简介:
在使用 Hive 外部表时,分隔符设置不当可能导致数据导入和查询过程中的问题。本文将详细介绍如何解决在 Hive 外部表中正确设置分隔符的步骤。
问题描述
:
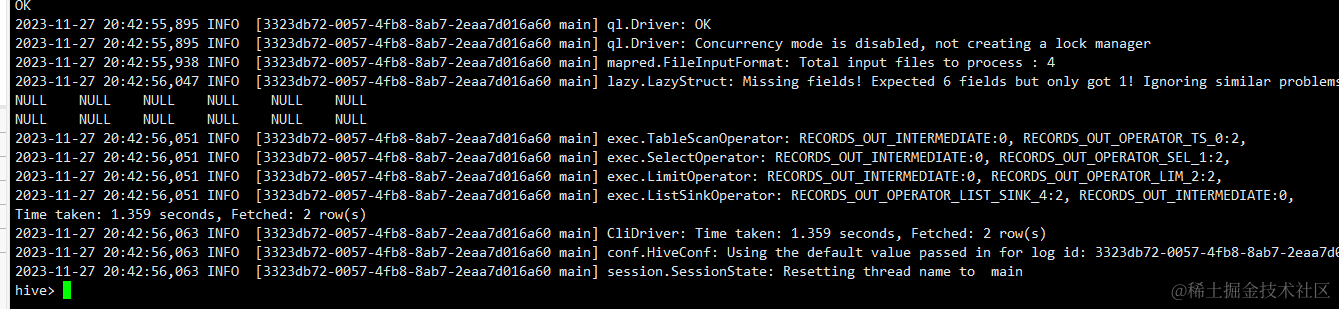
在使用Hive外部表时,可能会遇到分隔符问题。这主要是因为Hive在读取数据时,会根据设定的分隔符来区分不同的字段。如果Hive表的分隔符和数据的实际分隔符不一致,就会导致Hive无法正确地解析数据,从而使得数据字段显示为NULL。
案例分析
:
例如,假设你有一个以逗号分隔的CSV文件,你想将这个文件导入到Hive中。你创建了一个外部表,并设置了字段分隔符为逗号。然后,你将数据导入到Hive中。但是,如果你的数据实际上是以制表符或其他字符分隔的,那么Hive在读取数据时就会出现问题,因为它期望的是逗号分隔符,但实际上却是其他分隔符。结果,你在查询表时,会发现所有的字段都显示为NULL。
解决方案
:
步骤 1:识别问题
首先,我们需要确认问题是否由分隔符引起。如果在查询Hive表时,所有字段都显示为NULL,那么这可能是由于Hive表的分隔符和数据的实际分隔符不一致导致的。
步骤 2:修改外部表
一旦确认问题是由分隔符引起的,我们就可以使用
ALTER TABLE
命令来修改外部表的分隔符属性。例如,如果我们知道数据实际上是以井号分隔的,我们可以使用以下命令来修改分隔符:
ALTER TABLE your_table SET SERDEPROPERTIES ('field.delim' = '#');
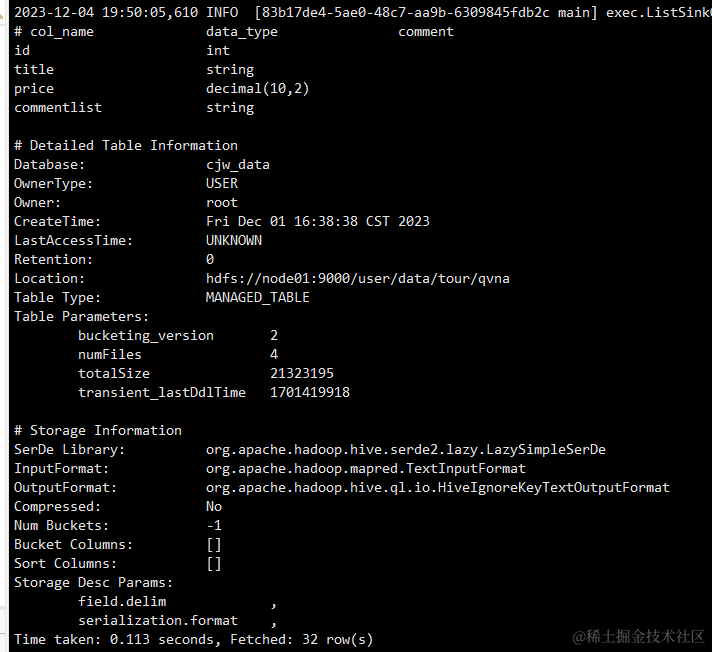
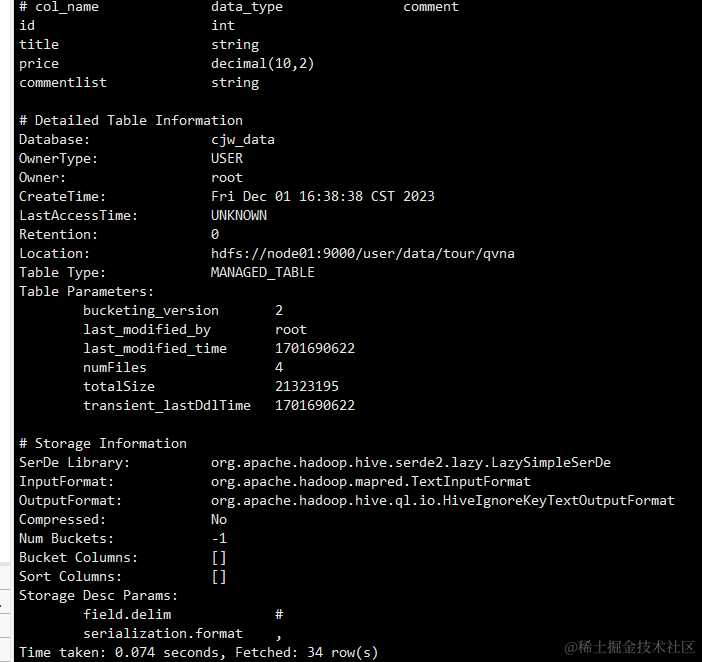
修改后可以通过下面指令去查看表的详细情况来确定是否修改成功:
步骤 3:处理数据
在数据导入前,我们可能需要进行一些预处理步骤。例如,如果HDFS中已经存在旧的数据文件,我们可能需要先删除这些文件。然后,我们可以重新设置分隔符,并将数据导入到HDFS中。
步骤 4:验证修改
最后,我们需要验证修改是否成功。我们可以查询表数据,以确认修改后的分隔符是否正确应用。如果所有字段都能正确显示,那么就说明我们的修改是成功的。


注意事项
:
除了分隔符问题外,进行数据迁移时还可能遇到以下一些问题:
-
数据类型不匹配
:如果Hive表的数据类型和实际数据的数据类型不一致,可能会导致数据显示错误或查询结果不准确。解决这个问题的方法是在创建表时确保数据类型的正确性,或者在表已经创建后,使用
ALTER TABLE
命令来修改数据类型。
-
文件格式问题
:Hive支持多种文件格式,如文本文件、SequenceFile、Avro、Parquet等。如果你的数据文件的格式和Hive表的文件格式设置不一致,可能会导致无法正确读取数据。解决这个问题的方法是在创建表时设置正确的文件格式,或者将数据文件转换为Hive表支持的格式。
-
权限问题
:如果Hive没有权限访问存储数据的HDFS目录,可能会导致无法读取数据。解决这个问题的方法是确保Hive有权限访问数据目录,或者更改数据目录的权限设置。