论文地址:《ContourNet: Taking a Further Step toward Accurate Arbitrary-shaped Scene Text Detection》
github地址:https://github.com/wangyuxin87/ContourNet
该论文发表与CVPR2020。
文章认为现在自然场景主要存在两个挑战:1. 误检问题 2. 自然场景中文本尺度变化较大使得网络难以学习。
为了解决上述的两个问题,文章提出了*Local Orthogonal Texture-aware Module (LOTM)*来缓解误检问题,Adaptive Region Proposal Network(Adaptive-RPN)来解决文本尺度问题。
一、网络结构
ContourNet整体结构如下图所示。可以看出网络主要由三部分,Adaptive Region Proposal Network (Adaptive-RPN), Local Orthogonal Texture-aware Module (LOTM) and Point Re-scoring Algorithm。
整体来看采用的是2-stage的方式。图片先经过backbone+FPN结构的网络,将FPN输出的feature送入Aaptive RPN获取proposals,然后通过Deformable RoI pooling将feature map对应区域特征提取送个LOTM模型,最终经过Point Re-scoring Algorithm输出文本的检测区域。
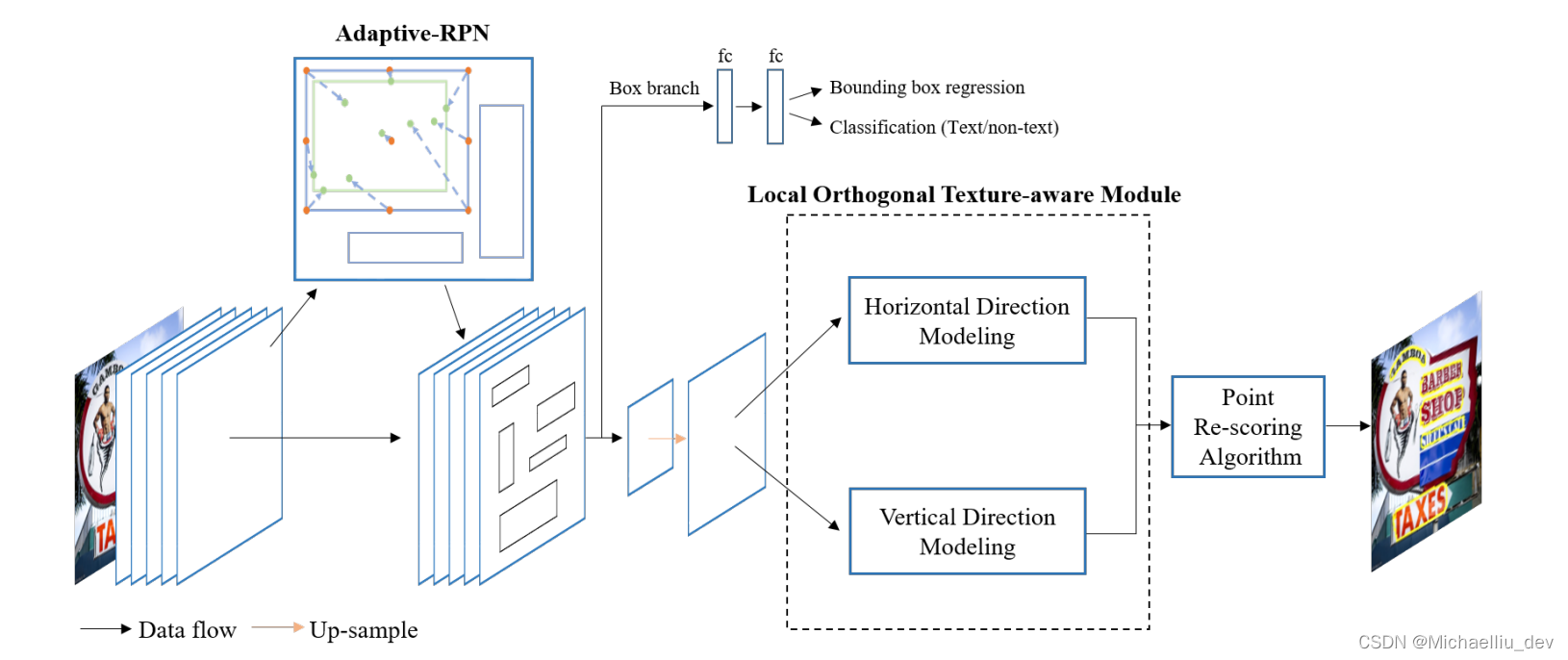
1.1 Adaptive-RPN
RPN是2-stage物体检测中常用的结构,通常是在anchor
B
c
=
{
x
c
,
y
c
,
w
c
,
h
c
}
B_c=\{x_c, y_c, w_c, h_c\}
Bc={xc,yc,wc,hc}基础上回归获得预测的proposal
B
t
=
{
x
c
+
w
c
Δ
x
c
,
y
c
+
h
c
Δ
y
c
,
w
c
e
Δ
w
c
,
h
c
e
Δ
h
c
}
B_t=\{x_c+w_c\Delta{x_c}, y_c+h_c\Delta{y_c}, w_ce^{\Delta{w_c}}, h_ce^{\Delta{h_c}}\}
Bt={xc+wcΔxc,yc+hcΔyc,wceΔwc,hceΔhc}。通常训练时采用smooth l1 loss,但是这种loss在大小不同的gt框情况下,对于相同IoU的检测框loss值不一样,所以对于优化检测框IoU来说是不太合适的。
为了解决上述问题,文章提出Adaptive-RPN,不同于RPN回归
{
Δ
x
,
Δ
y
,
Δ
w
,
Δ
h
}
\{\Delta{x}, \Delta{y}, \Delta{w}, \Delta{h}\}
{Δx,Δy,Δw,Δh}。
首先预定义一些点
P
=
{
(
x
1
,
y
l
)
}
l
=
1
n
P=\{(x_1, y_l)\}^n_{l=1}
P={(x1,yl)}l=1n(这n个点中包含了1个中心点和n-1个边界点),然后回归获得新的点
R
=
{
x
r
,
y
r
}
r
=
1
n
=
{
(
x
l
+
w
c
Δ
x
l
,
y
l
+
h
c
Δ
y
l
)
}
l
=
1
n
R=\{x_r, y_r\}^n_{r=1}=\{(x_l+w_c\Delta{x_l}, y_l+h_c\Delta{y_l})\}^n_{l=1}
R={xr,yr}r=1n={(xl+wcΔxl,yl+hcΔyl)}l=1n。
上式中,
{
Δ
x
l
,
Δ
y
l
}
l
=
1
n
\{\Delta{x_l}, \Delta{y_l}\}^n_{l=1}
{Δxl,Δyl}l=1n是预测的对应的点offsets,
w
c
w_c
wc和
h
c
h_c
hc为对应anchor框的宽和高。
获得回归后的点后,利用max-min函数求得对应的proposal框,公式如下:
P
r
o
p
o
s
a
l
=
{
x
t
l
,
y
t
l
,
x
r
b
,
y
r
b
}
=
{
m
i
n
{
x
r
}
r
=
1
n
,
m
i
n
{
y
r
}
r
=
1
n
,
m
a
x
{
x
r
}
r
=
1
n
,
m
a
x
{
y
r
}
r
=
1
n
}
Proposal=\{x_{tl}, y_{tl}, x_{rb}, y_{rb}\}\\=\{min\{x_r\}^n_{r=1}, min\{y_r\}^n_{r=1}, max\{x_r\}^n_{r=1}, max\{y_r\}^n_{r=1}\}
Proposal={xtl,ytl,xrb,yrb}={min{xr}r=1n,min{yr}r=1n,max{xr}r=1n,max{yr}r=1n}
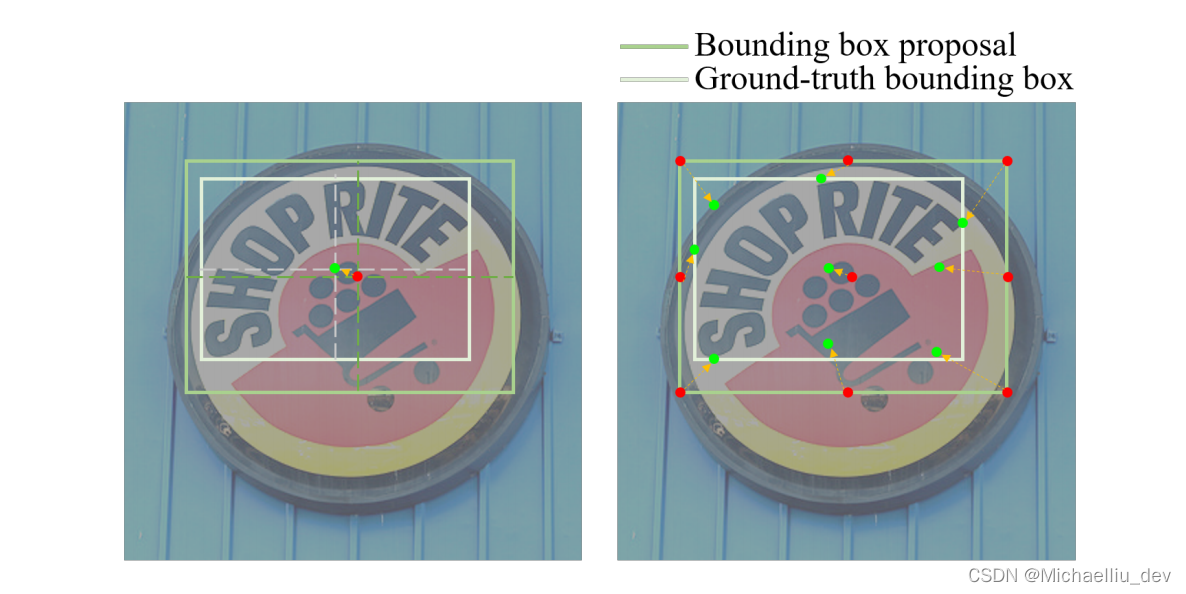
需要特别说明的是,n点中包含的中心点
{
x
′
,
y
′
}
\{x', y'\}
{x′,y′}也是为了限制框边界的,例如
如果
x
t
l
>
x
′
,
那么
x
t
l
=
x
′
。
如果x_{tl} > x', 那么x_{tl}=x'。
如果xtl>x′,那么xtl=x′。
RPN回归方式和Adaptive-RPN回归方式示意图如下:
1.2 LOTM
该模块的灵感来源于传统的边缘检测算法,例如Sobel算子。LOTM模块如下所示:
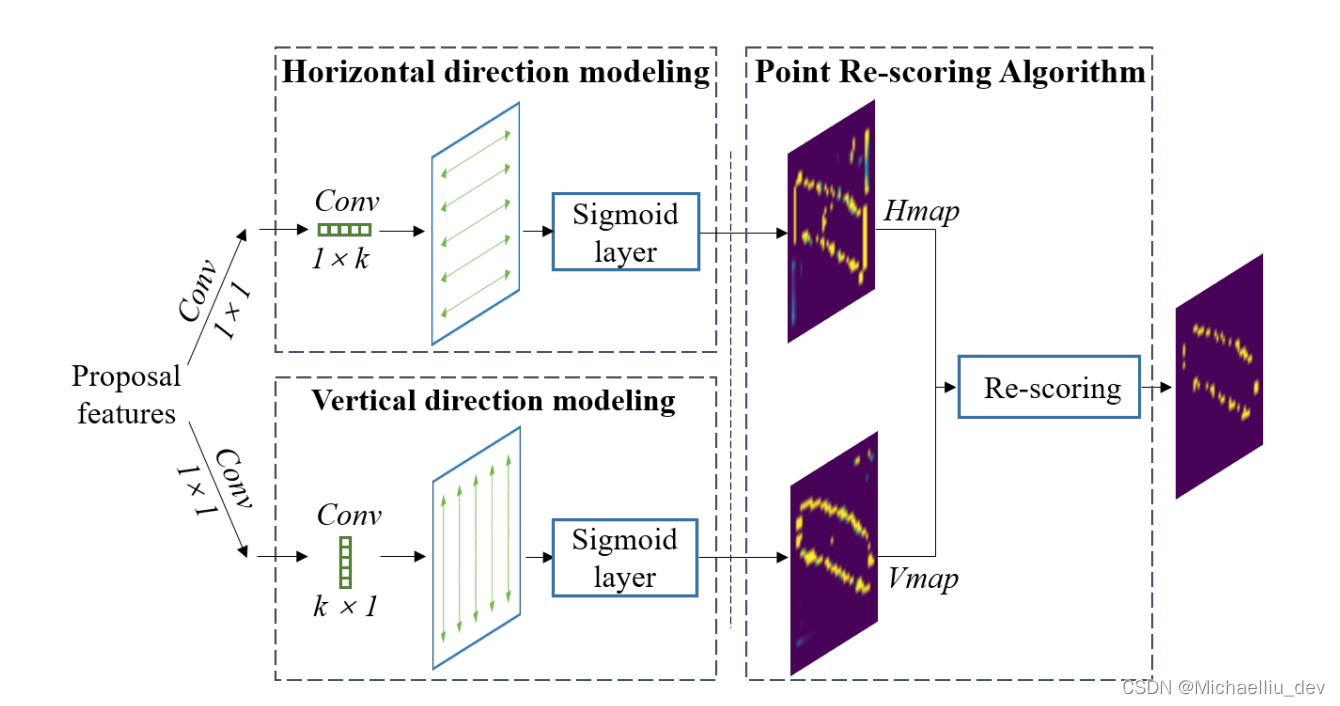
LOTM由两个平行的支路组成。图中上路分支采用
1
×
k
1\times k
1×k的卷积核对文本水平方向的信息进行提取,相同的下路分支采用
k
×
1
k\times 1
k×1的卷积核对文本竖直方向的信息进行提取。k为超参。两路分支的卷积结果分别经过sigmoid层将feature转为值在[0,1]之间的heatmaps,这两个heatmaps分别表示文字轮廓两个正交方向的响应信息。
1.4 Point Re-scoring Algorithm
该模块就是为了将LOTM输出的两个方向的响应信息融合出最终的轮廓信息。该模型的伪代码如下所示:

伪代码中的
N
M
S
H
NMS_H
NMSH和
N
M
S
V
NMS_V
NMSV就是采用类似
1
×
k
1\times k
1×k和
k
×
1
k\times 1
k×1的核进行maxpooling操作。k文章采用3,
θ
\theta
θ这里设置为0.5。
经过这一步后就获得了文本最终的文本轮廓。
二、Loss计算
网络采用的Loss如下式所示:
L
=
L
A
r
p
n
c
l
s
+
λ
A
r
e
g
L
A
r
p
n
r
e
g
+
λ
H
c
p
L
H
c
p
+
λ
V
c
p
L
V
c
p
+
λ
b
o
x
c
l
s
L
b
o
x
c
l
s
+
λ
b
o
x
r
e
g
L
b
o
x
r
e
g
L=L_{Arpn_{cls}}+\lambda_{Areg}L_{Arpn_{reg}}+\lambda_{Hcp}L_{Hcp}+\lambda_{Vcp}L_{Vcp}+\lambda_{box_{cls}}L_{box_{cls}}+\lambda_{box_{reg}}L_{box_{reg}}
L=LArpncls+λAregLArpnreg+λHcpLHcp+λVcpLVcp+λboxclsLboxcls+λboxregLboxreg
上式中
L
A
r
p
n
c
l
s
,
L
A
r
p
n
r
e
g
,
L
H
c
p
,
L
V
c
p
,
L
b
o
x
c
l
s
,
L
b
o
x
r
e
g
L_{Arpn_{cls}}, L_{Arpn_{reg}}, L_{Hcp},L_{Vcp}, L_{box_{cls}}, L_{box_{reg}}
LArpncls,LArpnreg,LHcp,LVcp,Lboxcls,Lboxreg分别表示Adaptive-RPN 分类loss, Adaptive-RPN 回归loss, 水平方向的contour point loss, 竖直方向的contour point loss, bounding box 分类loss, bounding box回归loss。对应的
λ
\lambda
λ值除
λ
A
r
e
g
\lambda_{Areg}
λAreg外作为balance的超参,其余都是1.
2.1 Adaptive-RPN Loss
上面讲过Adaptive-RPN为了缓解框大小带来的问题,所以Adaptive-RPN回归Loss采用IoU loss:
L
A
r
p
n
r
e
g
=
−
l
o
g
I
n
t
e
r
s
e
c
t
i
o
n
+
1
U
n
i
o
n
+
1
L_{Arpn_{reg}}=-log\frac{Intersection + 1}{Union +1}
LArpnreg=−logUnion+1Intersection+1
上式中Intersection和Union表示gt和预测proposal之间的交集和并集。
Adaptive-RPN分类Loss采用cross-entropy loss。
2.2 LOTM Loss
为了解决正负样本不均衡的问题,LOTM模型的loss监督采用class-balanced cross-entropy loss,如下所示:
L
H
c
p
=
L
V
c
p
=
L
c
p
=
−
N
n
e
g
N
y
i
l
o
g
p
i
−
N
p
o
s
N
(
1
−
y
i
)
l
o
g
(
1
−
p
i
)
L_{Hcp}=L_{Vcp}=L_{cp}=-\frac{N_{neg}}{N}y_ilogp_i-\frac{N_{pos}}{N}(1-y_i)log(1-p_i)
LHcp=LVcp=Lcp=−NNnegyilogpi−NNpos(1−yi)log(1−pi)
这里
y
i
y_i
yi和
p
i
p_i
pi表示gt和预测的像素值。
N
n
e
g
N_{neg}
Nneg和
N
p
o
s
N_{pos}
Npos分别表示负样本和正样本的个数,N表示总样本数。
2.3 bounding box Loss
Bounding box loss同faster rcnn。
三、gt
所有的训练数据集都是采用多边形的标注方式,多边形边缘的点都是用于训练的轮廓点。(使用scipy包中的distance_transform_edit函数获取)
Adaptive-RPN的gt获取采用预测时类似的方式max-min获取得到。
文章的原理基本是这样的,具体实验可以查看原文。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)