安装
Mac直接安装tesseract的话无法附带安装training tools
如果已经安装了没有training tools的tesseract,请先卸载
brew uninstall tesseract
先安装一些依赖的包
# Packages which are always needed.
brew install automake autoconf libtool
brew install pkgconfig
brew install icu4c
brew install leptonica
# Packages required for training tools.
brew install pango
# Optional packages for extra features.
brew install libarchive
# Optional package for builds using g++.
brew install gcc
从下列链接下载tesseract-4.1.1.tar.gz并解压
https://github.com/tesseract-ocr/tesseract/releases
编译并安装
cd tesseract-4.1.1
./autogen.sh
mkdir build
cd build
# Optionally add CXX=g++-8 to the configure command if you really want to use a different compiler.
../configure PKG_CONFIG_PATH=/usr/local/opt/icu4c/lib/pkgconfig:/usr/local/opt/libarchive/lib/pkgconfig:/usr/local/opt/libffi/lib/pkgconfig
make -j
# Optionally install Tesseract.
sudo make install
# Optionally build and install training tools.
make training
sudo make training-install
下载完不会附带着一起下载数据集,通过下列链接自行下载需要的语言
https://github.com/tesseract-ocr/tessdata
训练
首先,收集数据样本(若干张需要训练的图片)
图片格式需要转换为tif
下载并打开jTessBoxEditor (注意,该软件需要java8环境,请自行配置):
https://pilotfiber.dl.sourceforge.net/project/vietocr/jTessBoxEditor/jTessBoxEditor-2.3.1.zip
在jTessBoxEditor中Tools->Merge TIFF将所有tif文件合并

将合并后的tif文件重命名为eng.num.exp0.tif
生成box文件,用来纠正识别错误
tesseract eng.num.exp0.tif eng.num.exp0 -l eng batch.nochop makebox
此时,应该有eng.num.exp0.tif和eng.num.exp0.box两个文件
使用jTessBoxEditor打开eng.num.exp0.tif
(Box Editor->Open->eng.num.exp0.tif)
纠正识别错误

新建一个文件,取名font_properties,并填入下列内容
font 0 0 0 0 0
执行如下命令训练数据
tesseract eng.num.exp0.tif eng.num.exp0 nobatch box.train
unicharset_extractor eng.num.exp0.box
shapeclustering -F font_properties -U unicharset eng.num.exp0.tr
mftraining -F font_properties -U unicharset -O unicharset eng.num.exp0.tr
cntraining eng.num.exp0.tr
mv inttemp num.inttemp
mv normproto num.normproto
mv pffmtable num.pffmtable
mv shapetable num.shapetable
mv unicharset num.unicharset
combine_tessdata num.
执行后,会有如下文件
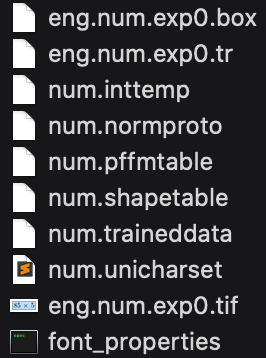
将num.traineddata移到相应路径便可使用
我的路径是/usr/local/share/tessdata/
应用
如果是在python里使用tesseract:
需要另外下载pytesseract
pip install pytesseract
或者可以选择清华大学镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package pytesseract
识别前建议使用opencv将要识别的图片做灰度处理
open-cv安装
pip install opencv-python
同样,可以选择清华大学镜像源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package opencv-python
还需自行安装PIL和numpy来搭配opencv使用
完整Python代码
import pytesseract
from PIL import Image
import cv2
import numpy as np
img = cv2.imread('image.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kernel = np.ones((2, 1), np.uint8)
gray = cv2.dilate(gray, kernel, iterations=1)
gray = cv2.erode(gray, kernel, iterations=2)
gray = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
cv2.imwrite('gray.png', gray)
img = Image.open('gray.png')
result = pytesseract.image_to_string(img, lang="num")
print(result)
如果有任何问题的话欢迎留言评论,也可以直接联系我
邮箱:whenry6688@gmail.com
参考资料:
https://www.jianshu.com/p/6633a7a85add
https://www.programmersought.com/article/64636255596/
https://towardsdatascience.com/simple-ocr-with-tesseract-a4341e4564b6
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)