1. 项目目标
一站制造
企业中项目开发的落地:代码开发
代码开发:SQL【DSL + SQL】
SparkCore
SparkSQL
数仓的一些实际应用:分层体系、建模实现
2. 内容目标
项目业务介绍:背景、需求
项目技术架构:选型、架构
项目环境测试
实施
项目行业:工业大数据
项目名称:加油站服务商数据运营管理平台
中石化,中石油,中海油、壳牌,道达尔……
整体需求
基于加油站的设备安装、维修、巡检、改造等数据进行统计分析
支撑加油站站点的设备维护需求以及售后服务的呼叫中心数据分析
提高服务商服务加油站的服务质量
保障零部件的仓储物流及供应链的需求
实现服务商的所有成本运营核算
具体需求
运营分析:呼叫中心服务单数、设备工单数、参与服务工程师个数、零部件消耗与供应指标等
设备分析:设备油量监控、设备运行状态监控、安装个数、巡检次数、维修次数、改造次数
呼叫中心:呼叫次数、工单总数、派单总数、完工总数、核单次数
员工分析:人员个数、接单次数、评价次数、出差次数
报销统计分析、仓库物料管理分析、用户分析
报表

项目具体需求
提高服务质量,做合理的成本预算
需求一:对所有工单进行统计分析
安装工单、维修工单、巡检工单、改造工单、回访分析
需求二:付费分析、报销分析
安装人工费用、安装维修材料费用、差旅交通费用
加油站设备维护的主要业务流程
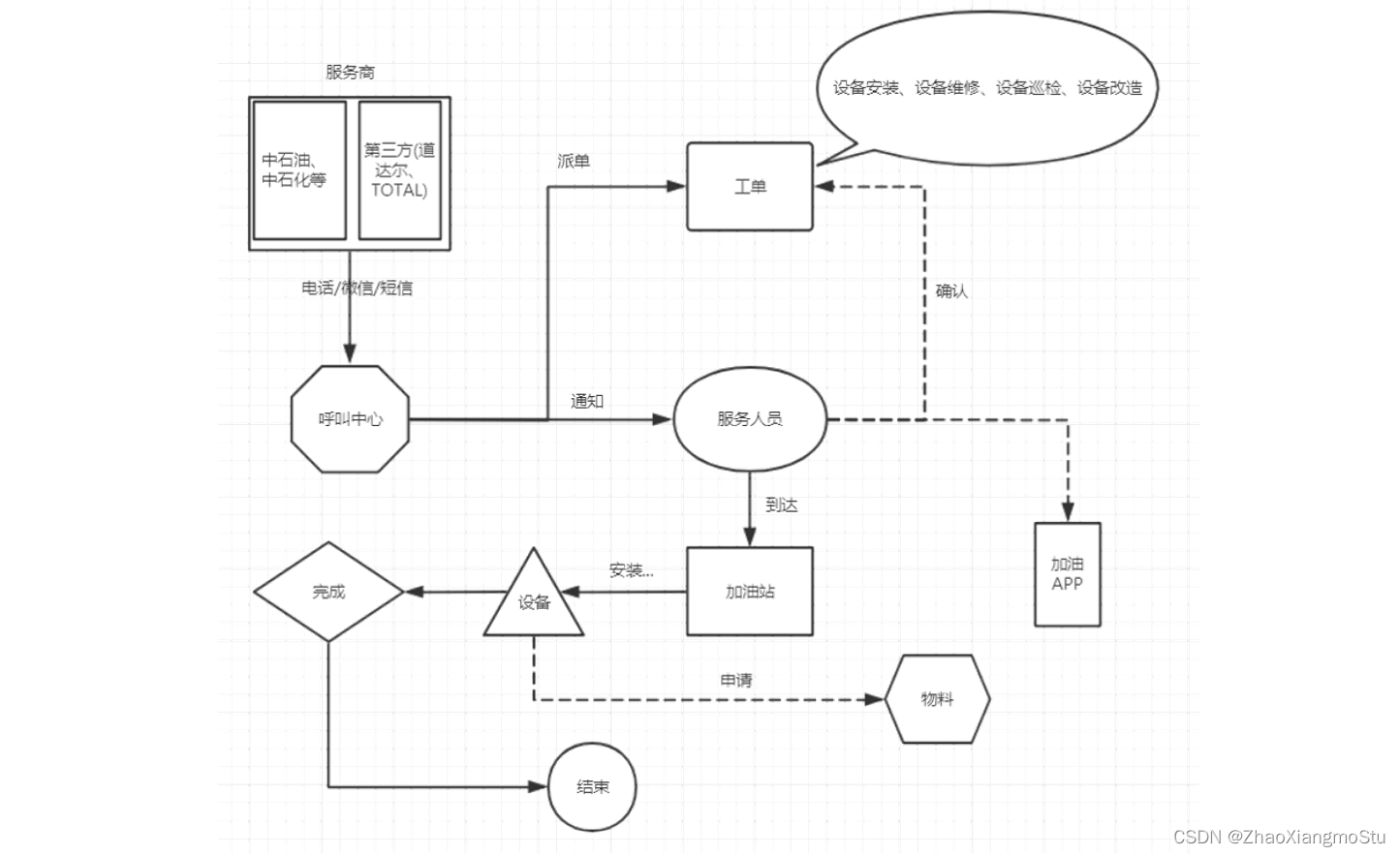
step1:加油站服务商联系呼叫中心,申请服务:安装/巡检/维修/改造加油机
step2:呼叫中心联系对应服务站点,分派工单:联系站点主管,站点主管分配服务人员
step3:服务人员确认工单和加油站点信息
step4:服务人员在指定日期到达加油站,进行设备检修
step5:如果为安装或者巡检服务,安装或者巡检成功,则服务完成
step6:如果为维修或者改造服务,需要向服务站点申请物料,物料到达,实施结束,则服务完成
step7:服务完成,与加油站站点服务商确认服务结束,完成订单核验
step8:工程师报销过程中产生的费用
step9:呼叫中心会定期对该工单中的工程师的服务做回访
小结
掌握加油站设备维护的主要业务流程
工单分析、费用分析、物料分析、回访分析
技术选型
目标:掌握加油站服务商数据运营平台的技术选型
实施
数据生成:业务数据库系统
Oracle:工单数据、物料数据、服务商数据、报销数据等
数据采集
Sqoop:离线数据库采集
数据存储
Hive【HDFS】:离线数据仓库【表】
数据计算
SparkCore:类MR开发方式【写代码调用方法函数来处理:面向对象 + 面向函数】
对非结构化数据进行代码处理
场景:ETL
SparkSQL:类HiveSQL开发方式【面向表】
对数据仓库中的结构化数据做处理分析
场景:统计分析
开发方式
DSL:使用函数【DSL函数 + RDD函数】
SQL:使用SQL语句对表的进行处理
功能:离线计算 + 实时计算
注意:SparkSQL可以解决所有场景的分布式计算,离线计算的选型不仅仅是SparkSQL
SparkSQL/Impala/Presto
使用方式
Python/Jar:spark-submit
ETL
ThriftServer:SparkSQL用于接收SQL请求的服务端,类似于Hive的
Hiveserver2
PyHive :Python连接SparkSQL的服务端,提交SQL语句
JDBC:Java连接SparkSQL的服务端,提交SQL语句
spark-sql -f :运行SQL文件,类似于hive -f
beeline:交互式命令行,一般用于测试
数据应用
MySQL:结果存储
Grafana:数据可视化工具
监控工具
Prometheus:服务器性能指标监控工具
调度工具
AirFlow:任务流调度工具
技术架构
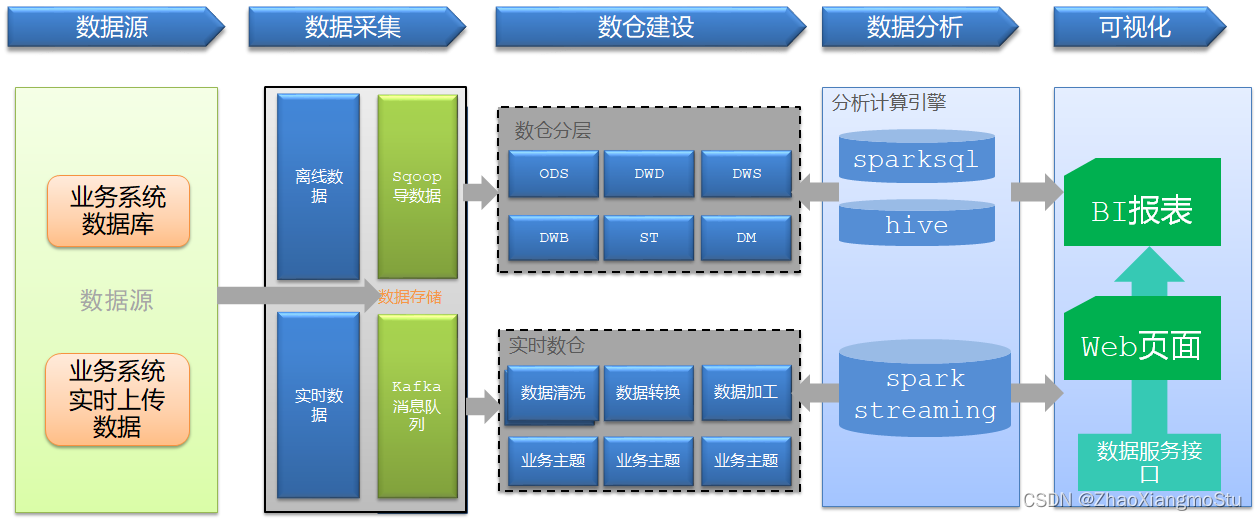
小结
本次项目的技术架构是什么?
Lambda架构:离线计算层 + 实时计算层 + 数据服务层
项目中用到了哪些技术?
数据生成:Oracle
数据采集:Sqoop
数据存储:Hive
数据处理:SparkSQL
数据应用:MySQL + Grafana
数据监控:Prometheus
任务调度:AirFlow
版本控制:Git + Gitee
资源容器:Docker
Docker的介绍
Docker是一个开源的应用容器引擎,使用GO语言开发,基于Linux内核的cgroup,namespace,Union FS等技术,对应用程序进行封装隔离,并且独立于宿主机与其他进程,这种运行时封装的状态称为容器。
目标
提供简单的应用程序打包工具
开发人员和运维人员职责逻辑分离
多环境保持一致性,消除了环境差异
功能:“Build,Ship and Run Any App,Anywhere”
通过对应用组件的封装,分发,部署,运行等生命周期的管理,达到应用组件级别的一次封装,多次分发,到处部署
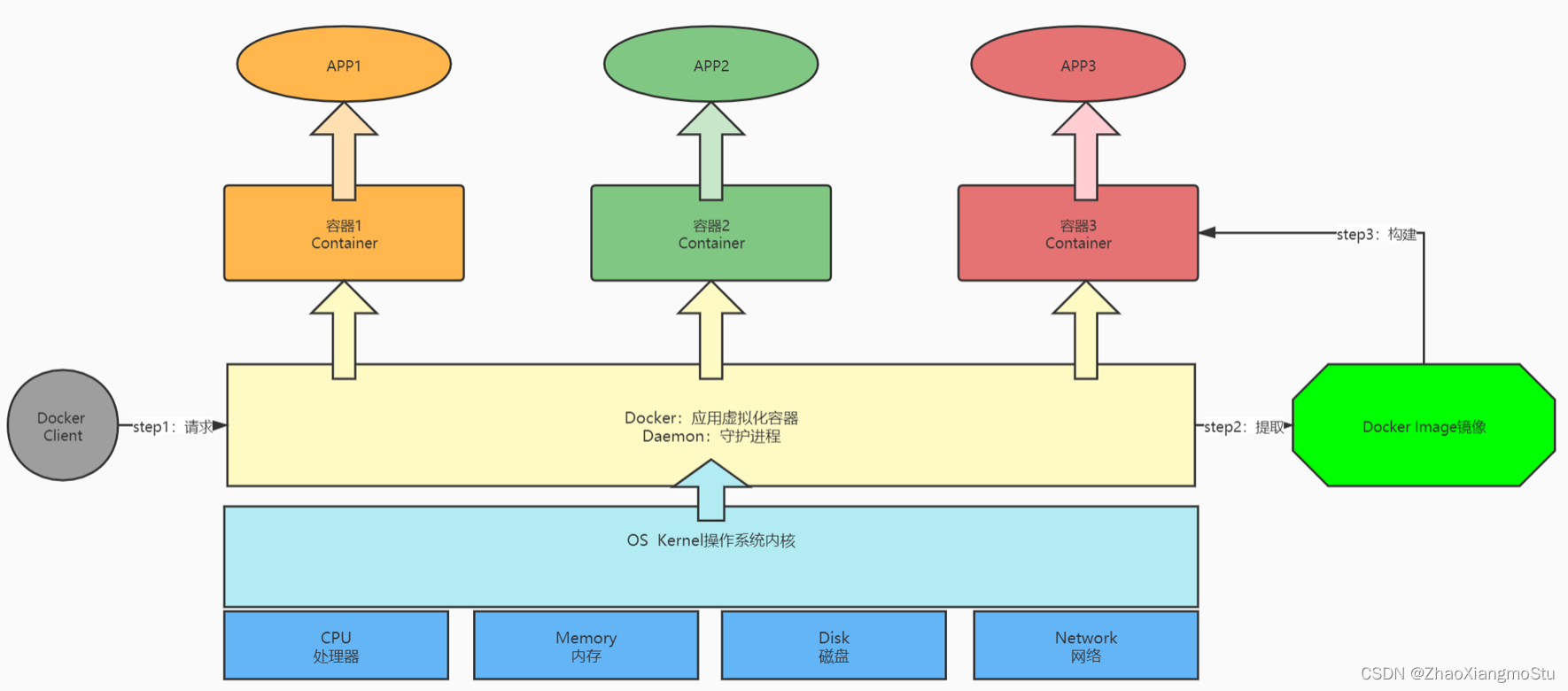
组成
宿主机:安装Docker的那台实际的物理机器
docker client 【客户端】:用于连接服务端,提交命令给服务端
#拉取镜像
docker pull ……
#启动容器
docker run ……
#进入容器
docker exec ……
#查看容器
docker ps ……
docker daemon【服务端】:用于接收客户端请求,实现所有容器管理操作
docker image【镜像】:用于安装APP的软件库,简单点理解为软件的安装包
docker container 【容器】:用于独立运行、隔离每个APP的单元,相当于每个独立的Linux系统
Docker的网络
Docker的本质在一个操作上虚拟了多个操作系统出来,那每个操作之间如何进行网络通信
模式
host模式:每个虚拟系统与主机共享网络,IP一致,用不同端口区分不同虚拟系统
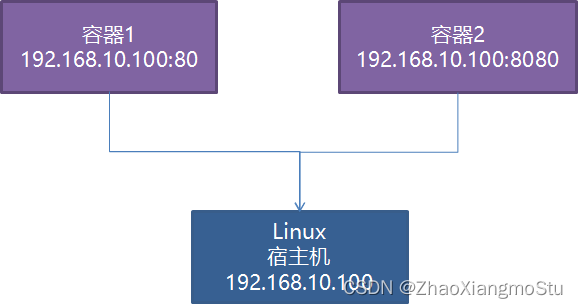
container模式:第一个容器构建一个独立的虚拟网络,其他的容器与第一个容器共享网络
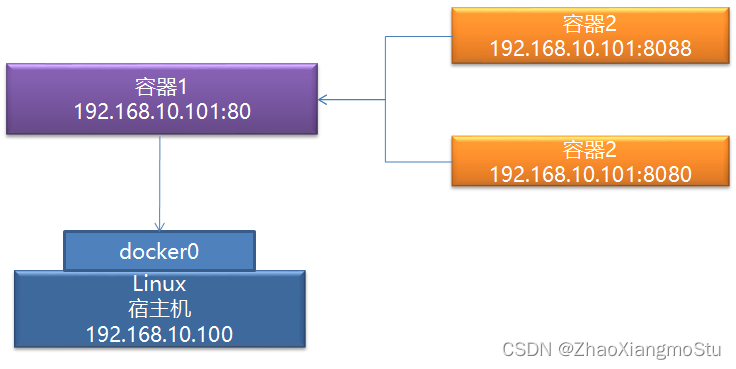
none模式:允许自定义每个容器的网络配置及网卡信息,每个容器独立一个网络

bridge模式:构建虚拟网络桥,所有容器都可以基于网络桥来构建自己的网络配置
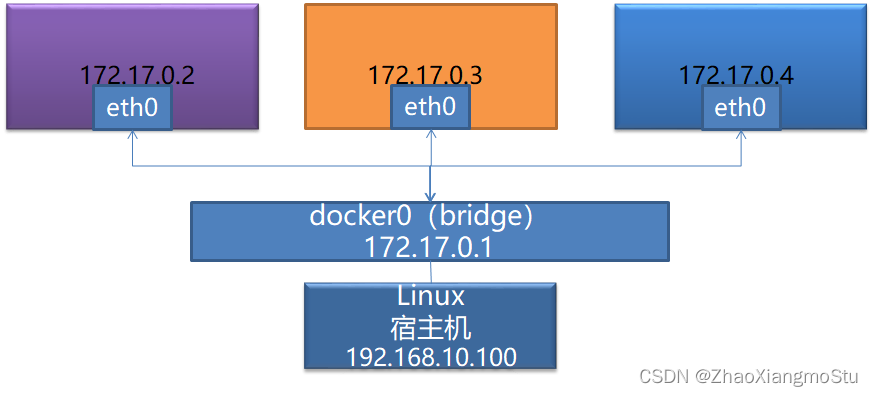
本次项目中使用bridge模式,类似于VM中的Net模式使用
# 创建
docker network create --subnet=172.33.0.0/24 docker-bd0 1
# 查看模式
docker network ls 1
# 删除
docker network rm ……
Docker的使用
Docker管理
# 启动服务
systemctl start docker 1
# 查看状态
systemctl status docker 1
# 关闭服务
systemctl stop docker
image管理
添加镜像
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g 1
列举镜像
docker images 1
移除镜像
docker rmi ……
container管理
# 创建并启动container run = create + start
docker run --net docker-bd0 --ip 172.33.0.100 -d -p 1521:1521 --name oracle 3fa112fd3642
# 列举container
#列举所有的
docker ps -a
#列举正在运行的
docker ps
# 进入container
docker exec -it Name bash
# 退出container
exit
# 删除container
docker rm ……
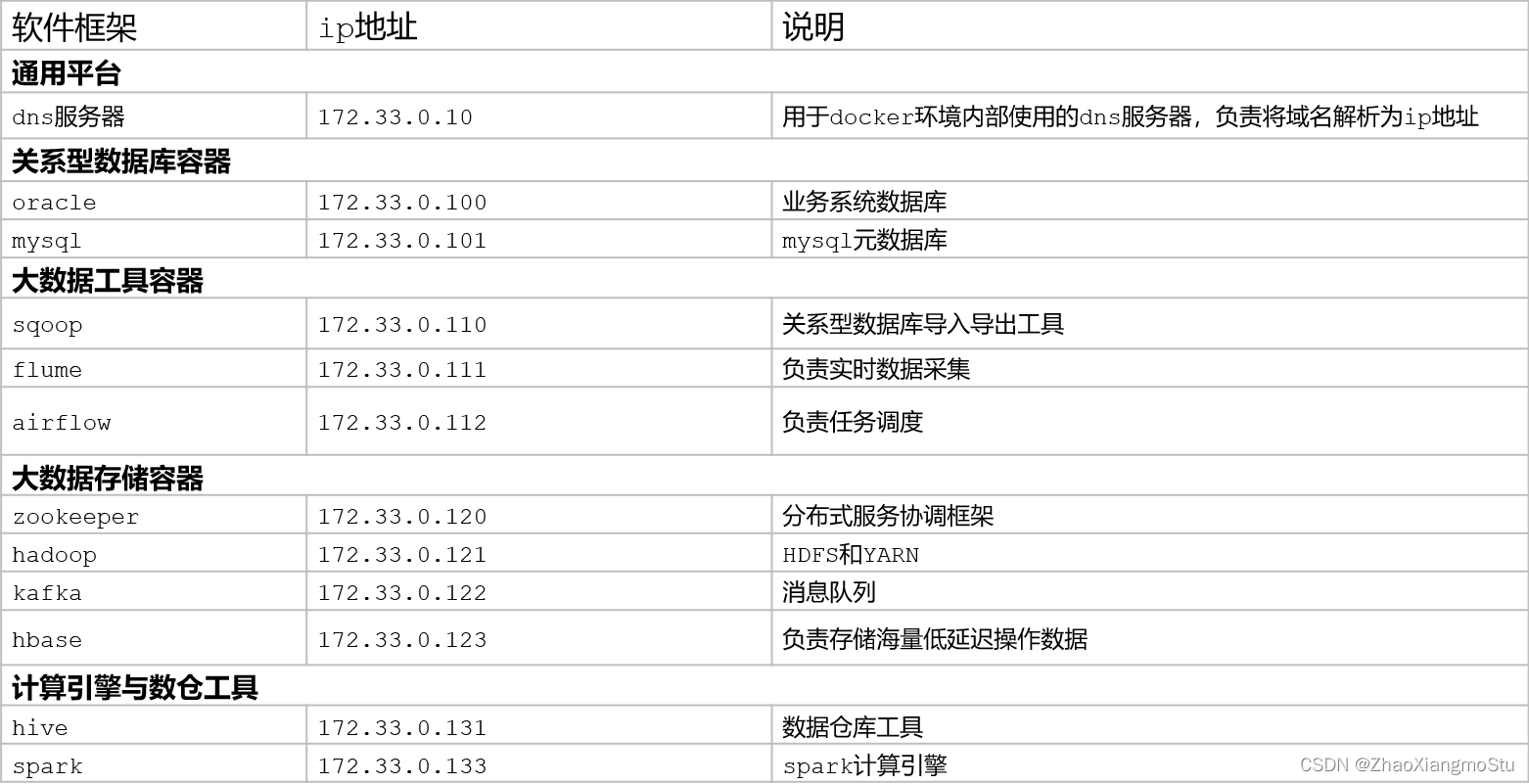
集群软件规划
Shuffle【分区、排序、分组】三种场景
重分区:repartition:分区个数由小变大
调用分区器对所有数据进行重新分区
rdd1
part0:1 2 3
part1: 4 5 6
rdd2:调用分区器【只有shuffle阶段才能调用分区器】
part0:0 6
part1:1 4
part2:2 5
全局排序:sortBy
part0:1 2 5
part1: 4 3 6
方案:将所有数据放入磁盘
实现:对数据做了范围分区:将所有数据做了采样:4
part0:6 5 4
part1:3 2 1
全局分组:groupBy,reduceByKey