Jvm调优
- java代码是怎么运行起来的
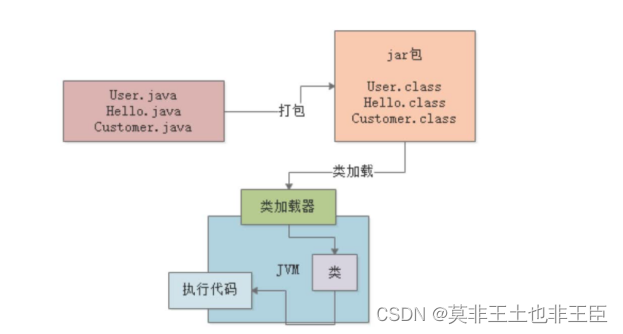
- 类加载到使用的过程

加载:用这个类的时候开始加载。类在使用的时候触发类加载器,把类加载到jvm中。

2.1验证阶段
类加载之前先进行验证是否符合JVM规范后交给JVM。比如final是否合规、类型是否正确、静态变量是否合理等
2.2准备阶段
加载完成后进入准备阶段,准备阶段是为static 字段分配内存,并设定默认值,解析类和方法确保类与类之间的相互引用正确性,完成内存结构布局

2.3解析阶段
解析阶段是将符号引用转化为直接引用的过程

符号引用:用一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时可以定位到目标即可
直接引用:直接引用可以直接指向目标的指针,相对偏移量或者一个能间接定位到目标的句柄.如果有了直接引用,那么引用的目标在虚拟机的内存中一定存在.
并未明确指出解析的具体时间,可以是在加载时就解析常量池中的符号引用,或者是等到第一个符号引用将要被使用前解析它,这个java虚拟机规范中没有明确说明.对同一个符号引用进行多次解析是存在的,虚拟机可以对第一次解析的结果进行缓存,譬如运行时直接引用常量池中的状态,并把常量标示为已解析状态,从而避免了重复动作.
解析动作主要针对类或接口,字段,类方法,接口方法,方法类型,方法句柄,调用点限定符等7类符号引用进行,分别对应了常量池中的constant_class_info,constant_firldref_info,constant_methodref_info,constant_interfacemethodref_info,constant_methodtype_info,constant_methodhandle_info,constant_dynamic_info和constant_invokedyanmic_info一共8种常量类型.
2.4核心阶段:初始化
其实就是为变量分配内存空间,并确定其初始值的过程。
初始化的内容:static修饰的变量、静态代码块、static中的new对象,main方法中的new对象,初始化类是如果父类没有初始化,必须先初始化父类。
2.5类加载器和双亲委派
类加载就是将磁盘上的class文件加载到内存中。
2.5.1启动类加载器 Bootstrap ClassLoader
负责加载我们机器上安装的java目录下的核心类,所以JVM启动就会委托启动类加载器去加载java安装目录下的“lib”目录中的核心类库。
2.5.2扩展类加载器Extension ClassLoader
Extension ClassLoader与Bootstrap ClassLoader 类似Extension ClassLoader加载的是“lib/ext”中的一些核心类。
2.2.3应用程序加载器 Application ClassLoader
Application ClassLoader负责加载”ClassPath”环境变量所指定的路径中的类。大致就是自己写的java代码加载到内存。
2.2.4自定义类加载器
自己定义的类加载器;继承ClassLoader进行自定义。
2.2.5双亲委派
当一个类加载器收到了类加载的请求的时候,它不会直接去加载指定的类,而是把这个请求委托给自己的父加载器去加载,每一个加载器都是如此。
- 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行。
- 2、如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器。
- 3、如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式。
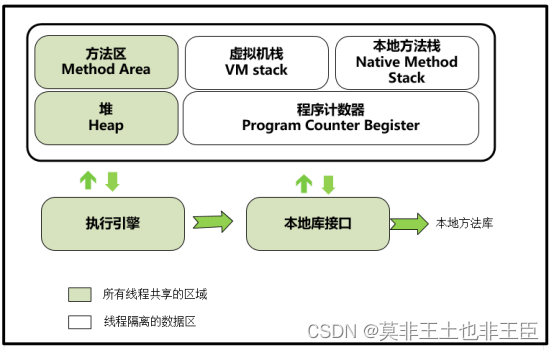
- JVM中有哪些内存区域,都是干嘛的?
Jvm在运行我们写好的代码时,它必须使用多块内存空间,不同的空间存放不同的数据,然后配合我们写的代码流程,让系统运行起来。
3.1存放类的方法区Metaspace 元空间
3.2程序计数器
Java代码编译成字节码.class后就会使用字节码执行引擎去执行.class字节码指令,程序计数器就是用来记录当前执行的字节码指令的位置。Java是多线程的所以一个线程会有一个程序计数器。
3.3 Java虚拟机栈
虚拟机栈也称为Java栈,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧(Stack Frame),每个线程都有自己的java虚拟机栈。
Java虚拟机栈属于线程私有,它的生命周期与线程相同(随线程而生,随线程而灭);
虚拟机栈说明了线程运行时的瞬时状态;每次方法调用,都会产生对应的栈帧;
栈帧包括局部变量表、操作数栈、动态链接、方法返回地址和一些附加信息;
每个方法被调用至执行完毕的过程,就对应这个栈帧在虚拟机栈中从入栈到出栈的完整过程;
栈的深度有限制;
举例:
栈帧情况如下:
Java初始换后虚拟机中的几块内存:
Java方法执行完毕就会从虚拟机栈中出栈,对象就没有指向了,也就是说没有一个变量指向java堆内存中的ReplicaManager对象了。
执行完毕后,replicaManager中loadReplicasFromDisk()方法出栈,对象指向消失。对象留在内存中占用有限的资源。
3.4 JVM垃圾回收
占用的对象需要JVM的垃圾回收机制。JVM本身运行这一个自运动的线程,只要启动一个进程,jvm就自带一个垃圾回收的线程,垃圾回收线程就会不断的检查JVM内存中的各个实例对象。
如果实例没有指向jvm垃圾回收机制就会定期清理掉释放资源。
3.4.1年轻代、老年代
举例如下:两个ReplicaManager的存活时间,方法内的ReplicaManager存活时间极短,每次循环执行后就会在极短的时间内被回收;Static修饰的ReplicaManager创建后会一直被静态变量引用会一直留在内存中不会被回收ReplicaManager会长期存在老年代里。
快速被回收的就是年轻代,一直在内存中的就是老年代;上图里的方法区,其实就是所谓的永久代,你可以认为永久代就是放一些类信息的。
3.4.2新生代,老年代回收时机
新生代内存几乎满了又有新生代需要创建此时就会发生内存回收,也称之为“Minor Gc”也叫“Young GC”。他会尝试把新生代没有引用的对象全部回收。
老年代回收时机:一是“Young GC”前,一通检测发现“Young GC”之后要进入老年代的对象太多了,老年代放不下,此时需要提前触发Full GC,然后在再带着进行“Young GC”,要不就是在“Young GC”后发现老年代放不下了,再进行Full GC
向上面被static修饰的ReplicaManager每次回收都没有回收掉他的对象就会加1(年龄),新生代的对象年龄超过10岁就会被认为是“老年人”就会被转移到老年代中。具体所多少岁进入老年代可以通过JVM参数“-XX:MaxTenuringThreshold”来设置,默认是15岁。还有一种情况就是Survivor里存在的对象内存大于Survivor的50%,大于的那部分会进入老年代;还有就是年轻代中回收完的对象大于Survivor内存,那么就直接放入老年代。
老年代的 Old GC 则分成初始标记、并发标记、重新标记和并发清理这四个阶段。其中并发标记阶段需要追踪老年代中中所有存活的对象,老年代中存活的对象比新生代多得多,用的时间也就更多。
在并发清理阶段也不是一次向回收一大片对象,一点点分散在各处的垃圾对象。清理完之后还需要整理一次内存碎片,将大量存活的对象移动到一起,此时还会「Stop the world」就更加慢了。
最后,并发清理阶段会有新的对象进入老年代,此时如果老年代的内存不足会引发了“Concurrent Mode Failure”问题,就会使用“Serial Old”垃圾回收器,“Stop the World”之后慢慢重新来一遍回收的过程。
- 系统如何设置JVM内存大小
-Xms: java堆内存大小
-Xmx: java堆内存最大大小
-Xmn: java堆内存中新生代大小,扣除新生代就是老年代的内存大小了
-XX:PermSize:永久代大小
-XX:MaxPermSize:永久代最大大小
-Xss:每个线程的栈内存大小
‐XX:SurvivorRatio:Eden区与Survivor区的大小比值
-XX:MaxTenuringThreshold 设置年轻代‘岁数’,默认是15
-XX:CMSInitiatingOccupancyFaction 可以设置老年代占用多少空间后进行垃圾回收,JDK1.6默认是92%,预留8%让对象能够进入老年代。
-XX:CMSFullGCsBeforeCompaction,这个意思是执行多少次Full GC之后再进行内存整理。默认是0。
案例1:日均1百万订单三、四台机器4核8G设置如下:内存4G,堆内存3G,堆内存新生代1.5G或者2G,每个线程1M,永久代256M。
‐Xms3072M ‐Xmx3072M ‐Xmn1536M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8
案例二:百万秒杀或大促,三台机器,整个内存使用4G,堆内存3G,新生代2G,老年代1G,永久代256M
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8
案例二:日均上亿大型数据计算分布式主要是从各种数据库取数据,服务器是4核8G的配置,JVM分配4G。新生代老年代都是1.5G。平均每分钟负责执行100次数据计算,每次1万条需要10秒的时间,每条平均包含20个字段平均每条数据大概在1Kb左右,1万条数据就对应了10MB的大小,按每分钟100次计算一分钟以后1000Mb,Eden区里就基本全满了。按照80%年轻代被回收,就是还剩余200MB,Survivor中本身就是100MB所以200MB就进入了老年代,系统运行7分钟后老年代就快满了,JVM最终大概8分钟一次FULL GC非常影响性能,解决方式是3G堆内存2G给新生代,1G给老年代。Survivor大概就有200MB内存了。
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8
4.1 JVM通用的优化方案(参数设置)
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5
4.2 大对象进入老年代
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M
4.3 指定回收器
新生代使用ParNew,老年代使用CMS
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
4.4 Concurrent Model Failure并发模型故障
并发故障出现是因为年轻代有200M的对象进入老年代,老年代没有足够的内存来存放200M的对象,此时就会导致立马进入STW状态,并切换CMS为Serial Old,直接进制程序运行,然后单线程进行老年代垃圾回收,回收掉后再让系统运行,此时优化为:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92
4.5 CMS垃圾回收之后内存碎片整理频率应该多高?
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:PermSize=256M ‐XX:MaxPermSize=256M ‐XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=5 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92 -XX:+UserCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0
4.6.垂直电商性能优化
-Xms4096M Xmx4096M -Xmn3072M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=265M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompation=0 -XX:+CMSParallelInitialMarkEnable -XX:+CMSScavengBeforeRemark
首先8G的机器上给JVM堆分配4G,年轻代分配3G尽量让年轻代大一些,CMSInitiatingOccupancyFaction当老年代达到92%后进行回收,CMSFullGCsBeforeCompation在执行多少次Full Gc后进行内存压缩。CMSParallelInitialMarkEnable在CMS初始标记阶段开启多线程并发执行,CMSScavengBeforeRemark在CMS的重新标记阶段之前进行一次Young GC
4.7 Full GC频繁原因
内存分配不合理,导致对象频繁进入老年代,进而引发FULL GC
内存泄露等问题,就是内存里驻留了大量的对象塞满了老年代,导致稍微有一些对象进入老年代就会FULL GC
永久代中类太多,触发FULL GC
使用System.gc()
- JVM中的算法
- 可达性分析算法
可达性分析算法就是对每个对象分析一下有谁在引用他,然后一层层往上判断,看看是否有一个GC Roots,GC Roots可以理解为对象的根节点,来引出他指向的下一个节点,再以下一个节点为起点引出下一个节点。
5.2复制算法
复制算法的核心就是,将原有的内存空间一分为二,每次只用其中的一块,在垃圾回收时,将正在使用的对象复制到另外一个内存空间中,然后将该内存空间清空,交换两个内存的角色,完成垃圾回收。
如果内存中的垃圾对象较多,需要复制的对象就较少,这种情况下适合使用该方式并且效率比较高,反之,则不适合。
优点:在垃圾对象多的情况下,效率较高。清理后,内存无碎片。
缺点:在垃圾对象少的情况下,不适用,如:老年代内存。分配的2块内存空间,在同一个时刻,只能使用一般,内存使用率较低。
复制算法一般情况下分配比例是8:1 ‐XX:SurvivorRatio=8
Jvm有个参数:-XX:PretenureSizeThreshold 可以设置成
5.3老年代标记清理算法
老年代使用的算法是标记整理算法,老年代垃圾回收算法速度至少比新生代速度慢10倍。如果频繁FullGc会导致系统性能被严重影响。
所谓的JVM调优,就是尽可能的让对象都在新生代中分配和回收,尽量别让太多对象就如老年代,避免频繁对老年代进行垃圾回收,同时给系统充足的内存大小,避免新生代频繁的进行垃圾回收。
- 垃圾回收器
JDK1.8 使用的是Parallel Scavenge 和 Parallel Old ,G1是用在内存cpu大的服务器上
Stop the word,在垃圾回收的时候系统会停止运行,等待垃圾回收完再启动运行。所有无论新生代GC还是老年代GC,都尽量不要让频率过高,也避免持续时间过长,避免影响系统正常运行,这也是再使用过程中最需要优化的地方。也是最大的痛点。
-
- Serial 和Serial old 新生代、老年代垃圾回收器
工作原理就是单线程运行,垃圾回收的时候会停止我们自己写的系统的工作线程,让我们的系统直接卡死不动,然后让他们垃圾回收,现在一般不用这两个。
-
- ParNew和CMS垃圾回收器
6.2.1 ParNew
ParNew现在一般都是用在新生代垃圾回收器,CMS是用在老年代垃圾回收器。他们都是多线程机制,性能更好,现在一般是线上系统标配。
以下是ParNew原理图:
使用 -XX:+UserParNewGC命令后JVM启动之后就会使用ParNew回收器了
使用 -XX:ParallelGCThreads 可以设置ParNew线程数。
6.2.2 CMS
因为Full GC比较长,长时间Stop the word 系统卡死时间过长很多,相应无法处理。所以CMS采用的方式是:垃圾回收现场和系统工作线程同时执行。
CMS垃圾回收分为4个阶段:初始标记、并发标记、重新标记、并发清理。
【初始标记阶】段会让系统的工作线程全部停止运行,进入STW(stop the word)状态,并标记出GC root直接引用对象。这个阶段运行很快。
【并发标记】并发标记阶段会继续对老年代中的对象进行GC Root追踪。这个阶段是最耗时、耗CPU的,因为是并发运行所以不会对系统运行造成影响。
【重新标记】并发标记完成后系统又会有许多对象需要标记回收,需要再次计入STW(stop the word)状态标记新的对象,这个阶段运行很快。
【并发清理】清理掉标记的对象,时间长,和系统并发运行并不影响。
问题1:并发处理阶段非常耗费CPU资源,CMS默认启动垃圾回收线程的数量是(CPU+3)- 4。如2核4G服务器消耗CPU就是 2+3-4=1
问题2:浮动垃圾(并发清理期间产生的垃圾)如何避免,保证CMS回收期间还有一定的空间让对象进入老年代。-XX:CMSInitiatingOccupancyFaction 可以设置老年代占用多少空间后进行垃圾回收,JDK1.6默认是92%,预留8%让对象能够进入老年代。
问题3:内存碎片问题,CMS标记清理完后会产生大量内存碎片,因为内存碎片产生实际上会导致更加频繁的Full GC,CMS有个参数是 -XX:UseCMSCompactAtFullCollenction 默认打开,意思是Full GC后再次STW ,对内存碎片进行整理,空出大片连续的内存空间。还有一个参数是 -XX:CMSFullGCsBeforeCompaction,这个意思是执行多少次Full GC之后再进行内存整理。默认是0。
-XX:CMSInitiatingOccupancyFaction 如果老年代可用内存大于历次新生代GC后进入老年代的对象平均大小,老年代使用的内存超过了这个参数指定比例,也会自动触发FULL GC
-
- G1
统一收集新生代和老年代,采用了更加优秀的算法和设计机制。G1垃圾回收器可以同时收回新生代和老年代的对象,一个人负责所有。
-
-
- 内存结构
把JAVA堆内存拆分为多个大小相等的Regin,新生代可能包含了某些Region,老年代可能包含某些Region。新生代和老年代是逻辑上的概念。
-
-
- 特点
G1很大的一个特点就是:可以设置垃圾回收器的预期停顿时间,G1是如何做到这一点的呢?他就必须追踪每个Region里的回收价值。他必须搞清楚每个Region里的对象有多少是垃圾,如果对这个Region进行垃圾回收,需要耗费多长时间,可以回收掉多少垃圾。
G1可以做到让你来设定垃圾回收对系统的影响,他自己通过把内存拆分为大量小Region,以及追踪每个Region中可以回收的对象大小和预估时间,最后在垃圾回收的时候尽量在你指定的时间内回收更多的垃圾。Region可能是新生代也可能是老年代。
-
-
- G1设置参数
-XX:InitiatingHeapOccupancyPercent 默认45%,意思是老年代占据堆内存45%的Region时,此时就会尝试触发老年代+年轻代一起回收的阶段。
-XX:MaxTenuringThreshold 设置G1默认年龄
-XX:MaxGCPauseMillis=time 制定垃圾回收停顿时间,默认是200ms
-XX:G1MixedGCCountTarget 可以设置在一次混合回收的过程中,最后一个阶段执行几次混合回收默认8次。
-XX:G1HeapWastePercent默认值是5%,意思是当混合回收的时候,一旦空闲出来的Region数量达到了堆内存的5%,此时就会立即停止混合回收。
-XX:G1MixedGCLiveThresholdPerent 默认85%,意思是确定回收Region的时候必须是存活的对象低于85%。
-
-
-
- 案例一
线上百万学生课程项目5台机器都是4核8G,每天集中在晚上3个小时的时间内,大约估算1秒600个请求,1秒大概产生3M左右的空间
-Xms4096M -Xmx4096M -Xss1M -XX:PermSize=256M -XX:MaxPermSize=256 -XX:+UseG1GC意思是JVM配置4G,每个java现成栈的内存为1MB,永久代256M。
-XX:G1NewSizePerent默认新生代初始占比为5%
-XX:G1MaxNewSizePerent默认新生代最大占比60%
-XX:MaxGCPauseMillis
-
-
- G1回收过程
【初始标记】这个过程需要进入STW状态,仅仅只是标记一下GC Root直接能引用的对象,这个过程速度很快
【并发标记】这个阶段允许程序运行,同时进行GC Root追踪,从GC Root 开始追踪所有存活的对象。标记耗时,和程序并发运行影响不大。
【最终标记】这个阶段会进入SWT,系统禁止运行,但会根据【并发标记】中记录的对象进行最终标记,最终标记那些是垃圾的对象,那些是存活的对象。
【混合回收】这个阶段会计算老年代中每个Region中对象存活的数量,存活对象的占比,还有执行垃圾回收的预期性能和效率。接着系统进入STW状态,然后全力以赴进行垃圾回收,此时会选择部分Region进行回收,因为必须让回收的停顿时间掌握在我们的控制范围内。老年代对堆内存占比达到45%的时候会触发【混合回收】
比如说老年代此时有1000个Region都满了,但是咱们规定的预期回收时间是200毫秒,那么通过计算得知,可能回收800个Region刚好需要200ms,那么就会回收800个Region。
[ Full GC 回收失败 ] 如果在进行Mixed回收的时候,老年代、年轻代都使用复制算法回收,把各个Region中对象拷贝到Region里去。此时万一出现在拷贝过程中发现没有空闲的Region可以承载自己存活的对象,就会发生Gc失败,一旦失败立马进入STW状态并且启动单线程回收来空出一批Region,过程极为缓慢。
-
- Parallel Scavenge和 Parallel Old
- Parallel Scavenge
Parallel Scavenge 收集齐是新生代收集齐,他也是使用的复制算法,又是并行的多线程收集齐,触发Parallel后STW 多线程处理垃圾。Parallel Scanveng更关注系统吞吐量。
吞吐量=运行用户代码的时间/(运行用户代码的时间+垃圾收集的时间)
-XX:MaxGCPauseMillis 控制最大垃圾收集停顿时间
-XX:GCTimeRatio 直接设置吞吐量的大小
-XX:+UserAdaptiveSziePolicy 新生代自适应调整
-
-
- Paralle Old
Paralle Old 收集齐是Paralle Scavenge 收集齐的老年代版本,使用多线程和标记整理算法进行垃圾回收,也是更加关注吞吐量。
-
- ZGC
ZGC收集器(Z Garbage Collector)由Oracle公司研发.2018年提交了JEP 333将ZGC提交给了OpenJDK,推动进入OpenJDK11的发布清单中。ZGC收集器是基于Region内存布局,暂时不设分代,使用读屏障,着色指针和内存多重映射等技术来实现并发的标记整理算法,以低延迟为目标的一款收集器。
- 与G1一样,ZGC也采用基于Region的堆内存布局
- ZGC的Region具有动态性
- 动态的创建和销毁
- 动态的Region容量大小
大小分类:
小型Region(Small Region),固定大小2MB,存放小于256KB的小对象
中型Region(Medium Region),固定大小32MB,存放大于256KB小于4MB的对象
大型Region(Large Region),大小不固定,可以动态变化,但必须是2MB的整数倍,用于放大于4MB的大对象,每个大型Region只会放一个大对象,所以实际容量可能会小于中型Region,最小到4MB。大型Region在ZGC实现中不会被重分配,因为复制一个大对象代价太高。
- JVM性能调优到底在优化什么?
系统因为内存分配、参数设置不合理导致你的对象频繁的进入老年代,然后频繁触发老年代GC,导致系统频繁卡顿甚至卡死。
案例一:百万级商家系统,
优化方式是更换大运存16核32G,使用G1
- 线上jvmGC情况查看工具
- jstat工具
Linux查看jar包运行PID :ps -ef | grep xxx.jar
Linux查看jar包gc情况:jstat -gc PID 1000 30 意思是每个1秒打印GC情况,打印30次。
S0C:这个是Form Survivor区的大小
S1C:这个是To Survivor区的大小
S0U:这个是Form Survivor区当前使用的内存大小
S1U:这个是To Survivor区当前使用的内存大小
EC:这是Eden区内存大小
EU:这个是Eden区当前使用的内存大小
OC:这是老年代的大小
OU:这是老年代当前使用的内存大小
MC:这是方法区(永久代、元数据区)的内存大小
MU:这是方法区(永久代、元数据区)当前使用的内存大小
YGC:这是系统运行迄今为止Young GC的次数
YGCT:Young GC的耗时
FGC:系统运行迄今为止FULL GC的此时
FGCT:FULL GC 耗时
FCT:GC总耗时
linux查看占用内存最多的程序
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
查看占用cpu最多的程序
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
-
- jmap和jhat摸清线上系统对象分部
Jmap -histo PID查看线程内存使用情况
-
- JAVA VisualVM
Window
-
- 阿里Arthas???
8.5MAT???
-
- Zabbix,open-Falcon???
- Eclipse Memory Analyzer???? 89
- 垃圾回收日志
- jvm优化到底怎么做?
系统因为内存分配、参数设置不合理导致你的对象频繁的进入老年代,然后频繁触发老年代GC,导致系统频繁卡顿甚至卡死。
10.1优化原则
尽可能大让每次YoungGC后存活对象远远小于Survivor区域,避免对象频繁进入老年代触发Full GC,最理想的状态是系统几乎不发生FULL GC老年代应该是稳定占用一定的空间,就是那些长期存活的躲过15次young Gc后升入老年带自然占用,然后就是几分钟发生young GC ,耗时几毫秒。
10.2 在压测之后合理调整线上参数
任何一个系统上线都要进行压测,此时在模拟线上压力的场景小,可以用jstat等工具进行JVM的运行内存模型,
Eden区的对象增长速率多块?
YoungGc 频率多高?
一次YoungGC多长耗时?
老年代增长速率多高?
FullGc频率多高?
一次FullGc的耗时?
尽可能的让系统仅有YoungGc。
10.3 线上系统监控优化
系统上线务必进行一定的监控,最高大上的做法就是Zabbix Open-Falcon之类的系统监控工具,频繁Full Gc 就要报警。
比较差的就是在机器上运行jstat,让其他监控写入一个文件,每天定时检查一下。
10.3.1 频繁Full Gc的几种常见原因
一、系统承载高并发请求,或者处理数量过大,导致Young GC很频繁,而每次YOUNG GC后存活对象太多,内存分配不合理,Survivor区域过小,导致对象频繁进入老年代,频繁FULL GC.
二、系统一次性加载过多数据进内存,搞出许多大对象出来,导致频繁有大对象进入老年代,必然频繁FULL gc
三、Metaspace(永久代)因为加载类过多触发FULL GC
四、误调用System.gc()触发FULL GC
常见的频繁FULL GC原因就是以上几种,从这几个角度分析即可,核心利器就是jstat。
Jstat分析发现FULL GC 原因是第一种,那么就合理分配内存,调大Survivor内存即可;如果jstat分析发现FULL GC 原因是第二种或者第三种,也就是老年代有大量对象无法回收掉,年轻代升入老年代的对象不多,那么就DUMP出来内存快照,然后MAT工具进行分析即可。
10.3.2 一个统一的JVM参数模板
为了简化JVM的参数设置和优化,建议各个公司和团队leader做一份JVM参数模板出来,设置一些常见参数即可。核心就是一些内存区域的分配,垃圾回收器的指定,CMS性能优化的一些参数,(比如压缩、并发、等等),包括禁止System.gc()打印GC日志等等。
10.3.3 JAVA程序员平时最常遇到的故障:系统OOM
内存溢出(oom)就是JVM内存就那么大,结果你拼命的塞东西,结果内存塞不下了,导致内存溢出。
10.3.3.1.Metaspace 区域是如何触发内存溢出的?
以下两个参数用来设置Metaspace的:
-XX:MetaspaceSize=512m
-XX:MaxMetaspaceSize=512m
Metaspace区域满了此时就会触发Full GC 连带这回收Metaspace里的类,那么什么样的类才会被回收呢?这个条件和苛刻包括不限于一下这些。比如类的加载器要先被回收;比如这个类的所有对象实例都要回收,所以Metaspace区域满了未必被回收。
Metaspace一般很少发生内存溢出,如果发生一般有连个原因:一、很多工程师没有给Metaspace设置大小,使用默认参数导致Metaspace区域才几十MB,对于大一点的系统因为他自己有很多类,又依赖很多JAR包,几十MB很容易满。二、很多人写系统会用cglib之类的技术动态生成的一些类,一旦代码没控制好导致类过多容易引发Metaspace内存溢出。
第一种情况一般设置512m就够。
10.3.3.2 线程栈内存溢出问题
什么情况下导致内存溢出?既然一个线程虚拟机栈的内存大小是有限的,比如1MB,假设你不停的让线程去调用各种方法,然后不停的把方法调用的栈帧压如栈中,就会占用这个线程栈的内存。大于这个内存就会导致内存溢出。
什么情况下回导致内存溢出呢?一般情况下是不会内存溢出的,如果走递归方法就不一定了。
10.3.3.3 堆内存溢出
发生堆内存溢出就一句话:有限的内存中放了过多的对象,而且大多数都是存活的,所以放入更多的对象是不可能了,因此引发内存溢出。
情况有两种:一、系统承载高并发,因为请求量过大导致大量对象都是存活的,所以继续放入心得对象就不行了;二、系统内存泄露问题,就是莫名奇妙弄了很多对象,结果对象都存活下来了,没有及时取消对他们的引用,导致触发GC.
10.3.3.4 .OOM内存快照
系统在OOM是设置两个参数就可以保存快照:
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/app/oom
第一个意思是OOM的时候自动dump内存快照出来,第二个意识是说那内存快照发到哪里去。
- JVM参数模板
《O基础开始带你成为JVM高手》中给出的jvm参数模板:
-Xms4096M -Xmx4096 -Xmn3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSParallelInitialMarkEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC
-XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/loacl/app/oom
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)