<1>数据库介绍
什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,
每个数据库都有一个或多个不同的API用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理的大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
如:
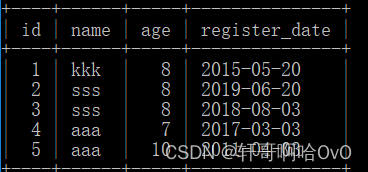
Mysql数据库
Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。由瑞典MySQL AB公司开发,目前属于Oracle公司。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- Mysql是开源的,所以你不需要支付额外的费用。
- Mysql支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL使用标准的SQL数据语言形式。
- Mysql可以允许于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
- Mysql对PHP有很好的支持,PHP是目前最流行的Web开发语言。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位系统支持最大的表文件为8TB。
- Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统。
<2>Mysql数据库操作
MySQL 用户设置
添加 MySQL 用户,你只需要在 mysql 数据库中的 user 表添加新用户即可。
以下为添加用户的的实例,用户名为shikai,密码为123,并授权用户可进行 SELECT, INSERT 和 UPDATE操作权限:
Windows端:
C:\Users\shikai>mysql -hlocalhost -uroot -p
Enter password: ***********
mysql> use mysql;
Database changed
mysql> insert into user
(host, user, password,
select_priv, insert_priv, update_priv)
VALUES ('localhost', 'shikai',
PASSWORD('123'), 'Y', 'Y', 'Y');
Query OK, 1 row affected (0.20 sec)
mysql> flush privileges; #将数据读取到内存中,从而立即生效。
Query OK, 1 row affected (0.01 sec)
mysql> select host, user, password from user where user = 'shikai';
+-----------+---------+------------------+
| host | user | password |
+-----------+---------+------------------+
| localhost | shikai | 6f8c114b58f2ce9e |
+-----------+---------+------------------+
1 row in set (0.00 sec)
另外一种添加用户的方法为通过SQL的 GRANT 命令,你下命令会给指定数据库TUTORIALS添加用户 zara ,密码为 zara123 。
root@host# mysql -u root -p password;
Enter password:*******
mysql> use mysql;
Database changed
mysql> GRANT SELECT,INSERT,UPDATE,DELETE,CREATE,DROP
-> ON TUTORIALS.*
-> TO 'zara'@'localhost'
-> IDENTIFIED BY 'zara123';
删除用户
drop user '用户名'@'IP地址';
修改用户
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';;
修改密码
set password for '用户名'@'IP地址' = Password('新密码')
忘记密码:
# 启动免授权服务端
mysqld --skip-grant-tables
# 客户端
mysql -u root -p
# 修改用户名密码
update mysql.user set authentication_string=password('123') where user='root';
flush privileges;
管理MySQL的命令
以下列出了使用Mysql数据库过程中常用的命令:
•USE 数据库名 :选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
•SHOW DATABASES: 列出 MySQL 数据库管理系统的数据库列表。
•SHOW TABLES: #显示指定数据库的所有表,使用该命令前需要使用 use命令来选择要操作的数据库。
•SHOW COLUMNS FROM 数据表: #显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息。
•create database testdb charset "utf8"; #创建一个叫testdb的数据库,且让其支持中文
•drop database testdb; #删除数据库
•SHOW INDEX FROM 数据表:显示数据表的详细索引信息,包括PRIMARY KEY(主键)。
<3>数据库增删改查
1:查看数据库
SHOW DATABASES;
结果:
2:创建数据库
# utf-8格式
CREATE DATABASE 数据库名称 DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
3:使用数据库
use 数据库名;
<4>数据表操作
1:查看表
show tables;
2:查看表结构
desc student;
3:创建表
create table table_name(
id INT NOT NULL AUTO_INCREMENT,
name CHAR(32) NOT NULL,
age INT NOT NULL,
register_date DATE,
PRIMARY KEY ( id )
);
# AUTO_INCREMENT 自增
#PRIMARY KEY ( id ) 设置id为主键
#自增 +主键 (表中只能有一个自增列)
id int not null auto_increment primary key,
主键和外键:
主键:一种特殊的唯一索引,不允许有空值,如果主键使用单个列,则它的值必须唯一,如果是多列,则其组合必须唯一。
外键:一个特殊的索引,关联指定另一个表,只能是指定内容
mysql> create table class(
-> id int not null primary key,
-> name char(16));
Query OK, 0 rows affected (0.02 sec)
CREATE TABLE `student2` (
`id` int(11) NOT NULL,
`name` char(16) NOT NULL,
`class_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `fk_class_key` (`class_id`),
CONSTRAINT `fk_class_key` FOREIGN KEY (`class_id`) REFERENCES `class` (`id`)
)
4:删除表
drop table 表名
5:清空表
delete from 表名
truncate table 表名
6:修改表
添加列:alter table 表名 add 列名 类型
删除列:alter table 表名 drop column 列名
修改列:
alter table 表名 modify column 列名 类型; -- 类型
alter table 表名 change 原列名 新列名 类型; -- 列名,类型
添加主键:
alter table 表名 add primary key(列名);
删除主键:
alter table 表名 drop primary key;
alter table 表名 modify 列名 int, drop primary key;
添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段);
删除外键:alter table 表名 drop foreign key 外键名称
修改默认值:ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000;
删除默认值:ALTER TABLE testalter_tbl ALTER i DROP DEFAULT;
<5>表内容操作
1:增
#插入数据
insert into 表 (列名,列名...) values (值,值...);
#添加字段
alter table student add id int(11) not null; #添加id字段
2:删
delete from 表 #删除表
delete from 表 where id=1 and name='shikai'
3:改
#改表内容
update 表名 set name = 'shikai' where id>1;
#修改字段类型和名称
ALTER TABLE table_name MODIFY age CHAR(32); #把age字符串长度改变
#CHANGE 子句修改字段类型和名称,在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。
ALTER TABLE table_name CHANGE name age BIGINT NOT NULL DEFAULT 100; #把name改成age,类型修改为BIGINT且值不为空,默认值为100
4:查询
1:查询表所有内容
#select * from 表
2:where 查询包含条件
#select * from 表 where id > 1
3:limit限制查条数,offset从哪个索引位开始查询
#select * from 表名 limit 3 offset 2;
4:like 语句#查询想‘kkk’ 这样的名字
#select *from student where name like "%kkk";
5:排序 order by
select * from 表 order by 列 asc - 根据 “列” 从小到大排列
select * from 表 order by 列 desc - 根据 “列” 从大到小排列
select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序
6:GROUP BY 语句 分组统计 (统计name)
SELECT name, COUNT(*) FROM table_name GROUP BY name;
6.1:coalesce 语法:改掉name名称,WITH ROLLUP统计出各项总数
select coalesce(name,"总数"),sum(age) from student group by name with rollup;
<6>Mysql 连接(left join, right join, inner join ,full join)
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
创建A B 两个表:
A B
- -
1 3
2 4
3 5
4 6
Inner join
#查询A B 的交集
select * from a INNER JOIN b on a.a = b.b;
Left join
select * from a LEFT JOIN b on a.a = b.b;

Right join
select * from a RIGHT JOIN b on a.a = b.b;

mysql 并不直接支持full join
select * from a left join b on a.a = b.b UNION select * from a right join b on a.a = b.b;
<7> 事务
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
• 在MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务
• 事务处理可以用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要么全部不执行
• 事务用来管理insert,update,delete语句
一般来说,事务是必须满足4个条件(ACID): Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durability(可靠性)
1、事务的原子性:一组事务,要么成功;要么撤回。
2、稳定性 : 有非法数据(外键约束之类),事务撤回。
3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit选项 决定什么时候吧事务保存到日志里。
在命令行操作:
mysql> begin; #开始一个事务
#事务1
mysql> insert into a (a) values(555);
mysql>rollback; 回滚 , 这样数据是不会写入的
mysql>commit 确认无误上传 对当前事务不做修改后上传
<八> 索引
索引其实就是两个表的共有部分数据,创建索引可以大大提高mysql的检索速度,缺点就是要存多份重复数据,占用系统内存,MySQL更新表的速度回降低。
创建索引:
CREATE INDEX indexName ON mytable(username(length));
在已创建好的表中修改索引:
ALTER mytable ADD INDEX [indexName] ON (username(length))
或者在新创建表时创建索引:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引:
DROP INDEX [indexName] ON mytable;
<9>pymysql模块
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。
MySQLdb:只支持py 2.x版本
pymsql :支持py3.x版本
1:连接MySQL并执行
#!_*_coding:utf-8_*_
#__author__:"shikai"
import pymysql
#创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', , db='shikai',charset = 'utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
#执行操作(写入cmd命令行代码即可)
effect_row = cursor.execute("select * from student") #打印表
data=[
("A",11,"2018-08-19"),
("B",11,"2018-07-29"),
("C",11,"2018-06-08"),
]
#effect_row = cursor.executemany("insert into student(name,age,register_date) values (%s,%s,%s)",data)
# 提交,不然无法保存新建或者修改的数据
#conn.commit()
# 获取第一行数据
#print(cursor.fetchone())
# 获取前n行数据
#print("***************")
# print(cursor.fetchmany(2))
# print("***************")
#获取所有数据 many 和all都是接着上面的获取
print(cursor.fetchall())
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
<10>ORM,sqlalchemy模块介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。相当于把sql命令转化为编程语言封装好的。
1:ORM框架是SQLAlchemy
基本步骤:连接数据库+Base(生成orm基类)+创建表结构+创建数据库回话+创建数据+添加数据到Session+提交到MySQL
2:增
#!_*_coding:utf-8_*_
#__author__:"shikai"
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
from sqlalchemy.orm import sessionmaker
#要用mysql+pymysql操作,后面依次用户名+密码+主机地址+数据库名 echo=True打印转化为sql语句的过程
engine=create_engine("mysql+pymysql://root:15682550131@localhost/shikai",encoding="utf-8",echo=True) #
Base=declarative_base() #生成orm基类
class User(Base):
__tablename__="user" #表名
id=Column(Integer,primary_key=True)
name=Column(String(32))
password=Column(String(64))
def __repr__(self): #打印获数据的内容
return "<User({} name={},password={})>".format(self.id,self.name,self.password)
class Student(Base):
__tablename__="student2" #表名
id=Column(Integer,primary_key=True)
name=Column(String(32),nullable=False)
date=Column(String(32),nullable=False)
def __repr__(self):
return "<User({} name={},date={})>".format(self.id,self.name,self.date)
#创建表结构
Base.metadata.create_all(engine)
############################################################
#创建数据工作
Session_class=sessionmaker(bind=engine) #创建和数据库回话Session_class,这里返回给session的是个类class,
Session=Session_class() #生成session实例
#生成创建数据对象
user_obj1=User(name="Helena")
user_obj2=User(name="shikai")
stu_obj=Student(name="BBB",date="2028-03-08")
stu_obj2=Student(name="hhh",date="2008-04-20")
#把创建的数据对象添加到session里,待会同意创建数据
Session.add_all([user_obj1,user_obj2,stu_obj,stu_obj2])
#现此才统一提交,创建数据
Session.commit()
3:查询:
filter_by与filter区别: filter里面用==号,data= Session.query(User).filter_by(name="AAA").first()
#统计
data=Session.query(User).filter(User.name=="Helena").count()
#带条件查询
data=Session.query(User).filter(User.id>0).filter(User.id<2).all()
#统计分组
#data=Session.query(User.name,func.count(User.name)).group_by(User.name).all()
#打印结果:[('Helena', 2), ('shikai', 1)]
#实现两个表间的查询
#data=ret = Session.query(User, Student).filter(User.id == Student.id).all()
print(data)
结果:
<__main__.User object at 0x105b4ba90>
需要在定义表的类下面添加:(打印的data就是return返回的数据)
def __repr__(self):
return "<User({} name={},date={})>".format(self.id,self.name,self.date)
4:修改
data= Session.query(User).filter_by(name="AAA").first()
data.name = "BBB"
Session.commit()
5:获取所有数据
print(Session.query(User.name,User.id).all() )
6:回滚
#rollback回滚
# user_obj1=User(name="AAA",password="AAA123")
# Session.add(user_obj1)
# print(Session.query(User).filter_by(name="AAA").first())
# Session.rollback()
# print("**************************************")
# print(Session.query(User).filter_by(name="AAA").first())
#现此才统一提交,创建数据
Session.commit()
7:外键关联
让student3表的id和study_record3表的id关联,然后通过student3表可以反查study_record3的数据
#!_*_coding:utf-8_*_
#__author__:"shikai"
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey
from sqlalchemy.orm import sessionmaker,relationship
from sqlalchemy import func
#要用mysql+pymysql操作,后面依次用户名+密码+主机地址+数据库名 echo=True打印转化为sql语句的过程
engine=create_engine("mysql+pymysql://root:15682550131@localhost/shikai",encoding="utf-8") #
Base=declarative_base() #生成orm基类
class Student(Base):
__tablename__="student3"
id=Column(Integer,primary_key=True)
name=Column(String(32),nullable=False)
date=Column(String(32),nullable=False)
def __repr__(self): #打印数据时候显示正常
return "<User({} name={},date={})>".format(self.id,self.name,self.date) #
class StudyRecord(Base):
__tablename__="study_record3" #表名
id=Column(Integer,primary_key=True)
day=Column(Integer,nullable=False)
status=Column(String(64),nullable=False)
stu_id=Column(Integer,ForeignKey("student3.id")) #外键关联
student=relationship("Student",backref="my_study_record") #student表里通过外键关联可以反查study_record表的数据
def __repr__(self):
return "<User:({} day={},status={})>".format(self.id,self.day,self.status)
Base.metadata.create_all(engine) #创建表结构
#创建数据工作
Session_class=sessionmaker(bind=engine) #创建和数据库回话Session_class,这里返回给session的是个类class,
Session=Session_class() #生成session实例
#添加表数据
# s1=Student(name="AAA",date="2018-03-03")
# s2=Student(name="CCC",date="2018-04-04")
# r1=StudyRecord(day=1,status="No")
# r2=StudyRecord(day=1,status="Yes")
# Session.add_all([s1,s2,r1,r2])
data=Session.query(Student).filter(Student.name=="AAA").first() #实现两个表间的查询
print(data.my_study_record) #通过外键关联之后可以反查一个表的数据
#现此才统一提交,创建数据
Session.commit()
8:多外键关联
让customer的billing_address_id 和shipping_address_id两个外键关联address.id
为了简洁在程序二执行:
程序一:
#!_*_coding:utf-8_*_
#__author__:"shikai"
from sqlalchemy import Integer, ForeignKey, String, Column,create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String(32))
billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id"))
billing_address = relationship("Address", foreign_keys=[billing_address_id])
shipping_address = relationship("Address", foreign_keys=[shipping_address_id])
def __repr__(self): #打印数据时候显示正常
#return "<User({} name={},date={})>".format(self.name,self.street,self.city)
return self.id
class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
street = Column(String(32))
city = Column(String(32))
state = Column(String(32))
engine=create_engine("mysql+pymysql://root:15682550131@localhost/shikai",encoding="utf-8")
#Base.metadata.create_all(engine) #创建表结构
程序二:
#!_*_coding:utf-8_*_
#__author__:"shikai"
from MySQL import orm_many_api
from sqlalchemy.orm import sessionmaker
Session_class=sessionmaker(bind=orm_many_api.engine) #创建和数据库回话Session_class,这里返回给session的是个类class,
Session=Session_class() #生成session实例
# addr1=orm_many_api.Address(street ="圣灯街",city ="成都",state ="四川")
# addr2=orm_many_api.Address(street ="铁建",city ="泸州",state ="四川")
# addr3=orm_many_api.Address(street ="华林路",city ="德阳",state ="四川")
# Session.add_all([addr1,addr2,addr3])
#
# c1=orm_many_api.Customer(name ="shikai",billing_address =addr1,shipping_address =addr2)
# c2=orm_many_api.Customer(name ="jack",billing_address =addr3,shipping_address =addr3)
# Session.add_all([c1,c2])
data=Session.query(orm_many_api.Customer).filter(orm_many_api.Customer.name=="shikai").first()
print(data.name,data.billing_address,data.shipping_address)
Session.commit()
9:多对多表关联
如:一本书与由多个作者关联,多本书可以关联一个作者
#!_*_coding:utf-8_*_
#__author__:"shikai"
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String,ForeignKey,DATE,Table
from sqlalchemy.orm import sessionmaker,relationship
from sqlalchemy import func
#要用mysql+pymysql操作,后面依次用户名+密码+主机地址+数据库名 echo=True打印转化为sql语句的过程
engine=create_engine("mysql+pymysql://root:15682550131@localhost/shikai?charset=utf8",encoding="utf-8") #
Base=declarative_base() #生成orm基类
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return self.name
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return self.name
Base.metadata.create_all(engine) #创建表结构
#创建数据工作
Session_class=sessionmaker(bind=engine) #创建和数据库回话Session_class,这里返回给session的是个类class,
Session=Session_class() #生成session实例
# b1=Book(name="追风筝的人",pub_date="2015-08-03")
# b2=Book(name="夏至未至",pub_date="2012-04-03")
# b3=Book(name="孤独患者",pub_date="2016-05-03")
#
# a1=Author(name="shikai")
# a2=Author(name="AAA")
# a3=Author(name="BBB")
#
# b1.authors=[a1,a2]
# b2.authors=[a2,a3]
# b3.authors=[a3,a3]
#
# Session.add_all([b1,b2,b3,a1,a2,a3])
book_obj=Session.query(Book).filter_by(name="追风筝的人").first()
#print(book_obj.name,book_obj.pub_date)
author_obj=Session.query(Author).filter_by(name="shikai").first()
print(author_obj.name,author_obj.books)
#现此才统一提交,创建数据
Session.commit()
books:

authors:
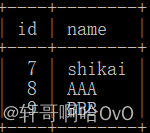
book_m2m_author

程序执行如下:
book_obj=Session.query(Book).filter_by(name="追风筝的人").first()
print(book_obj.name,book_obj.pub_date)
author_obj=Session.query(Author).filter_by(name="shikai").first()
print(author_obj.name,author_obj.books)
#结果
追风筝的人 2015-08-03
shikai [追风筝的人]
多对多删除:直接删除books和authors表内容
book_obj.authors.remove(author_obj) #从一本书里删除一个作者
s.delete(author_obj) #直接删除作者
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)