博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业
毕业设计
项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
1、项目介绍
技术栈:
Python语言、Flask框架、Selenium爬虫、机器学习、多元线性回归预测模型、LayUI框架、Echarts可视化大屏、淘宝数据采集
2、项目界面
(1)商品数据可视化大屏

(2)商品数据后台管理
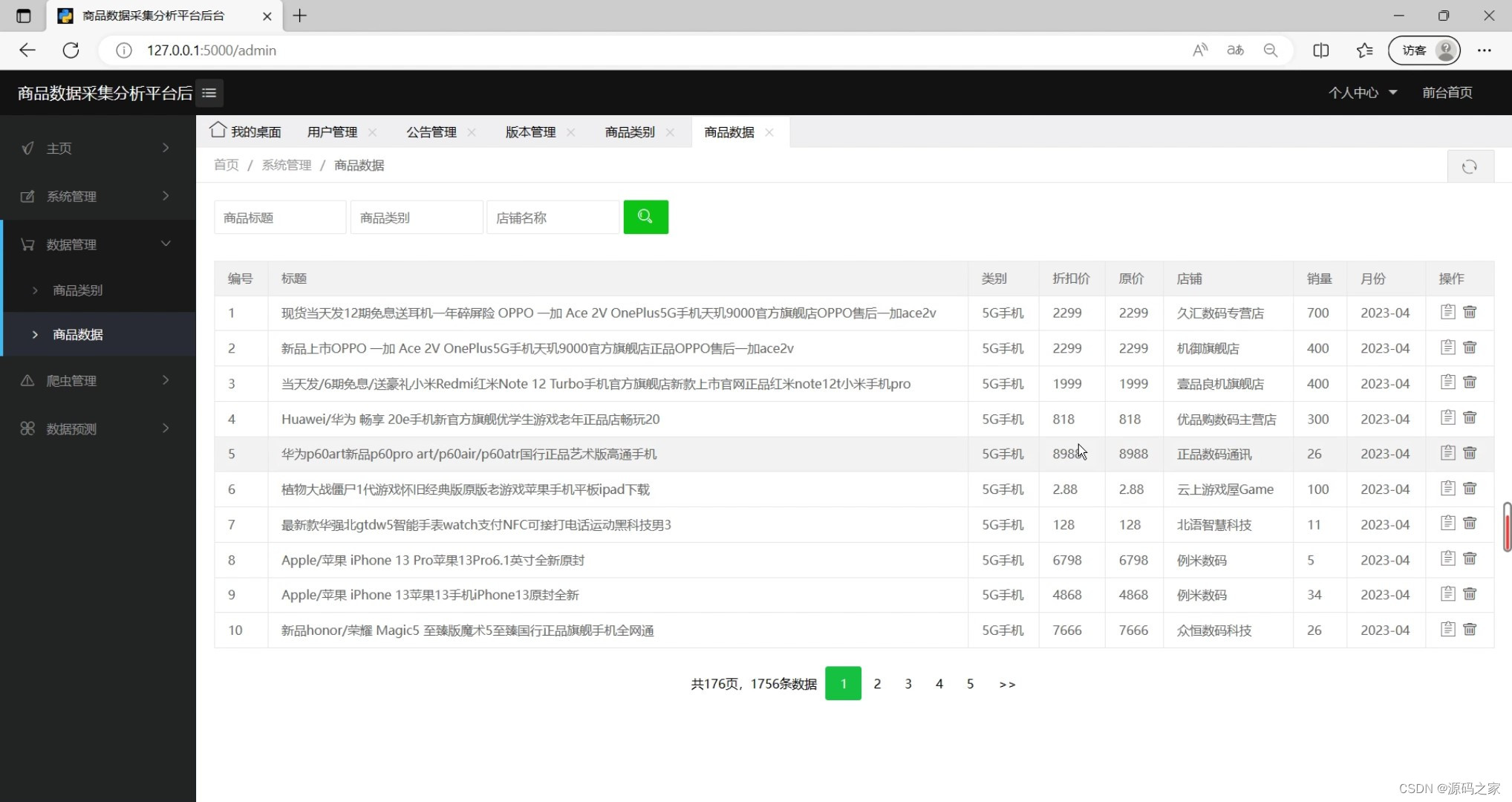
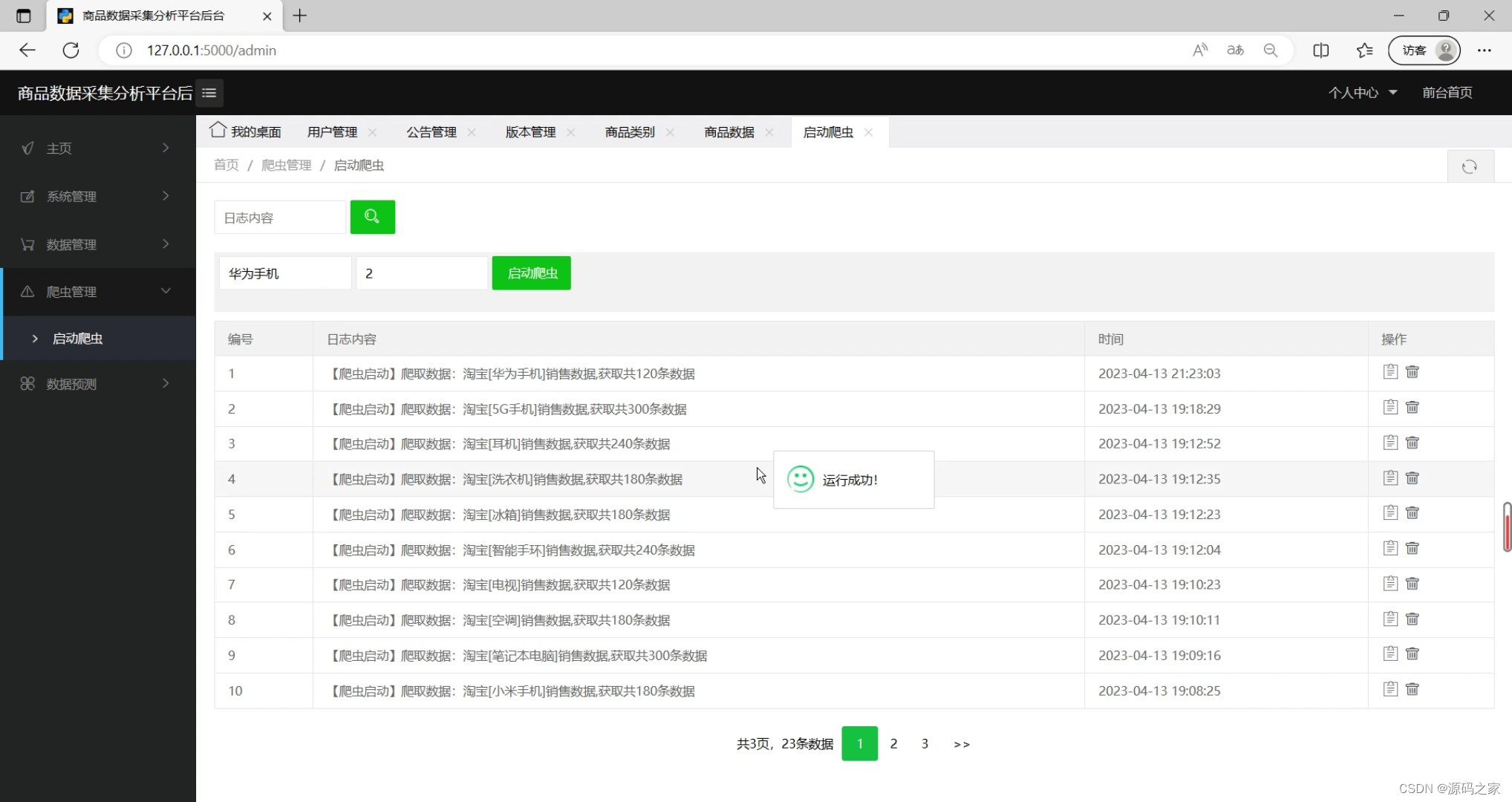
(3)定时爬虫数据采集
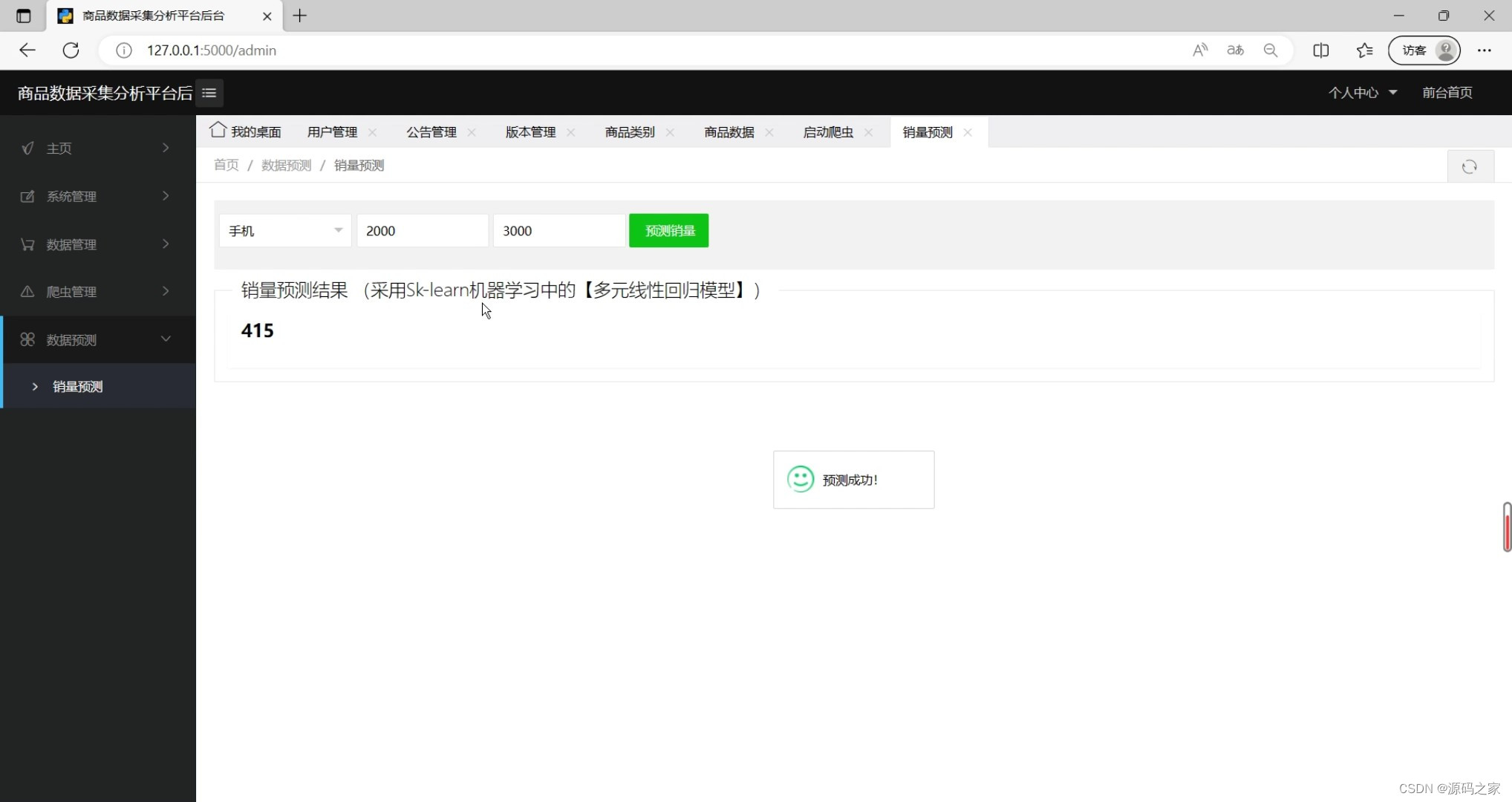
(4)机器学习预测算法(销量预测)
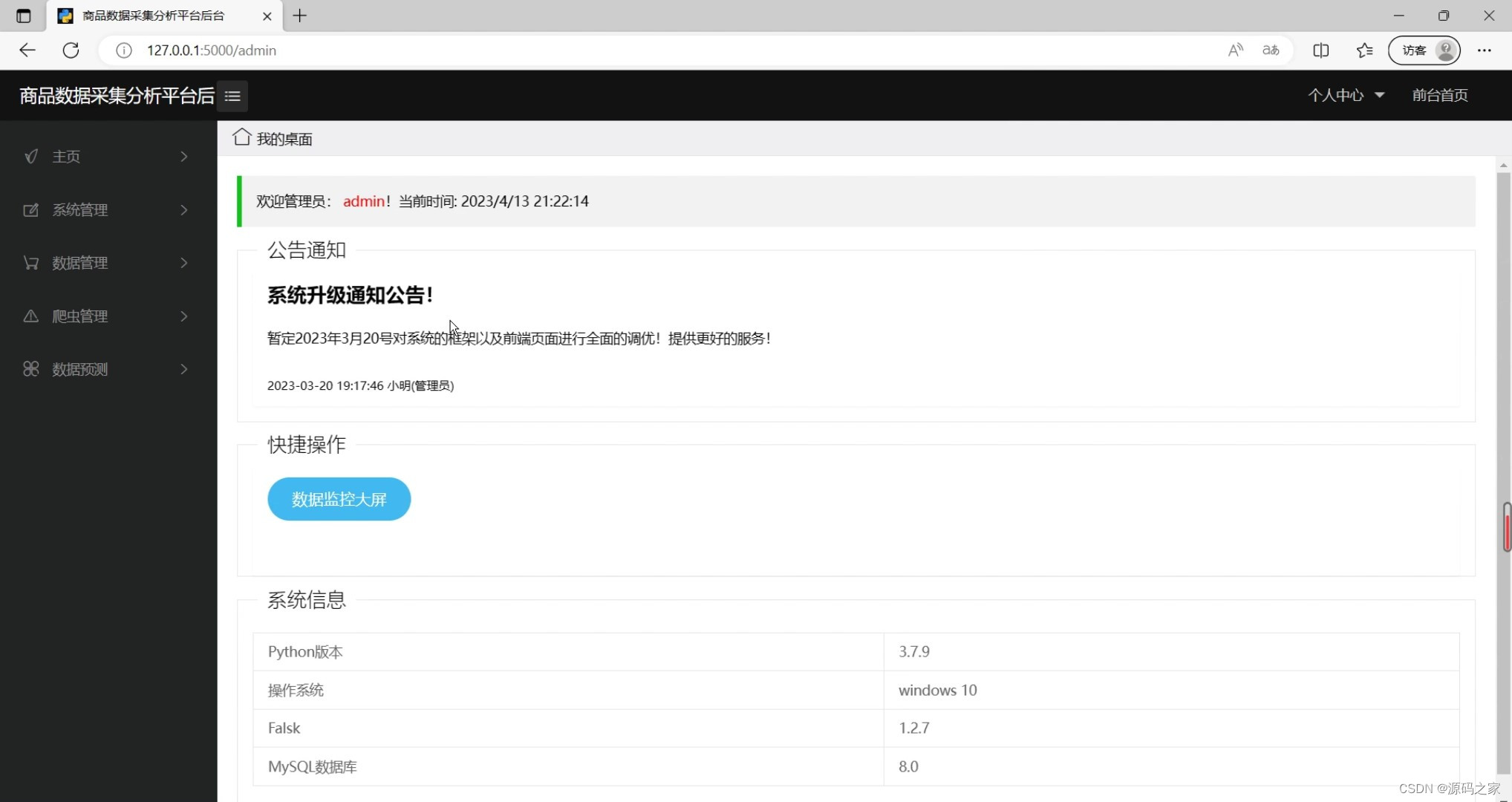
(5)后台管理页面
(6)注册登录界面
(7)用户管理
3、项目说明
突如其来爆发的各类数据,使得电商软件面临商品数据管理不当导致商品更新慢;动态变化的疫情对销量产生不确定性,导致平台亏损不一的情况;商品数据背后的价值不能够直观地得到等问题。基于以上问题,本次设计将电商和数据分析系统结合,使用数字化加持,简化平台管理,赋能智慧企业的一款数据分析可视化管理系统。本文主要工作为:分析电商背景后,对本平台所使用到的相关技术如Selenium、Echarts、Ajax、MySQL和Flask、Lay-UI、Bootstrap框架进行介绍及对比分析,通过电商数据平台管理者的基本需求及相关电商管理模块的需求分析进行总结,对本平台的设计概要分为数据管理部分及后台管理两大核心模块,数据管理部分囊括了数据爬取、数据存储、数据分析、数据可视化以及基于多元线性回归的数据预测五个板块。
本课题的核心内容是以电商企业对数据分析平台的基本需求为背景,根据预先设计的思路进行平台的搭建。运用Selenium爬虫技术将数据爬取并用Pandas进行清洗后,将数据导入到MySQL中,使用数据可视化技术对数据进行直观地展示,同时也通过机器学习中的多元线性回归算法对商品销量进行预测,并导入后台在后台管理中查看或使用。最后,本平台运用黑盒测试对数据管理和后台管理进行功能性测试,测试结果均符合预期且平台能够正常运行。
4、核心代码
from flask import Flask as _Flask, flash
from flask import request, session
from flask import render_template
from flask.json import JSONEncoder as _JSONEncoder, jsonify
import decimal
import service.users_data as user_service
import service.notice_data as notice_data
import service.slog_data as slog_data
import service.goods_data as goods_data
import service.category_data as category_data
import service.view_data as view_data
import service.version_data as version_data
import machine_learning.goods_predict as gp
from spider import shopping_spider
from concurrent.futures import ThreadPoolExecutor
class JSONEncoder(_JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o)
super(_JSONEncoder, self).default(o)
class Flask(_Flask):
json_encoder = JSONEncoder
import os
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'filesystem'
app.config['SECRET_KEY'] = os.urandom(24)
# -------------前台可视化大数据分析相关服务接口start-----------------
# 系统默认路径前台跳转
@app.route('/')
def main_page():
return render_template("main.html")
# -------------前台可视化大数据分析相关服务接口end-----------------
# -------------后台管理模块相关服务接口start-----------------
# 登录
@app.route('/login', methods=['POST'])
def login():
if request.method == 'POST':
account = request.form.get('account')
password = request.form.get('password')
if not all([account, password]):
flash('参数不完整')
return "300"
res = user_service.get_user(account, password)
if res and res[0][0] > 0:
session['is_login'] = True
session['role'] = res[0][1]
return "200"
else:
return "300"
# 新增系统版本数据
@app.route('/version/add', methods=["POST"])
def sys_version_add():
get_data = request.form.to_dict()
name = get_data.get('name')
version = get_data.get('version')
return version_data.add_sys_version(name, version)
# 修改系统版本数据
@app.route('/version/edit', methods=["PUT"])
def version_edit():
get_data = request.form.to_dict()
id = get_data.get('id')
name = get_data.get('name')
version = get_data.get('version')
version_data.edit_sys_version(id, name, version)
return '200'
# 删除系统版本数据
@app.route('/version/delete', methods=["DELETE"])
def version_delete():
get_data = request.form.to_dict()
id = get_data.get('id')
version_data.del_sys_version(id)
return '200'
# -----------------系统版本管理模块END-----------------
# -----------------类别管理模块START-----------------
# 公告管理页面
@app.route('/html/category')
def category_manager():
return render_template('html/category.html')
# 获取公告数据分页
@app.route('/category/list', methods=["POST"])
def category_list():
get_data = request.form.to_dict()
page_size = get_data.get('page_size')
page_no = get_data.get('page_no')
param = get_data.get('param')
data, count, page_list, max_page = category_data.get_category_list(int(page_size), int(page_no), param)
return jsonify({"data": data, "count": count, "page_no": page_no, "page_list": page_list, "max_page": max_page})
# 新增类别数据
@app.route('/category/add', methods=["POST"])
def category_add():
get_data = request.form.to_dict()
content = get_data.get('content')
return category_data.add_category(content)
# 修改类别数据
@app.route('/category/edit', methods=["PUT"])
def category_edit():
get_data = request.form.to_dict()
id = get_data.get('id')
content = get_data.get('content')
category_data.edit_category(id, content)
return '200'
# 删除类别数据
@app.route('/category/delete', methods=["DELETE"])
def category_delete():
get_data = request.form.to_dict()
id = get_data.get('id')
category_data.del_category(id)
return '200'
# -----------------类别管理模块END-----------------
# -----------------爬虫管理模块START-----------------
# 后台调用爬虫
@app.route('/spider/start', methods=["POST"])
def run_spider():
get_data = request.form.to_dict()
key = get_data.get('key')
total_pages = get_data.get('num')
executor = ThreadPoolExecutor(2)
executor.submit(shopping_spider.spider(key, total_pages))
return '200'
# 爬虫日志页面
@app.route('/html/slog')
def slog_manager():
return render_template('html/slog.html')
# 获取爬虫日志数据分页
@app.route('/slog/list', methods=["POST"])
def slog_list():
get_data = request.form.to_dict()
page_size = get_data.get('page_size')
page_no = get_data.get('page_no')
param = get_data.get('param')
data, count, page_list, max_page = slog_data.get_slog_list(int(page_size), int(page_no), param)
return jsonify({"data": data, "count": count, "page_no": page_no, "page_list": page_list, "max_page": max_page})
# 修改爬虫日志数据
@app.route('/slog/edit', methods=["PUT"])
def slog_edit():
get_data = request.form.to_dict()
id = get_data.get('id')
log = get_data.get('log')
slog_data.edit_slog(id, log)
return '200'
# 删除爬虫日志数据
@app.route('/slog/delete', methods=["DELETE"])
def slog_delete():
get_data = request.form.to_dict()
id = get_data.get('id')
slog_data.del_slog(id)
return '200'
# -----------------爬虫管理模块END-----------------
# -----------------商品管理模块START----------------
# 商品页面
@app.route('/html/goods')
def goods_manager():
return render_template('html/goods.html')
# 获取商品数据分页
@app.route('/goods/list', methods=["POST"])
def goods_list():
get_data = request.form.to_dict()
page_size = get_data.get('page_size')
page_no = get_data.get('page_no')
param = get_data.get('param')
data, count, page_list, max_page = goods_data.get_goods_list(int(page_size), int(page_no), param)
return jsonify({"data": data, "count": count, "page_no": page_no, "page_list": page_list, "max_page": max_page})
# 修改商品数据
@app.route('/goods/edit', methods=["PUT"])
def goods_edit():
get_data = request.form.to_dict()
id = get_data.get('id')
title = get_data.get('title')
category = get_data.get('category')
discount = get_data.get('discount')
original_price = get_data.get('original_price')
shop = get_data.get('shop')
monthly_sales = get_data.get('monthly_sales')
goods_data.edit_goods(id, title, category, discount, original_price, shop, monthly_sales)
return '200'
# 删除商品数据
@app.route('/goods/delete', methods=["DELETE"])
def goods_delete():
get_data = request.form.to_dict()
id = get_data.get('id')
goods_data.del_goods(id)
return '200'
# 预测页面
@app.route('/html/predict')
def html_predict():
return render_template('html/predict.html')
# 预测商品数据
@app.route('/goods/predict', methods=["POST"])
def goods_predict():
get_data = request.form.to_dict()
t = get_data.get('t')
p = get_data.get('p')
op = get_data.get('op')
return jsonify({"data": gp.predict(t, p, op)})
# -----------------商品管理模块END-----------------
# -----------------可视化页面模块START-----------------
# 获取页面总计数据
@app.route('/data/total')
def total_data():
return view_data.total_data()
# 商品销量top10
@app.route('/data/sales/top')
def sales_top():
return view_data.goods_sales_top()
# 商铺销量top10
@app.route('/data/shop/top')
def shop_top():
return view_data.shop_sales_top()
# 销量分布
@app.route('/data/sales/distribution')
def sales_distribution():
return view_data.sales_distribution_data()
# 价格分布
@app.route('/data/price/distribution')
def price_distribution():
return view_data.price_distribution_data()
# 类别统计
@app.route('/data/category/count')
def category_data_view():
return view_data.category_goods_data()
# 最近6个月销量趋势
@app.route('/data/sales/month')
def sales_data():
return view_data.sales_data()
# -----------------可视化页面模块END-----------------
if __name__ == '__main__':
# 端口号设置
app.run(host="127.0.0.1", port=5000)
????✌
感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!
????✌
源码获取:
????
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
????
点赞、收藏、关注,不迷路,
下方查看
????????
获取联系方式
????????