作者:张云杨
2023 年 11 月 27 日,AWS 在 re:Invent 大会上宣布推出 Amazon Aurora Limitless Database 预览版。根据
官方博客
的说明,Aurora Limitless 允许用户在 PB 级别的数据规模上进行数百万次/秒的写请求,并且保持了 Serverless 的使用体验,帮助开发者专注于构建高拓展性的应用程序而无需维护复杂的数据库方案。

AWS 在自研数据库方面的投资一直备受工业界认可,从 DynamoDB 开始,到 Redshift 和 Aurora,一直稳稳压住 MonogoDB、Snowflake、Oracle 等强大的竞争对手。然而这次发布的 Aurora Limitless,从产品形态和技术架构上看竟然隐隐约约有种“致敬”阿里云
PolarDB-X
的感觉,而从强调写入性能的应用场景上来看又跟自家的 DynamoDB 有些重合,一反以往泾渭分明的风格。 PolarDB 的整个产品体系在诞生之初受到了 Aurora 非常大的启发,但是 PolarDB-X 的出现又大大早于 Aurora Limitless,这很有趣。(难道 AWS 终于开始从中国进口数据库人才了?)
官方介绍:PolarDB-X 是一款面向超高并发、海量存储、复杂查询场景设计的云原生分布式数据库系统。其采用 Share Nothing 与存储计算分离架构(Share Everything),支持水平扩展、分布式事务、混合负载等能力,具备企业级、云原生、高可用、高度兼容 MySQL 生态等特点。
技术架构
从技术架构上看,Aurora Limitless 和 PolarDB-X 非常接近。一般厂商会在 Share Everything 或 Share Nothing 两条路中选一种,比如 TiDB、OceanBase、CockroachDB、PlanetScale 都采用了 Share Nothing 架构,而 PolarDB、Aurora 和 Neon 则采用了 Share Everything 架构。
PolarDB-X 作为一个独立产品,它的 Share Everything + Share Nothing 融合架构是在 2019 年第一次提出的,充满了阿里云特色;而 Aurora Limitless 应该是全球第二个采用该融合架构的数据库产品。双方的架构图,看上去只有配色的差别
:
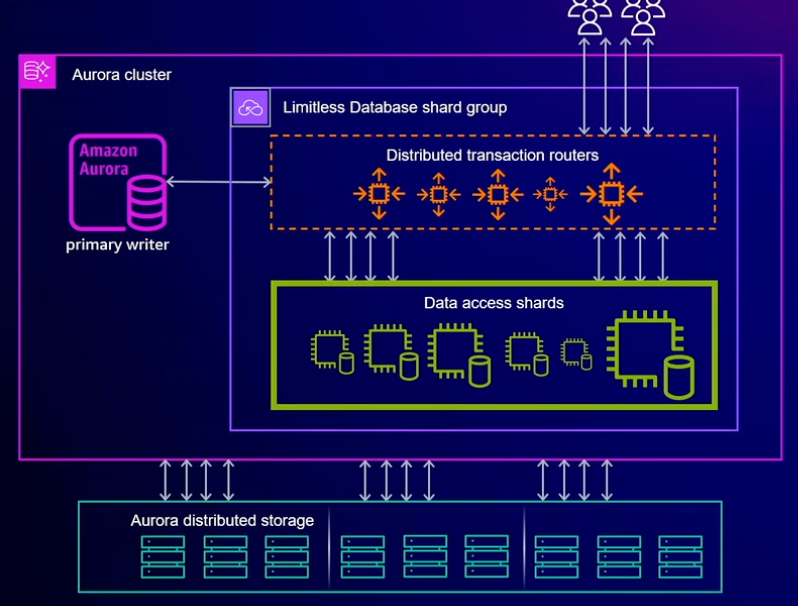
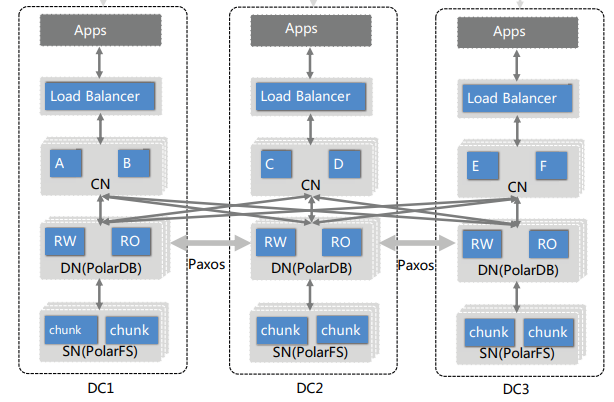
在这个分布式架构下面:
-
库和表的路由都是由 Proxy 控制的,只不过在 Aurora Limitless 里面叫做“事务路由”,而在 PolarDB-X 里面叫做“计算节点”;
-
每个 Shard 都是由多个 MySQL 进程构成,分布在不同的服务器上保证高可用;
-
每个 Shard 都包含全局表的所有数据和分片表的部分数据,分配主要看数据的分区键哈希值;
-
当某个 Shard 的数据量太大,或者访问的热度过高时,部分数据会被迁移到比较空闲的 Shard。
双方都声称做到了无感的水平扩缩容。虽然数据迁移在支持多点挂载的共享存储上更容易实现,但是无感一般特指在负载比较低的时候做缩容操作,在负载比较高的时候做扩容,
体验可能更接近阵痛而不是无感
。????

分布式事务
作为分布式系统,Aurora Limitless 的全局时间戳是通过 EC2 TimeSync Service 获得的,虽然协议上使用了 NTP,但是精度上更接近 Google 提出的 TrueTime 方案,把时间误差控制在了
毫秒级别
。Aurora Limitless 支持全局范围的写后读、本地事务(一阶段提交)和分布式事务(两阶段提交),在 RR 和 RC 两种事务隔离级别下的体验完全对齐 PostgreSQL 的单机事务。
PolarDB-X 的全局时间戳采用了
Time Stamp Oracle 方案
,去除了外部的 NTP 依赖,但是引入了一个 GMS 组件来提供 TSO,以保证时间戳始终单调递增。值得一提的是,PolarDB-X 的时间戳格式是“物理时钟+逻辑时钟”的形式,意味着为 HLC 方案做好的切换准备。不出意料的,PolarDB-X 也有写后读、本地事务、分布式事务,以及 RR 和 RC 两种事务隔离级别。
无论是 Aurora Limitless 还是 PolarDB-X,都不太推荐用户在数据库上面做太多分布式事务。毕竟二阶段提交的限制摆在那里,如果写入全部是分布式的话,谁都不太可能做到几百万/秒的提交。

语法兼容
将集中式数据库改造成分布式数据库,最大的问题就是老的使用习惯兼容不了
,特别是复杂查询、存储过程、触发器、三方插件。如果兼容性做的不好,老的应用就没有办法用比较小的代价迁移到分布式数据库上面。Aurora Limitless 目前能够比较好地支持分片内的操作,也能在创建索引、收集统计信息和少量聚合操作上面充分利用多个分片的计算资源,但是没有给出完整的兼容性列表,可能要到正式版出来之后才会有。

PolarDB-X 出道更早,对于不兼容的使用习惯有比较明确的说明,比如标识符限制、SQL 语法限制、数据库对象
限制
:

使用体验
在实际的使用体验上,Aurora Limitless 还是比较友好的,根据 AWS 官方给出的
指引文档
和 re:Invent 上面的
演讲视频
,用户只需要两步就能开启“无尽”的体验。
首先,用户需要通过 AWS Console 或者 API 为指定的 Aurora 集群开启 DB Shard Group:

接着,用 PG 客户端(比如 psql)连接 Limitless Endpoint,通过设置环境变量的方式控制表的类型,例子和 PolarDB-X 也非常像:
# Create Sharded Table
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';
CREATE TABLE customer (
cust_id INT PRIMARY KEY NOT NULL,
name ТЕХТ,
email VARCHAR (100)
);
# Create Co-located Table
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key:='{"cust_id"}';
SET rds_aurora.limitless_create_table_collocaate_with='customer';
CREATE TABLE order (
order_id INT NOT NULL,
cust_id INT NOT NULL,
amount DOUBLE NOT NULL,
tax_rate_id DOUBLE,
PRIMARY KEY (order_id, cust_id)
);
# Create Reference Table
SET rds_aurora.limitless_create_table_mode=='reference';
CREATE TABLE tax_rate (
tax_rate_id INT PRIMARY KEY NOT NULL,
city TEXT NOT NULL,
state TEXT,
country TEXT NOT NULL,
tax_rate DOUBLE NOT NULL
) ;
PolarDB-X 的对象概念类似,只是操作方法上面稍有不同。用户在建表的时候指定分区键或者表组(Table Group),具有相同键值的数据就会被存放在同一个 Shard 内。不过 PolarDB-X 比 Aurora Limitless 多了一个全局二级索引,可能很快就会被“借鉴”。
网友评论
Hacker News 的热心群众对 Aurora Limitless 进行了褒贬不一的点评:有开发者认为 Limitless 是一个有野心的说法,迫不及待想要在生产环境使用;而有的开发者则认为 Limitless 只适合财富 500 企业,
并不适合初创公司
。关于 Citus 魔改换皮的猜测,引得 AWS 官方不得不下场解释了一番,顺便炒了一下
Aurora 论文的冷饭
。

Reddit 上也有类似的讨论。很多人在质疑这个是不是能 scale down 到 0,也有人会说性价比的问题以及什么程度的数据量才值得去采用 Aurora Limitless。

怎么说呢,连评论都有些似曾相识。虽然国内有不少人批评分布式数据库、HTAP 数据库的应用场景有限。但是实际上,不仅仅 AWS Aurora,还有
Oracle HeatWave
都在往这些地方挤。也许阿里云只是比 AWS、Oracle 更早感受到了增长的压力,不得不在技术上面做更多的投入,并且真的在部分领域实现了“遥遥领先”?从这个角度看,AWS 的产品特性会越来越像阿里云。 我们甚至可以大胆猜测,AWS Aurora 会不会在某天也推出了 HTAP 特性,通过不同的存储格式或者使用更多的内存来提升事务性引擎的分析能力。 ????

最后
Aurora Limitless 目前还在 Preview 状态,正式开放估计要 6-12 个月。而 PolarDB-X 不仅仅提供了阿里云托管的版本,还提供了可以运行在其它环境的开源版本。如果大家对分布式数据库感兴趣,又不想花钱在云上试用,不妨可以看看 KubeBlocks 这个项目。
KubeBlocks 已经完成了 PolarDB-X 的兼容性认证,支持一键拉起 PolarDB-X 集群,欢迎大家试用并留下宝贵意见!
官网:www.kubeblocks.io
GitHub:github.com/apecloud/kubeblocks
体验文档:kubeblocks.io/docs/release-0.7/user_docs/try-out-on-playground/try-kubeblocks-on-your-laptop
关于作者
张云扬,云猿生数据 COO & 联合创始人,前阿里云数据库产品总监,阿里云数据库产品及运营负责人。在职期间主要负责 RDS、MongoDB、Redis、PolarDB 等产品的用户体验、商业化和国际化,带领阿里云数据库产品第一次进入 Gartner OPDBMS 魔力象限。