目录
思路
配置master服务器
配置slave服务器
启动
运行example
常见报错
多次初始化导致master和slave的clusterID的不一致
INFO mapreduce.Job: Running job: job_1647679522593_0001
Got exception: java.net.ConnectException
其他报错
小好奇
思路
目标:一台master,两台slave。
新建两台虚拟机,一台master一台slave,先配置master ssh登录slave,之后在master上配置好jdk和Hadoop后直接通过scp传送到slave1,然后通过slave1虚拟机克隆产生slave2。
配置master服务器
1.设置SSH免密码登录
具体教程可见
ssh免密登录远程服务器
2.安装JDK
下载“jdk-8u11-linux-x64.tar.gz”,放到/home/java目录下,解压
tar -zxvf jdk-8u11-linux-x64.tar.gz
在/etc/profile文件后面添加
export JAVA_HOME=/home/java/jdk1.8.0_11
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin
一定记得输入命令
source /etc/profile
测试是否成功安装
java -version
3.安装hadoop-2.6.5
下载“hadoop-2.6.5.tar.gz”,放到/home/hadoop目录下,解压
tar -xzvf hadoop-2.6.5.tar.gz
在/home/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
4.添加java和hadoop环境变量
打开/root下的.bashrc文件,添加三行
export HADOOP_HOME=/home/hadoop/hadoop-2.6.5
export JAVA_HOME=/home/java/jdk1.8.0_11
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
这里注意三点:
一是要在对应用户下修改对应用户的.bashrc。由于我是在root用户下操作,修改的是root的.bashrc,所以我在普通用户下输入hadoop会显示command not found。
二是PATH要在最下面,否则引用不了HADOOP_HOME和JAVA_HOME。
三是记得
source /root/.bashrc
5.修改配置文件
配置/home/hadoop/hadoop-2.6.5/etc/hadoop目录下的core-site.xml
需要修改第四行ip
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.79.128:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的hdfs-site.xml
需要修改倒数第七行ip
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.79.128:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的mapred-site.xml
修改两行value的ip
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.79.128:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.79.128:19888</value>
</property>
</configuration>
配置/home/hadoop/hadoop-2.7.0/etc/hadoop目录下的yarn-site.xml
修改好多ip
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.79.128:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.79.128:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.79.128:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.79.128:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.79.128:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6144</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
配置/home/hadoop/hadoop-2.6.5/etc/hadoop目录下hadoop-env.sh、yarn-env.sh
export JAVA_HOME=/home/java/jdk1.8.0_11
配置/home/hadoop/hadoop-2.6.5/etc/hadoop目录下的slaves,删除默认的localhost,增加2行
192.168.79.138
192.168.79.143
(这一步要等到创建slave2后,知道slave2的ip再回来填,到时候记得就好)
6.将jdk和hadoop传给slave
scp -r /home/java 192.168.79.138:/home/
scp -r /home/hadoop 192.168.79.138:/home/
(如果上一步ssh配置好的话,这一步是不需要密码的)
配置slave服务器
1.配置slave1
java配置同master服务器,只需要修改/etc/profile并且source一下就可以了。
hadoop配置传送过来就好了,不要修改hadoop下的配置文件,master和slave的这些配置文件需要一毛一样。
添加java和hadoop环境变量,同master,可参考master的配置。
2.克隆产生slave2
选择 创建完整克隆
(如果之前没有额外的虚拟机的话,选择克隆会比新建一个虚拟机快一些,而且不会出错。如果之前有的话,通过scp传送java和Hadoop也很快)
试一下用master能不能ssh登录,再试一下java -version,如果都可以的话说明克隆成功了
3.配置master上/home/hadoop/hadoop-2.6.5/etc/hadoop目录下的slaves,把之前那一步做完
启动
1.启动
在master上,输入
hdfs namenode -format
这里一定要注意,初始化一次就够了,不要多次初始化,重启hdfs的时候不需要再次初始化,如果已经多次初始化,参考常见报错第一个。
一般提示Exiting with status 0表示成功
start-all.sh
2.查看
在master和slave上分别输入jps,显示已运行的java程序
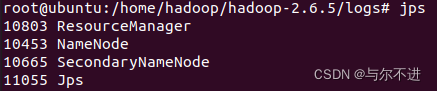
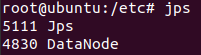
也可以用浏览器打开管理页面http://192.168.79.128:50070/ ,查看节点信息
打开http://192.168.79.128:8088/ ,查看节点运行情况
3.关闭所有节点
stop-all.sh
运行example
hadoop jar /home/hadoop/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 10 10
没有报错并正确显示计算结果,表明运行成功

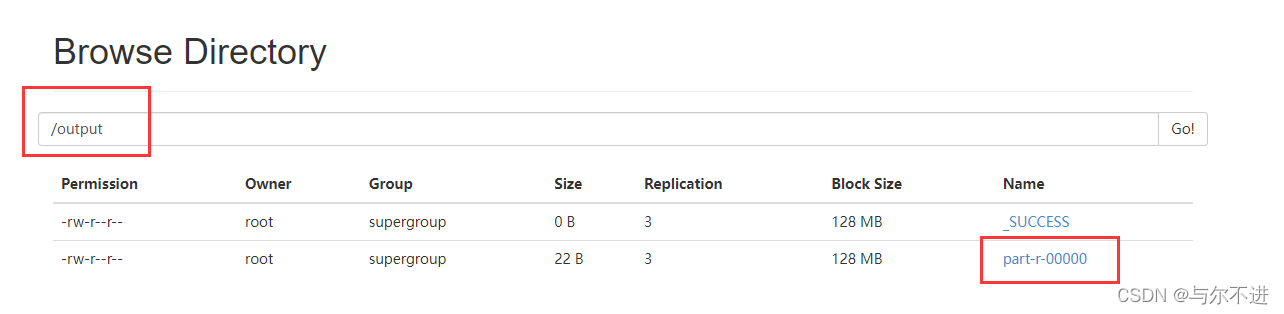
先创建input文件夹,再上传文件至input目录下,输入以下命令,统计结果会放到output里
hadoop jar /home/hadoop/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
可在管理页面找到output,下载统计结果

常见报错
多次初始化导致master和slave的clusterID的不一致
使得slave节点无法启动datanode。
如果已经多次初始化,按如下步骤恢复。
首先
stop-all.sh
再删除core-site.xml和hdfs-site.xml指定路径下所有的文件和文件夹,但一定要保留他们指定的文件夹。
比如我最后的结果是这样的
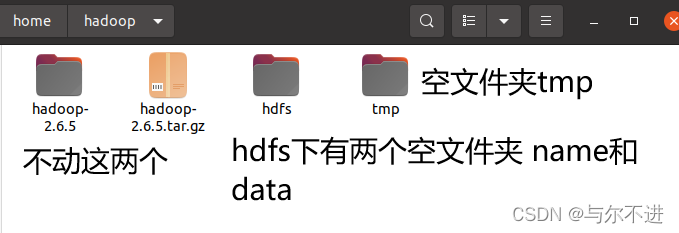
所有slave中data下的文件和tmp下的文件都要删除,最后状态应该和master一样。
现在可以初始化了
hdfs namenode -format
在master上打开/home/hadoop/hdfs/name/current/VERSION,再在slave上打开/home/hadoop/hdfs/data/current/VERSION,如果发现两者clusterID一致的话,说明初始化成功了。
以后记得不要多次初始化了噢~
INFO mapreduce.Job: Running job: job_1647679522593_0001
运行example时卡在这行不动了,可参考
hadoop yarn方式执行mapreducejob一致peding,卡住不动_如何在5年薪百万的博客-CSDN博客
Hadoop运行任务时一直卡在: INFO mapreduce.Job: Running job_Oooover的博客-CSDN博客_hadoop卡在runningjob
但我当时的问题是hostname配置不对,跟第二个报错是一样的,这里解释了问题原因
Hadoop java Got exception: java.net.ConnectException
Got exception: java.net.ConnectException
根本原因是hosts和hostname配置不对,修改一下配置再重启虚拟机就好了。记得master和slave都要修改设置。
以下是我的配置:
/etc/hosts(slave同master)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#127.0.1.1 ubuntu
192.168.79.128 meta1
192.168.79.138 meta2
192.168.79.143 meta3
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback localhost localhost.localdomain localhost4 localhost4.localdomain4
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
/etc/hostname,每个服务器写自己的名称就好,修改之后重启虚拟机才生效,然后输入命令查看是否生效。
hostname
我的报错和这里的几乎一样,他的解决方法很有效,可参考。
Hadoop java Got exception: java.net.ConnectException
其他报错
参考这里。
Linux报错集锦
小好奇
上传文件的时候,究竟上传到哪里了呢~
用find查找整个系统,发现找不到,最后在从节点的这个目录下找到文件
/home/hadoop/dfs/data/current/BP-1615665570-127.0.1.1-1647576217136/current/finalized/subdir0/subdir0
原文链接(会有更新)
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.A new tool that blends your everyday work apps into one. It's the all-in-one workspace for you and your team https://thrilling-coffee-afc.notion.site/hadoop-cb4c19c3494d4d22af3ba74c166a5826
https://thrilling-coffee-afc.notion.site/hadoop-cb4c19c3494d4d22af3ba74c166a5826
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)