1 简介
本文根据2019年《A Self-Attentive model for Knowledge Tracing》翻译终结。
SAKT:self attentive knowledge tracing.
知识追踪(Knowledge tracing)的任务是模拟每个学生在一系列学习活动中对知识概念的掌握情况。最近几年,基于RNN(Recurrent Neural Networks)方法,如 Deep Knowledge Tracing (DKT) 和Dynamic Key-Value Memory Network (DKVMN) 取得了很好的结果。但是这些模型有个问题是,不能很好的处理稀疏数据,毕竟真实世界中,有些学生只进行很少部分的知识概念交互,或者说我们只有这些学生很少的学习数据。
我们的模型SAKT可以很好的处理数据稀疏的问题。
2 介绍

DKT模型的解释性差。
DKVMN具有更好的解释性:key:知识概念矩阵,value:知识状态表达矩阵。
但这两个模型都不能很好的泛化处理稀疏数据。
SAKT首先识别学生过去所有交互的相关性,然后预测学生的表现。比如学习方程前,学生要先掌握加减乘除。
3 方法

E:整个练习的数量
Embedding layer


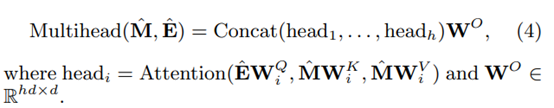
Feed Forward layer
加入FF层,引入非线性变换。

预测层:
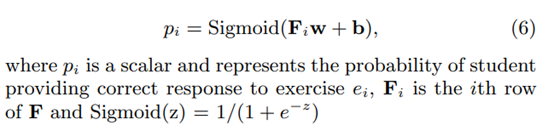
损失函数:
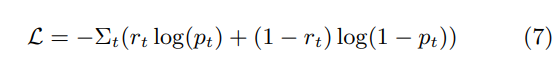
4 实验结果
可以看到SAKT模型效果很好。对于ASSISTChall 数据,DKT也很好,主要是因为该数据不稀疏。

5 Ablation Study
No Positional Encoding (PE),No Residual Connection (RC),No block: When no self-attention block is used。

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)