说在前面
网络爬虫是一种自动化工具,能够模拟人类在互联网上浏览和提取信息的行为。它的应用范围广泛,包括数据采集、信息监控、搜索引擎优化等方面。而在数据抓取和处理中,获取图片资源往往是一个常见的需求。
本文将介绍如何使用Node.js和相关库构建一个简单而高效的网络爬虫工具,帮助你从百度图片搜索结果中抓取并下载图片。我们将使用Node.js中的axios库发起HTTP请求,并利用cheerio库解析返回的JSON数据。通过这个示例项目,你将学会如何编写一个完整的图片下载工具,可以根据不同的需求进行定制和扩展。
需要注意的是,网络爬虫在使用过程中需要遵守法律法规,尊重网站的隐私政策和使用条款。在进行数据抓取时,请确保遵守相关规定并尊重他人的权益。
代码实现
1、抓取百度图片搜索结果
我们将介绍如何使用Node.js和相关库构造一个搜索URL并从百度图片搜索结果中抓取所需的信息。具体步骤如下:
(1)构造搜索URL并发起请求
在百度图片搜索页中,我们可以通过修改URL参数来实现不同的搜索结果显示。我们将利用这一点,构造一个新的URL,包含我们需要搜索的关键字和其他必要参数。
在Node.js中,我们可以使用axios库发送HTTP请求,并设置请求头、请求参数等信息。以下代码展示如何构造一个简单的搜索请求:
const axios = require('axios');
const searchKeyword = '银魂'; // 搜索的关键词
const searchUrl = `https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord=${encodeURI(searchKeyword)}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&pn=0&rn=30&gsm=1e&1512323757549=`;
axios.get(searchUrl, {
headers: {
Referer: 'https://image.baidu.com/',
Host: 'image.baidu.com',
}
})
.then(response => {
console.log(response.data);
})
.catch(error => {
console.error(error);
});
在上述代码中,我们首先定义了一个变量searchKeyword,表示需要搜索的关键词。然后,我们使用字符串模板构造了一个新的搜索URL,其中包含了所有必要的参数。其中,关键词需要进行URL编码,以便在请求中正确传递。
接着,我们使用axios库发起GET请求,并设置请求头中的Referer和Host参数。这是因为百度图片搜索需要检查Referer和Host参数,以防止爬虫程序直接访问搜索页面。
(2)解析返回的JSON数据,提取所需的图片链接
当我们发送请求后,服务器会返回一个JSON格式的数据响应。我们需要解析这个响应,提取出其中的图片链接信息。
在Node.js中,我们可以使用cheerio库对HTML或XML文档进行解析。以下代码展示如何解析百度图片搜索结果中的JSON数据:
const cheerio = require('cheerio');
axios.get(searchUrl, {
headers: {
Referer: 'https://image.baidu.com/',
Host: 'image.baidu.com',
}
})
.then(response => {
const $ = cheerio.load(response.data);
const imgList = $('img');
const imgUrlList = [];
imgList.each((index, img) => {
const imgUrl = $(img).attr('src');
if (imgUrl) {
imgUrlList.push(imgUrl);
}
});
console.log(imgUrlList);
})
.catch(error => {
console.error(error);
});
在上述代码中,我们首先使用cheerio的load()方法将返回的数据转换为一个可操作的DOM对象。接着,我们使用cheerio的选择器语法$(‘img’)获取所有的图片标签,并遍历每个标签,提取出其中的src属性。最后,将所有有效的图片链接保存到一个数组中,并输出到控制台。
通过以上方法,我们可以快速而准确地从百度图片搜索结果中抓取所需的图像链接。
2、使用Node.js下载图片
我们将介绍如何利用Node.js从网络上下载图片,并将其保存到本地文件系统中。具体步骤如下:
(1)发送HTTP请求,获取图片数据
在Node.js中,我们可以使用http或https模块发送HTTP请求,并获取服务器响应。以下代码展示如何使用http模块获取百度图片搜索结果中的第一张图片:
const http = require('http');
const fs = require('fs');
const imgUrl = 'https://imgsa.baidu.com/forum/pic/item/6a600c338744ebf8d97f9aa8d0f9d72a6059a771.jpg';
http.get(imgUrl, response => {
let imgData = '';
response.setEncoding('binary');
response.on('data', chunk => {
imgData += chunk;
});
response.on('end', () => {
fs.writeFile('image.jpg', imgData, 'binary', error => {
if (error) {
console.error(error);
} else {
console.log('Image saved');
}
});
});
})
.on('error', error => {
console.error(error);
});
在上述代码中,我们首先定义了一个变量imgUrl,表示需要下载的图片链接。接着,我们使用http模块发起GET请求,并设置响应编码方式为binary,以便正确处理图片数据。
当响应数据开始返回时,我们监听data事件,并将返回的数据拼接到imgData字符串中。当响应结束时,我们使用fs模块的writeFile()方法将图片数据保存到本地文件系统中。在保存文件时,必须将编码方式设置为binary,以便正确写入图片数据。
(2)批量下载多张图片
通过上述代码,我们可以下载单张图片并保存到本地文件系统中。但是,在实际的爬虫应用中,我们通常需要批量下载多张图片。以下代码展示如何使用Promise.all()方法和async/await语法,同时下载多张图片并等待所有下载完成:
const http = require('http');
const fs = require('fs');
const imgUrls = [...]; // 保存需要下载的多张图片链接
const downloadImage = imgUrl => {
return new Promise((resolve, reject) => {
http.get(imgUrl, response => {
let imgData = '';
response.setEncoding('binary');
response.on('data', chunk => {
imgData += chunk;
});
response.on('end', () => {
const fileName = imgUrl.substring(imgUrl.lastIndexOf('/') + 1);
fs.writeFile(fileName, imgData, 'binary', error => {
if (error) {
reject(error);
} else {
resolve(`Image ${fileName} saved`);
}
});
});
})
.on('error', error => {
reject(error);
});
});
};
(async () => {
try {
const result = await Promise.all(imgUrls.map(downloadImage));
console.log(result);
} catch (error) {
console.error(error);
}
})();
在上述代码中,我们首先定义了一个数组imgUrls,其中保存了需要下载的多张图片链接。接着,我们定义了一个名为downloadImage的函数,用于下载单张图片并返回Promise对象。
在函数中,我们使用http模块发送GET请求,并将响应数据拼接到imgData字符串中。当响应结束时,我们从图片链接中提取出文件名,然后使用fs模块的writeFile()方法保存图片数据到本地文件系统中。在保存文件时,如果发生错误,则会将Promise状态设置为rejected;否则,将Promise状态设置为resolved,并返回一个成功信息。
最后,我们使用async/await语法和Promise.all()方法,同时下载多张图片,并等待所有图片下载完成。在下载过程中,我们可以监听Promise的状态变化,并输出下载进度或错误信息。
3、实现一个简单的图片下载工具
const http = require('http');
const https = require('https');
const fs = require('fs');
const path = require('path');
/**
* 下载图片
* @param {string} url 图片链接
* @param {string} dest 保存路径
*/
function downloadImage(url, dest) {
const protocol = url.startsWith('https') ? https : http;
return new Promise((resolve, reject) => {
protocol.get(url, response => {
if (response.statusCode !== 200) {
reject(new Error(`Failed to download image (${response.statusCode})`));
return;
}
const ext = path.extname(url);
const fileName = `${Date.now().toString()}${ext}`;
const filePath = path.join(dest, fileName);
const fileStream = fs.createWriteStream(filePath);
response.pipe(fileStream);
fileStream.on('error', error => {
reject(error);
});
fileStream.on('finish', () => {
resolve(filePath);
});
})
.on('error', error => {
reject(error);
});
});
}
// Example usage
(async () => {
try {
const url = 'https://example.com/image.jpg';
const dest = './images';
const filePath = await downloadImage(url, dest);
console.log(`Image downloaded: ${filePath}`);
} catch (error) {
console.error(error);
}
})();
上述代码中,我们定义了一个downloadImage()函数,用于下载图片。该函数接受两个参数:图片链接和保存路径。在函数内部,我们首先判断图片链接的协议(http或https),然后使用相应的模块(http或https)发送GET请求。
当响应数据开始返回时,我们首先判断响应状态码。如果状态码不为200,则认为下载失败,并将Promise状态设置为rejected;否则,从图片链接中提取出文件扩展名(例如.jpg),并使用当前时间戳生成新的文件名。
接着,我们使用path.join()方法拼接保存路径和文件名,创建一个可写入流,并将响应数据导入该流中。在写入过程中,我们监听错误事件,并在发生错误时将Promise状态设置为rejected;在写入完成时,将Promise状态设置为resolved,并返回文件路径。
最后,我们使用async/await语法调用downloadImage()函数,下载一张图片,并输出下载进度或错误信息。
示例与效果展示
完整代码
const axios = require("axios");
const cheerio = require("cheerio");
const fs = require("fs");
async function getSearchResults(searchQuery, page = 1) {
const searchUrl = `https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&query=${encodeURIComponent(
searchQuery
)}&word=${encodeURIComponent(searchQuery)}&pn=${page}`;
try {
const response = await axios.get(searchUrl);
const imageData = response.data;
// 在这里处理API返回的图片数据
processImageData(imageData, page);
} catch (error) {
console.error("Error:", error);
}
}
const downloadImage = async (imageUrl, filename) => {
const imagePath = `./images/${filename}`;
const writer = fs.createWriteStream(imagePath);
const response = await axios({
url: imageUrl,
method: "GET",
responseType: "stream",
});
response.data.pipe(writer);
return new Promise((resolve, reject) => {
writer.on("finish", resolve);
writer.on("error", reject);
});
};
const processImageData = async (imageData, page) => {
const imageLinks = [];
// 解析图片数据并提取图片链接
for (const result of imageData.data) {
if (result.middleURL) {
imageLinks.push(result.middleURL);
}
}
// 下载图片
for (let i = 0; i < imageLinks.length; i++) {
const imageUrl = imageLinks[i];
const filename = `image_${page + i}.jpg`;
await downloadImage(imageUrl, filename);
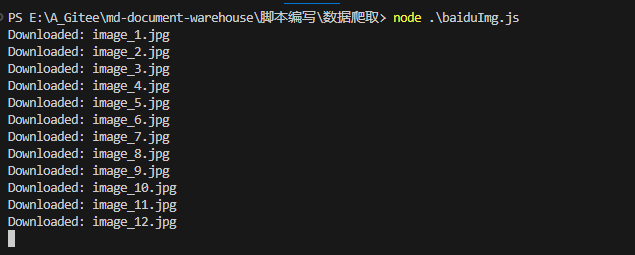
console.log(`Downloaded: ${filename}`);
}
};
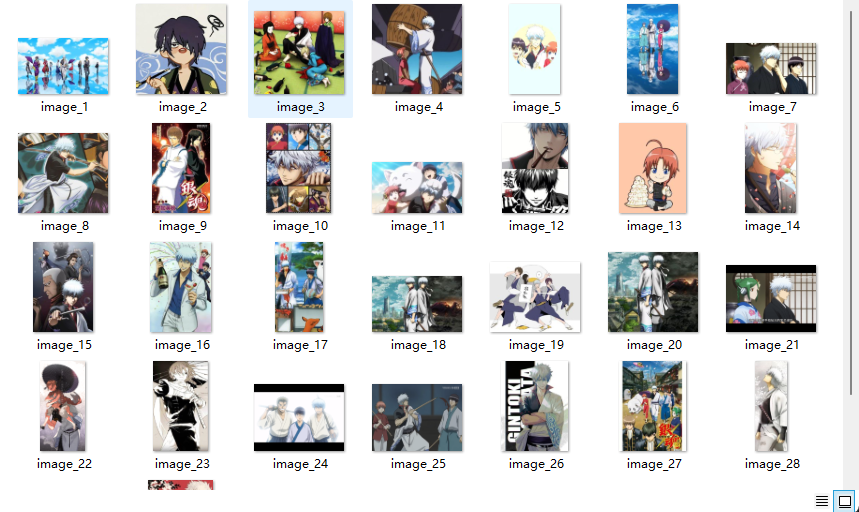
getSearchResults("银魂", 1);
下载图片
公众号
关注公众号『
前端也能这么有趣
』,获取更多新鲜内容。
说在后面
???? 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 ???? ,平时也喜欢写些东西,既为自己记录 ????,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 ????,写错的地方望指出,定会认真改进 ????,偶尔也会在自己的公众号『
前端也能这么有趣
』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 ????。