文章目录
- DBSCAN聚类算法
- 基本思想
- 基本概念
- 工作流程
- 参数选择
- DBSCAN的优劣势
- 代码分析
- ==Matplotlib Pyplot==
- ==make_blobs==
- ==StandardScaler==
- ==axes类使用==
- ==plt.cm.Spectral颜色分配==
- ==python numpy 中linspace函数==
- ==enumerate()函数==
- ==plt.scatter()绘制散点图==
- 整体代码
DBSCAN聚类算法
基本思想
基本概念
-
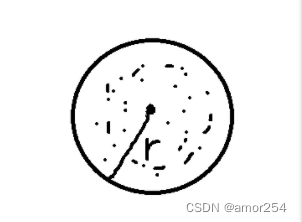
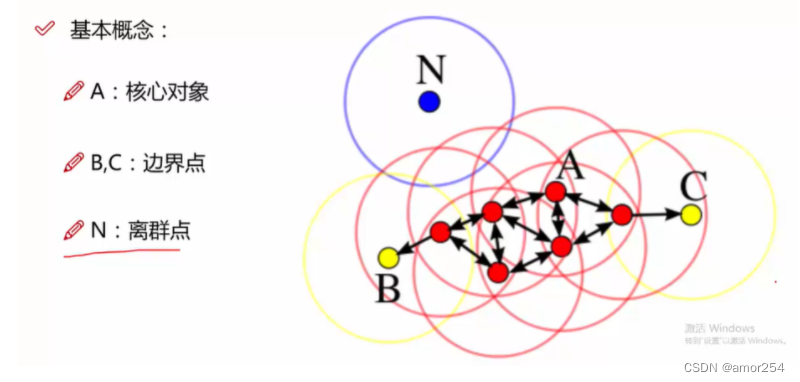
核心对象: 若某个点的密度达到算法设定的阈值(人为设置的)则其为核心点(即r领域内点的数量不小于minpts) (minpts就是自己设置的阈值 r就是这个点的领域范围)
-
∈-领域的距离阈值:设定的半径r
-
直接密度可达:若某点p在点q的r领域内,且q是核心电脑则p-q直接密度可达
-
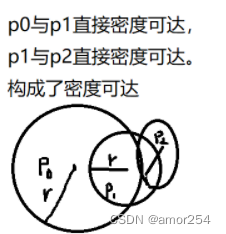
密度可达:若有一个点的序列q0,q1,…qk,对任意qi-qi-1是直接密度可达的,则称从q0到qk密度可达,这实际上是直接密度可达的“传播”
-
密度相连:若从某核心点p出发,点q点k都是密度可达的,则称点q和点k是密度相连。
-
边界点;属于某一个类的非核心点,不能发展下线了
-
噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达(所有簇都不可以圈住的点)
工作流程

参数选择
-
半径

-
MinPts

DBSCAN的优劣势
- 优势
- 不需要指定簇的个数
- 可以发现任意形状的簇
- 擅长找到离群点
- 两个参数就够了
- 劣势
- 高纬数据有些困难(可以做降维)
- 参数难以选择(参数对结果的影响非常大)
- Sklearn中效率很慢(数据消减策略)
- 机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。
- sklearn的特点
- 简单高效的数据挖掘和数据分析工具
- 让每个人都能够在复杂环境中重复使用
- 建立Numpy,Scipy,MatPlotLib之上
代码分析
Matplotlib Pyplot
-
Pyplot是Matplotlib的子库,提供了和matlab类似的绘图API
-
Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。
-
plot([x], y, [fmt], *, data=None, **kwargs)
plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs)
-
**x, y:**点或线的节点,x 为 x 轴数据,y 为 y 轴数据,数据可以列表或数组。
-
**fmt:**可选,定义基本格式(如颜色、标记和线条样式)。
-
****kwargs:**可选,用在二维平面图上,设置指定属性,如标签,线的宽度等。

- 如果我们不指定 x 轴上的点,则 x 会根据 y 的值来设置为 0, 1, 2, 3…N-1。
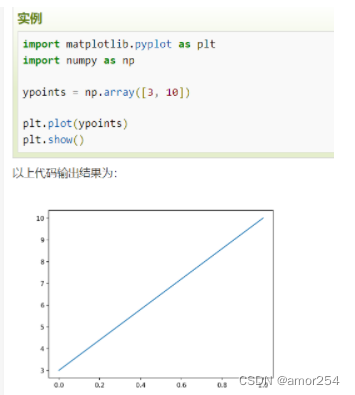
-
import matplotlib.pyplot as plt
import numpy as np
x=np.arange(0,4*np.pi,0.1)
y=np.sin(x)
z=np.cos(x)
plt.plot(x,y,x,z)
plt.show()
make_blobs
- make_blobs函数是为聚类产生数据集,产生一个数据集和相应的标签
StandardScaler
- 作用
- 去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本
- 对特征数据进行归一化
- np.mean求均值,np.std求标准差
- 标准差标准化
-
![image-20221125133150962]()
- 归一化后加快了梯度下降求最优解的速度;
- 归一化有可能提高精度;
- fit_transform()
axes类使用
- axes类(轴域类),该类对象被称为axes对象(即轴域对象),它指定了一个有数值范围限制的绘图区域。在一个给定的画布(figure)中可以包含多个axes对象,但是同一个axes对象只能在一个画布中使用
plt.cm.Spectral颜色分配

python numpy 中linspace函数
- 与Numpy arange函数类似,生成结构与Numpy 数组类似的均匀分布的数值序列。
- 通过定义均匀间隔来创建数值序列,其次需要指定间隔起始点,终止端,以及指定分隔值总数(包括起始点和终止点),最终函数返回间隔类均匀分布的数值序列
enumerate()函数
plt.scatter()绘制散点图
-
作用:用于散点图的绘制
-
基本参数

整体代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
UNCLASSIFIED=0
NOISE=-1
def getdatadisstance(datas):
line,column=np.shape(datas)
dists=np.zeros([line,line])
for i in range(0,line):
for j in range(0, line):
vi=datas[i,:]
vj=datas[j,:]
dists[i,j]=np.sqrt(np.dot((vi-vj),(vi-vj)))
return dists
def find_near_pionts(point_id,eps,dists):
index=(dists[point_id]<=eps)
return np.where(True==index)[0].tolist()
def expand_cluster(dists,labs,cluster_id,seeds,eps,min_points):
i=0
while i<len(seeds):
Pn=seeds[i]
if labs[Pn]==NOISE:
labs[Pn]=cluster_id
elif labs[Pn]==UNCLASSIFIED:
labs[Pn]=cluster_id
new_seeds=find_near_pionts(Pn,eps,dists)
if len(new_seeds)>=min_points:
seeds=seeds+new_seeds
else:
continue
i=i+1
def DBSCAN(datas,eps,min_points):
dists=getdatadisstance(datas)
n_points=datas.shape[0]
labs=[UNCLASSIFIED]*n_points
cluster_id=0
for point_id in range(0,n_points):
if not(labs[point_id]==UNCLASSIFIED):
continue
seeds = find_near_pionts(point_id, eps, dists)
if len(seeds)<min_points:
labs[point_id]=NOISE
else:
cluster_id=cluster_id+1
labs[point_id]=cluster_id
expand_cluster(dists,labs,cluster_id,seeds,eps,min_points)
return labs,cluster_id
def draw_cluster(datas,labs,n_cluster):
plt.cla()
colors=[plt.cm.Spectral(each) for each in np.linspace(0,1,n_cluster)]
for i,lab in enumerate(labs):
if lab==NOISE:
plt.scatter(datas[i,0],datas[i,1],s=16,color=(0,0,0))
else:
plt.scatter(datas[i,0],datas[i,1],s=16,color=colors[lab-1])
plt.show()
if __name__=="__main__":
file_name="jain"
with open(file_name+'.txt','r',encoding='utf-8') as f:
lines=f.read().splitlines()
lines=[line.split("\t")[:2] for line in lines]
datas=np.array(lines).astype(np.float32)
datas=StandardScaler().fit_transform(datas)
eps=0.2
min_points=5
labs,cluster_id=DBSCAN(datas,eps=eps,min_points=min_points)
draw_cluster(datas,labs,cluster_id)
- 可视化效果
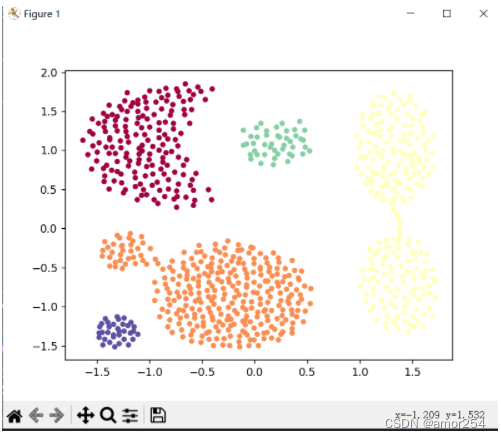
参考文章
https://blog.csdn.net/Joyce_Ff/article/details/91955640
参考视频
https://www.bilibili.com/video/BV17Y4y1v7XH/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1vL41147Ah/?spm_id_from=333.337.search-card.all.click&vd_source=1e0628d472510a4049e6a6e9a12fb1da
数据集链接:https://pan.baidu.com/s/1FeckeC2er84CpMzb55TdDA
提取码:2580
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)
