5.比赛中的CV算法
讲了这么多,视觉组的重头戏——算法终于来了。
在大部分时候我们都不需要设计底层的算法,而是直接调用封装好的API,设计更具体的应用于特定问题的算法。当然,有必要了解一下造轮子(底层算法的实现)的过程,这能够让我们深入理解算法内部的构造,从而更好地使用这些算法,出错的时候也能更快定位问题。如果只是调用API而不了解原理,那么只是简单的缝合+搭积木,对于提升自我的思考能力和逻辑思维没有任何帮助。应当要有“使用科技的黑箱会使我惶惶不安” 的觉悟。
我们最常用的OpenCV和一些神经网络模型都是开源的,它们都有优秀的注释和说明文档,尤其是OpenCV的Documentation和Tutorial十分详细,全是使用doxygen生成的标准文档系统。通过阅读这些材料,很快就能上手。在GitHub社区你可以提出Issues,和其他开发者一起讨论问题。
5.0.CV的常识性概念
计算机视觉是让机器拥有视觉同时让机器能够理解所看到的东西并对其进行一定的分析和处理的研究领域。目前主要分为图像识别、图像分割、图像生成、目标检测、目标追踪、视频处理 等,因为有着共通的根基和大量知识交叠,其实很难将他们分得太开。此部分就主要介绍最基本的概念:
-
典型的任务
-
图像识别:给定一张图片,通过算法确定这张图像的分类,又叫图像分类。比如提供一张含有猫的图片给计算机,计算机应当认出:这张图里有一只猫咪。图像识别的输出是整张图片的标记,是图片(若把一张宽高分别为w、h的图片看成一个长度为w*h的向量,则图像识别是找到一个从w*h的空间到图像分类标记的映射(函数)。
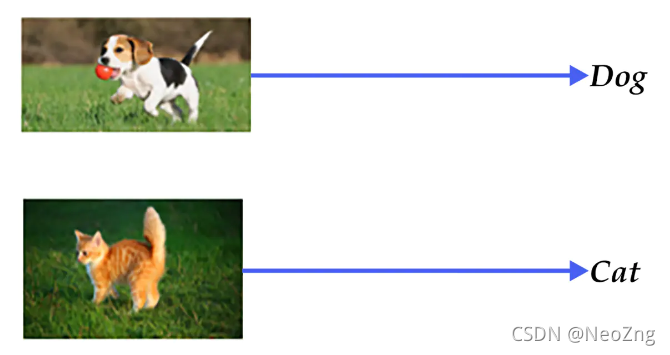
图像分类的例子
-
图像生成:这部分的内容比较复杂,现在一般是通过神经网络训练一个生成模型,它可以根据你给予的标签(如猫咪),根据学习的数据生成一张对应的图片,因此又被成为“画家AI”。GAN是生成模型领域的始祖。若感兴趣可以参考生成模型之PixelRNN、VAE与GAN三种算法浅解。在RM比赛中,我们可以利用生成模型创造出一个会让对手的自瞄算法认为是装甲板的图片,用它来作为机器人的涂装,以此干扰敌方的识别(一般对特定的神经网络有效,对传统算法无效)。这样的涂装看起来和装甲板毫不相干,但是检测算法却会认为它是一个装甲板!下图给出了示例。

通过对抗学习,给一张熊猫的图片增加了一些噪声
虽然在和一张噪声图片叠加之后的熊猫看起来和原来别无二致,但是目标检测算法却将它认作一只黑猩猩!当然,我们不能直接在装甲板上添加这样的噪声,这显然无法实现,但我们可以在周围的涂装上使用对抗样本,让神经网络认为贴在涂装上的喷涂样式是一个装甲板。是不是觉得这和迷彩服、隐身战斗机有相似之处呢?
-
目标检测:这是Robomater赛场上最常用的算法。目标检测和图像识别在一些方面有些类似,图像识别主要是对图像进行分类,让计算机判断这张图“有什么”或者”是什么“,而目标检测不仅要判断图片中是否有对应的物体,还要输出关于这些物体”在哪儿“的信息。和目标检测相似的“目标定位”的任务则是对图像中的一个特定物体进行定位,而目标检测算法中,图像内含有的对象种类和数量都是未知的。目标检测的输出是目标物体的位置和类别。

目标检测算法不仅对图像中的对象给出了分类,还用一个Box把他们框出
上图展示的是多目标检测算法的检测结果,基于神经网络的目标检测算法能将一套框架运用到所有目标对象的检测问题上,在训练过程中习得待检测对象的特征。而基于灯条匹配、扇叶识别的算法则是专门针对装甲板识别和能量机关识别的,相当于我们手动设计需要检测对象的特征。他们各有优劣,我们会在 5.2、6.1、6.2 中对他们进行更详细的介绍。
时下效果好、速度快的目标检测算法几乎都是基于神经网络构建的,常见的有R-CNN系列、YOLO、SSD等,我们也会在 5.2 中分别解读这几个算法。可以参阅这个系列的文章来进一步了解目标检测:目标检测入门(建议看完5.2再看这个)。
-
图像分割:根据图像的特征把图片分为几个有确定性质的区域,并寻找我们感兴趣的区域。图像分割算法可以目标检测的基础上进一步解析图像,其输出可以是对每个像素的像素级别的描述,如下图中灰粉色的区域就代表“运动员”。常见的算法有阈值分割、边缘分割、聚类、基于神经网络的语义分割等。想要了解更多可以参考图像分割传统方法整理。同样,最新的效果最好速度最快的算法也是基于神经网络的。这类算法目前在雷达站、自动步兵上可能会使用到。

图中的运动员和他的自行车被算法从背景中提取了出来
图源知乎-芝芝-https://zhuanlan.zhihu.com/p/143261645 ,侵删
-
目标跟踪:视觉目标(单目标)跟踪任务就是在给定某视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置。有同学可能会疑问,明明目标检测算法能对每一帧图像进行处理确定出目标的位置,为什么还需要目标跟踪?这是因为目标检测算法需要对整张图片进行处理,其消耗的运算资源很大,而目标跟踪不仅运算量以数量级的优势比前者小,还有简单准确,适用面广,抗噪性好的特点。因此在检测出目标之后,可以使用目标跟踪算法来进行后续的处理,同样能识别到装甲板等物体。在 5.3 中我们会更具体地介绍这个算法。

-
-
视频处理:在以上的几个任务中,大多以单张图片作为任务对象,视频处理则是将一段时间内的所有帧都作为任务输入。一个RM赛场的例子就是,我们可以保存在一秒钟内相机拍摄的所有图片,将它们堆叠成一个张量,送入卷积神经网络的输入层(卷核的维度也要进行相应的改变)。此时,我们便不单单可以处理定格在图像中的信息了,还能够对包含时间的数据如机器人处于小陀螺运动这个状态进行检测,以启用反小陀螺算法。利用了历史数据的图像处理算法都可以看作是视频处理算法。
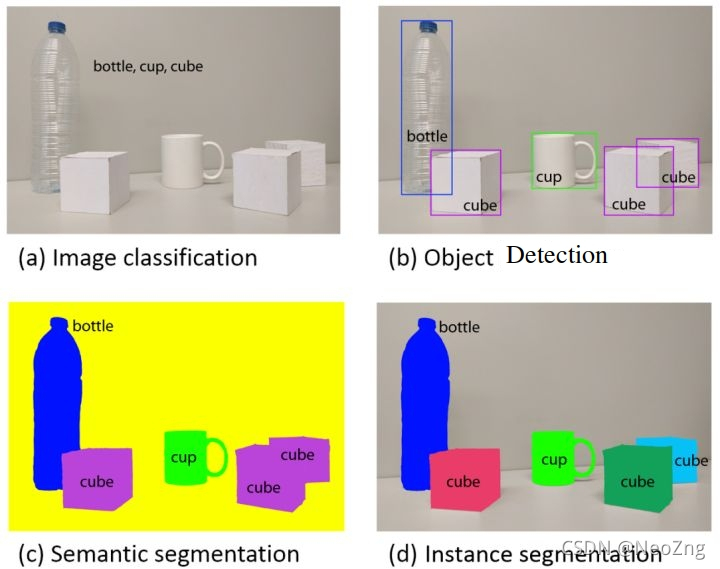
上文所述的几种任务的直观区别,a为图像分类,b为目标检测,c为语义分割,d为实例分割
5.1.OpenCV常用算法
OpenCV 是一个软件工具包,用于处理实时图像和视频,并提供分析和机器学习功能。使用这些标准化的软件包可以极大提高我们的开发效率,并且这些工具包对算法运行速度有特别的优化,能够使得这些算法在拥有GPU或支持多线程的电脑上得到加速。掌握OpenCV中的基本数据类型和常用函数是视觉组迈出开发的第一步,同时也能学习大量的相关知识。
这是OpenCV的官方网站,可以在这里的社区和其他开发者交流或查阅说明文档和例程。
首先你需要安装OpenCV,可以参考Ubuntu下OpenCV+contirb模块完全安装指南-NeoZng。
-
基本数据类型
-
Mat:矩阵类型,能够保存图像。
-
Point:一个像素点,或者任何类型的“点”。
-
Scalar:一个四维点类,是许多函数的参数。
-
Size:同样是一对数据构成的组,一般表示一块区域或图像的宽高,有些时候可以和point互换。
-
Rect:rectangle,矩形类,拥有Point和Size成员,用于表示一块矩形的区域。
-
RotatedRect:同上,不过有额外的成员angle用于表示角度。注意这个类的角度系统有些独特,务必阅读:OpenCV中旋转矩形的角度。
具体的说明请参阅OpenCV的说明文档,或在IDE内选择switch to declaration,便能转到注释处。
-
imgproc 模块(image process)
是我们使用OpenCV时最重要的模块之一。主要是一些像素级的操作,通过图像滤波、形态学操作、阈值操作、通道处理、图像变换、轮廓查找等功能来凸显图像特征或滤除噪声。还可以通过一些简单的绘图函数在图片上作画、输出文本。下面列出一些常用函数:
circle() //画出一个颜色、大小、粗细可调的圆,一般用于标记角点等特殊位置
line() //在两点之间画出一条直线,用于框出目标或作为参考。
//用于标记装甲板、能量机关的角点,框出候选的目标
cvtColor() //将图片从一个颜色空间转换到另一个颜色空间
split() //把图片的不同通道进行拆分,放入不同的Mat
subtract() //将两张矩阵的每个元素相减
//这在自瞄中将用于RGB到GRAY和HSV等空间的转换和颜色通道的分离。
threshold() //阈值操作,对一个特定的分量与阈值进行比较,大于阈值则全部设为某个值,小于阈值设为另一个值
inRange() //进阶版本,可以确定一个分量是否在一个区间内
//我们使用这两个函数来筛选特征,对拆分后的颜色空间进行操作以屏蔽不感兴趣的部分
blur() //加权模糊图像
GaussianBlur() //高斯加权模糊
medianBlur() //中值滤波
bilateralFilter() //双边滤波
//用于对图像进行降噪处理,或是抹去小光斑等
erode() //腐蚀操作,二值图的边缘或收缩
dilate() //膨胀操作,二值图的边缘会扩张
getStructuringElement() //获得结构元素(核)
morphologyEx() //更多的形态学操作,包括Opening,Closing,Morphological Gradient,Top Hat,Black Hat等
//用于增强图像的某些特征
Sobel() //微分运算,检测边缘,微分会使得图像中像素强度(某个分量)变化最大的部分为极值
Laplacian() //二阶微分,检测边缘,二阶微分会使得图像中像素强度变化最剧烈的部分为零
//寻找图像中的边缘
滤波、平滑、形态学操作等都属于使用图像算子对图片进行卷积操作,学习过数字图像处理或信号与系统的同学应该对此熟悉。在OpenCV中,你可以使用 getStructuringElement() 来构建独特的卷积核,随后使用 filer2D() 来对图像进行卷积运算。
floodFill() //漫水法,常用于寻找轮廓的预处理操作,和“画图”软件中“油漆桶”工具有相同的效果
findContour() //寻找二值图中的轮廓,并保存为一组点,算法类似于漫水法,遍历所有像素并查找相邻像素
drawContour() //根据一组点画出轮廓
//承接上面的各种预处理,用于找出图像中的轮廓并进行下一步操作
minAreaRect() //通过轮廓点,拟合出最小面积的RotatedRect
boundingRect() //通过轮廓点,找到其外接矩形Rect(水平)
fitEcllipse() //通过轮廓点,用最小二乘法拟合出一个外接椭圆,函数会返回椭圆的内接旋转矩形RotatedRect
minEnclosingCircle() //通过轮廓点,找到最小面积的包含圆(注意不是外接圆)
//将轮廓点转换为更容易处理的形状对象
remap() //根据给定的映射(函数)改变图像中每个像素点的位置
warpPerspective() //进行透视变换
getPerspectiveTransform() //获得透视变换所需的矩阵(4个点)
warpAffine() //进行仿射变换
getAffineTransform() //获得仿射变换所需的矩阵(3个点,为什么比透视少一个点?)
//一般用于把图像根据变换关系转化成正视图以便进行模板匹配、SVM匹配等操作
要区分仿射变换和投影变换,请记住仿射变换是线性变换,而投影变换不单单是线性变换。仿射变换会保持对象的相似关系和平行关系,而投影变换可能会改变这种关系,添加了非线性的因素(仿射变换的维度比投影少1,投影是一个商空间)。
imread() //根据路径读取一张图片
imwrite() //向对应路径写入一张图像
imreadmulti() //一次读取多张图片
//读取、保存测试用的图片或者自己制作的卷积核、用作模板匹配的图片模板等
class VideoCapture()
//构建一个视频捕获类,捕获的视频可以以每一帧图像的形式保存到Mat中
//VideoCapture cap(0); Mat frame; cap>>frame;这样就把一帧图片保存到frame内部了
//这个类能够通过get(),set()方法获取和设置一些相机参数
class VideoWriter()
//构建一个视频保存类,能够方便地保存视频,并且提供各种格式
//在实验室时无法模拟赛场的光线环境,常常在比赛时录制相机第一视角的视频,以供之后测试使用
//也可以把检测完的每一帧图片连成视频,保存下来,之后根据这个视频来查找问题、改进算法
imshow()/*在指定名称的窗口中显示一张图片,注意和waitKey()配合使用否则可能导致异常,用于查看一些算法处理后的结果,waitKey()的参数为图片显示的时间*/
//以下这个组合可以极大地方便参数调试,在程序运行的过程中通过回调函数,可以实时修改参数值
nameWindow() //新建一个空窗口
createTrackBar() //创建一个拖条,传入相关的参数可以实现参数调节
getTrackBarPos() //返回拖条所在的位置
//这个组合能够通过键盘和鼠标向程序传递参数,改变程序的状态,调试的时候非常好用
setMouseCallback() //设置鼠标的回调函数
waitKeyEx() //从键盘读取输入
除了第一个 imshow(),在使用highgui模块时需要你了解一些响应式编程的方法(有些类似于中断编程),不同于以往的的控制流命令式(面向过程)编程,响应式的程序在运行的时候会监听并响应异步数据流(Event Stream),可以时时和用户交互。我们使用的操作系统图形界面几乎都采用了响应式编程。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)