参考博客
VMware虚拟机上不能使用CUDA
Linux(Ubuntu)系统查看显卡型号
一、综述
虚拟机的显卡是虚拟的,不能使用CUDA
虚拟机上装Nvidia显卡驱动会导致其他驱动全都不能用,所以不能在虚拟机上装N卡驱动,即无法使用GPU
二、虚拟机中查看显卡

1. 查看显卡型号
>> lspci | grep -i vga
lspci 查找目前主机的硬件配备
grep -i 进行大小写无关的搜索
虚拟机中的虚拟显卡
00:0f.0 VGA compatible controller: VMware SVGA II Adapter
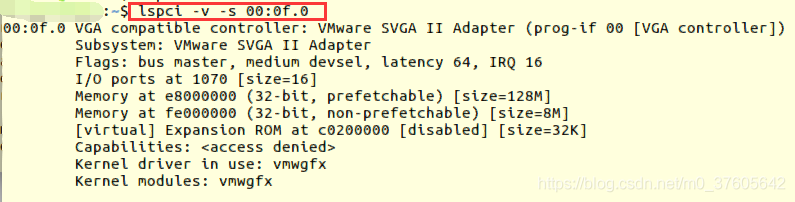
2. 查看详细的信息
>> lspci -v -s 00:0f.0
按照十六进制数字代码找到相应的显卡型号 The PCI ID Repository



如果知道是NVIDIA显卡,可直接用命令 nvidia-smi 即可显示具体显卡型号

>> nvidia-smi
nvidia-smi:未找到命令 # 没有安装Nvidia显卡驱动
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)