字段插入值的方法有两种:一种是指定所有字段名,另一种是完全不指定字段名。
例1:在person表中,插入一条新记录,id值为1,name值为Green,age值为21,info值为lawyer。
执行插入语句之前,使用SELECT语句查看表中数据;
SELECT * FROM person;
也可以选中person表,点击小图标快速查看表中的所有数据(往后的表中全部数据查询都将使用该功能快速展示,查表全部数据的sql语句不再提供)
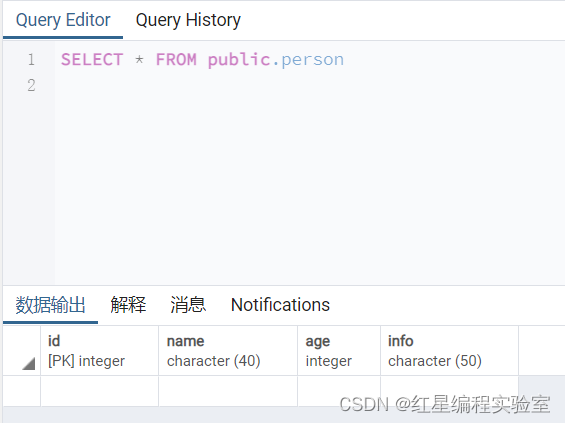
当前显示结果为空,没有数据,下面将插入第一条数据
insert into person(id,name,age,info)values(1,'Green',21,'Lawyer');
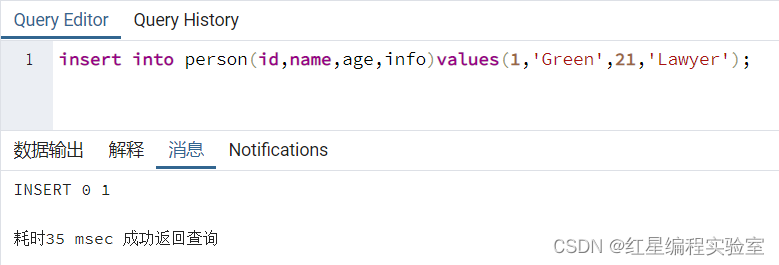
查询结果
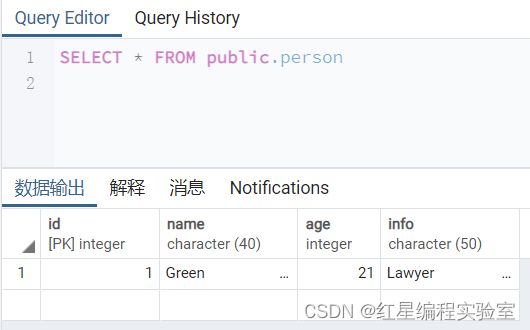
可以看到插入记录成功。在插入数据时,指定了person表的所有字段,因此将为每一个字段插入新的值。
INSERT语句后面的列名称顺序可以不是person表定义时的顺序,即插入数据时不需要按照表定义的顺序插入,只需要保证值的顺序与列字段的顺序相同就可以,如下面的例子所示。
例2.在person表中,插入一条新记录,id的值为2,name值为Suse,age值为22,info值为dancer,sql语句如下。
insert into person(age,name,id,info)values(22,'Suse',2,'Dancer');
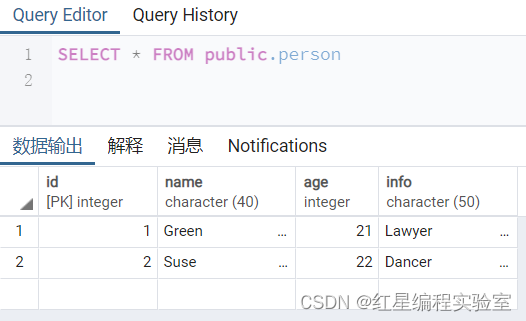
使用INSERT插入数据时,允许列名称列表column_list为空。此时,值列表中需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同。
例3.在person表中,插入一条新记录,sql语句如下:
insert into person values(3,'Mary',24,'Student');
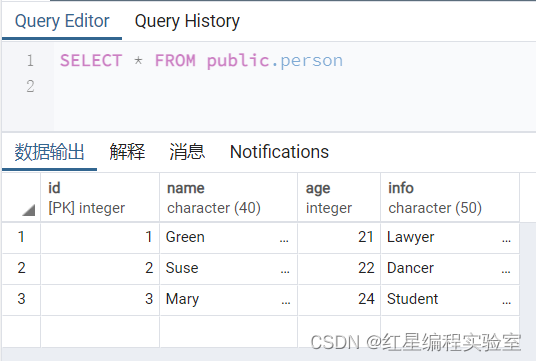
虽然可以使用INSERT插入数据时忽略插入数据的列名称,但是如果不包括列名称,那么VALUES关键字后面的值不但要求必须完整而且顺序必须和表定义时列的顺序相同。如果表的结构被修改,对列进行增加、删除或者位置改变操作,将使得用这种方式插入数据时的顺序也必须同时改变。如果指定列名称,则不会受到表结构改变的影响。
2.为表的指定字段插入数据
为表的指定字段插入数据,就是在INSERT语句中只向部分字段中插入值,而其他字段的值为表定义时的默认值。
例:在person表中,插入一条新记录,id值为4,name值为Laura,age值为25,sql语句如下:
insert into person(id,name,age)values(4,'Laura',25);

3.同时插入多条记录
INSERT语句可以同时向数据表中插入多条记录。插入时指定多个值列表,每个值列表之间用逗号隔开,基本语法格式如下:
insert into 表名(属性列表) values(取值列表1),(取值列表2),...,(取值列表n);
其中,“表名”为需要插入数据的表的名称;“属性列表”为可选参数,指定向哪些字段插入数据,如果没有指定字段,那么默认向所有字段插入数据;“取值列表n”参数表示要插入的记录,各个记录之间用逗号隔开。
例:在person表中,在id、name、age和info字段指定插入值,同时插入3条新记录,sql语句如下:
insert into person(id,name,age,info)values(5,'Evans',27,'Secretary'),(6,'Dale',22,'Cook'),(7,'Eison',28,'Singer');
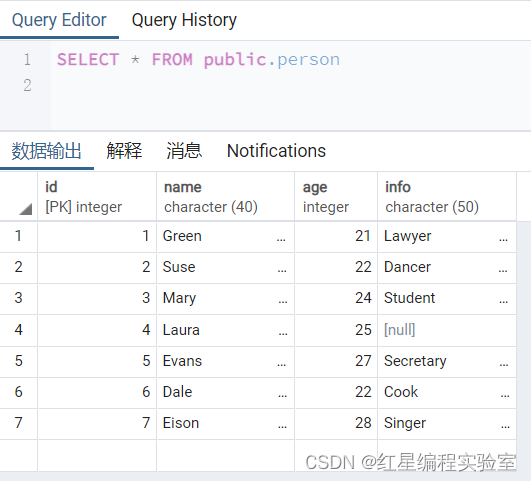
使用INSERT同时插入多条记录时,pgsql会返回一些在执行单行插入时没有的额外信息,这些包含数值的字符串的意思分别是:
(1)Records 表明插入的记录条数
(2)Duplicates 表明插入时被忽略的记录,原因可能是这些记录包含了重复的主键值
(3)Warnings 表明有问题的数据值,例如发生数据类型转换
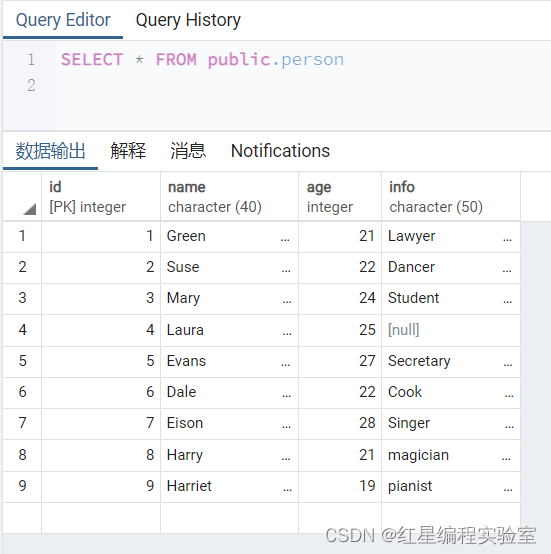
例:在person表中,不指定插入列表,同时插入2条新记录,sql语句如下:
insert into person values(8,'Harry',21,'magician'),(9,'Harriet',19,'pianist');
4.将查询结果插入列表中
INSERT语句用来给数据表插入记录时指定插入记录的列值,INSERT还可以将SELECT语句查询的结果插入到表中,如果想要从另一个表中合并个人信息到person表,不需要把每一条记录的值一个一个输入,只需要使用一条INSERT语句和一条SELECT语句组成的组合语句即可快速的从一个或多个表向一个表中插入多行。基本语法如下:
insert into 表名1(列名) select(列名) from 表名2 where(条件);
例:从person_old的表中查询所有的记录,并将其插入到person表中
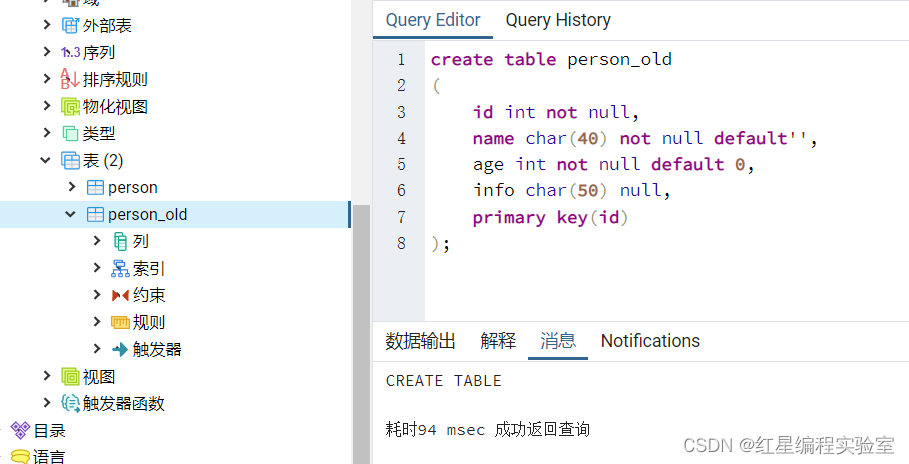
创建一个名为person_old的数据表,其表结构与person表结构相同,SQL语句如下
create table person_old
(
id int not null,
name char(40) not null default'',
age int not null default 0,
info char(50) null,
primary key(id)
);
向person_old的表中添加两条记录
insert into person_old values(10,'harry',20,'student'),(11,'Beckham',31,'police');
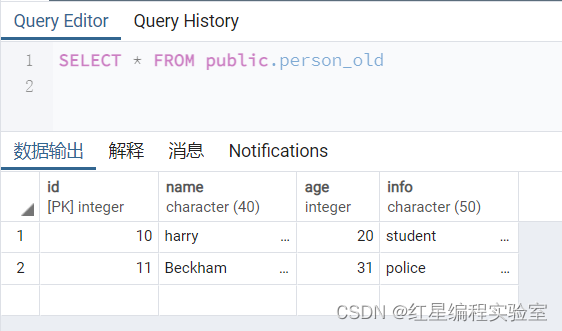
可以看到,插入记录成功,person_old表中现在有两条记录,接下来将person_old的表中所有的记录插入person表中,SQL语句如下:
insert into person(id,name,age,info) select id,name,age,info from person_old;
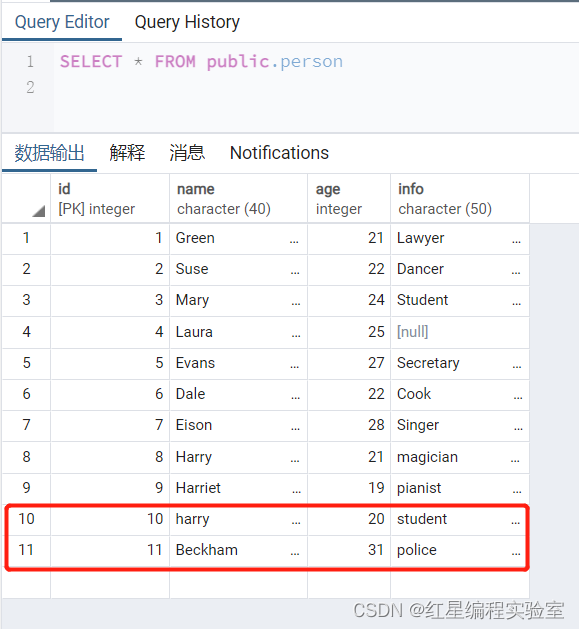
由结果可以看到,INSERT语句执行后,person表中多了两条记录这两条记录和person_old的表中的记录完全相同,数据转移成功,这里的id字段为主键,在插入的时候要保证该字段值的唯一性
更新数据
表中有数据之后,接下来可以对数据进行更新操作,在pgsql中,使用UPDATE语句更新表中的记录,可以更新特定的行或者同时更新所有的行,基本语法结构如下:
update table_name set column_name1 = value1,column_name2 = value2,...,column_namen = valuen where(condition);
column_name1,column_name2,...,column_namen为指定更新的字段的名称;value1,value2,...,valuen为相对应的指定字段的更新值,condition指定更新的记录需要满足的条件。更新多个列时,每个“列-值”对之间用逗号隔开,最后一列之后不需要逗号。
例1:在person表中,更新id值为10的记录,将age字段值改为15,将name字段值改成LiMing。
更新操作执行前可以使用SELECT语句查看当前的数据
select * from person where id=10;
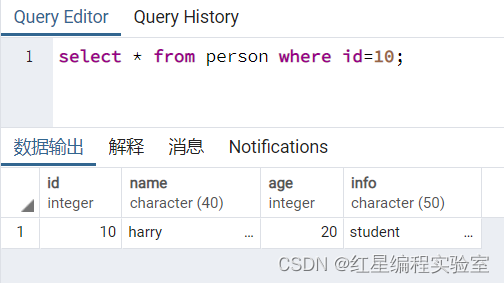
由结果可以看到,更新之前id=10的记录的name的字段值为Harry,age字段值为20。下面使用UPDATE语句更新数据,语句执行结果如下:
update person set age=15,name='LiMing' where id=10;
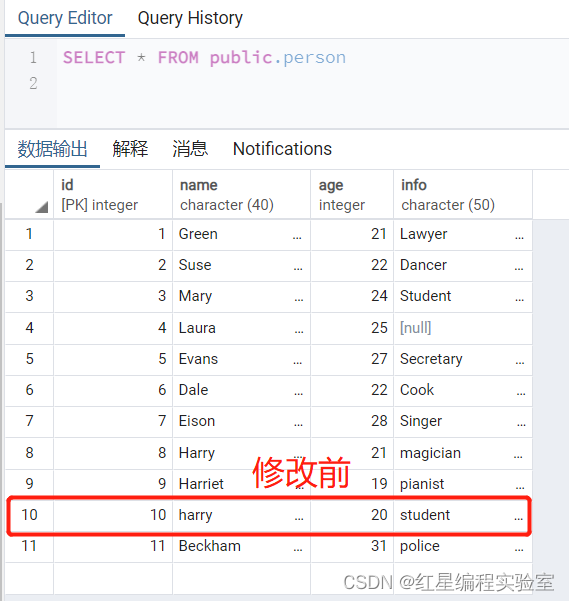
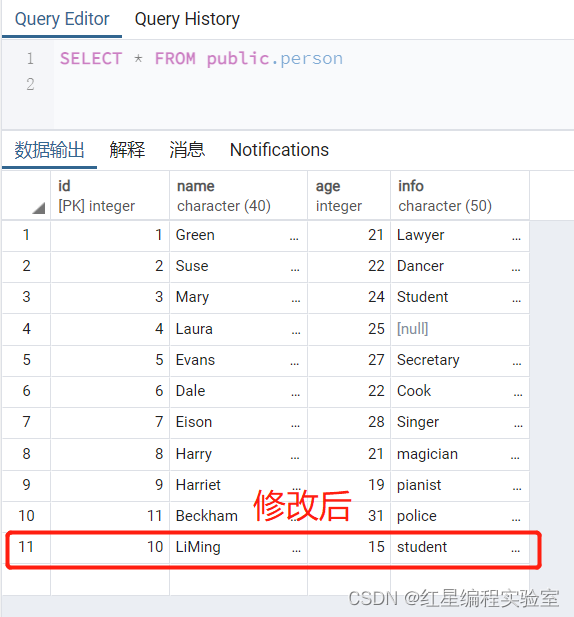
可以看到id=10的数据已经修改,如果希望看到结果按id顺序排列可以在末尾加排序语句
select * from person order by id;
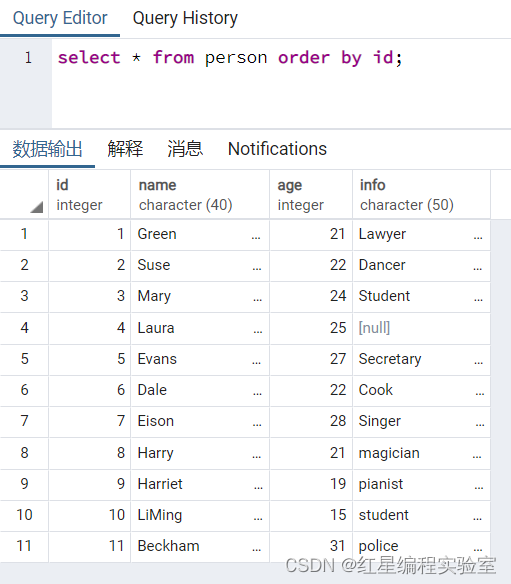
例2:在person表中更新age值为19~22的记录,将Info字段值都改为student
更新操作执行前可以使用SELECT语句查看当前的数据:
select * from person where age between 19 and 22;

可以看到这些age值字段值在19~22之间的记录info字段值各不相同,下面使用UPDATE的语句更新数据,语句执行结果如下:
update person set info='student' where age between 19 and 22;
查看结果
select * from person where age between 19 and 22;
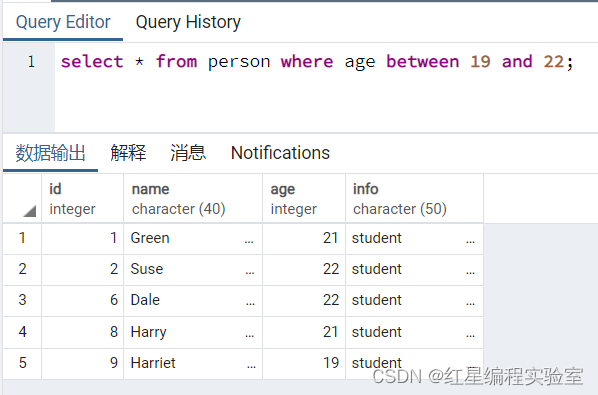
由结果可以看到,UPDATE执行后,成功将表中符合条件的记录的Info字段值都改为了student。
删除数据
从数据表中删除数据使用DELETE语句。DELETE语句允许WHERE子句指定删除条件。DELETE语句的基本语法格式如下:
delete from table_name[where<condition>];
table_name指定要执行删除操作的表。[where<condition>]为可选参数,指定删除条件,如果没有WHERE子句,DELETE语句将删除表中的所有记录。
例1:在person表中删除ID=10的记录
执行删除操作前,使用SELECT语句查看当前id=10的记录。
select * from person where id=10;
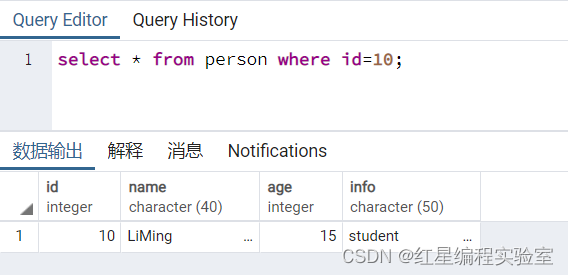
可以看到,现在表中有id=10的记录,下面使用delete语句删除记录。
delete from person where id=10;
语句执行完毕后,查看执行结果。
select * from person where id=10;

查询结果为空,说明删除操作成功。
例2:在person表中使用DELETE语句同时删除多条记录,在前面UPDATE语句中将age字段值在19~22之间的记录info字段值修改为student,在这里删除这些记录。
执行删除操作前,使用select的语句查看当前的数据。
select * from person where age between 19 and 22;

可以看到这些age字段值在19~22之间的记录存在表中。下面使用DELETE删除这些记录。
delete from person where age between 19 and 22;
语句执行完毕,查看执行结果。
select * from person where age between 19 and 22;

查询结果为空,删除多条记录成功。
例3:删除person表中的所有记录。
执行删除操作前,使用SELECT的语句查看当前的数据。
select * from person;
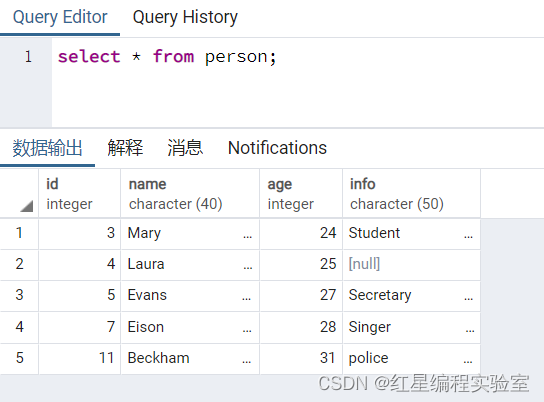
结果显示person表中还有五条记录,执行DELETE语句,删除这五条记录。
delete from person;
语句执行完毕后,查看执行结果。
select * from person;
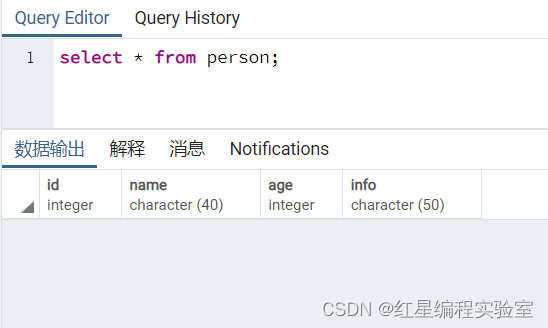
查询结果为空,删除表中所有记录成功,现在person表中已经没有任何数据记录。
如果想删除表中的所有记录,还可以使用TRUNCATE TABLE。TRUNCATE将直接删除原来的表并重新创建一个表。其语法结构为TRUNCATE TABLE 表名。直接删除表,而不是删除记录,因此执行速度比DELETE快。
综合案例——记录的插入,更新和删除
有关综合案例——记录的插入,更新和删除的相关内容请通过原教材《postgresql11从入门到精通》(清华大学出版社)第152页开始了解,常见问题及解答在原书158页,经典习题在原书159页,该部分作为自由了解范围请购买原著自行学习,感谢理解。
作者的话(Alvin):
本文根据原书《PostgreSql11 从入门到精通》(清华大学出版社)第7章总结整理,为提问与解答可以帮助更多人,本博客模拟GitHub的issue方案,所以私信已关,有问题请在评论区直接指正与提问,允许转发、复制或引用本文章,必须遵守开源法则注释来源与作者,感谢您的阅读。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)