文章目录
- 1、环境搭建
- 2、数据集
- 3、下载预训练模型
- 4、配置文件
- DecodeImage
- DetLabelEncode
- IaaAugment
- EastRandomCropData
- MakeBorderMap
- 5、开启训练
- 6、纯记录,我在我服务器做的事情
- 7、显示label
- 8、推导模型的导出与预测
- 9、转到onnx模型和mnn模型
-
- 10、在线可视化
- 11、推理的时候,从概率图到文字框的过程(后处理)
- 12、DBnet损失函数
- DiceLoss-->loss_binary_maps
- MaskL1Loss-->loss_threshold_maps
- BalanceLoss-->bce_loss -->loss_shrink_maps
- 损失函数配置
- 13、评估指标
1、环境搭建
官网环境准备参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/environment.md#1.3
paddle官网:https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html
linux cpu用于调试:
conda create -n paddle python=3.7 -y
conda activate paddle
pip install -r requirements.txt
python -m pip install paddlepaddle==2.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
如果是gpu,docker用起来:
nvidia-docker run -v $PWD:/paddle -v /ssd/xiedong/datasets/ICDAR2015/:/ICDAR2015 --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda11.2-cudnn8 /bin/bash
python -m pip install -i https://pypi.douban.com/simple --upgrade pip && pip config set global.index-url https://pypi.douban.com/simple
cd /paddle
pip install -r requirements.txt
2、数据集
官网的数据集参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/dataset/ocr_datasets.md
以ICDAR 2015数据集来说,可以直接下载PaddleOCR给的标注,也可以自行使用ppocr/utils/gen_label.py进行标签转换:
python gen_label.py --mode="det" --root_path="/ssd/xiedong/datasets/ICDAR2015/ch4_training_images/" \
--input_path="/ssd/xiedong/datasets/ICDAR2015/ch4_training_localization_transcription_gt" \
--output_label="/ssd/xiedong/datasets/ICDAR2015/train_icdar2015_label.txt"
3、下载预训练模型
官网参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/detection.md
下载预训练模型:
https://github.com/PaddlePaddle/PaddleClas/blob/release%2F2.0/README_cn.md#resnet%E5%8F%8A%E5%85%B6vd%E7%B3%BB%E5%88%97
我这里下载后放这里:
修改label文件中所描述的路径:
import os
lb_file = r"C:\Users\dong.xie\Desktop\test_icdar2015_label.txt"
lb_file_dst = lb_file
with open(lb_file, 'r') as f:
lines = f.readlines()
res_list = []
for line in lines:
pathname, label = line.split('\t')
basename = os.path.basename(pathname)
pathname_new = r"/ICDAR2015/ch4_test_images/" + basename
res_list.append(pathname_new + '\t' + label)
with open(lb_file_dst, 'w') as f:
f.write(''.join(res_list))
4、配置文件
配置文件修改为:
Global:
use_gpu: true
use_xpu: false
use_mlu: false
epoch_num: 1200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/db_mv3/
save_epoch_step: 1200
eval_batch_step: [ 0, 2000 ]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_small_x0_35_ssld_pretrained
checkpoints:
save_inference_dir:
use_visualdl: true
infer_img: doc/imgs_en/img_10.jpg
save_res_path: ./output/det_db/predicts_db.txt
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.35
model_name: small
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
Loss:
name: DBLoss
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
learning_rate: 0.001
regularizer:
name: 'L2'
factor: 0
PostProcess:
name: DBPostProcess
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DetMetric
main_indicator: hmean
Train:
dataset:
name: SimpleDataSet
data_dir: /ICDAR2015/ch4_training_images/
label_file_list:
- /ICDAR2015/train_icdar2015_label.txt
ratio_list: [ 1.0 ]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- DetLabelEncode:
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [ -10, 10 ] } }
- { 'type': Resize, 'args': { 'size': [ 0.5, 3 ] } }
- EastRandomCropData:
size: [ 640, 640 ]
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean: [ 0.485, 0.456, 0.406 ]
std: [ 0.229, 0.224, 0.225 ]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: [ 'image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask' ]
loader:
shuffle: True
drop_last: False
batch_size_per_card: 16
num_workers: 8
use_shared_memory: True
Eval:
dataset:
name: SimpleDataSet
data_dir: /ICDAR2015/ch4_test_images/
label_file_list:
- /ICDAR2015/test_icdar2015_label.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: False
- DetLabelEncode:
- DetResizeForTest:
image_shape: [ 736, 1280 ]
- NormalizeImage:
scale: 1./255.
mean: [ 0.485, 0.456, 0.406 ]
std: [ 0.229, 0.224, 0.225 ]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: [ 'image', 'shape', 'polys', 'ignore_tags' ]
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1
num_workers: 8
use_shared_memory: True
选择模型的配置是下面,在初始构建模型的代码中会拉起:
Architecture:
model_type: det
algorithm: DB
Transform:
Backbone:
name: MobileNetV3
scale: 0.35
model_name: small
Neck:
name: DBFPN
out_channels: 256
Head:
name: DBHead
k: 50
DecodeImage
从文件路径加载图片到内存:
- DecodeImage:
img_mode: BGR
channel_first: False
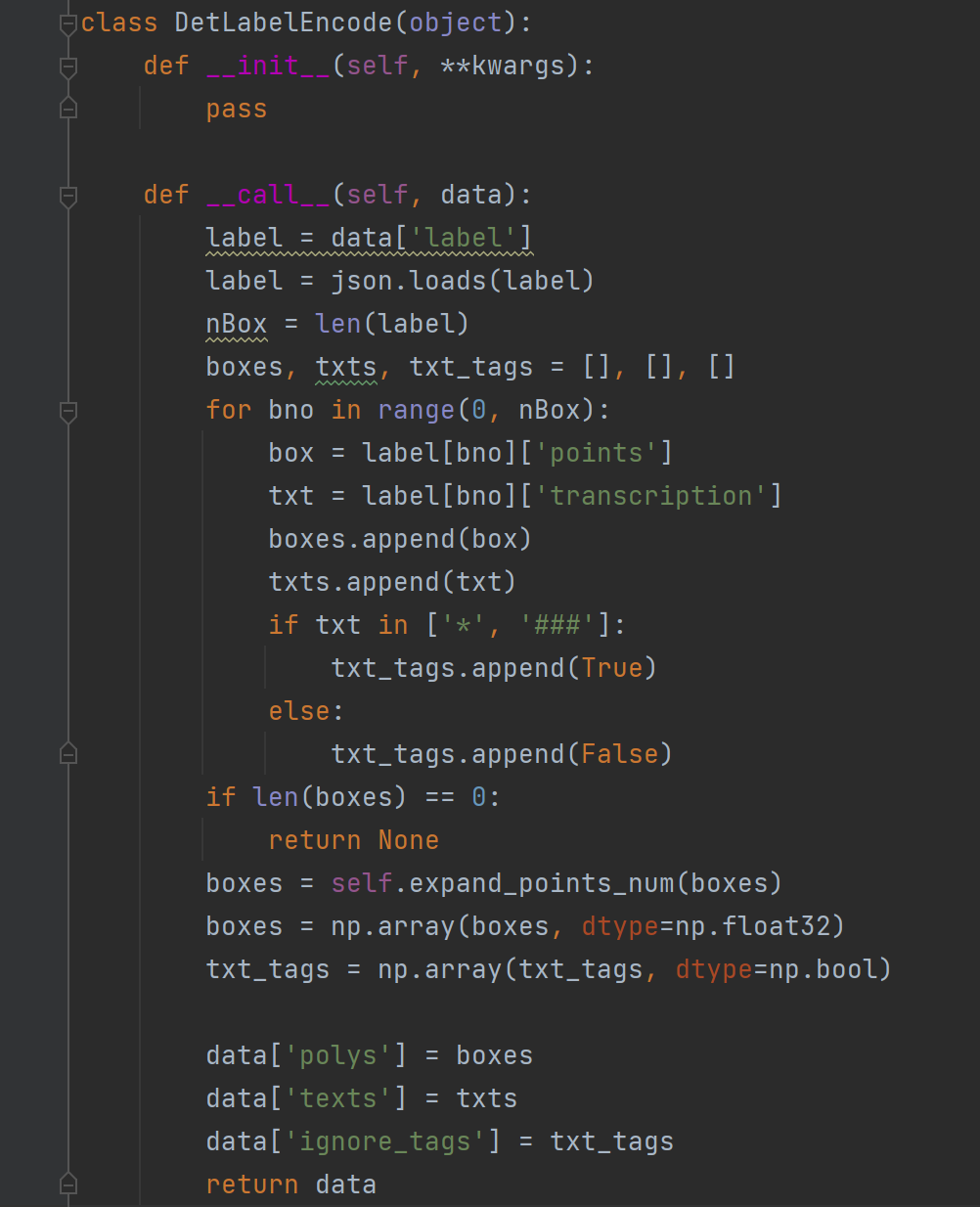
DetLabelEncode
处理label文本,可看出文字标记为"*“或者”###"的,tag都会是True,后续将忽略此标记。
- DetLabelEncode:
IaaAugment
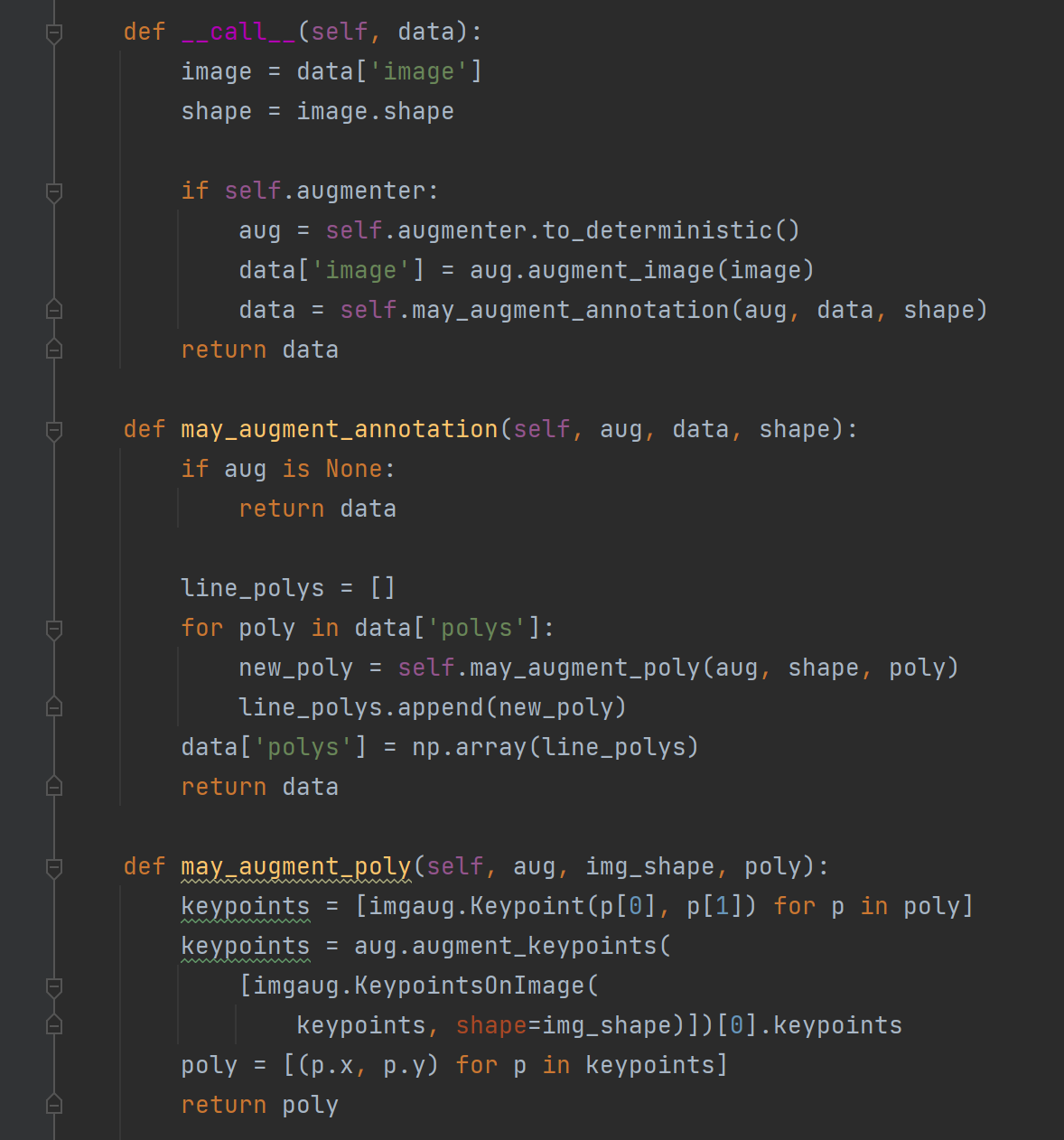
这段代码定义了一个名为 IaaAugment 的类,用于进行图像增强操作。该类的实例化方法 init 接受一个参数 augmenter_args 和其他可选参数 **kwargs。如果没有提供 augmenter_args,则默认使用三个图像增强器:水平翻转、仿射变换和尺寸调整,每个增强器都有不同的参数设置。
call 方法接受一个数据字典 data,其中包括一个 image 键,对应于输入的图像。方法首先获取输入图像的形状,然后将图像传递给 augmenter 对象进行增强操作。增强器对象首先被转换为确定性的,然后对输入图像进行增强,返回增强后的图像。此外,方法还调用 may_augment_annotation 方法对标注进行相同的增强操作,并将增强后的数据字典返回。
may_augment_annotation 方法接受 aug 增强器对象、 data 数据字典和 shape 输入图像的形状。该方法使用 may_augment_poly 方法对 polys 键中的多边形进行增强操作,并将增强后的多边形数组存储在 data[‘polys’] 中。
may_augment_poly 方法接受 aug 增强器对象、img_shape 输入图像的形状和 poly 多边形数组。该方法将多边形的每个点转换为 imgaug.Keypoint 对象,并将它们作为一个 imgaug.KeypointsOnImage 对象传递给增强器的 augment_keypoints 方法。该方法返回一个包含增强后的关键点的 imgaug.KeypointsOnImage 对象,然后将这些点的坐标转换回原始多边形的形式,最后返回增强后的多边形。
- IaaAugment:
augmenter_args:
- { 'type': Fliplr, 'args': { 'p': 0.5 } }
- { 'type': Affine, 'args': { 'rotate': [ -10, 10 ] } }
- { 'type': Resize, 'args': { 'size': [ 0.5, 3 ] } }
EastRandomCropData
这段代码定义了两个类 EastRandomCropData 和 RandomCropImgMask,它们都是用于数据增强(data augmentation)的。
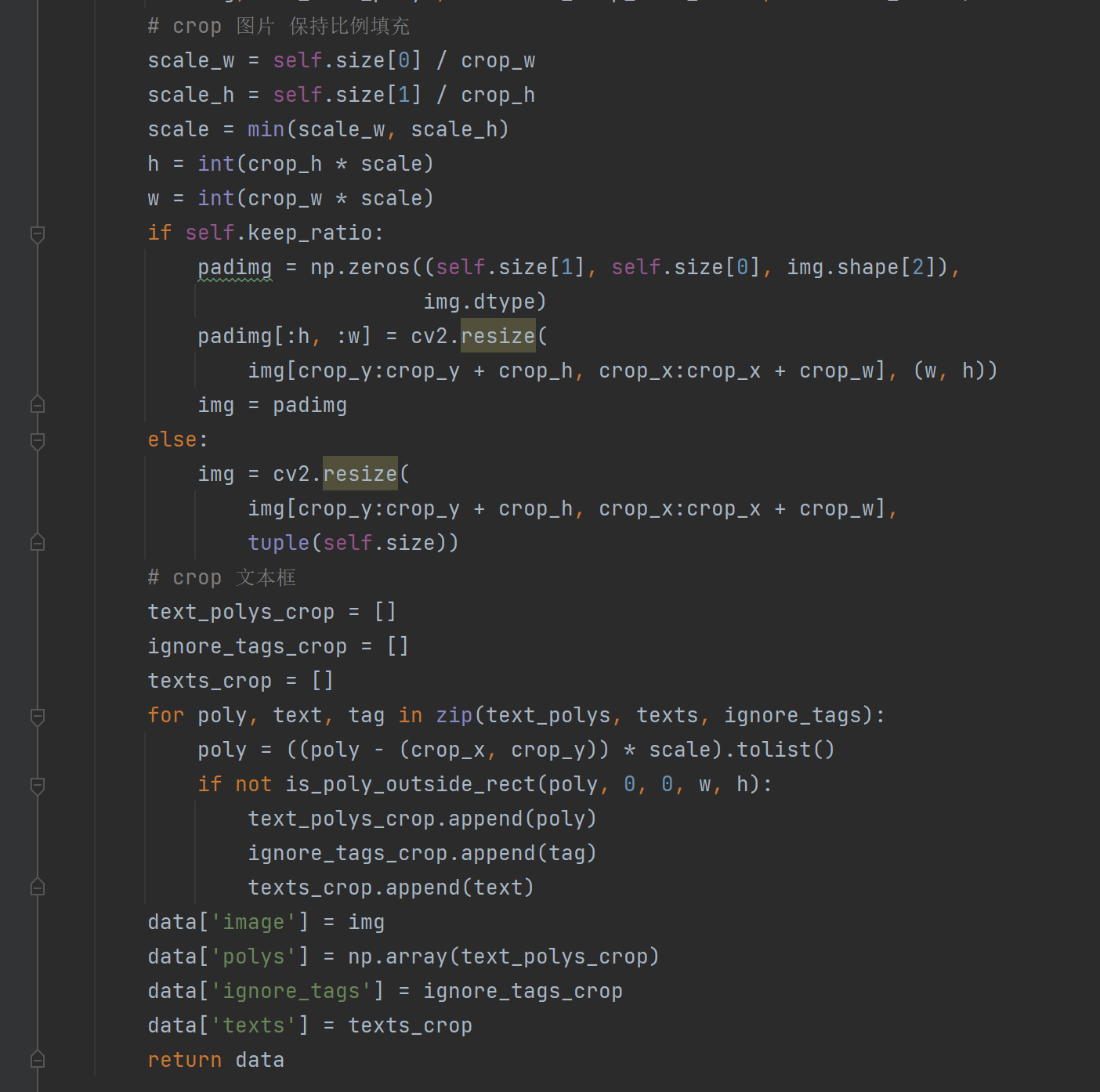
EastRandomCropData 类实现了一种基于 EAST(Efficient and Accurate Scene Text detection)文本检测算法的数据增强方法,主要作用是对原始图片进行随机裁剪,使得裁剪出的区域包含至少一个文本框,并保持裁剪后的图片与原始图片比例一致。具体实现过程如下:
首先,通过调用 crop_area 函数计算出一个合适的裁剪区域,该函数会根据输入的 all_care_polys 参数(即所有不被标记为忽略的文本框)和裁剪区域的最小边长比例 min_crop_side_ratio,随机生成多个裁剪区域并返回其中包含至少一个文本框的那个区域。如果经过 max_tries 次尝试后还是没有找到合适的裁剪区域,则直接返回原始图片。
接着,根据裁剪区域的大小和目标大小(即 self.size 参数),计算出缩放比例 scale,并将裁剪后的图片缩放到目标大小。如果 keep_ratio 参数为 True,则先将目标大小的全零矩阵 padimg 创建出来,将缩放后的图片居中填充到 padimg 中,最后返回 padimg;否则直接将缩放后的图片调整为目标大小并返回。
最后,对原始文本框进行相应的裁剪和缩放操作,以保证其与裁剪后的图片大小相匹配,并返回增强后的数据。
RandomCropImgMask 类实现了一种随机裁剪的数据增强方法,主要作用是对输入的图像和掩码进行随机裁剪。具体实现过程如下:
首先,根据输入图像的大小和目标大小,生成一个随机裁剪区域,并将该区域应用于输入图像和掩码上。具体来说,如果掩码中存在非零像素(即存在文本区域),则保证裁剪区域至少包含一个文本区域;否则随机生成一个裁剪区域。
接着,对输入数据中包含在 self.crop_keys 列表中的数据(如图像、掩码等)进行裁剪操作,并将裁剪后的数据更新到原始数据中。
最后,返回增强后的数据。
- EastRandomCropData:
size: [ 640, 640 ]
max_tries: 50
keep_ratio: true
MakeBorderMap
配置:
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
代码块:
从代码可以看出,输入是文本框polys,输出是canvas和mask,利用下面的代码可以将两者保存为灰度图:
# 保存成图
import cv2
# 将 canvas 和 mask 缩放到 [0, 255] 区间内并转换为无符号 8 位整数类型
canvas_uint8 = cv2.normalize(canvas, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
mask_uint8 = cv2.normalize(mask, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
# 保存为灰度图像
cv2.imwrite('canvas.png', canvas_uint8)
cv2.imwrite('mask.png', mask_uint8)
canvas就是threshold_map:

mask就是threshold_mask:

5、开启训练
开启训练的指令:
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
det_mv3_db.yml的含义:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/config.md
6、纯记录,我在我服务器做的事情
在19服务器将docker镜像拉下来:
docker pull kevinchina/deeplearning:paddle2.1.3paddleocr
使用rsync同步文件:
rsync -avz xiedong@10.20.31.16:/ssd/xiedong/workplace/PaddleOCR-release-2.6/ ./PaddleOCR-release-2.6/
启动容器:
nvidia-docker run -v $PWD:/paddle -v /ssd/xiedong/datasets/ICDAR2015/:/ICDAR2015 --shm-size=64G --network=host -it kevinchina/deeplearning:paddle2.1.3paddleocr /bin/bash
nvidia-docker run -v $PWD:/paddle -v /ssd/xiedong/datasets/para_det_paddle:/para_det_paddle --shm-size=64G --network=host -it kevinchina/deeplearning:paddle2.1.3paddleocr /bin/bash
单机多卡训练:
python3 -m paddle.distributed.launch --gpus '0,1,2' tools/train.py -c configs/det/det_mv3_db_para_det_paddle.yml
python3 -m paddle.distributed.launch --gpus '0,1,2' tools/train.py -c configs/det/det_mv3_db_para_det_paddle_1_0_20230506.yml
断点resume训练:
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python3 -m paddle.distributed.launch --gpus '0,1,2' tools/train.py -c configs/det/det_mv3_db_para_det_paddle.yml -o Global.checkpoints=./output/db_mv3_para_det_paddle/latest.pdparams
7、显示label
将图片中的文字画框后显示出来:
import os
import PIL.Image as Image
import PIL.ImageDraw as ImageDraw
import cv2
src = r"E:\q\ICDAR2015"
labelfilename = r"E:\q\ICDAR2015\train_icdar2015_label.txt"
with open(labelfilename, "r", encoding="utf-8") as f:
lines = f.read().splitlines()
for line in lines:
line = line.split("\t")
imgpath = os.path.join(src, line[0])
img = Image.open(imgpath)
img = img.convert("RGB")
draw = ImageDraw.Draw(img)
for d in eval(line[1]):
points = d["points"]
draw.line(points[0] + points[1] + points[2] + points[3] + points[0], fill=(255, 0, 0), width=3)
img.show()
8、推导模型的导出与预测
检测模型转inference 模型方式:
python3 tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model="./output/db_mv3_3/best_accuracy" Global.save_inference_dir="./output/db_mv3_3_inference/"

段落框:
python3 tools/export_model.py -c configs/det/det_mv3_db_para_det_paddle.yml -o Global.pretrained_model="./output/db_mv3_para_det_paddle/best_accuracy" Global.save_inference_dir="./output/db_mv3_para_det_paddle_inference/"
用于预测:
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True
用于预测,段落框:
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/db_mv3_para_det_paddle_inference/" --image_dir="./doc/imgs/" --use_gpu=True
9、转到onnx模型和mnn模型
到onnx
安装:pip install paddle2onnx onnx onnx-simplifier onnxruntime-gpu
导出模型:paddle2onnx --model_dir ./output/db_mv3_para_det_paddle_inference/ --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./output/db_mv3_para_det_paddle_inference/model.onnx --opset_version 10 --enable_dev_version True --enable_onnx_checker True
参数选项
| 参数 | 参数说明 |
|---|
| –model_dir | 配置包含Paddle模型的目录路径 |
| –model_filename | [可选] 配置位于--model_dir下存储网络结构的文件名 |
| –params_filename | [可选] 配置位于--model_dir下存储模型参数的文件名称 |
| –save_file | 指定转换后的模型保存目录路径 |
| –opset_version | [可选] 配置转换为ONNX的OpSet版本,目前支持7~15等多个版本,默认为9 |
| –enable_dev_version | [可选] 是否使用新版本Paddle2ONNX(推荐使用),默认为False |
| –enable_onnx_checker | [可选] 配置是否检查导出为ONNX模型的正确性, 建议打开此开关。若指定为True, 默认为False |
| –enable_auto_update_opset | [可选] 是否开启opset version自动升级,当低版本opset无法转换时,自动选择更高版本的opset 默认为True |
| –input_shape_dict | [可选] 配置输入的shape, 默认为空; 此参数即将移除,如需要固定Paddle模型输入Shape,请使用此工具处理 |
| –version | [可选] 查看paddle2onnx版本 |
- 使用onnxruntime验证转换模型, 请注意安装最新版本(最低要求1.10.0):
如你有ONNX模型优化的需求,推荐使用onnx-simplifier,也可使用如下命令对模型进行优化:
python -m paddle2onnx.optimize --input_model model.onnx --output_model new_model.onnx
如需要修改导出的模型输入形状,如改为静态shape:
python -m paddle2onnx.optimize --input_model model.onnx \
--output_model new_model.onnx \
--input_shape_dict "{'x':[1,3,224,224]}"
到mnn
sudo /ssd/xiedong/miniconda3/envs/py37c/bin/mnnconvert -f ONNX --modelFile model.onnx --MNNModel model.mnn --bizCode MNN
10、在线可视化
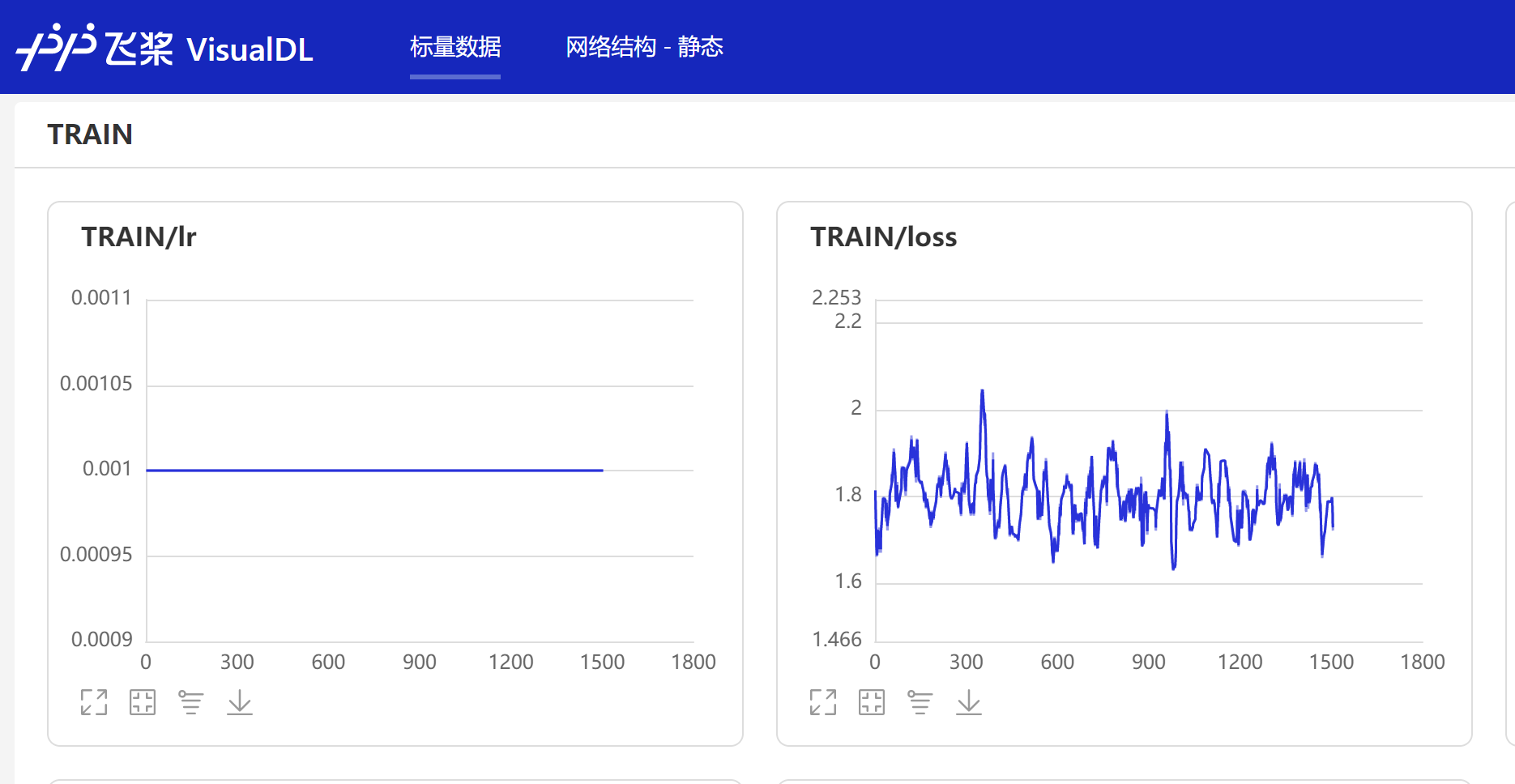
百度提供的visualdl 对log可视化:
visualdl --logdir="vdl"
下面这图是我resume训练了,看起来loss还在波动。
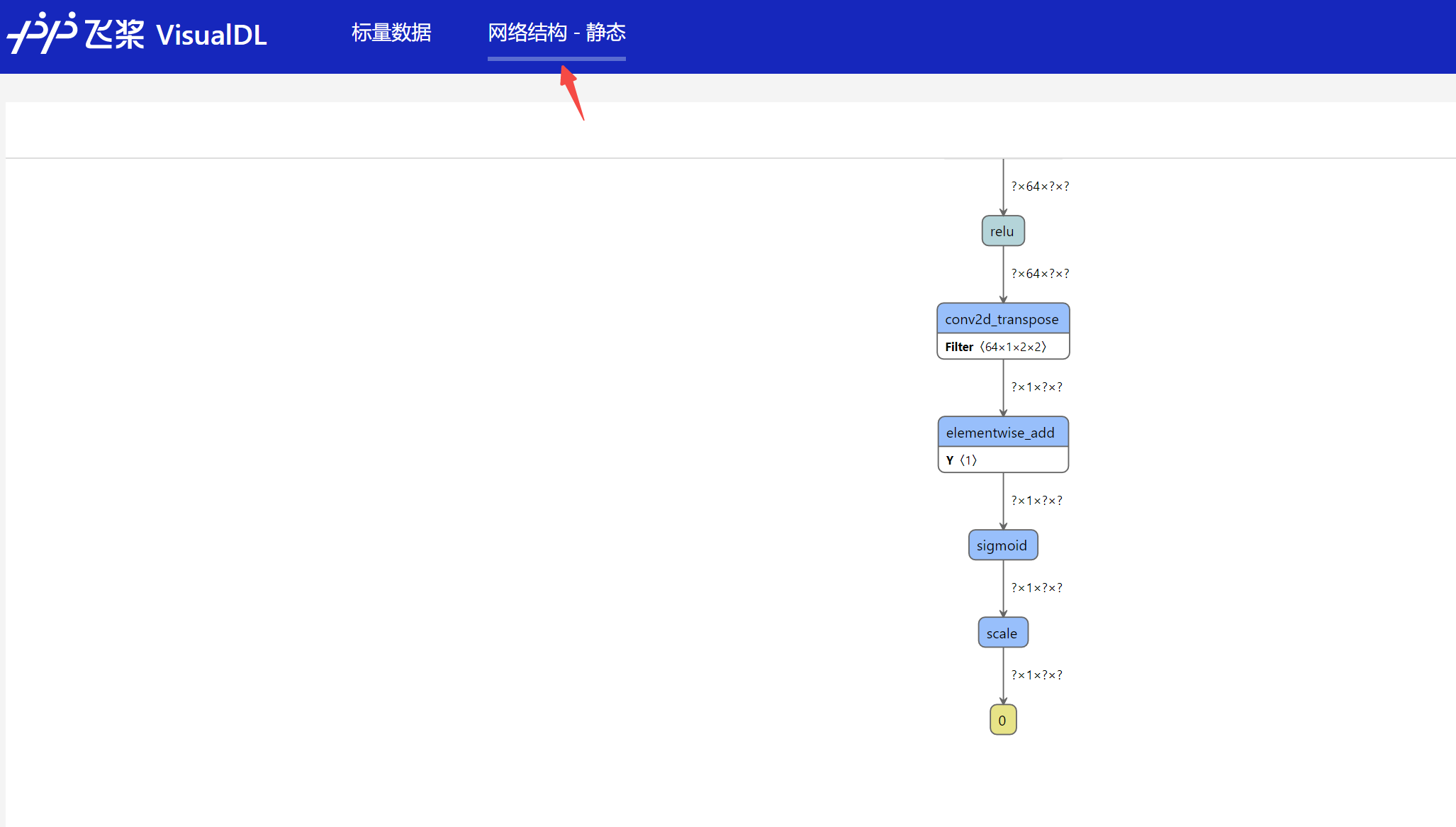
也可以将inference.pdmodel模型放入后查看模型结构:
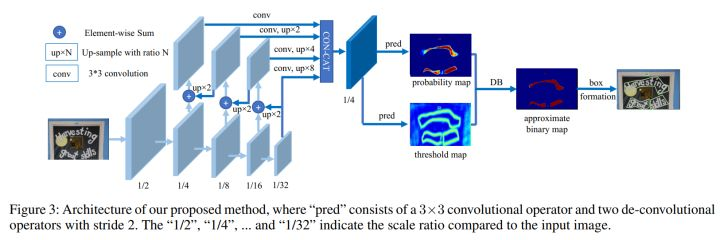
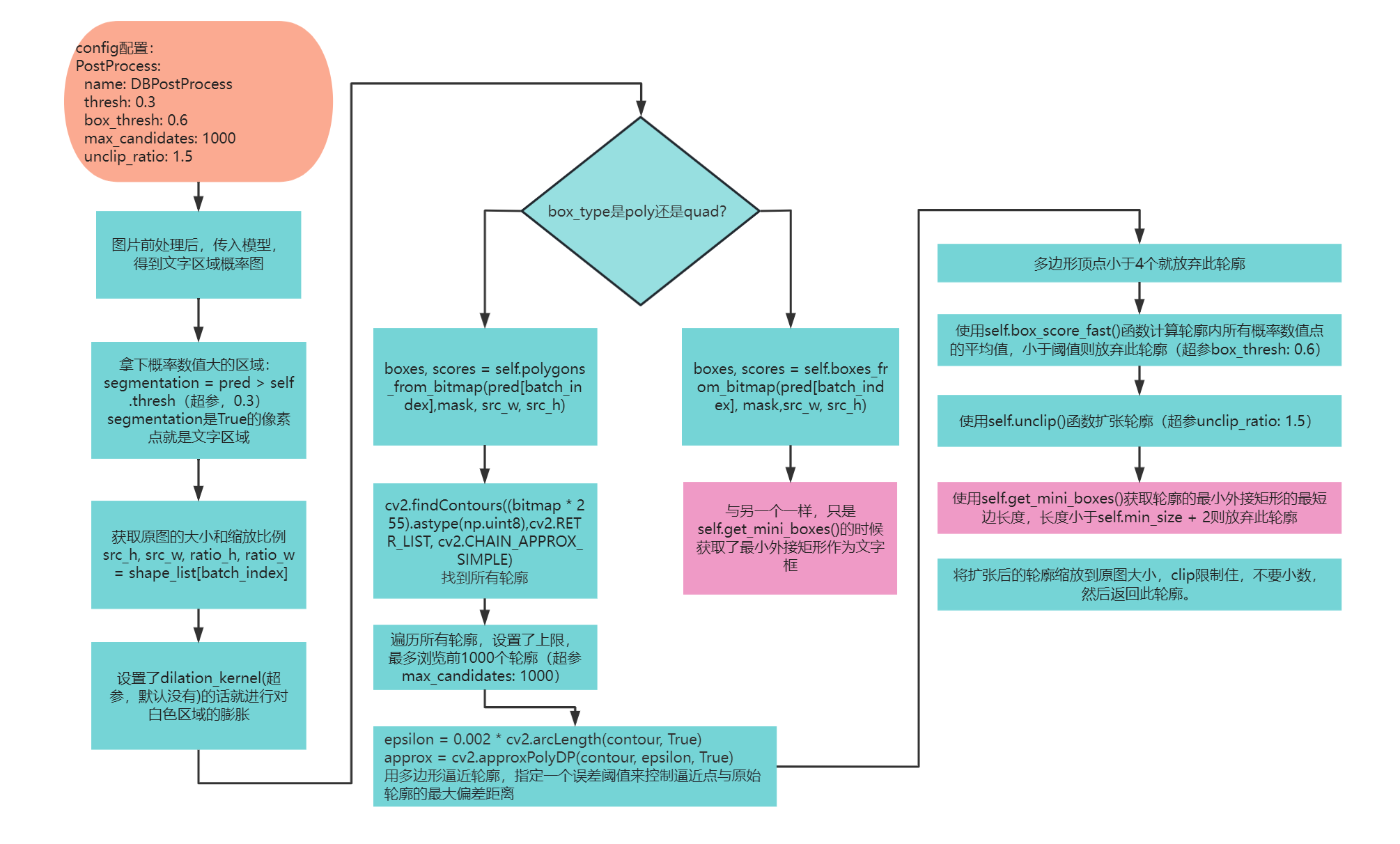
11、推理的时候,从概率图到文字框的过程(后处理)
可以执行下面的指令,添加断点:
python3 tools/export_model.py -c configs/det/det_mv3_db_para_det_paddle.yml -o Global.pretrained_model="./output/db_mv3_para_det_paddle/best_accuracy" Global.save_inference_dir="./output/db_mv3_para_det_paddle_inference/"
此内容在 class DBPostProcess(object) 中, 使用config的一些配置,完成了从概率图到文本框的转换。
12、DBnet损失函数
源码:
from .det_basic_loss import BalanceLoss, MaskL1Loss, DiceLoss
class DBLoss(nn.Layer):
"""
Differentiable Binarization (DB) Loss Function
args:
param (dict): the super paramter for DB Loss
"""
def __init__(self,
balance_loss=True,
main_loss_type='DiceLoss',
alpha=5,
beta=10,
ohem_ratio=3,
eps=1e-6,
**kwargs):
super(DBLoss, self).__init__()
self.alpha = alpha
self.beta = beta
self.dice_loss = DiceLoss(eps=eps)
self.l1_loss = MaskL1Loss(eps=eps)
self.bce_loss = BalanceLoss(
balance_loss=balance_loss,
main_loss_type=main_loss_type,
negative_ratio=ohem_ratio)
def forward(self, predicts, labels):
predict_maps = predicts['maps']
label_threshold_map, label_threshold_mask, label_shrink_map, label_shrink_mask = labels[
1:]
shrink_maps = predict_maps[:, 0, :, :]
threshold_maps = predict_maps[:, 1, :, :]
binary_maps = predict_maps[:, 2, :, :]
loss_shrink_maps = self.bce_loss(shrink_maps, label_shrink_map,
label_shrink_mask)
loss_threshold_maps = self.l1_loss(threshold_maps, label_threshold_map,
label_threshold_mask)
loss_binary_maps = self.dice_loss(binary_maps, label_shrink_map,
label_shrink_mask)
loss_shrink_maps = self.alpha * loss_shrink_maps
loss_threshold_maps = self.beta * loss_threshold_maps
loss_all = loss_shrink_maps + loss_threshold_maps \
+ loss_binary_maps
losses = {'loss': loss_all, \
"loss_shrink_maps": loss_shrink_maps, \
"loss_threshold_maps": loss_threshold_maps, \
"loss_binary_maps": loss_binary_maps}
return losses
一步一步拆解开看,
DiceLoss–>loss_binary_maps
源码:
class DiceLoss(nn.Layer):
def __init__(self, eps=1e-6):
super(DiceLoss, self).__init__()
self.eps = eps
def forward(self, pred, gt, mask, weights=None):
"""
DiceLoss function.
"""
assert pred.shape == gt.shape
assert pred.shape == mask.shape
if weights is not None:
assert weights.shape == mask.shape
mask = weights * mask
intersection = paddle.sum(pred * gt * mask)
union = paddle.sum(pred * mask) + paddle.sum(gt * mask) + self.eps
loss = 1 - 2.0 * intersection / union
assert loss <= 1
return loss
公式计算:

MaskL1Loss–>loss_threshold_maps
源码:
class MaskL1Loss(nn.Layer):
def __init__(self, eps=1e-6):
super(MaskL1Loss, self).__init__()
self.eps = eps
def forward(self, pred, gt, mask):
"""
Mask L1 Loss
"""
loss = (paddle.abs(pred - gt) * mask).sum() / (mask.sum() + self.eps)
loss = paddle.mean(loss)
return loss
公式表达:

BalanceLoss–>bce_loss -->loss_shrink_maps
源码:
class BalanceLoss(nn.Layer):
def __init__(self,
balance_loss=True,
main_loss_type='DiceLoss',
negative_ratio=3,
return_origin=False,
eps=1e-6,
**kwargs):
"""
The BalanceLoss for Differentiable Binarization text detection
args:
balance_loss (bool): whether balance loss or not, default is True
main_loss_type (str): can only be one of ['CrossEntropy','DiceLoss',
'Euclidean','BCELoss', 'MaskL1Loss'], default is 'DiceLoss'.
negative_ratio (int|float): float, default is 3.
return_origin (bool): whether return unbalanced loss or not, default is False.
eps (float): default is 1e-6.
"""
super(BalanceLoss, self).__init__()
self.balance_loss = balance_loss
self.main_loss_type = main_loss_type
self.negative_ratio = negative_ratio
self.return_origin = return_origin
self.eps = eps
if self.main_loss_type == "CrossEntropy":
self.loss = nn.CrossEntropyLoss()
elif self.main_loss_type == "Euclidean":
self.loss = nn.MSELoss()
elif self.main_loss_type == "DiceLoss":
self.loss = DiceLoss(self.eps)
elif self.main_loss_type == "BCELoss":
self.loss = BCELoss(reduction='none')
elif self.main_loss_type == "MaskL1Loss":
self.loss = MaskL1Loss(self.eps)
else:
loss_type = [
'CrossEntropy', 'DiceLoss', 'Euclidean', 'BCELoss', 'MaskL1Loss'
]
raise Exception(
"main_loss_type in BalanceLoss() can only be one of {}".format(
loss_type))
def forward(self, pred, gt, mask=None):
"""
The BalanceLoss for Differentiable Binarization text detection
args:
pred (variable): predicted feature maps.
gt (variable): ground truth feature maps.
mask (variable): masked maps.
return: (variable) balanced loss
"""
positive = gt * mask
negative = (1 - gt) * mask
positive_count = int(positive.sum())
negative_count = int(
min(negative.sum(), positive_count * self.negative_ratio))
loss = self.loss(pred, gt, mask=mask)
if not self.balance_loss:
return loss
positive_loss = positive * loss
negative_loss = negative * loss
negative_loss = paddle.reshape(negative_loss, shape=[-1])
if negative_count > 0:
sort_loss = negative_loss.sort(descending=True)
negative_loss = sort_loss[:negative_count]
balance_loss = (positive_loss.sum() + negative_loss.sum()) / (
positive_count + negative_count + self.eps)
else:
balance_loss = positive_loss.sum() / (positive_count + self.eps)
if self.return_origin:
return balance_loss, loss
return balance_loss
公式表达:

损失函数配置
Loss:
name: DBLoss
balance_loss: true # 需要平衡损失
main_loss_type: DiceLoss
alpha: 5 # 给loss_shrink_maps加权
beta: 10 # 给loss_threshold_maps加权
ohem_ratio: 3
loss_shrink_maps:该损失函数是基于二分类交叉熵损失函数的,用于优化预测结果与实际文本区域边界收缩情况之间的差异,以便网络学习到更好的文本边界信息。
loss_threshold_maps:该损失函数是基于L1损失函数的,用于优化预测结果与实际文本区域阈值之间的差异,以便网络学习到更好的文本区域阈值信息。在二值化处理中,使用了一个预设的阈值,该损失函数可以使网络更好地学习到最优阈值。
loss_binary_maps:该损失函数是基于Dice Loss的,用于优化预测结果与实际二值化文本区域之间的重叠率,以便网络学习到更准确的二值化文本区域信息。
这三种损失函数都是为了优化网络预测结果与实际标签之间的差异,从而提高文本检测的性能。同时,不同的损失函数也针对不同的方面进行优化,使网络学习到更多的相关信息,并最终提高整个文本检测系统的性能。
13、评估指标

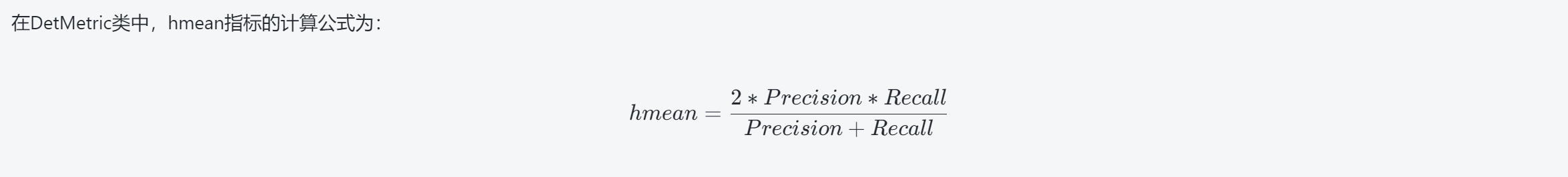
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)