workbox学习笔记
一 PWA介绍
1.1 学习workbox之前先了解一下PWA(如果了解请跳过)
PWA( 全称:Progressive Web App )也就是说这是个渐进式的网页应用程序。一个 PWA 应用首先是一个网页, 可以通过
Web 技术编写出一个网页应用. 随后添加上Manifest 和 Service Worker 来实现 PWA 的安装和离线等功能。
而ServiceWorker是PWA中最重要的一部分,它就像是一个网站安插在用户浏览器中的大脑。Service Worker是这样被注册
在页面上的。
对比原生应用
原生应用:
• 使用原生SDK和开发工具开发
• 需要考虑跨平台,不同系统往往需要独立开发
• 需要发布到应用商店才能下载使用
• 可以安装到手机主屏,生成应用图标
• 直接运行于操作系统上,访问系统资源方便
• 可以离线使用
• 可以获取消息通知
PWA应用:
• 使用HTML,CSS,JS开发
• 无需考虑跨平台,只需要考虑浏览器兼容性
• 通过url访问,无需发布到应用商店
• 可以安装到手机主屏,生成应用图标
• 运行于浏览器中,可访问系统资源
• 可以离线使用
• 可以获取消息通知
基于https
HTTPS 不仅仅可以保证你网页的安全性,还可以让一些比较敏感的 API 完美的使用。值得一提的是,SW 是基于 HTTPS 的,
所以,如果你的网站不是 HTTPS,那么基本上你也别想了 SW。但是在因为方便开发者在本地测试,在本地调试时支持
localhost和127.0.0.1本地域名
if(navigator.serviceWorker!=null){
navigator.serviceWorker.register('/sw.js', {scope: '/'}).then(function(registartion){
console.log('support sw',registartion.scope)
})
}
为什么说SW(下文将ServiceWorker简称为SW)是网站的大脑?举个例子,如果在www.example.com的根路径下注册了一个SW,
那么这个SW将可以控制所有该浏览器向www.example.com站点发起的请求。只需要监听fetch事件,你就可以任意的操纵请求,
可以返回从cacheStorage中读的数据,也可以通过fetch API发起新的请求,你可以操作他返回的请求,将其存到浏览器的缓
存中,你甚至可以new一个Response,返回给页面。例如下面是一个比较完整的sw文件
var cacheStorageKey='check-demo-1.0'
var cacheList=[
]
self.addEventListener('install',function(e){
e.waitUntil(
caches.open(cacheStorageKey)
.then(function(cache){
return cache.addAll(cacheList)
})
.then(function(){
return self.skipWaiting()
})
)
})
self.addEventListener('fetch',function(e){
var reqUrl = e.request.url
if (someRules) {
e.respondWith(
caches.match(e.request).then(function(response){
if(response!=null){
return response
}
var fetchRequest = e.request.clone();
return fetch(fetchRequest)
.then(function(res){
if(!res || res.status !==200){
return res
}
var responseToCache = res.clone()
caches
.open(cacheStorageKey)
.then(function(cache){
cache.put(e.request,responseToCache)
});
return res
}
)
})
)
}
})
self.addEventListener('activate',function(e){
e.waitUntil(
caches.keys().then(function(cacheNames){
return Promise.all(
cacheNames.filter(function(cacheName){
return cacheName !==cacheStorageKey
}).map(function(cacheName){
return caches.delete(cacheName)
})
)
}).then(function(){
return self.clients.claim()
})
)
})
其实所有站点SW的install和active都差不多,无非是做预缓存资源列表,更新后缓存清理的工作,
逻辑不太复杂,而重点在于fetch事件。上面的代码,我把fetch事件的逻辑省略了,因为如果认真
写的话,太多了,而且也不利于讲明白缓存策略这件事。想象一下,你需要根据不同文件的扩展名
把不同的资源通过不同的策略缓存在caches中,各种css,js,html,图片,都需要单独搞一套缓存
保存到桌面
Pwa有一个很方便的功能能就是将页面以快捷图标的方式保存到桌面,使得一个它更加接近原生app,实现这种方式需要满足三个条件:
• 包含一个 manifest.json 文件,其中包含 short_name 以及 icons 字段
• 包含 service workers
• 使用 HTTPS(这个好像是废话,既然使用了 service workers,那肯定已经基于 https了)
从上面 3 点可以看到,如果你的应用已经是个 PWA 应用的话,那么,第二,第三点就已经满足了,添加至桌面的功能其实只需为项目添加一个描述性的配置文件 manifest.json 就可以了。
那 manifest.json 这东西到底是啥?
它是 PWA 的一部分,是一个 JSON 格式的文件用来描述应用相关的信息,目的是提供将应用添加至桌面的功能,从而使用户可以无需下载就可以如应用一般从桌面打开 web 应用,大大增强用户体验和粘性。
以下是mainfest的一些参数解析:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P7jhWV7v-1588059855159)(https://github.com/gla-TBG/image-storage/blob/master/workbox-study/3.4-2.png?raw=true)]
1.2 什么是workbox?
workBox由许多node模块和插件库组成的一个库,可以轻松缓存资产并充分利Service Worker的
特性用于构建Progressive Web Apps的功能。workbox的出现就是为了解决上述sw的问题的,它
被定义为PWA相关的工具集合其实可以把workbox理解为Google官方PWA框架,因此workbox也是
基于https的,它解决的就是用底层API写PWA太过复杂的问题。这里说的底层API,指的就是去监听
SW的install, active, fetch事件做相应逻辑处理等。
二 使用workbox
2.1安装
方法一:使用workbox sw 通过cdn开始使用此模块的最简单方法是通过CDN。 开发者只需将以下内容添加到sw.js:
importScripts('https://storage.googleapis.com/workbox-cdn/releases/3.0.0/workbox-sw.js')
方法二:使用本地Workbox Files
通过workbox-cli的copyLibraries命令或GitHub Release获取文件,然后通过modulePathPrefix配置选项告诉
workbox-sw在哪里找到这些文件。如果你把文件放在/ third_party / workbox /下,你会像这样使用它们:
importScripts('/third_party/workbox/workbox-sw.js');
workbox.setConfig({
modulePathPrefix: '/third_party/workbox/'
});
2.2 基础实例
要开始使用Workbox,只需要在service worker中导入工作workbox-sw.js文件。
更改你的service worker,使其具有以下importScripts()调用。
importScripts('https://storage.googleapis.com/workbox-cdn/releases/4.3.1/workbox-sw.js');
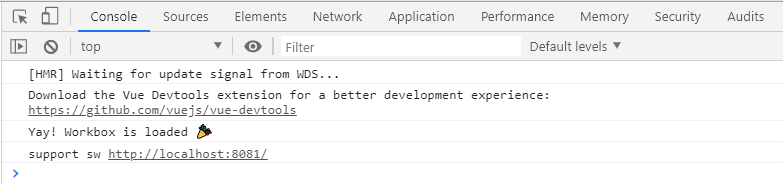
if (workbox) {
console.log(`Yay! Workbox is loaded 🎉`);
} else {
console.log(`Boo! Workbox didn't load 😬`);
}
运行效果
workbox的主要功能之一是路由和缓存策略模块。它允许你监听来之网页的请求,并提供多种策略来处理你的请求
workbox.skipWaiting();
workbox.clientsClaim();
一个简单的例子,缓存所有js文件
workbox.routing.registerRoute(
new RegExp('.*\.js'),
new workbox.strategies.NetworkFirst()
);

文件已存入缓存中

需要注意的是:
1、请求的类型很重要。默认情况下,路由已注册了“GET”请求的事件监听。 如果开发者希望拦截其他类型的请求,则需要指定额外的方法。
2、路由注册的顺序很重要。如果注册了多个可以处理请求的路由,则首先注册的路由将优先响应请求
三 模块介绍
3.1 workbox.routing
Service worker可以拦截网页的网络请求,它可以把从网络请求中缓存的或者在service worker中
请求获取的内容返回给浏览器。也就是说浏览器不会再直接与服务器交互,而是由service worker代理。
Workerbox.routing是一个模块,可以容易地将这些请求“路由”映射到不同的响应,并提供设置相应策略的方法。
3.2 路由的匹配和处理
路由器将请求与路由匹配,然后处理该请求(即提供响应)的过程。
workbox.routing.registerRoute()接收两个变量:
1. matchFunction(请求的规则)
2. handler (处理符合规则的请求)
可通过三种方式将请求与workbox路由相匹配 :
1、 字符串
workbox.routing.registerRoute(
'/https://some-other-origin.com/logo.png',
handler
);
2、正则表达式
正则表达式是根据网站的完整的URL匹配的,如果有匹配,handler会被触发
例如:
workbox.routing.registerRoute(
new RegExp('\\.js$'),
jsHandler
);
workbox.routing.registerRoute(
new RegExp('\\.css$'),
cssHandler
);
workbox.routing.registerRoute(
new RegExp('/blog/\\d{4}/\\d{2}/.+'),
handler
);
3、回调函数
const matchFunction = ({url, event}) => {
return false;
};
workbox.routing.registerRoute(
matchFunction,
handler
);
3.3 使用缓存策略处理请求
所谓缓存策略,就是当workbox捕获到一条已存在于缓存中的请求时,以何种方式获取他的返回(网络请求/缓存)
1、StaleWhileRevalidate
StaleWhileRevalidate模式允许你使用缓存的内容尽快响应请求(如果可用),如果未缓存,则回退到网络请求。
然后,网络请求用于更新缓存。这是一种相当常见的策略,适合更新频率很高但重要性要求不高(至少允许一次缓存
读取)的内容。在有缓存的情况下,该模式保证了客户端第一时间拿到数据的同时,也会去请求网络资源更新缓存,
保证下次客户端从缓存中读取的数据是最新的。因此该模式不能减轻后台服务器的访问压力,但却能给前端用户提供
快速响应的体验。
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.staleWhileRevalidate()
);

2、Cache First (缓存优先,缓存回落到网络)
如果缓存中有响应,则将使用缓存的响应来完成请求,根本不会使用网络。 如果没有缓存的响应,则将通过网络请求
来满足请求,并且将缓存响应,以便直接从缓存提供下一个请求。该模式可以在为前端提供快速响应的同时,减轻后
台服务器的访问压力。但是数据的时效性就需要开发者通过设置缓存过期时间或更改sw.js里面的修订标识来完成缓
存文件的更新。一般需要结合实际的业务场景来判断数据的时效性。
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.cacheFirst()
);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1PmxtxWy-1588059855164)(https://github.com/gla-TBG/image-storage/blob/master/workbox-study/3.1-2.png?raw=true)]
3、Network First (网络回落到缓存)
对于经常更新且关键(由业务判断出来)的请求,网络优先策略是理想的解决方案。 默认情况下,它将尝试从网络获
取最新请求。 如果请求成功,它会将响应放入缓存中。 如果网络无法返回响应,则将使用缓存响应。这意味着只要当
第一次请求成功时,service worker就会缓存一份请求结果。当后续重复请求时,缓存也会每次更新。若网络请求失
败时,只要缓存里有内容,就能让前端获取一个响应(从service worker的缓存里)。因此,此种模式提高了前端页
面的稳固性,即使在网络请求失败的情况下,页面也能从上次的缓存中读取到数据展示,而不是粗鲁的告诉用户网络请
求失败的一个响应。
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.networkFirst()
);

4、Network Only
如果你需要从网络中完成特定请求,则只使用网络策略。
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.networkOnly()
);

只使用网络策略,此时缓存中并无任何数据

5、Cache Only
仅缓存策略确保从缓存获取请求。 这在workbox中不太常见,但如果你有自己的预先缓存步骤则可能很有用。
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.cacheOnly()
);

3.4 配置策略
一些常用的配置:
· cacheName (存入缓存的名字)
· Workbox附带了一组可以与这些策略一起使用的插件, 可以设置缓存在策略中使用的过期限制,最大条目数,哪些特定返回能加入缓存等
1、策略中使用的缓存名
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.staleWhileRevalidate({
cacheName: 'js-cache',
})
);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LECRNgAt-1588059855168)(https://github.com/gla-TBG/image-storage/blob/master/workbox-study/3.4-1.png?raw=true)]
2、 workbox.expiration.Plugin —— 根据缓存中的项目数或缓存请求的期限删除缓存的请求
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.cacheFirst({
cacheName: 'js-cache',
plugins: [
new workbox.expiration.Plugin({
maxEntries: 60,
maxAgeSeconds: 30 * 24 * 60 * 60,
}),
]
})
);
插件将检查配置的缓存,并确保缓存数量不超过限制。如果超过,最早的条目将被删除。
3、workbox.cacheableResponse.Plugin —— 根据响应的状态代码或标头限制缓存哪些请求
workbox.routing.registerRoute(
new RegExp('.*\.js'),
workbox.strategies.cacheFirst({
cacheName: 'js-cache',
plugins: [
new workbox.cacheableResponse.Plugin({
statuses: [200, 404],
headers: {
'X-Is-Cacheable': 'true',
}
})
]
})
);
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)