redis在2.8版本中支持分布式的部署,但不是真正意义上的集群,单独操作一台主机获取相应key,如果这个key没有落在该机器上,那么就获取不到。只有分片在该机器上才能获取到。redis从3.0版本开始支持自身集群方式,多个节点组成一个集群, 无论操作哪台机器,都可以设置值和获取值。
redis3.0以上版本集群方案采用了无中心节点设计的思想,多组节点构成集群,每组节点中需要有主节点,每个主节点可以有一个或者多个从节点。这样的设计,保证了一组节点中的主节点挂掉了,从节点可以被选举为主节点,继续保证集群可用。当主节点恢复之后,他会变为从节点。
redis3.0保证集群可用,并不是每个节点都保留了一份数据,而是采用了一种分槽(slots)的技术,将16384个槽,分配给每一组的节点。客户端连接redis,不是直接操作slot,而是通过redis操作槽,让槽来set,get。
我们如果构建三组节点,分配16384个槽,那么会如下图所示:

如果增加一个节点,那么相应的,若需要槽均匀分布,需要将三组中的槽分配给新的节点。按照16384/4=4096,每个节点可以分配4096个槽,新分配的节点的槽,不会是连续的,如下图所示。

可以看出每组节点从开始位置分别移动1366,1366,1365个节点到新的主节点上。
下面我们通过示例演示:
创建集群:
创建集群的命令:src/redis-trib.rb create --replicas 1 10.100.8.13:7001 10.100.8.13:7002 10.100.8.14:7003 10.100.8.14:7004 10.100.8.18:7005 10.100.8.18:7006,--replicas表示需要为主节点创建的从节点的个数,这里默认每个主节点配置一个从节点,创建成功的花,会出现如下图所示slot的分配,7001,7002节点分配slot:0-5641,7003,7004分配slot:5461-10922,7005,7006分配slot:10923-10683,正好如我们前面分析,三组节点将16384个槽均匀分配了。
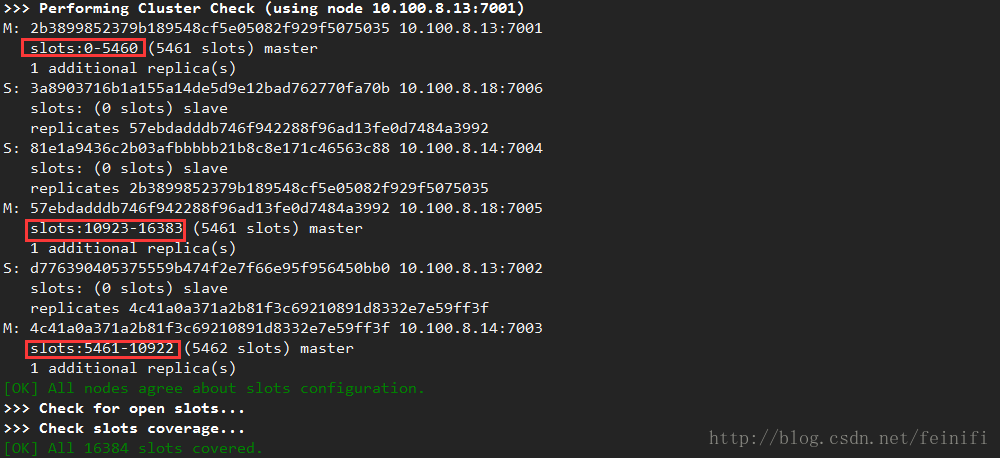
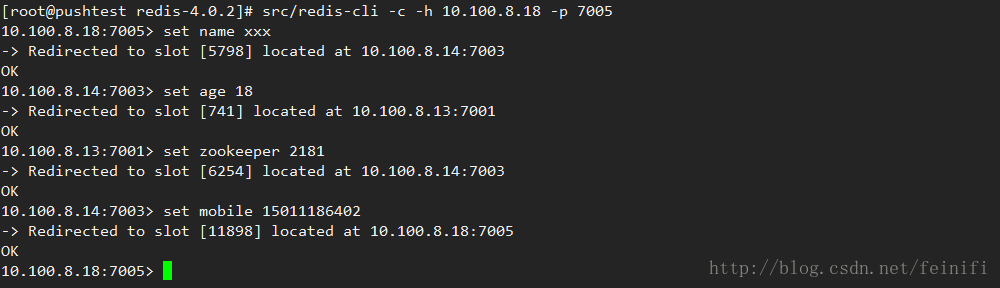
这样集群就创建成功了,我们可以通过设置一些值,看看值是如何在槽上分布的。
新增主节点
新增的主节点要求节点中无任何数据,如果有数据,会出现以下提示
[ERR] Node 10.100.8.38:7007 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
新增主节点的命令:src/redis-trib.rb add-node 10.100.8.38:7007 10.100.8.13:7001,其中第一个节点是要增加的节点,第二个节点是集群的节点,用来探测集群的,这个节点可以是已经构成集群中的任意节点,创建成功,会出现以下提示。
[root@pushtest redis-4.0.2]# src/redis-trib.rb add-node 10.100.8.38:7007 10.100.8.13:7001
>>> Adding node 10.100.8.38:7007 to cluster 10.100.8.13:7001
>>> Performing Cluster Check (using node 10.100.8.13:7001)
M: 2b3899852379b189548cf5e05082f929f5075035 10.100.8.13:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 3a8903716b1a155a14de5d9e12bad762770fa70b 10.100.8.18:7006
slots: (0 slots) slave
replicates 57ebdadddb746f942288f96ad13fe0d7484a3992
S: 81e1a9436c2b03afbbbbb21b8c8e171c46563c88 10.100.8.14:7004
slots: (0 slots) slave
replicates 2b3899852379b189548cf5e05082f929f5075035
M: 57ebdadddb746f942288f96ad13fe0d7484a3992 10.100.8.18:7005
slots:10923-16383 (5461 slots) master
1 additional replica(s)
S: d776390405375559b474f2e7f66e95f956450bb0 10.100.8.13:7002
slots: (0 slots) slave
replicates 4c41a0a371a2b81f3c69210891d8332e7e59ff3f
M: 4c41a0a371a2b81f3c69210891d8332e7e59ff3f 10.100.8.14:7003
slots:5461-10922 (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 10.100.8.38:7007 to make it join the cluster.
[OK] New node added correctly.
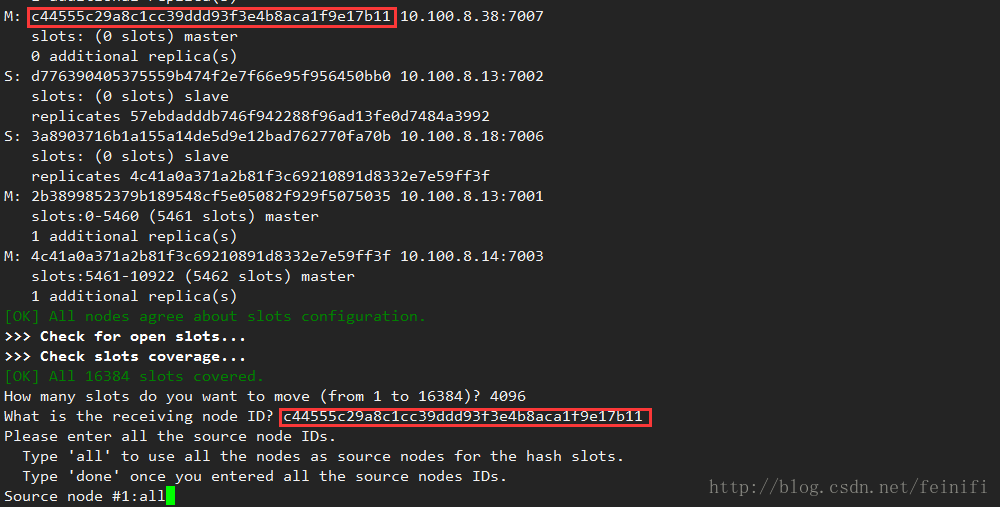
这里可以通过check来检查节点信息,可以看到10.100.8.38:7007加入了集群,但是还没有分槽信息,这样他是无法保存数据的。

这里需要重新分槽redis-trib.rb reshard 10.100.8.14:7005,这里指定的节点同样可以是已经构成集群的任意节点,他会将现有的槽根据后续指定的参数分配给新的节点。当输入分槽命令之后,会出现how many slots do you want to move(from 1 to 16384)?的信息,这里我们根据之前的设计,需要移动4096个槽给10.100.8.38:7007节点,然后提示需要分配给哪个节点,这里我们输入10.100.8.38:7007节点的ID,最后会提示源节点,这里我们输入all,表示从现有的三组主节点均匀移动节点到新的节点。
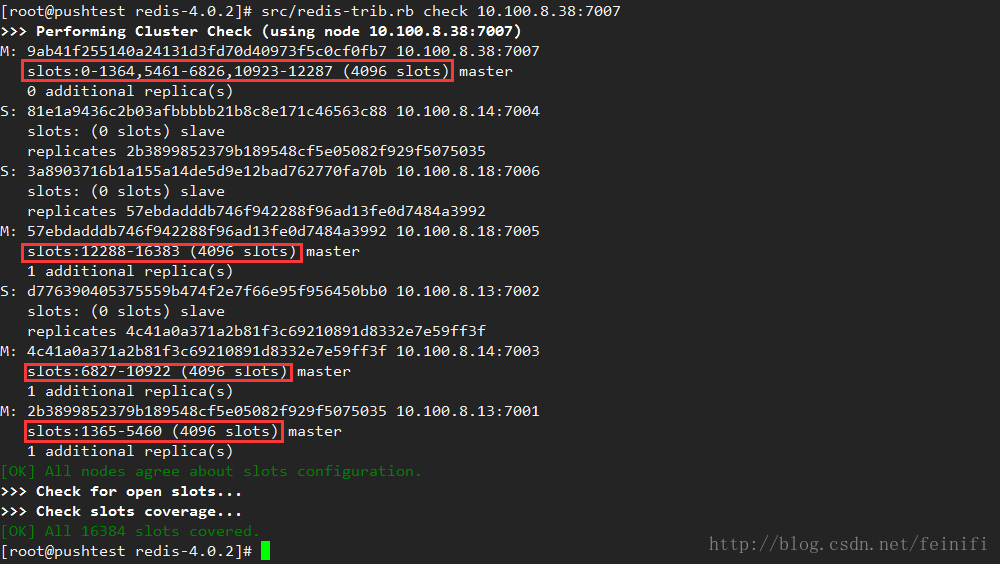
输入all之后会出现移动槽的滚屏操作,还会出现一次确认,输入yes之后,分槽成功。我们再次check节点10.100.8.38:7007,按照分槽的结果,他上面的槽是不连续的。每个主节点4096个槽。
新增从节点:
redis-trib.rb add-node --slave --master-id $nodeid 10.100.8.38:7008 10.100.8.13:7001
master-id:指定主节点ID,表示哪个主节点的从节点 //如果不指定则随机从主节点中从节点数少的节点中选择一个节点
第一个节点参数:要增加的从节点
第二个节点参数:集群节点,辨别集群
[root@pushtest redis-4.0.2]# src/redis-trib.rb add-node --slave 10.100.8.38:7008 10.100.8.13:7001
>>> Adding node 10.100.8.38:7008 to cluster 10.100.8.13:7001
>>> Performing Cluster Check (using node 10.100.8.13:7001)
...//省略部分信息
M: 9ab41f255140a24131d3fd70d40973f5c0cf0fb7 10.100.8.38:7007
slots:0-1364,5461-6826,10923-12287 (4096 slots) master
0 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
Automatically selected master 10.100.8.38:7007
>>> Send CLUSTER MEET to node 10.100.8.38:7008 to make it join the cluster.
Waiting for the cluster to join.
>>> Configure node as replica of 10.100.8.38:7007.
[OK] New node added correctly.
这时可以查看节点信息,四个主节点,四个从节点。
10.100.8.13:7001> cluster nodes
f7488758b689af6715402ed7258e475934c53cb3 10.100.8.38:7008@17008 slave 9ab41f255140a24131d3fd70d40973f5c0cf0fb7 0 1511851042000 7 connected
3a8903716b1a155a14de5d9e12bad762770fa70b 10.100.8.18:7006@17006 slave 57ebdadddb746f942288f96ad13fe0d7484a3992 0 1511851042519 6 connected
81e1a9436c2b03afbbbbb21b8c8e171c46563c88 10.100.8.14:7004@17004 slave 2b3899852379b189548cf5e05082f929f5075035 0 1511851042000 4 connected
57ebdadddb746f942288f96ad13fe0d7484a3992 10.100.8.18:7005@17005 master - 0 1511851043620 5 connected 12288-16383
2b3899852379b189548cf5e05082f929f5075035 10.100.8.13:7001@17001 myself,master - 0 1511851043000 1 connected 1365-5460
d776390405375559b474f2e7f66e95f956450bb0 10.100.8.13:7002@17002 slave 4c41a0a371a2b81f3c69210891d8332e7e59ff3f 0 1511851042418 3 connected
4c41a0a371a2b81f3c69210891d8332e7e59ff3f 10.100.8.14:7003@17003 master - 0 1511851041414 3 connected 6827-10922
9ab41f255140a24131d3fd70d40973f5c0cf0fb7 10.100.8.38:7007@17007 master - 0 1511851043421 7 connected 0-1364 5461-6826 10923-12287
在这里通过重新分槽,最早我们设置的数据,会分配到新的节点,还是可以查询出来,但是很明显槽的信息发生了变化,他们都分配到了10.100.8.38:7007节点。
集群高可用测试:我们杀掉节点10.100.8.38:7007进程,检查集群节点信息,10.100.8.38:7008成为主节点,节点数变为7个。

恢复10.100.8.38:7007之后,他变为从节点。

删除主节点:
删除主节点需要先移走主节点上的数据,否则会提示节点非空。
[root@pushtest redis-4.0.2]# src/redis-trib.rb del-node 10.100.8.13:7001 9ab41f255140a24131d3fd70d40973f5c0cf0fb7
>>> Removing node 9ab41f255140a24131d3fd70d40973f5c0cf0fb7 from cluster 10.100.8.13:7001
[ERR] Node 10.100.8.38:7007 is not empty! Reshard data away and try again.
这里的reshard和前面给10.100.8.38:7007节点分配槽时类似,就是在提示接收的节点和源节点时需要设置。这里是需要将4096个槽再分给任意节点,这里唯一不同的是,接收节点不能是多个,只能指定一个节点。这样槽的分配就不均匀了(理论上可以通过不断的reshard,让槽再次均匀分布并且连续),所以在实际中不要轻易的删除节点。
reshard之后再来删除,就可以删除了。
[root@pushtest redis-4.0.2]# src/redis-trib.rb del-node 10.100.8.13:7001 9ab41f255140a24131d3fd70d40973f5c0cf0fb7
>>> Removing node 9ab41f255140a24131d3fd70d40973f5c0cf0fb7 from cluster 10.100.8.13:7001
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
删除从节点:
直接移除,不用担心数据槽信息,这里就需要指定集群任意节点,用来探测集群,再一个参数就是要删除的节点ID。
[root@pushtest redis-4.0.2]# src/redis-trib.rb del-node 10.100.8.13:7001 f7488758b689af6715402ed7258e475934c53cb3
>>> Removing node f7488758b689af6715402ed7258e475934c53cb3 from cluster 10.100.8.13:7001
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)