算法描述:
1> 从N个数据中选出K个元素作为质心,即数据将被分成K簇
2> 依次计算剩下的每一个元素到K个元素的相异度,一般是计算距离,将这些元素分别划分到相异度最低的簇中去
3> 根据聚类结果分别重新计算k个簇各自的中心,计算方法是取簇中各维度的算术平均值。
4> 将D的全部元素按照新的中心重新聚类。
5> 重复第四步,直到聚类结果不再发生改变。
6> 将结果输出
算法的工作过程:
首先从n个数据对象任意选择K个作为初始聚类中心,对于剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配到与其最相似的聚类中,然后再计算新的聚类的聚类质心,不断重复这个过程,直至标准测度函数收敛为止,一般采用均方差作为标准测度函数。
K-means算法的特点:
各簇之间的差异性较大,簇内的相似性较大
用数学表达式来说就是:
在聚类中的训练样本是{x(1),……x(m)},每个x(i)∈R(n)没有y
K-means算法就是将样本聚类冲K个簇
① 随机选取K个聚类质心点,分别为μ1,μ2,……,μk∈ Rn
②重复下面过程直到收敛
{
对于每一个样本计算它应该属于的簇(类)
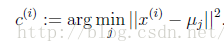
对于每一个簇(类)重新计算质心
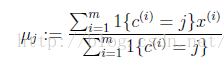
}
K是实现由用户给定的聚类数,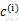 表示样例i与k个类中质心点距离最近的那个类,
表示样例i与k个类中质心点距离最近的那个类,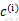 的值是1到K中的一个,质心
的值是1到K中的一个,质心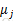 代表对属于同一个类的样本中心点的猜测。
代表对属于同一个类的样本中心点的猜测。
K-means 算法可以说是一个不断迭代的问题,目的是为了求得每个样本点到质心的最小距离。公式描述如下:
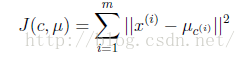
J函数表示每个样本点到其质心的距离平方和。K-means算法是要将其调整到最小值,可以看出这个J函数最终是收敛的,因为不管是调整质心或是调整每个样例所属的类别,都可以让J逐渐变小,当J减到最小的时候,μ和c也就同时收敛。
这样可以得到K-means算法的时间复杂度和空间复杂度:
时间复杂度:O(tKmn),其中t为迭代次数,K为簇的数目,m为记录数目,n为维数
空间复杂度:O((m+K)*n),m为记录数目,K为簇的数目,n为维数
k-means算法的不足之处:
① K值是事先给定的,但是这个K的值不太好确定,事先不清楚到底分多少个类比较合适。
② 聚类质心不好选择,初始的聚类质心的值的选择对聚类结果具有较大的影响。由于K-means算法的聚类准则函数是常用的误差平
方和准则函数,是一个非凸函数,存在多个局部极小值,只有一个是全局最小的。加上K-means聚类算法随机选取的初始中心往往
会落入到非凸函数曲面的位置,从而导致与全局最优解的范围存在一定偏离,因此通过迭代技术往往使聚类准则函数达到局部最优
而非全局最优的解。
③ 算法的开支比较大,因为要不断地对样本进行分类调整,并需要不断地计算新的簇的质心,因此当数据量很大的时候,算法的时间开发就很大了。
K-means算法在人体运动编辑与合成方面的应用:
应用流形学习技术结合K-means算法对长运动序列进行聚类分析以达到动作分割目的
matlab源代码:
KMeans.m
%N是数据一共分多少类
%data是输入的不带分类标号的数据
%u是每一类的中心
%re是返回的带分类标号的数据
function [u re]=KMeans(data,N)
[m n]=size(data); %m是数据个数,n是数据维数
ma=zeros(n); %每一维最大的数
mi=zeros(n); %每一维最小的数
u=zeros(N,n); %随机初始化,最终迭代到每一类的中心位置
for i=1:n
ma(i)=max(data(:,i)); %每一维最大的数
mi(i)=min(data(:,i)); %每一维最小的数
for j=1:N
u(j,i)=ma(i)+(mi(i)-ma(i))*rand(); %随机初始化,不过还是在每一维[min max]中初始化好些
end
end
while 1
pre_u=u; %上一次求得的中心位置
for i=1:N
tmp{i}=[]; % 公式一中的x(i)-uj,为公式一实现做准备
for j=1:m
tmp{i}=[tmp{i};data(j,:)-u(i,:)]; %tmp存数的是每个数据减去每个聚类中心的结果,这是第i个聚类中心
end
end
quan=zeros(m,N);
for i=1:m %公式一的实现
c=[];
for j=1:N
c=[c norm(tmp{j}(i,:))];%返回二范数
end
[junk index]=min(c); %找每行得到的j个最小值的最终最小值,并返回其是那个聚类
quan(i,index)=norm(tmp{index}(i,:));%得到当前行的对应最小二范数的值
end
for i=1:N %公式二的实现
for j=1:n
u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));%重新计算质心
end
end
if norm(pre_u-u)<0.1 %不断迭代直到位置不再变化
break;
end
end
re=[];
%迭代不再发生变化,那就说明达到最后一步了,直接再计算一次二范数,去最小的那个,得到每一行所属的标签
%可以看到与上面的步骤相同。
for i=1:m
tmp=[];
for j=1:N
tmp=[tmp norm(data(i,:)-u(j,:))];
end
[junk index]=min(tmp);
re=[re;data(i,:) index];
end
end
KMeansTset.m
clear all;
close all;
clc;
%第一类数据
mu1=[0 0 0]; %均值
S1=[0.3 0 0;0 0.35 0;0 0 0.3]; %协方差
data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
%%第二类数据
mu2=[1.25 1.25 1.25];
S2=[0.3 0 0;0 0.35 0;0 0 0.3];
data2=mvnrnd(mu2,S2,100);
%第三个类数据
mu3=[-1.25 1.25 -1.25];
S3=[0.3 0 0;0 0.35 0;0 0 0.3];
data3=mvnrnd(mu3,S3,100);
%显示数据
plot3(data1(:,1),data1(:,2),data1(:,3),'+');
hold on;
plot3(data2(:,1),data2(:,2),data2(:,3),'r+');
plot3(data3(:,1),data3(:,2),data3(:,3),'g+');
grid on;
%三类数据合成一个不带标号的数据类
data=[data1;data2;data3]; %这里的data是不带标号的
%k-means聚类
[u re]=KMeans(data,3); %最后产生带标号的数据,标号在所有数据的最后,意思就是数据再加一维度
[m n]=size(re);
%最后显示聚类后的数据
figure;
for i=1:m
if re(i,4)==1
plot3(re(i,1),re(i,2),re(i,3),'ro');
hold on;
elseif re(i,4)==2
plot3(re(i,1),re(i,2),re(i,3),'go');
hold on;
else
plot3(re(i,1),re(i,2),re(i,3),'bo');
hold on;
end
end
grid on;
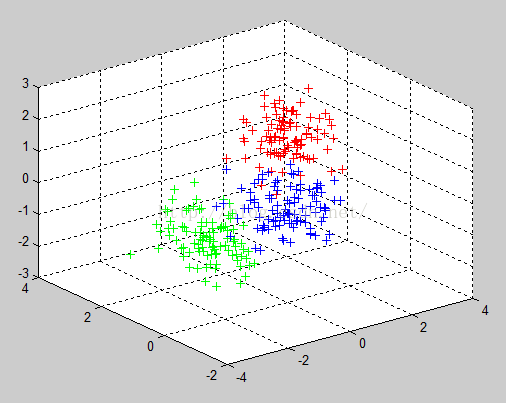
最终结果:
聚类之前的数据:
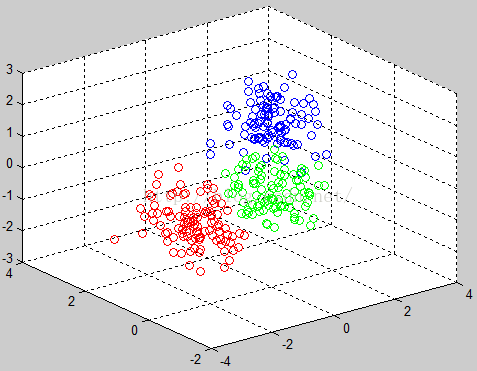
聚类之后的数据:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)