基于AutoEncoder的生成对抗网络:VAE-GAN
- AutoEncoder
- VAE
- GAN
- VAE-GAN
- DCGAN
- InfoGAN
- ss-InfoGAN
- 论文链接
"
生成模型(Generative modeling)"已成为机器学习的一个较为广泛的领域。在图像这种流行数据上,每张图像都有数千数万的维度(像素点),
生成模型的工作就是通过某种方式来捕获像素之间的依赖,而具体捕获哪些依赖关系,就取决于我们想用模型来做些什么。
通常来讲,看起来像真实图像的数据点会以更高的概率被采纳,而看起来像随机噪声图像的数据点会以较低的概率被采纳。有时候这样的模型不一定有用,因为知道了一张图像后就不太可能合成不一样的图像。我们实际上更加需要的是和已经存在的图像类似,但又不完全相同的图像,拿来扩充数据,这样的图像原本是不存在的。
GAN和VAE都是效果比较好的生成模型,但是VAE希望通过一种显式的方法找到一个概率密度,并通过最小化对数似函数的下限来得到最优解;GAN则是使用对抗的方式来寻找一种平衡,不需要给定显式的概率密度函数。
AutoEncoder
VAE(变分自编码器)是基于AE(自编码器)提出的,所以要先了解AE。Encoder将输入X映射到一个隐状态Z,Decoder将Z再映射回X’,AE的训练目标就是使得输入X和输出X’尽可能相似,同时AE是完全确定的,AE的输入直接决定了生成结果。在AE中,因为Encoder将输入X映射为更低维度的表征,这些表征通常被认为是低噪声且富有信息的,所以Z可以被称为特征向量。
VAE
在VAE中,我们为了生成新的样本,需要建模数据的真实分布
p
(
x
)
p(x)
p(x)。VAE避开了直接建模
p
(
x
)
p(x)
p(x)这个难题,它实际构建了一种从一个给定隐变量的先验分布
p
(
z
)
p(z)
p(z)到真实数据的分布
p
(
x
)
p(x)
p(x)的转换。
为此,我们首先可以用Decoder建模
p
(
x
∣
z
)
p(x|z)
p(x∣z)。那么当模型训练完毕后,通过在
p
(
z
)
p(z)
p(z)上采样再将结果输入Decoder,就能生成新样本了。具体来说,VAE建模的
p
(
x
)
p(x)
p(x)公式如下:
p
(
x
)
=
∫
p
(
z
)
p
(
x
∣
z
)
d
z
p(x)=\int p(z)p(x|z)dz
p(x)=∫p(z)p(x∣z)dz通过建模对数据的真实分布
p
(
x
)
p(x)
p(x)进行近似。所以VAE最终生成的样本并不会和原始样本一模一样,只会是相似但不相同。
在VAE中,Decoder可以看作生成模型,它可以将低维空间的表示恢复为高维空间表示。Encoder的作用是抓住一些关键的特征和变量之间的依赖,使得采样的特征向量z有意义。
AE更多使用的是它的Encoder,用于做分类任务,VAE更多使用的是它的Decoder,用于做生成任务。
GAN
生成对抗网络包含两个模型,一个模型G(生成器)用来学习真实样本的数据分布,产生和其类似的样本。另一个模型D(判别器)用来判断样本是否为真实样本。交替训练D和G,最终的理想结果是G完全学到了真实样本的分布,D已经无法判断样本是否为真实样本,G产生的样本在D的概率为0.5。整体的优化可以表示为:
min
G
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
log
D
(
x
)
]
+
E
z
∼
p
z
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\min_G\max_DV(D,G)=\mathbb{E}_{x\sim p_{data}(x)}[\log D(x)]+\mathbb{E}_{z\sim p_z(z)}[\log (1-D(G(z)))]
GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
训练过程中,对于生成器来说,就是要使得
D
(
G
(
z
)
)
D(G(z))
D(G(z))尽可能大(伪造的样本像真的),即最小化
l
o
g
(
1
−
D
(
G
(
z
)
)
)
log(1-D(G(z)))
log(1−D(G(z)))。对于判别器,就是对于输入的真实样本,使得判别概率尽可能大,对于假样本,概率尽可能小,即判别能力强。
VAE-GAN
了解了VAE和GAN之后,会很自然想到将它们进行结合,于是VAE-GAN就出现了。把VAE作为GAN的生成器,这样的网络既具有VAE的可控制图片生成的特性,又能够拥有GAN优良生成图片的性能。
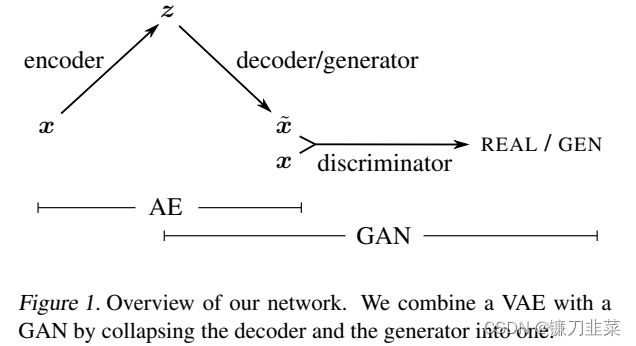
这个网络前半部分就是一个完整的VAE,后面是一个GAN,其中VAE和GAN共享一个Decoder。
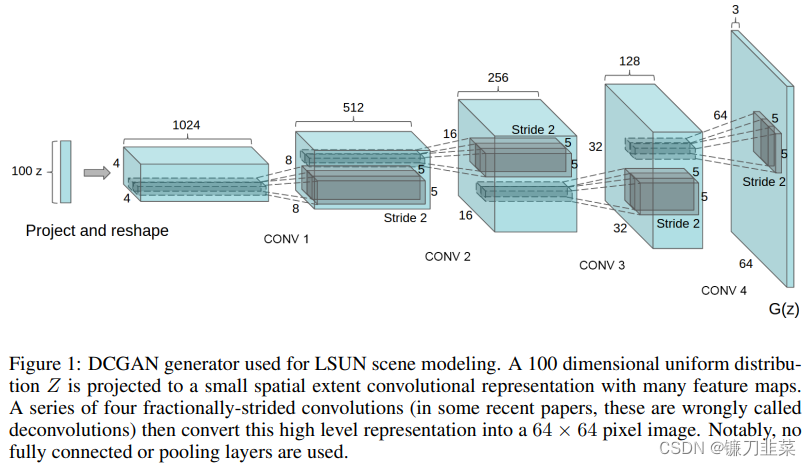
DCGAN
与最原始的GAN相比,DCGAN的改进地方在于将生成器的网络用卷积网络替换掉,这样生成图片的清晰度会提高。在下图中,100维的随机噪声通过4次fractional-strided卷积后生成64×64的图像,即生成器的最终输出。
上图为DCGAN所生成的cifar10的样本。
InfoGAN
原始的GAN和DCGAN都属于无监督方法,该方法不使用任何的标签信息,换种说法就是我们无法人为控制生成图片的种类。因此,无监督方法需要对隐空间进行解耦得到有意义的特征表示。
InfoGAN 对把输入噪声分解为隐变量
z
z
z和条件变量
c
c
c(训练时,条件变量
c
c
c从均匀分布采样而来),二者被一起送入生成器。在训练过程中通过最大化
c
c
c和
G
(
z
,
c
)
G(z,c)
G(z,c)的互信息
I
(
c
;
G
(
z
,
c
)
)
I(c;G(z,c))
I(c;G(z,c))以实现变量解耦(
I
(
c
;
G
(
z
,
c
)
)
I(c;G(z,c))
I(c;G(z,c))的互信息表示
c
c
c里面关于
G
(
z
,
c
)
G(z,c)
G(z,c)的信息有多少,如果最大化互信息
I
(
c
;
G
(
z
,
c
)
)
I(c;G(z,c))
I(c;G(z,c)),也就是最大化生成结果和条件变量
c
c
c的关联性)。
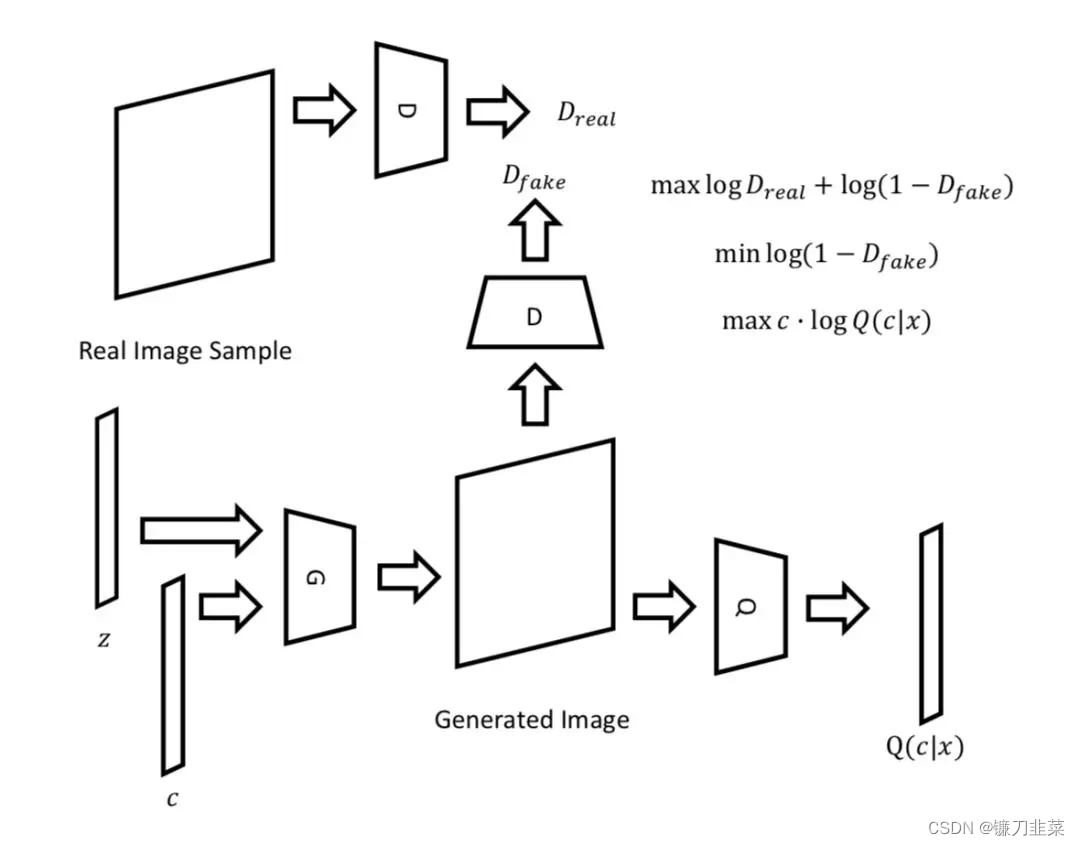
上图中中 G-D 的组合即原始的 GAN,而G-Q的组合可以看做一个“自动编码机”,而 G-Q 不同于“自动编码机”的地方在于,后者的信息流是:复杂-简单-复杂,前者的信息流是:简单(输入的随机数)- 复杂(手写数字图片)-简单(手写数字图片所代表的数字)。
另外,换一个视角,从把GAN 的 D 当做一个复杂的损失函数来看,infoGAN 的 D+Q 则是一个更复杂的损失函数,在分别真假的基础上、增加了识别数据特征的能力。
具体的 Pytorch 实现上,D 和 Q 共享部分参数,D 使用二值交叉熵指导其辨别真假,G 使用softmax 指导其识别图片所代表的数字,使用 log_gaussian 函数指导其辨别连续的特征如笔画粗细和倾斜角度。
ss-InfoGAN
为了解决无法控制c的问题,ss-InfoGAN出现了,该方法采用半监督的学习方法,输入少量带标签的真实样本,让判别器能够学习到真实样本的一些标签信息,使得生成出来的样本也能对应标签。
论文摘要:在本文中,我们提出了一个新的半监督GAN体系结构(SS-INFOGAN),用于图像合成,该图像合成,该构成从少数标签中利用信息(少于0.22%,最多的数据集的10%)来学习语义上有意义且可控制的数据表示形式。潜在变量对应于标签类别。与完全无监督的设置相比,该体系结构建立在最大化生成对抗网络(INFOGAN)(INFOGAN)的信息基础上,并显示出可以学习连续和分类代码,并获得了更高的合成样本质量。此外,我们表明使用少量标记的数据加速训练收敛。该体系结构保持了无可用标签的潜在变量的能力。最后,我们贡献了一个信息理论推理,介绍了如何引入半统治会增加合成数据和真实数据之间的共同信息。
论文链接
- Autoencoding beyond pixels using a learned similarity metric
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets
- Guiding InfoGAN with Semi-Supervision
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)