Weiyang Liu 1 Yandong Wen 2 Zhiding Yu 2 Ming Li 3 Bhiksha Raj 2 Le Song 1
1 Georgia Institute of Technology
2 Carnegie Mellon University
3 Sun Yat-Sen University
wyliu@gatech.edu, {yandongw,yzhiding}@andrew.cmu.edu, lsong@cc.gatech.edu
Abstract
本文研究了 open-set 协议下的深度人脸识别问题,在适当的度量空间下,理想人脸特征的最大类内距离小于最小类间距离。 然而,很少有现有算法可以有效地达到这个标准。 为此,我们提出了角度 softmax (A-Softmax) 损失,它使卷积神经网络 (CNN) 能够学习有角度的判别性特征。 从几何上讲,A-Softmax 损失可以被视为对超球面流形施加判别性约束,它本质上与人脸位于流形上的先验相匹配。 此外,角间隔的大小可以通过参数m进行定量调整。 我们进一步推导出特定的 m 来近似理想的特征标准。 对 Labeled Face in the Wild (LFW)、Youtube Faces (YTF) 和 MegaFace Challenge 1 的广泛分析和实验表明,A-Softmax loss 在 FR 任务中的优越性。
5. Concluding Remarks
本文提出了一种用于人脸识别的新型深度超球面嵌入方法。 具体来说,我们提出了 CNN 的 angular softmax loss 来学习具有角度间隔的判别性人脸特征 (SphereFace)。 A-Softmax 损失通过将学习到的特征限制为在超球面流形上具有判别性,从而提供了很好的几何解释,这在本质上与人脸同样位于非线性流形上的先验相匹配。 这种联系使得 A-Softmax 对于学习人脸表征非常有效。 几个流行的人脸基准的结果证明了我们方法的优越性和巨大潜力。
1. Introduction
通常,人脸识别可分为人脸识别和人脸验证[8, 11]。 前者将一张脸归类为特定的身份,而后者则确定一对人脸是否属于同一身份。
在测试协议方面,人脸识别可以在封闭集或开放集设置下进行评估,如图 1 所示。对于封闭集协议,所有测试身份都在训练集中预定义。将测试人脸图像分类为给定的身份是很自然的。在这种情况下,人脸验证相当于分别对一对人脸进行识别(见图1左侧)。因此,闭集 FR 可以很好地作为分类问题解决,其中特征是可分离的。对于开放集协议,测试身份通常与训练集脱节,这使得 FR 更具挑战性但更接近实践。由于不可能将人脸分类为训练集中的已知身份,因此我们需要将人脸映射到有判别力的特征空间。 在这种情况下,人脸识别可以被视为在探测人脸和图库中的每个身份之间执行人脸验证(见图 1 右侧)。 Open-set FR 本质上是一个度量学习问题,其中关键是学习有判别力的大边距特征
 Figure 1: Comparison of open-set and closed-set face recognition.
Figure 1: Comparison of open-set and closed-set face recognition.
期望开放集 FR 的特征满足在特定度量空间下最大类内距离小于最小类间距离的标准。 如果我们想使用最近邻达到完美的精度,这个标准是必要的。 然而,由于面部表现出的本质上较大的类内变化和较高的类间相似性 [21],因此学习到具有此标准的特征通常很困难。
很少有基于 CNN 的方法能够在损失函数中有效地制定上述标准。 开创性工作 [30, 26] 通过 softmax 损失学习人脸特征,但 softmax 损失 [跟随[16],我们将softmax loss定义为最后一个全连接层、softmax 函数和交叉熵损失的组合] 仅学习可分离的特征,这些特征的判别性不够。 为了解决这个问题,一些方法将 softmax 损失与对比损失 [25, 28] 或中心损失 [34] 结合起来,以增强特征的判别能力。 [22] 采用三元组损失来监督嵌入学习,导致最先进的人脸识别结果。 然而,中心损失仅明确鼓励类内紧凑性。 对比损失 [3] 和三重损失 [22] 都不能约束每个单独的样本,因此需要精心设计的对/三元组挖掘程序,这既耗时又对性能敏感。

 图 2:softmax 损失、修正的 softmax 损失和 A-Softmax 损失之间的比较。 在这个玩具实验中,我们构建了一个 CNN 来学习 CASIA 人脸数据集子集上的二维特征。 具体来说,我们将 FC1 层的输出维度设置为 2,并将学习到的特征可视化。 黄色点代表第一类人脸特征,紫色点代表第二类人脸特征。 可以看出,原始 softmax loss 学习的特征不能简单地通过角度进行分类,而修改后的 softmax loss 可以。 我们的 A-Softmax 损失可以进一步增加学习特征的角度余量。
图 2:softmax 损失、修正的 softmax 损失和 A-Softmax 损失之间的比较。 在这个玩具实验中,我们构建了一个 CNN 来学习 CASIA 人脸数据集子集上的二维特征。 具体来说,我们将 FC1 层的输出维度设置为 2,并将学习到的特征可视化。 黄色点代表第一类人脸特征,紫色点代表第二类人脸特征。 可以看出,原始 softmax loss 学习的特征不能简单地通过角度进行分类,而修改后的 softmax loss 可以。 我们的 A-Softmax 损失可以进一步增加学习特征的角度余量。
将 Euclidean margin 强加给学习到的特征 【加间隔到特征上?】似乎是一个被广泛认可的选择,但是出现了一个问题:Euclidean margin 是否总是适合学习有判别力的人脸特征? 为了回答这个问题,我们首先研究如何将基于 Euclidean margin 的损失应用于 FR。 最近的方法 [25, 28, 34] 将基于欧几里得边际的损失与 softmax 损失相结合来构建联合监督。 然而,从图 2 中可以看出,通过 softmax 损失学习的特征具有固有的角度分布【角度分布?】(也由 [34] 验证)。 从某种意义上说,基于 Euclidean margin 的损失与 softmax 损失不兼容,因此将这两种类型的损失结合起来并没有很好的动机。【直接说不兼容可还行?因为softmax损失有角度分布,而加上欧式间隔,可能就没了角度分布。】
在本文中,我们提出加入角间隔。 我们从一个二分类栗子开始分析 softmax 损失。 softmax loss 的决策边界是 (W1 − W2)x + b1 − b2 = 0,其中 Wi 和 bi 分别是 softmax loss 的权重和偏置 [如果不指定,论文中的权重和偏置对应的是softmax loss中的全连接层]。 如果我们将 x 定义为特征向量并约束 ‖W1‖ = ‖W2‖ = 1 和 b1 = b2 = 0,则决策边界变为 ‖x‖(cos(θ1) − cos(θ2)) = 0,其中 θi 为 Wi 和 x 之间的夹角。 新的决策边界仅取决于 θ1 和 θ2。 修改后的 softmax 损失能够直接优化角度,使 CNN 能够学习角度分布的特征(图 2)。
与原始 softmax loss 相比,modified softmax loss 学习到的特征是有角度分布的,但不一定更具辨别力。 最后,我们将 modified softmax loss 损失推广到 angular softmax (A-Softmax) 损失。 具体来说,我们引入一个整数 m (m ≥ 1) 来定量控制决策边界。 在二分类情况下,类 1 和类 2 的决策边界分别变为 ‖x‖(cos(mθ1)−cos(θ2))=0 和 ‖x‖(cos(θ1)− cos(mθ2))=0 。 m 定量控制角间隔的大小。 此外,A-Softmax 损失可以很容易地推广到多个类别,类似于 softmax 损失。 通过优化 A-Softmax 损失,决策区域变得更加分离,同时扩大类间间隔并压缩类内角分布。
A-Softmax loss 有清晰的几何解释。 在 A-Softmax 损失的监督下,学习到的特征构建了一个判别性角距离度量,相当于超球面流形上的测地距离 [geodesic distance ]。 A-Softmax 损失可以解释为将学习到的特征约束为在超球面流形上具有判别性,这本质上与面部图像位于流形 [14, 5, 31]上的先验相匹配。 A-Softmax loss 和超球面流形之间的紧密联系使得学习到的特征对于人脸识别更有效。 出于这个原因,我们将学习到的特征称为 SphereFace。
此外,A-Softmax loss 可以通过参数 m 定量调整角度裕度,使我们能够进行定量分析。 有鉴于此,我们推导出参数 m 的下限以近似期望得到的open-set FR 标准,即最大类内距离应小于最小类间距离。
我们的主要贡献可以总结如下:
(1) 我们为 CNN 提出了 A-Softmax 损失,以学习具有清晰和新颖几何解释的判别性面部特征。 学习到的特征在超球面流形上有判别性地 span,这本质上与面部也位于流形上的先验相匹配。
(2) 我们推导出 m 的下限,使得 A-Softmax 损失可以近似于最小类间距离大于最大类内距离的学习任务。
(3) 我们是第一个展示角间隔在 FR 中的有效性的人。 在公开可用的 CASIA 数据集 [37] 上进行训练,SphereFace 在多个基准测试中取得了有竞争力的结果,包括 Labeled Face in the Wild (LFW)、Youtube Faces (YTF) 和 MegaFace Challenge 1。
2. Related Work
Metric learning. 度量学习旨在学习相似性(距离)函数。 传统的度量学习 [36, 33, 12, 38] 通常在给定的特征 x1, x2 上学习距离度量 ‖x1 − x2‖A = √(x1 − x2)T A(x1 − x2) 的矩阵 A。 最近,流行的深度度量学习 [7, 17, 24, 30, 25, 22, 34] 通常使用神经网络来自动学习判别特征 x1、x2,然后是简单的距离度量,例如欧几里德距离 ‖x1 − x2‖2。 深度度量学习中最广泛使用的损失函数是对比损失 [1, 3] 和三重损失 [32, 22, 6],两者都对特征施加了Euclidean margin。
Deep face recognition. 深度人脸识别可以说是过去几年最活跃的研究领域之一。 [30, 26] 使用由 softmax 损失监督的 CNN 解决了开放集 FR,它本质上将开放集 FR 视为多类分类问题。 [25]结合对比损失和softmax损失共同监督CNN训练,大大提升了性能。 [22] 使用三元组损失来学习统一的人脸嵌入。 在近 2 亿张人脸图像上进行训练,他们达到了当前最先进的 FR 精度。 受线性判别分析的启发,[34] 提出了 CNN 的中心损失,并获得了有希望的性能。 一般而言,当前用于 FR 的表现良好的 CNN [28, 15] 主要建立在对比损失或三重损失的基础上。 人们可能会注意到,最先进的 FR 方法通常采用度量学习中的思想(例如对比损失、三重损失),这表明开放集 FR 可以通过判别性度量学习很好地解决。
L-Softmax 损失 [16] 也隐含地涉及角度的概念。 作为一种正则化方法,它对闭集分类问题有很大的改进。 不同的是,A-Softmax 损失被开发来学习判别性人脸嵌入。 正如我们的实验所证实的那样,与超球面流形的显式连接使我们学习的特征特别适用于开放集 FR 问题。 此外,A-Softmax 损失中的角度间隔是明确施加的,并且可以进行定量控制(例如,近似期望的特征标准的下限),而 [16] 只能进行定性分析。
3. Deep Hypersphere Embedding
3.1. Revisiting the Softmax Loss
我们通过研究 softmax 损失的决策标准( decision criteria )来重新审视 softmax 损失。 在二分类的情况下,softmax loss 得到的后验概率是: 其中 x 是学习到的特征向量。 Wi 和 bi 分别是对应于第 i 类的最后一个全连接层的权重和偏差。
其中 x 是学习到的特征向量。 Wi 和 bi 分别是对应于第 i 类的最后一个全连接层的权重和偏差。
如果 p1 > p2,则预测标签将分配给第 1 类,如果 p1 < p2,则将其分配给第 2 类。通过比较p1和p2,很明显,W T 1 x + b1和W T 2 x + b2决定了分类结果。决策边界是 (W1 − W2)x + b1 − b2 = 0。然后我们将 W T i x + bi 重写为 ‖W T i ‖‖x‖ cos(θi) + bi 其中 θi 是 Wi 和 x 之间的角度。请注意,如果我们将权重归一化并将偏差归零(‖Wi‖ = 1,bi = 0),后验概率变为 p1=‖x‖ cos(θ1) 和 p2=‖x‖ cos(θ2)。请注意,p1 和 p2 共享相同的 x,最终结果仅取决于角度 θ1 和 θ2。决策边界也变为 cos(θ1)−cos(θ2)=0(即矢量 W1 和 W2 的角平分线)。虽然上述分析是建立在二元类案例上的,但将分析推广到多类案例是微不足道的。在训练期间,修改后的 softmax loss (‖Wi‖=1, bi =0) 鼓励第 i 个类别的特征具有比其他类别更小的角度 θi(更大的余弦距离),这使得 Wi 和特征之间的角度对分类来说成为一个可靠的度量。
为了给出修改后的 softmax 损失的正式表达式,我们首先定义输入特征 xi 及其标签 yi。 原始的 softmax 损失可以写成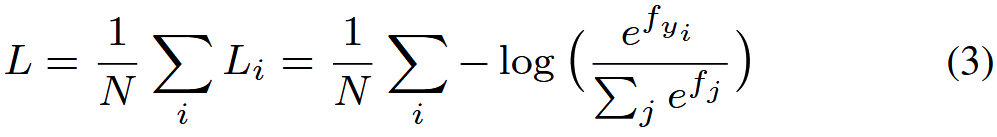 其中 fj 表示类得分向量 f 的第 j 个元素(j ∈ [1, K],K 是类的数量),N 是训练样本的数量。 在 CNN 中,f 通常是全连接层 W 的输出,因此 fj = WT j xi + bj 和 fyi = WT yi xi + byi 其中 xi, Wj , Wyi 是第 i 个训练样本, W 的第 j 列和第 yi 列。 我们在等式 (3) 中进一步重新表述 Li:
其中 fj 表示类得分向量 f 的第 j 个元素(j ∈ [1, K],K 是类的数量),N 是训练样本的数量。 在 CNN 中,f 通常是全连接层 W 的输出,因此 fj = WT j xi + bj 和 fyi = WT yi xi + byi 其中 xi, Wj , Wyi 是第 i 个训练样本, W 的第 j 列和第 yi 列。 我们在等式 (3) 中进一步重新表述 Li: 其中 θj,i(0 ≤ θj,i ≤ π) 是向量 Wj 和 xi 之间的夹角。 如上所述,我们首先在每次迭代中归一化 ‖Wj ‖ = 1, ∀j 并将偏差归零。 然后我们有修改后的 softmax 损失:
其中 θj,i(0 ≤ θj,i ≤ π) 是向量 Wj 和 xi 之间的夹角。 如上所述,我们首先在每次迭代中归一化 ‖Wj ‖ = 1, ∀j 并将偏差归零。 然后我们有修改后的 softmax 损失: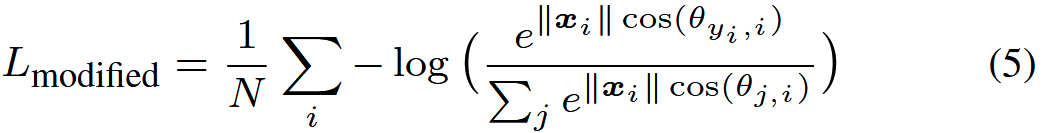 尽管我们可以使用修改后的 softmax 损失学习具有角度边界的特征,但这些特征仍然不一定具有判别力。 由于我们使用角度作为距离度量,因此很自然地将角度间隔加入到学习特征中以增强判别能力。 为此,我们提出了一种结合角间隔的新方法。
尽管我们可以使用修改后的 softmax 损失学习具有角度边界的特征,但这些特征仍然不一定具有判别力。 由于我们使用角度作为距离度量,因此很自然地将角度间隔加入到学习特征中以增强判别能力。 为此,我们提出了一种结合角间隔的新方法。
3.2. Introducing Angular Margin to Softmax Loss
我们没有设计一种新型的损失函数或者构建一个带有 softmax 损失的加权组合(类似于对比损失),而是提出了一种更自然的方式来学习角边距。 从前面对 softmax loss 的分析中,我们了解到决策边界可以极大地影响特征分布,所以我们的基本思想是操纵决策边界来产生角间隔。 我们首先给出一个激励性的二分类例子来解释我们的想法是如何运作的。
假设从第 1 类学习到的特征 x 是给定的,θi 是 x 和 Wi 之间的角度,已知修改后的 softmax 损失需要 cos(θ1) > cos(θ2) 才能正确分类 x。但是,如果我们需要 cos(mθ1) > cos(θ2) 其中 m ≥ 2 是一个整数以便正确分类 x 呢?它本质上使决策比以前更严格,因为我们要求 cos(θ1) 的下限 [当θ1∈[0,π / m], m≥2时,cos(θ1) > cos(mθ1)] 大于 cos(θ2)。第 1 类的决策边界是 cos(mθ1) = cos(θ2)。类似地,如果我们需要 cos(mθ2) > cos(θ1) 来正确分类第 2 类的特征,则第 2 类的决策边界 【每个类一个决策边界?】 为 cos(mθ2) = cos(θ1)。假设所有训练样本都被正确分类,这样的决策边界将产生 (m−1) / (m+1) θ1 2 的角间隔,其中 θ1 2 是 W1 和 W2 之间的角度。【不明白?】
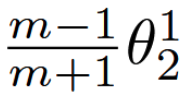
从角度来看,从身份 1 正确分类 x 需要 θ1 < θ2 / m ,而从身份 2 正确分类 x 需要 θ2 < θ1 / m 。两者都分别比原来的 θ1 < θ2 和 θ2 < θ1 更难。通过直接将这个想法表述为修改后的 softmax 损失方程。 (5), 我们有: 其中 θyi ,i 必须在 [0, π / m ] 的范围内。 为了摆脱这种限制并使其在 CNN 中可优化,我们扩展了 cos(θyi ,i) 的定义范围,将其推广为单调递减的角函数 ψ(θyi ,i),该函数应等于 cos(θyi ,i) 在 [0, π / m]。 因此,我们提出的 A-Softmax 损失公式如下:
其中 θyi ,i 必须在 [0, π / m ] 的范围内。 为了摆脱这种限制并使其在 CNN 中可优化,我们扩展了 cos(θyi ,i) 的定义范围,将其推广为单调递减的角函数 ψ(θyi ,i),该函数应等于 cos(θyi ,i) 在 [0, π / m]。 因此,我们提出的 A-Softmax 损失公式如下: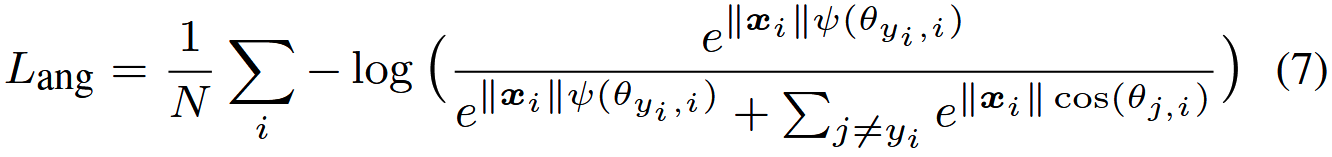 在这里,我们定义:
在这里,我们定义:
 m≥1是一个控制角间隔大小的整数。当m = 1时,即为修改后的softmax损失。
m≥1是一个控制角间隔大小的整数。当m = 1时,即为修改后的softmax损失。
也可以从决策边界的角度来论证 A-Softmax 损失的合理性。 A-Softmax loss 对不同的类采用不同的决策边界(每个边界比原来的更严格),从而产生角间隔。 【不同的决策边界产生了角间隔?】决策边界的比较如表1所示,从原始softmax loss到修改后的softmax loss,从优化内积到优化角度。 从修改后的 softmax loss 到 A-Softmax loss,使得决策边界更加严格和分离。 角间隔随着 m 的增大而增加,如果 m = 1 则为零。 表1:二元情况下决策边界的比较。θi是Wi与x的夹角。
表1:二元情况下决策边界的比较。θi是Wi与x的夹角。
在 A-Softmax 损失的监督下,CNN 学习具有几何可解释角边距的面部特征。 因为 A-Softmax loss 需要 Wi = 1,bi = 0,所以它使得预测只取决于样本 x 和 Wi 之间的角度。 所以 x 可以用最小角度来归为身份ID。 添加参数 m 是为了学习不同ID之间的角间隔。【迷糊了?】
为了便于梯度计算和反向传播,我们将 cos(θj,i) 和 cos(mθyi ,i) 替换为仅包含 W 和 xi 的表达式,这很容易通过定义余弦和多角度公式来完成(也是为什么我们需要 m 是一个整数的原因)[by definition of cosine and multi-angle formula]。 没有 θ,我们可以计算关于 x 和 W 的导数,类似于 softmax 损失。【不懂???】
3.3. Hypersphere Interpretation of A-Softmax Loss
当 m ≥ 2 时,A-Softmax loss 对正确分类有更强的要求,这会在不同类别的学习特征之间产生角度分类余量。 A-Softmax 损失不仅通过角边距对学习的特征施加判别力,而且还呈现出漂亮而新颖的超球面解释。 如图 3 所示,A-Softmax 损失等效于学习在超球面流形上具有判别力的特征,而 Euclidean margin 损失则学习欧几里得空间中的特征。
为简化起见,我们采用二分类情况来分析超球面解释。考虑一个来自第 1 类的样本 x 和两个列权重 W1、W2,A-Softmax loss 的分类规则是 cos(mθ1) > cos(θ2),相当于 mθ1 < θ2。注意 θ1, θ2 等于它们在单位超球面 {vj , ∀j| 上对应的弧长 [arc length] ω1, ω2 。 [ωi 为 Wi 与样本 x 在单位超球面上的投影点之间的最短弧长(测地线距离),而对应的 θi 为 Wi 与 x 之间的夹角]
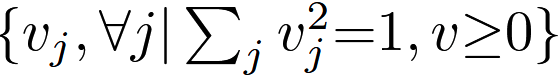
因为 ‖W ‖1 = ‖W ‖2 = 1,所以决策依赖于弧长 ω1 和 ω2。决策边界等价于 mω1 = ω2,将 x 正确分类为第 1 类的约束区域为 mω1 < ω2。从几何上讲,这是一个位于超球面流形上的类超圆区域。例如,它是 3D 情况下单位球体上的圆形区域,如图 3 所示。请注意,较大的 m 导致每个类的更小的类超圆区域,这是对流形的显式判别约束。为了更好地理解,图 3 提供了 2D 和 3D 可视化。可以看到,A-Softmax loss 在 2D 情况下对单位圆施加弧长约束,在 3D 情况下对单位球体施加类圆区域约束。我们的分析表明,使用 A-Softmax 损失优化角度本质上使学习到的特征在超球面上更具辨别力。
 图 3:欧几里得边际损失(例如对比损失、三元组损失、中心损失等)、修正的 softmax 损失和 A-Softmax 损失的几何解释。 第一行是2D特征约束,第二行是3D特征约束。 橙色区域表示类别 1 的判别性约束,而绿色区域表示类别 2。
图 3:欧几里得边际损失(例如对比损失、三元组损失、中心损失等)、修正的 softmax 损失和 A-Softmax 损失的几何解释。 第一行是2D特征约束,第二行是3D特征约束。 橙色区域表示类别 1 的判别性约束,而绿色区域表示类别 2。
3.4. Properties of A-Softmax Loss
Property 1. A-Softmax 损失定义了一个难度可调的大的角度间隔学习任务。 m越大,角间隔越大,流形上的约束区域越小,相应的学习任务也变得越困难。
我们知道 m 越大,A-Softmax 损失约束的角间隔就越大。 存在一个最小 m 约束最大类内角距离小于最小类间角距离,这也可以在我们的实验中观察到。【?】
Definition 1. (期望特征分布的最小 m)。 mmin 是最小值,当 m > mmin 时,A-Softmax 损失定义了一个学习任务,其中最大类内角特征距离被限制为小于最小类间角特征距离。
Property 2 (二分类情况下 mmin 的下限)。 在二分类的情况下,我们有 mmin ≥ 2 + √3。
证明。 我们考虑 W1 和 W2 所跨越的空间。 由于 m ≥ 2,容易得到第 1 类跨越的最大角度为 θ12 / (m−1) + θ12 / (m+1) 【不懂?】,其中 θ12 是 W1 和 W2 之间的夹角。 为了要求最大类内特征角距离小于最小类间特征角距离,我们需要约束: 解完这两个不等式【两个不等式也不懂?】后,我们可以得到mmin ≥ 2 +√3,这是二分类栗子的下界。
解完这两个不等式【两个不等式也不懂?】后,我们可以得到mmin ≥ 2 +√3,这是二分类栗子的下界。
Property 3 (多类情况下 mmin 的下限)。 在假设 Wi, ∀i 在欧几里得空间中均匀分布的情况下,我们有 mmin ≥ 3。
证明。 我们考虑下界的 2D k 类(k ≥ 3)场景。 因为 Wi, ∀i 在二维欧几里得空间中均匀分布,我们有 θi+1 i = 2π / k ,其中 θi+1 i 是 Wi 和 Wi+1 之间的角度。 由于 Wi, ∀i 是对称的,我们只需要分析其中之一。 对于第 i 个类 (Wi),我们需要约束:
 解出这个不等式后,得到mmin≥3,这是多类情况下的下界。
解出这个不等式后,得到mmin≥3,这是多类情况下的下界。
基于此,我们使用 m = 4 来近似所需的特征分布标准。 由于下限不一定是严格的,在某些条件下给出更严格的下限和上限也是可能的,我们留待以后的工作。 实验还表明,较大的 m 始终效果更好,而 m = 4 通常就足够了。
3.5. Discussions
Why angular margin. 首先,也是最重要的一点,角间隔与流形上的判别性直接相关,它本质上与人脸同样位于流形上的先验相匹配。 其次,将 angular margin 与 softmax loss 结合起来实际上是一个更自然的选择。如图 2 所示,由原始 softmax 损失学习的特征具有固有的角度分布。 所以直接将欧几里德间隔约束和 softmax 损失结合起来是不合理的。
Comparison with existing losses. 在深度 FR 任务中,最受欢迎和性能良好的损失函数包括对比损失、三重损失和中心损失。 首先,他们只对学习到的特征施加欧几里得间隔(没有归一化),而我们的则直接考虑自然动机的角边界。 其次,对比损失和三元组损失在从训练集中构成对/三元组时都会受到数据扩展的影响,而我们的不需要样本挖掘并对整个小批量施加判别性约束(相比之下,对比和三元组损失仅影响少数代表性的对/三元组【略微不懂?】)。
4. Experiments
4.1. Experimental Settings
CNNs Setup.
Testing. 我们从 FC1 层的输出中提取深度特征 (SphereFace)。 对于所有实验,测试人脸的最终表示是通过连接其原始人脸特征和水平翻转特征来获得的。 分数(度量)由两个特征的余弦距离计算。 最近邻分类器和阈值分别用于人脸识别和验证。
4.2. Exploratory Experiments
Effect of m. We perform a toy example with different m。我们用在 CASIA-WebFace 中拥有最多样本的 6 个个体来训练 A-Softmax 损失。 我们将输出特征维度 (FC1) 设置为 3,并将图 5 中的训练样本可视化。可以观察到,如预期的那样,较大的 m 会导致球体上的更具判别性的分布以及更大的角边距。 我们还使用第 1 类(蓝色)和第 2 类(深绿色)构建正负对来评估来自同一类和不同类的特征的角度分布。 正负对的角度分布(图 5 的第二行)定量地显示了角间隔变大,而 m 增加,每个类也变得更加清晰。 图 5:使用不同 m 学习的特征的可视化。 第一行显示投影在单位球体上的 3D 特征。 投影点是特征向量和单位球体的交点。 第二行显示了正对和负对的角度分布(我们从子集中选择第 1 类和第 2 类来构建正负对)。 橙色区域表示正对,蓝色区域表示负对。 所有角度都以弧度表示。 请注意,此可视化实验使用了 CASIA-WebFace 数据集的 6 类子集
图 5:使用不同 m 学习的特征的可视化。 第一行显示投影在单位球体上的 3D 特征。 投影点是特征向量和单位球体的交点。 第二行显示了正对和负对的角度分布(我们从子集中选择第 1 类和第 2 类来构建正负对)。 橙色区域表示正对,蓝色区域表示负对。 所有角度都以弧度表示。 请注意,此可视化实验使用了 CASIA-WebFace 数据集的 6 类子集
Effect of CNN architectures. 我们用不同的卷积层数训练 A-Softmax 损失(m = 4)和原始 softmax 损失。 具体的 CNN 架构见表 2。 从图 6 中可以看出,A-Softmax 损失始终优于具有 softmax 损失的 CNN(1.54%∼1.91%),表明 A-Softmax 损失更适合开放集 FR。 此外,A-Softmax loss定义的困难学习任务充分利用了更深层次架构的优越学习能力
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)