Ps:Tesseract识别英文和字母效果好
中文的话,虽然有训练数据也可以识别,但是效果不是很好
Tesseract的安装和使用:
1.首先用 pip 下载包
pip install tesseract
这时还没法直接用,还要下载一些东西
2.tesseract
我下载的是5.0 64位的版本
3.配置环境变量
把上面下载的Tesseract-ocr的目录添加到Path中
4.可以使用了
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open('1.png'))
print(text)
这个函数默认是识别英文和数字的
如果想要识别中文,需要额外下载训练数据
地址我挂这里了
chi_sim 是简体中文
chi_tra 是繁体中文
把其后缀为traineddata的文件拖到Tesseract-ocr目录下的tessdata文件夹里即可
然后,pyhon 里识别中文时,还要设置 lang 属性指定语言包(也就是我们之前下载的)
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open('1.png'),lang='chi_sim')
print(text)
最后,再介绍一下自己训练数据的方法
需要两个工具:
一个是 Java JDK (Java™ Platform, Standard Edition Development Kit)
拉到最下面就可以找到合适的版本了
安装完后,还要配置环境变量
新建一个变量
JAVA_HOME
路径是 JDK 的安装目录
另外一个是jTessBoxEditor
下载链接在这
安装好后,双击 jTessBoxEditor,jar 即可运行
接下来利用jTessBoxEditor开始训练
1.Tools – Merge TIFF
查看文件类型选到All Image Files
选择你要训练的图片
文件命名为:langyp.fontyp.exp0.tif
2.管理员权限cmd命令行进入上面tif的目录,用下面的指令生成box文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l chi_sim batch.nochop makebox
用记事本打开box文件,查看内容
如果不空,那就不用管了
如果是空的,则需要我们手动修改一下
3.box文件内容按下面的格式修改
【你要识别的字】 【字的x坐标】【字的y坐标】【宽度】【高度】
粤 60 17 140 125
ps:上面的数字你可以随便输,到时我们可以用 jTessBoxEditor 再进行修正的
然后,打开jTessBoxEditor
4.Box Editor–open 打开前面我们 merge 的 tif 文件
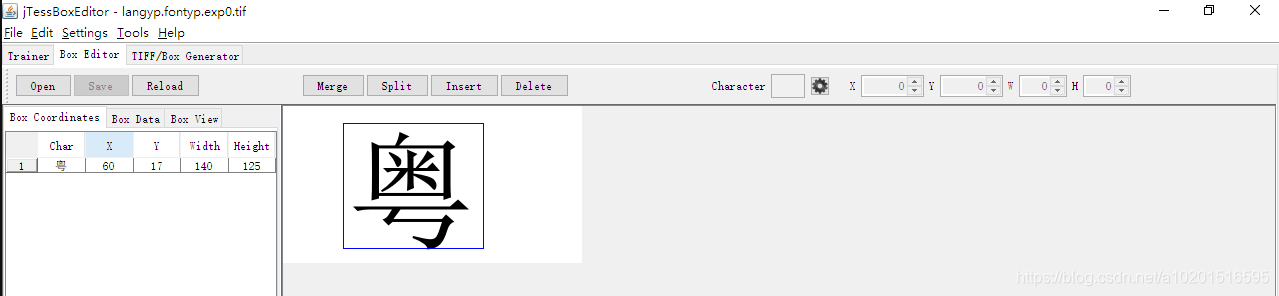
单击 粤 那一行可以在右边的 X Y W H 那修改数据 齿轮图标是确认修改
框好后 Save 则可以保存box文件
5. 生成 font_properties
新建一个空文件,文件名为 font_properties 不要后缀
文件内容:
fontyp 0 0 0 0 0
6.生成训练文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l eng -psm 7 nobatch box.train
7.生成字符集文件
unicharset_extractor langyp.fontyp.exp0.box
8.生成shape文件
shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
9、生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
10、生成字符正常化特征文件
cntraining langyp.fontyp.exp0.tr
11、更名
rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable
12、合并训练文件,生成fontyp.traineddata
combine_tessdata fontyp.
然后就可以得到自己训练的traineddata文件了
把他放到 tessdata 文件夹内就可以通过 lang 属性 使用了
文章最后
这 tesseract 识别真的不敢恭维。。。真的不好使
下面我推荐一个OCR的工具
cnocr
这个识别中文就特好使,网站里已经附带了使用教程
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)