
引言
在快速发展的数据驱动时代,数据的实时、准确同步成为了企业信息系统不可或缺的一部分。随着技术的进步,特别是在分布式计算和大数据技术的背景下,构建一个高效且可靠的数据同步管道成为了挑战。
Apache SeaTunnel作为一个先进的数据集成开发平台,提供了构建高效CDC数据同步管道的可能性。本文将深入探讨利用Apache SeaTunnel构建CDC数据同步管道的过程,揭示其背后的关键技术和实践策略,旨在为面临数据同步挑战的专业人士提供实用指导。
大家下午好,今天分享的主题是基于Apache SeaTunnel构建CDC数据同步管道。我之前主要从事监控APM的计算平台工作,后来转向数据集成开发平台。目前,我正在基于Apache SeaTunnel开发CDC的数据同步管道,长期活跃于开源社区。我是Apache SeaTunnel的PMC成员和Skywalking的committer。
Apache SeaTunnel 简介
Apache SeaTunnel是一个数据集成开发平台,其发展经历了几个重要阶段:
-
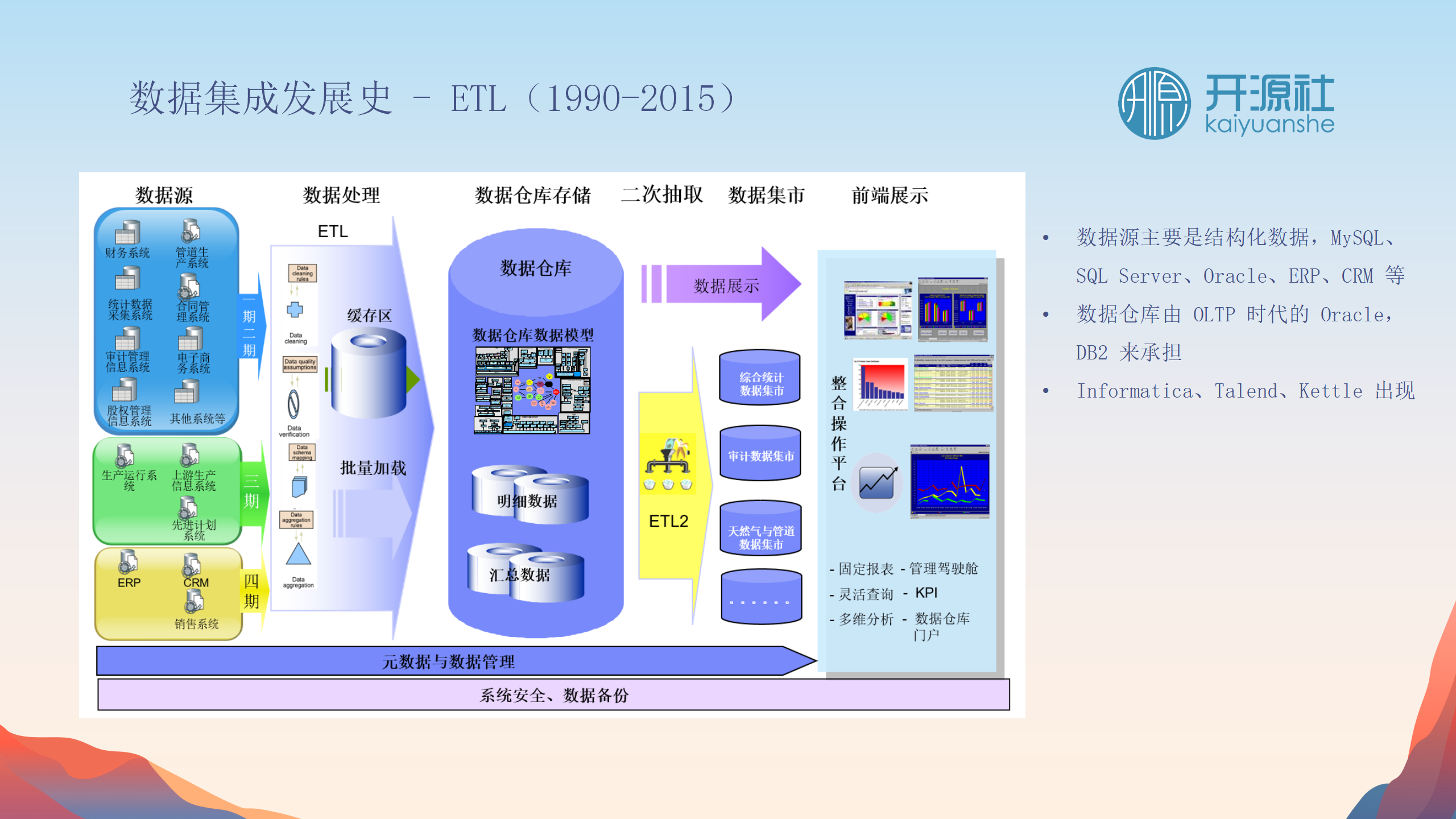
ETL时代(90年代)
:面向结构化数据库的数据同步,用于构建数据仓库。
-
MPP和分布式技术流行
:使用技术如Hive进行数据仓库的构建。此阶段主要使用mapreduce程序进行数据搬运和转换。
-
数据湖技术流行
:重视数据集成,强调先同步数据至数据湖仓储,再进行业务面向的转换和设计。
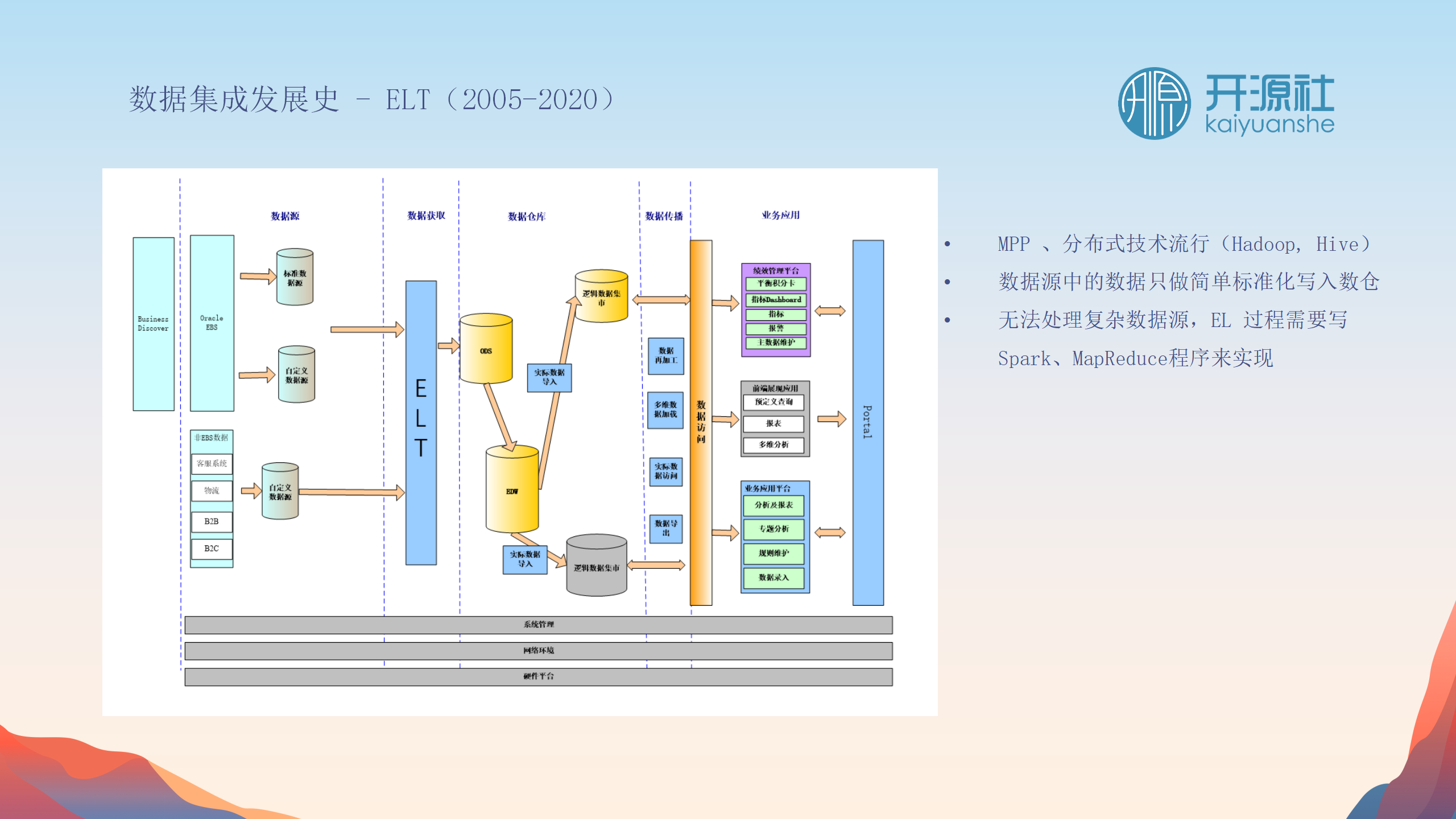
技术定位与挑战

Apache SeaTunnel在ELT环节中,主要解决简单的转换问题,并快速搬运数据。面临的挑战包括:
-
处理多样化的数据源和存储差异。
-
尽量减少对数据源的影响。
-
适应不同的数据集成场景,如离线和实时CDC同步。
-
保证数据集成的监控和量化指标。
重要特性
-
简单易用
:No code,通过配置文件提交作业。
-
运行监控
:提供详细的读写监控。
-
丰富的生态
:插件式架构,提供统一的读写API。
Apache SeaTunnel的发展历程
Apache SeaTunnel的前身是Whatdorp。它于2021年加入Apache孵化器,并在2022年发布了第一个版本。2022年10月,进行了重大重构,引入统一API。
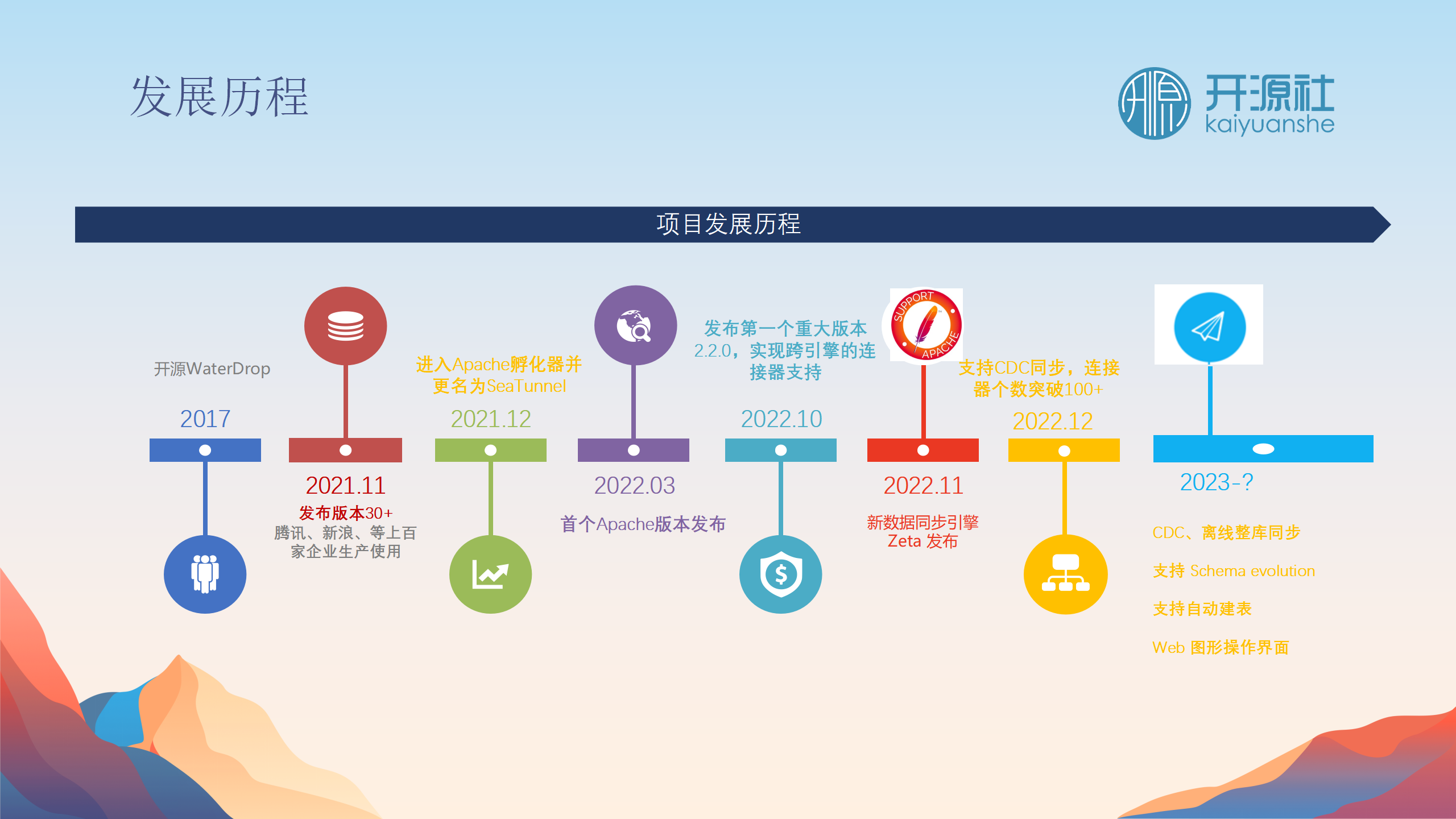
2022年11月,开发了专门用于数据同步的引擎。到2022年底,连接器的读写功能已经支持超过100种数据源。到2023年,主要集中于CDC和整库同步。

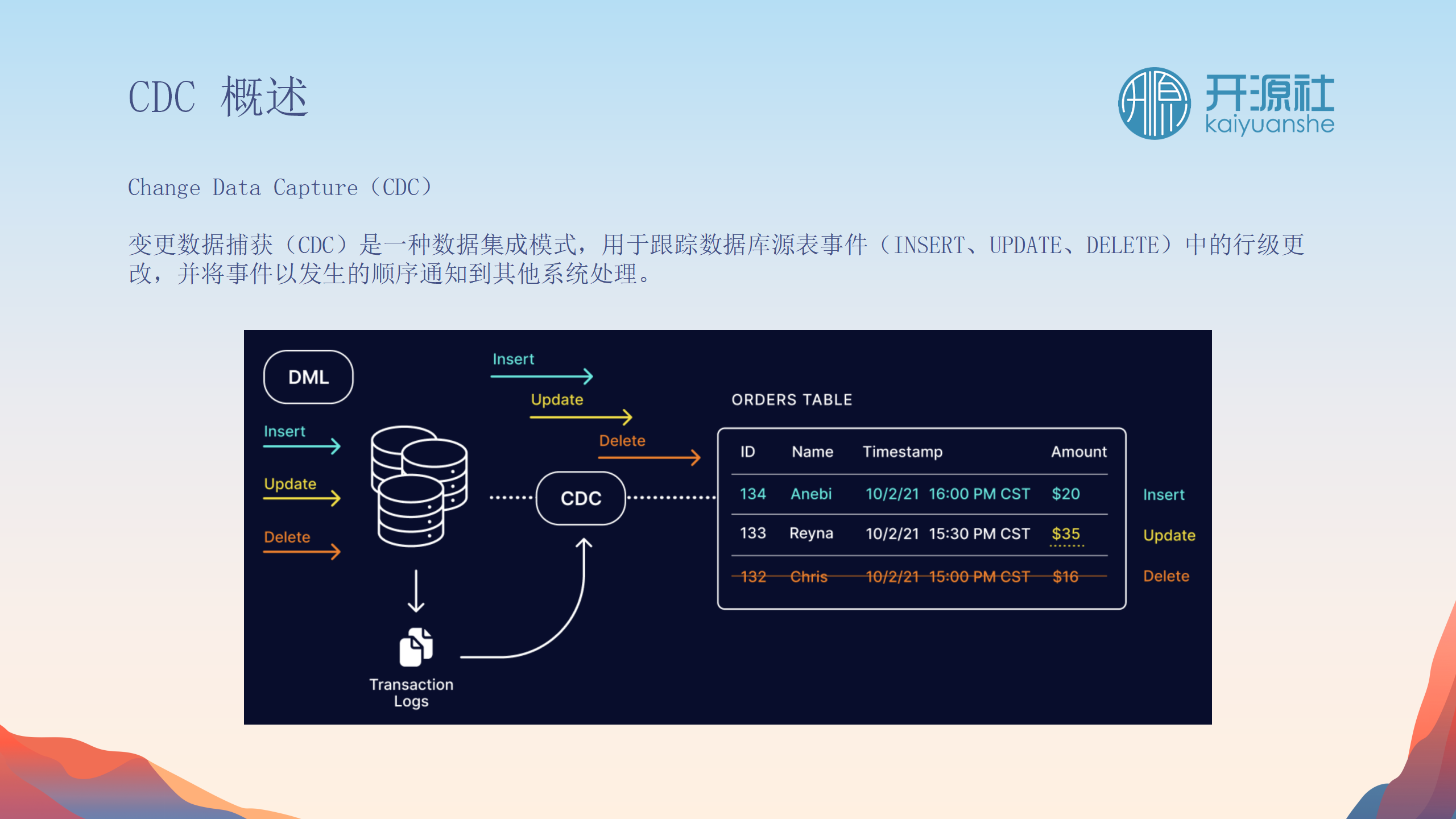
CDC(Change Data Capture)简介
 CDC,即变更数据捕获,是一种捕获数据库变更事件(如插入、更新、删除)的技术。在业务数据库中,数据不断变更,CDC的作用是捕获这些事件,并同步到数仓、数据湖或其他平台,确保目标存储与原始数据库保持一致。
CDC,即变更数据捕获,是一种捕获数据库变更事件(如插入、更新、删除)的技术。在业务数据库中,数据不断变更,CDC的作用是捕获这些事件,并同步到数仓、数据湖或其他平台,确保目标存储与原始数据库保持一致。
CDC的应用场景
-
数据复制
:如备库建设或读写分离。
-
数据分析
:在大数据平台进行基于BI的数据分析。
-
检索业务
:例如,将商品库或文档库同步到ES等检索平台。
-
操作审计
:记录系统变更,用于金融审计等。
常见的CDC方案的痛点
-
单表作业限制
:大多数开源方案中,一个作业通常只能处理一个表。
-
读取与写入分离
:一些平台专注于数据捕获,而另一些只负责数据写入。
-
多数据库支持问题
:不同的数据库可能需要不同的同步平台,增加了维护难度。
-
大规模表处理困难
:处理大型表时可能遇到性能瓶颈。
-
DDL变更同步
:实时同步数据库结构(DDL)变更是一个复杂且重要的需求。
Apache SeaTunnel在CDC中的应用
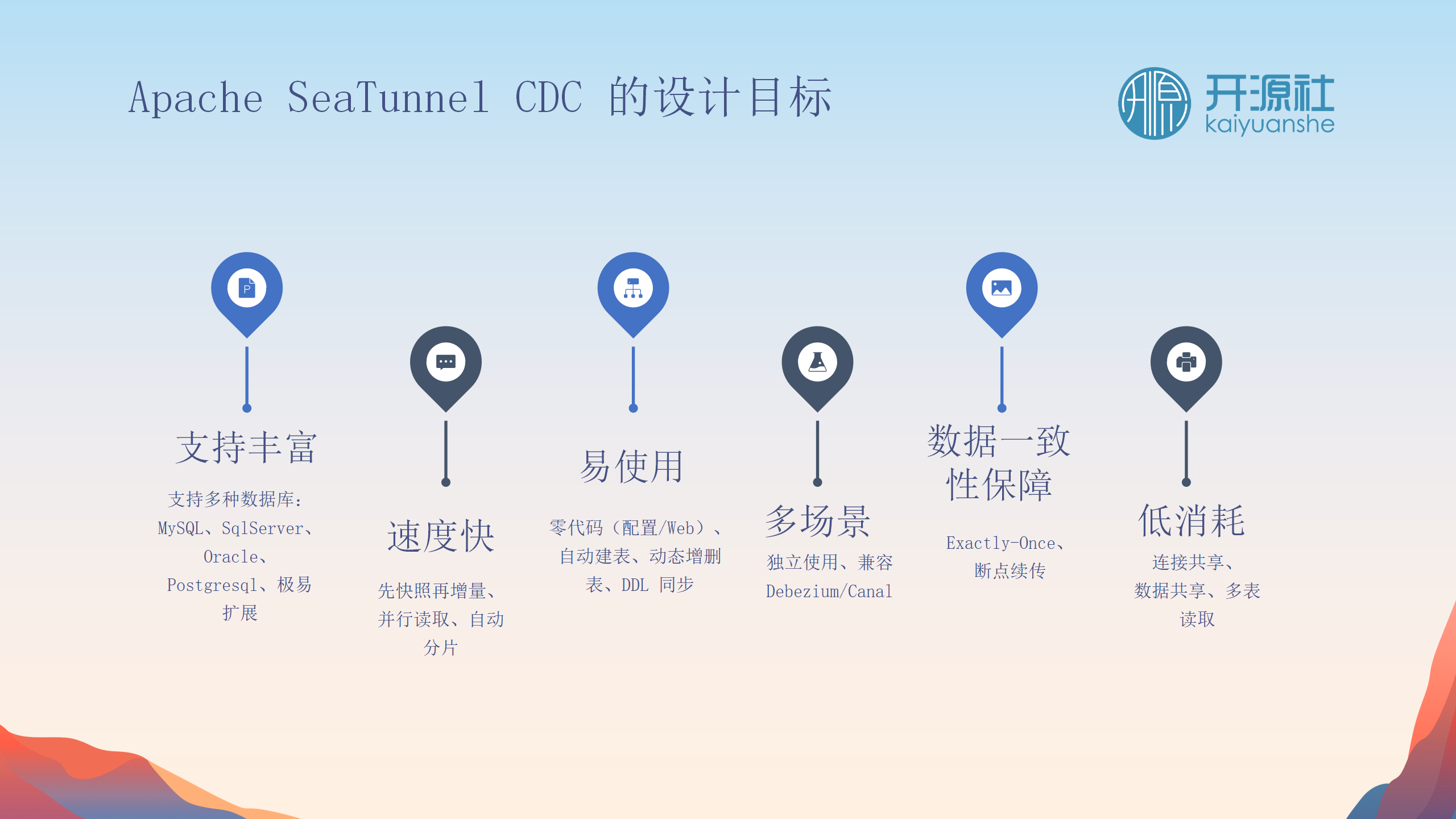 Apache SeaTunnel作为一个连接器,可以实现抽象的Source API和Sink API,即读写API,以实现数据的同步。它的设计目标是:
Apache SeaTunnel作为一个连接器,可以实现抽象的Source API和Sink API,即读写API,以实现数据的同步。它的设计目标是:

-
支持多种数据库
:如MySQL、Oracle等。
-
零编码
:自动建表和动态增删表,无需编写代码。
-
高效读取
:先进行数据快照,再跟踪binlog变化。
-
确保一致性
:实现exactly-once语义,即使在中断恢复情况下也不会出现数据重复。
Apache SeaTunnel CDC的设计实践重点
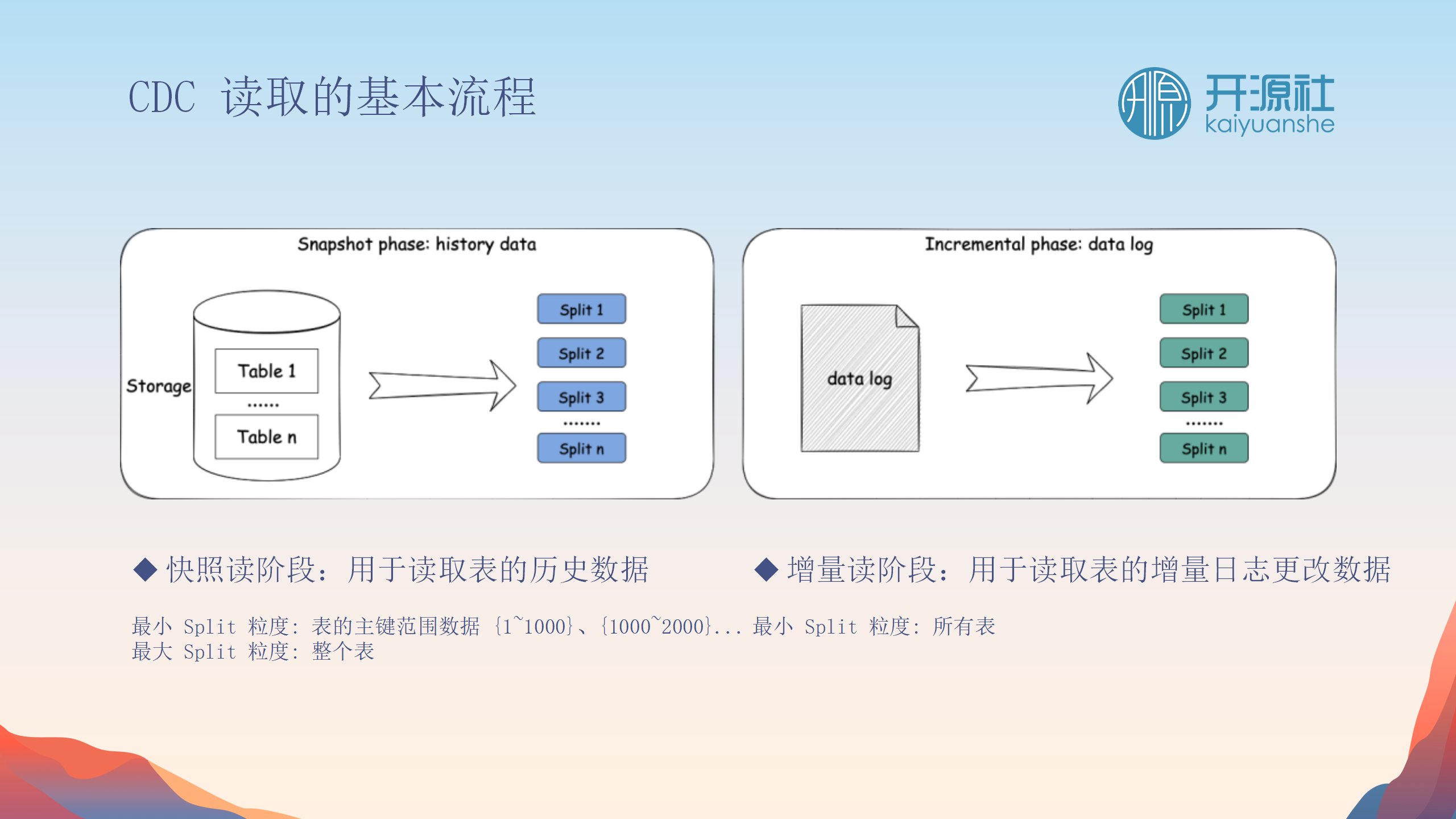 在于处理数据同步的两个阶段:快照读取和增量跟踪。
在于处理数据同步的两个阶段:快照读取和增量跟踪。

快照读取阶段
基本流程
-
Chunk划分(Splitting)
:为了高效同步大量历史数据,表被划分为多个chunk(或split),每个chunk处理一部分数据。
-
并行处理
:每个表分成多个split,这些split通过路由算法分配给不同的reader进行并行读取。
-
事件反馈机制
:每个reader在完成split读取后会向split分发器报告进度(watermark)。
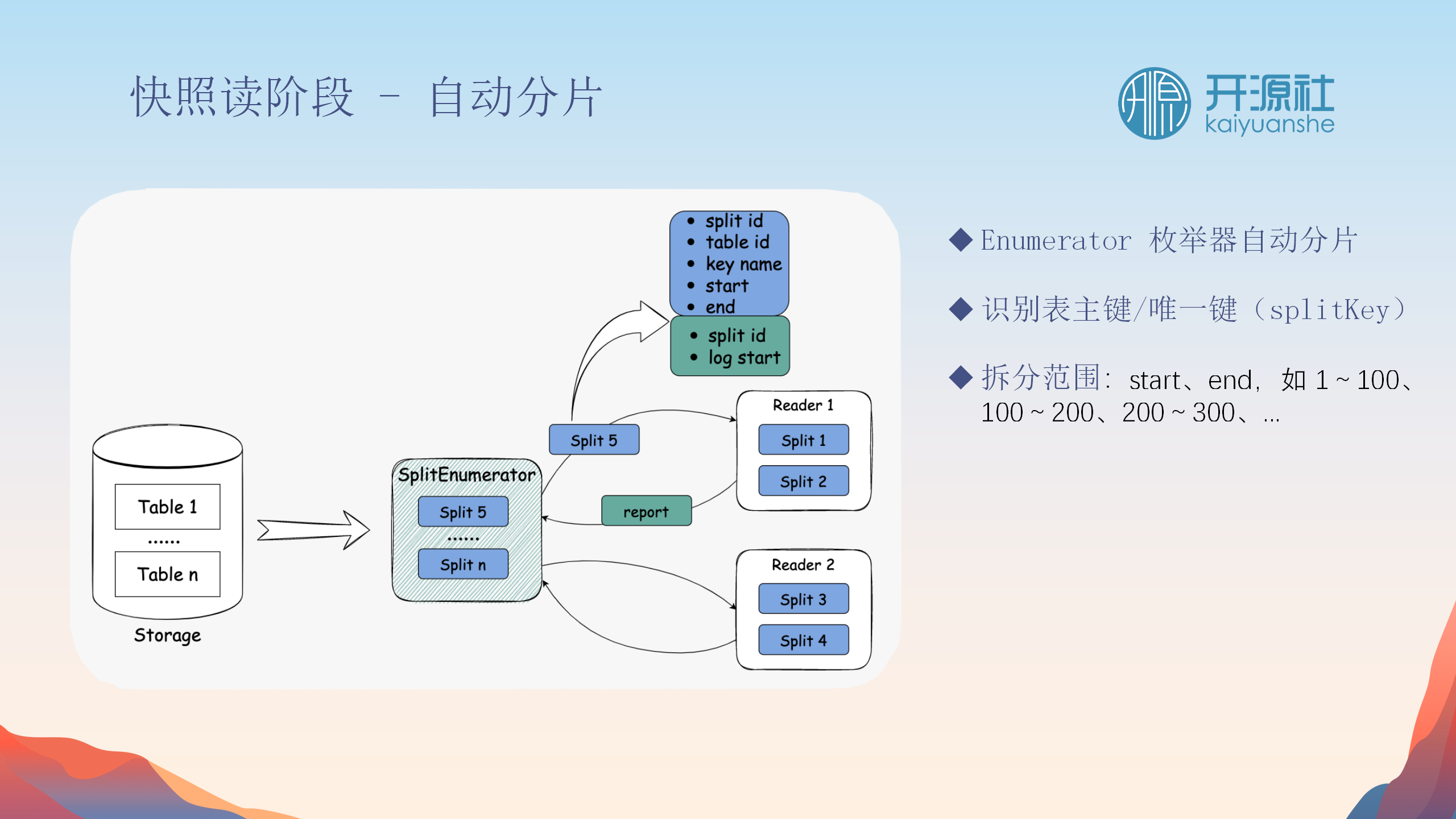
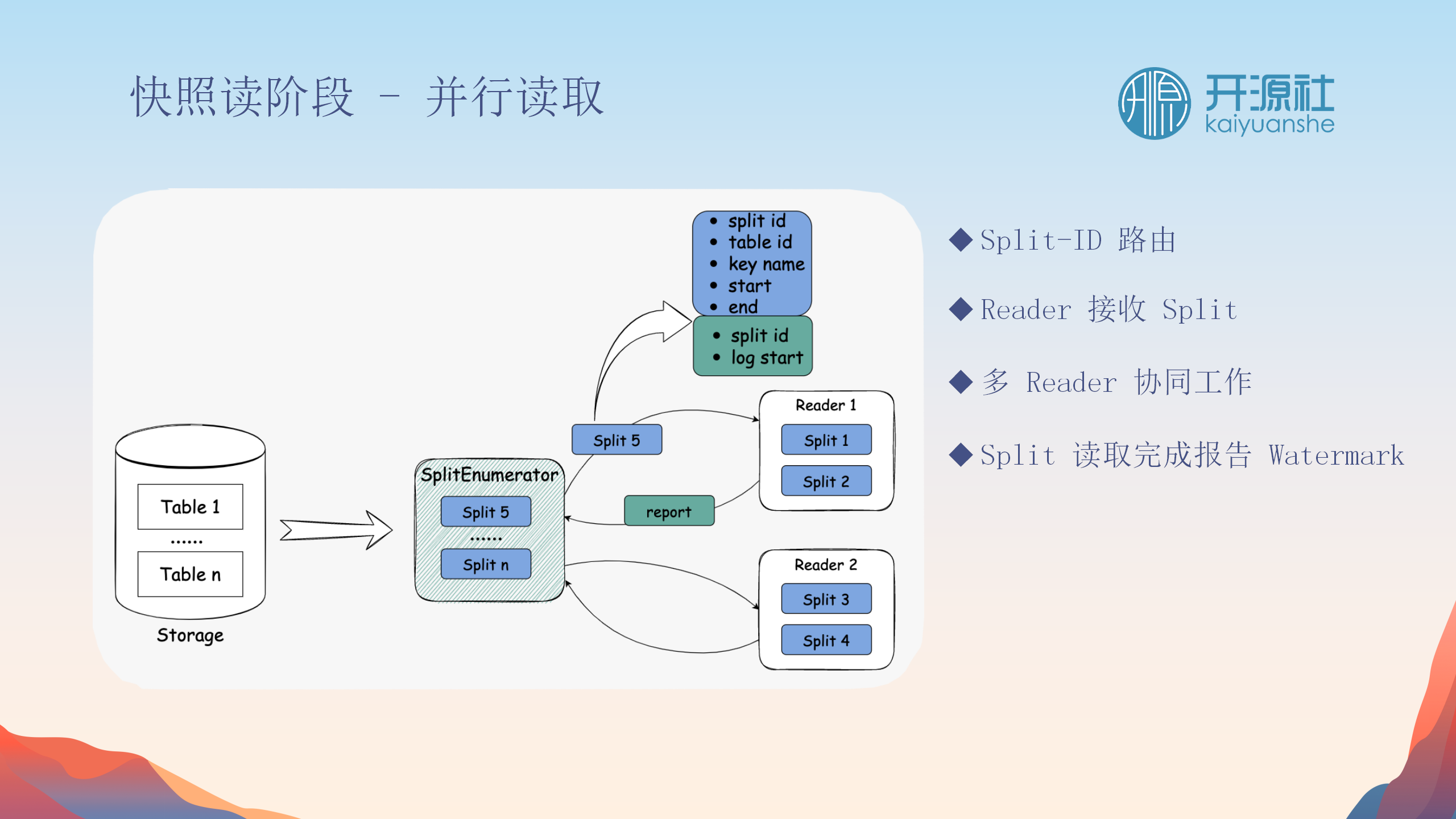
Split详解
-
组成
:Split包括唯一ID、指向的表ID、以及划分细节(如数据范围)。
-
划分方法
:Split可基于不同类型的列(如数字或时间)进行范围划分。
-
处理过程
:划分后的split被分发给reader,每个split的读取完成后会报告数据水位线。

增量跟踪阶段
单线程流读取
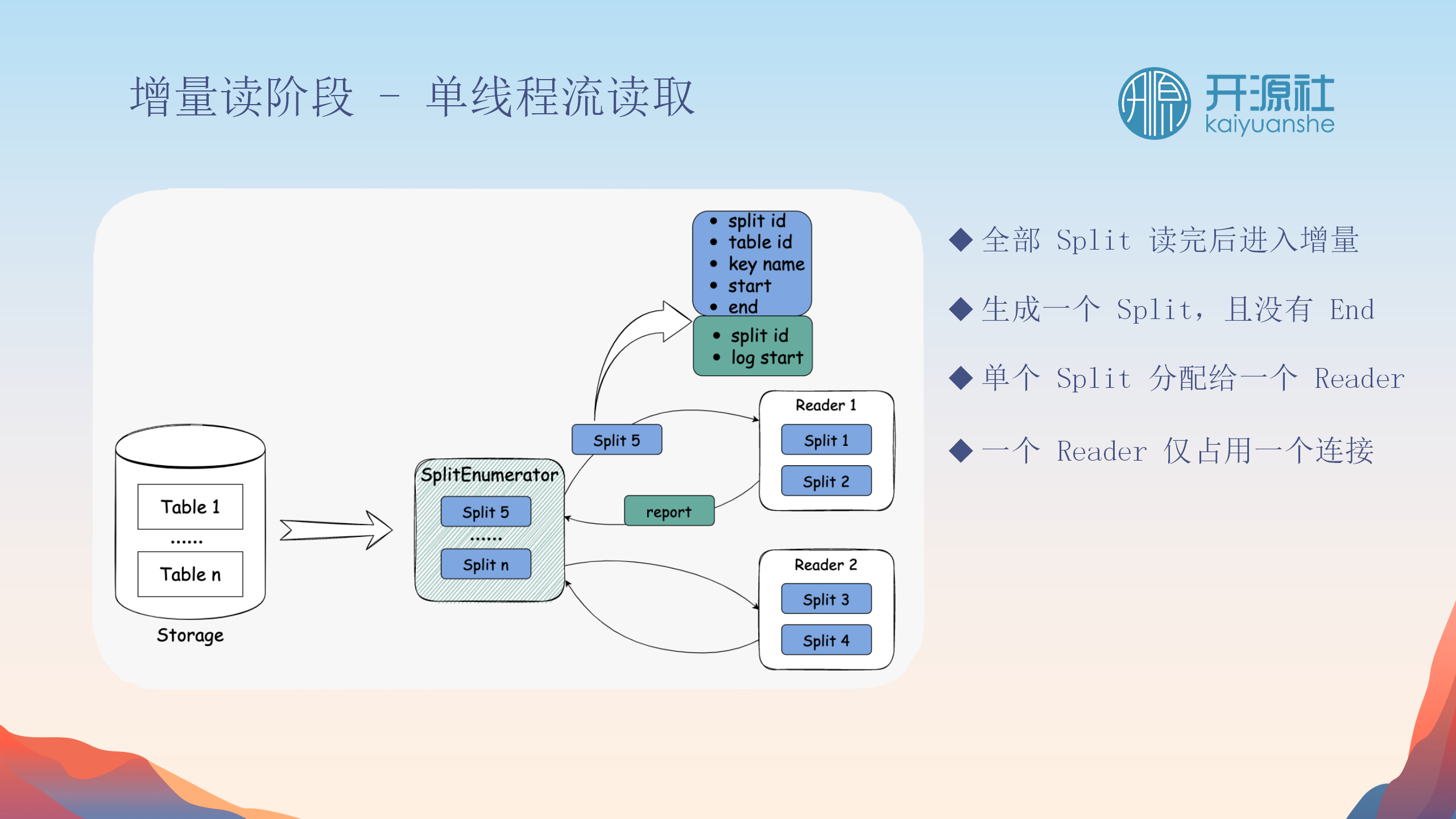
-
流读取特性
:与快照阶段的并行读取不同,增量跟踪通常为单线程操作。
-
减少业务压力
:避免重复拉取binlog,减轻对业务数据库的压力。


Split管理
-
无终止的Split
:增量阶段的Split没有结束点,意味着流读取是持续的。
-
水位线管理
:增量Split包含所有快照Split的最小水位线,从最小位置开始读取。
-
资源优化
:一个reader占用一个连接,保持高效且资源优化的数据跟踪。
Apache SeaTunnel CDC的设计允许有效地同步历史数据(快照读取)和实时变更(增量跟踪)。通过Split管理和资源优化策略,确保数据同步既高效又对原始数据库影响最小。
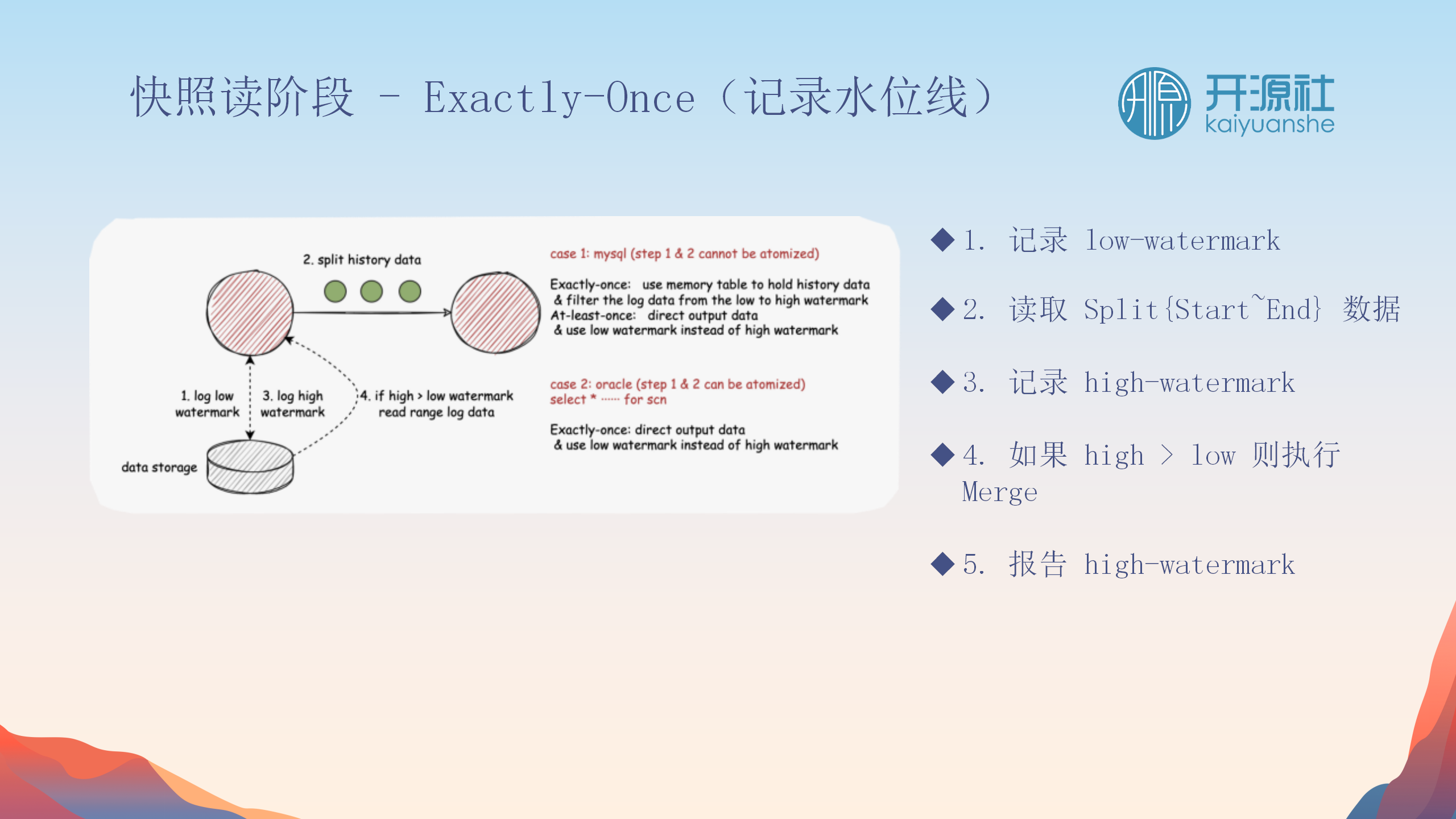
Apache SeaTunnel CDC的Exactly-Once实现
Apache SeaTunnel CDC实现Exactly-Once语义的核心在于处理数据同步中的不一致性和系统故障。
Exactly-Once的实现机制
快照读取的水位线管理
-
低水位与高水位
:在快照读取时,首先记录低水位线,读取结束后记录高水位线。这两个水位线之间的差异表明数据库在此期间发生了变化。
-
内存表合并
:低水位和高水位之间的变更会被合并到内存表中,确保未遗漏任何变更。
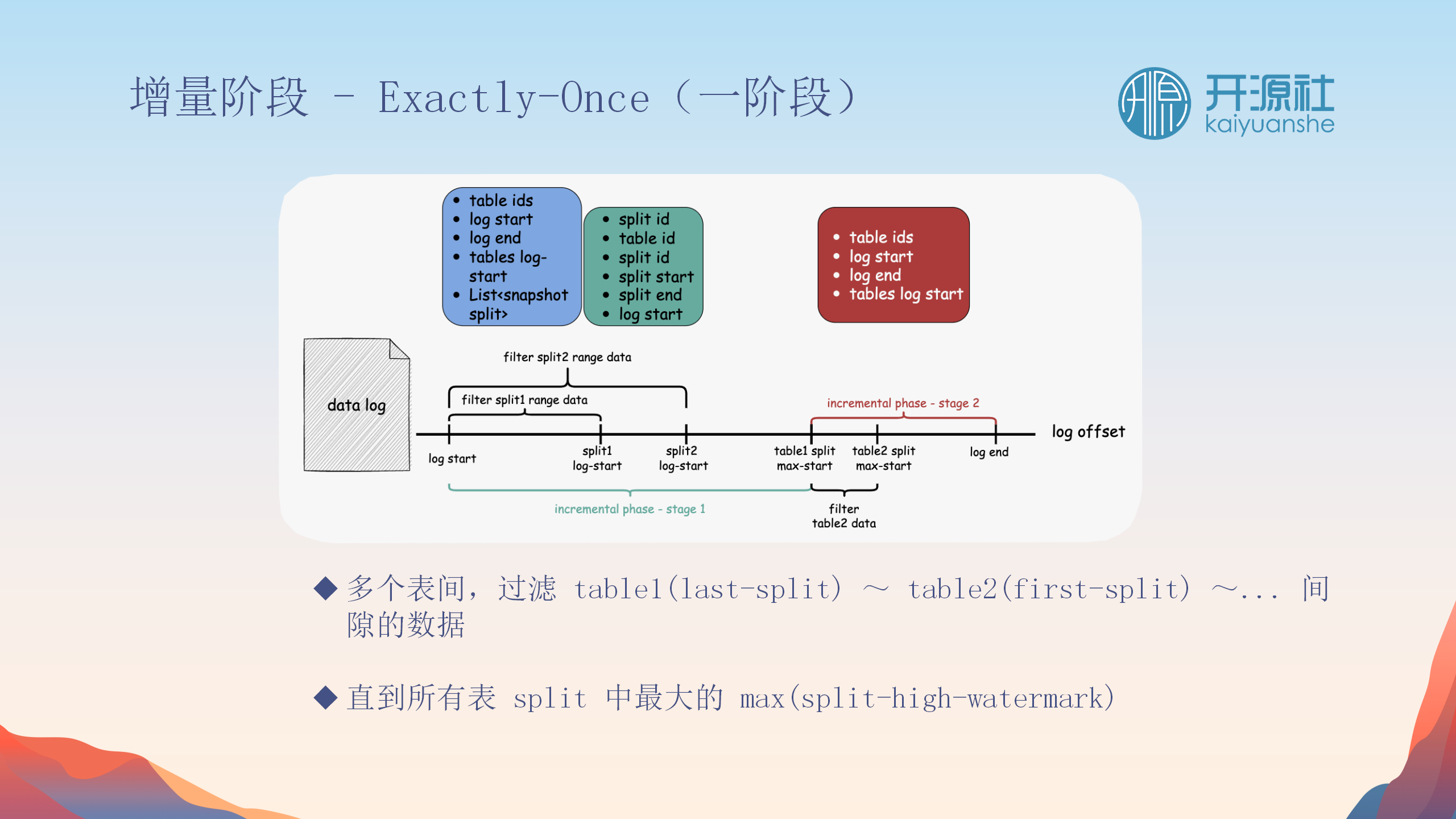
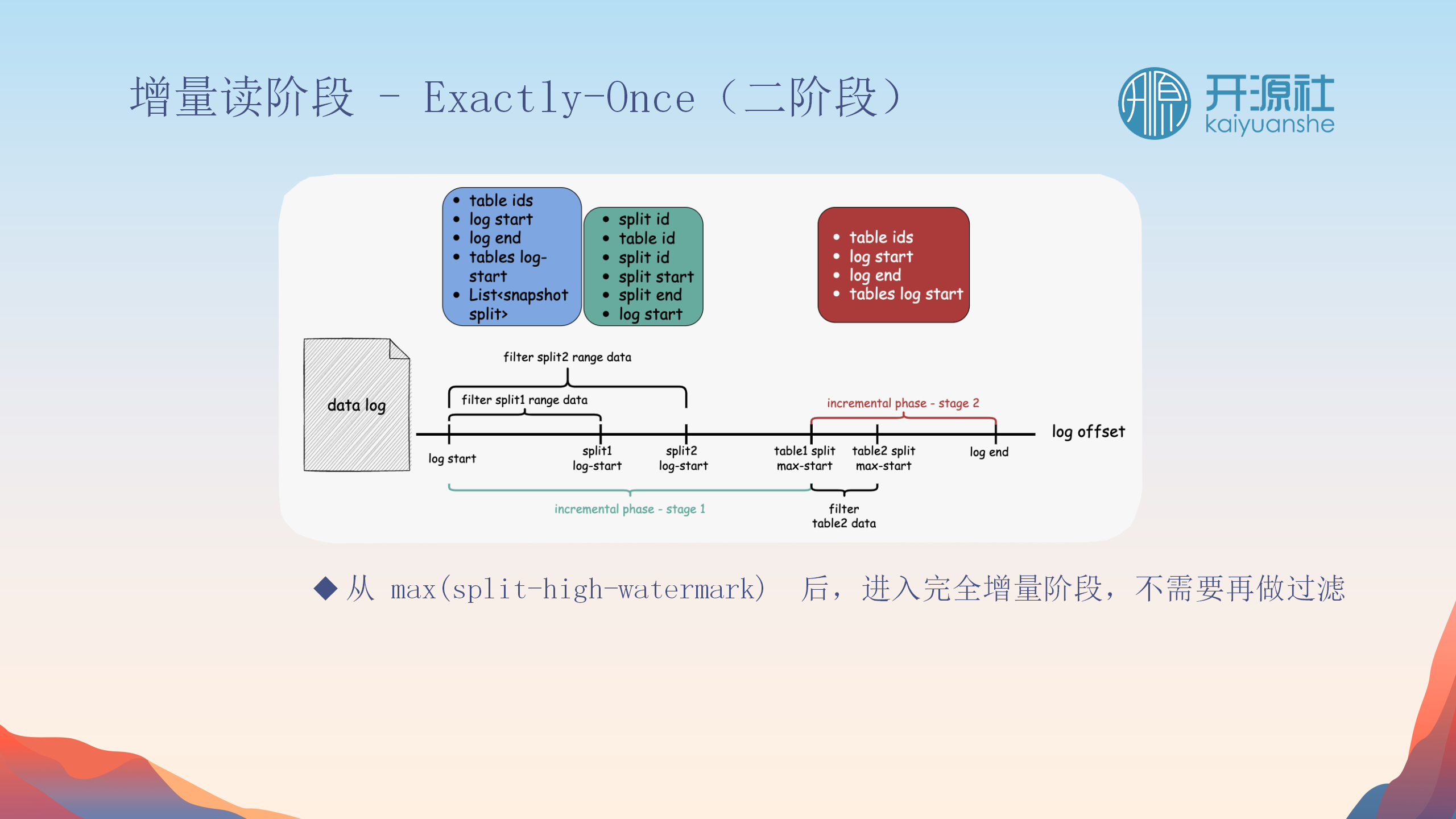
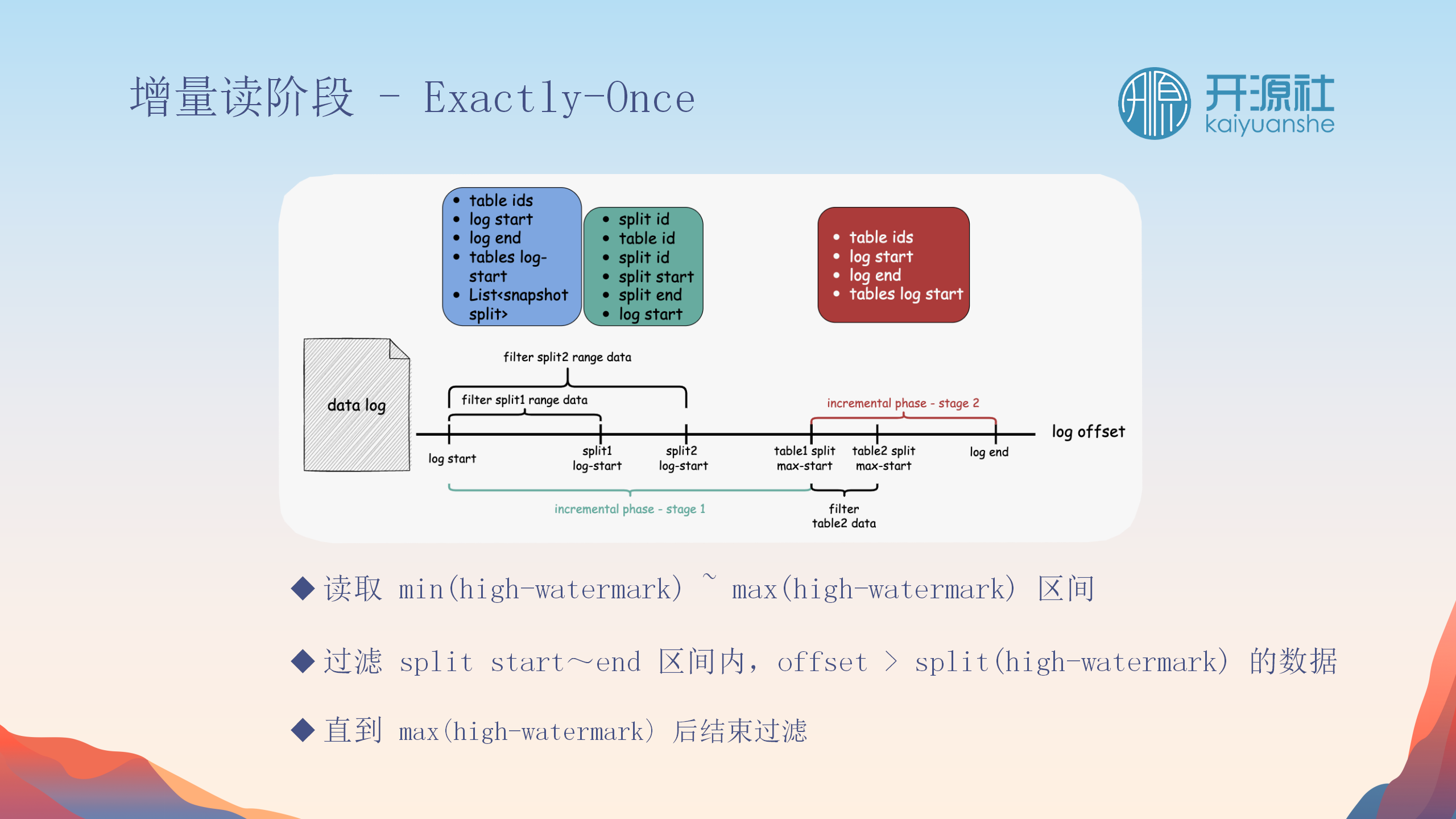
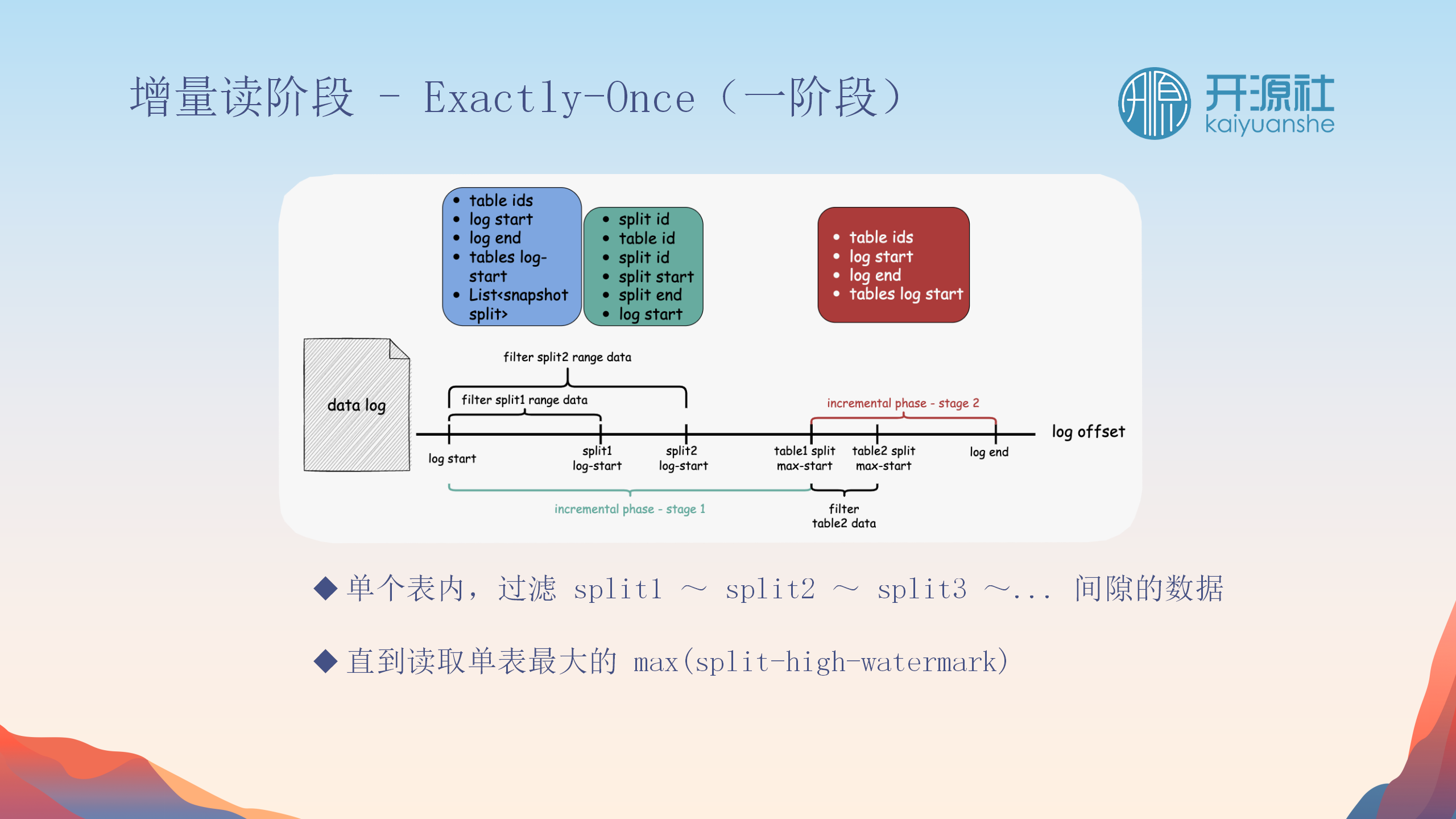
Split与Split之间的间隙处理
-
处理数据间隙
:处理Split间的数据间隙,确保没有遗漏变更。
-
反向过滤与回捞
:快照阶段的每个数据点都会检查以确保没有被之前的Split覆盖,避免数据重复。
-
阶段性校对
:分为两个阶段(Stage 1和Stage 2),分别处理Split间的间隙和表间的间隙,确保所有变更都被捕获。
断点续传与分布式快照
分布式快照机制

-
不同引擎适配
:分布式快照API适配不同的执行引擎,确保状态一致性。
-
检查点保存
:定期发起检查点保存操作,所有组件上传自己的状态,保存完整的检查点状态。
-
恢复选择
:在恢复时,可以选择任何一个检查点版本进行恢复。
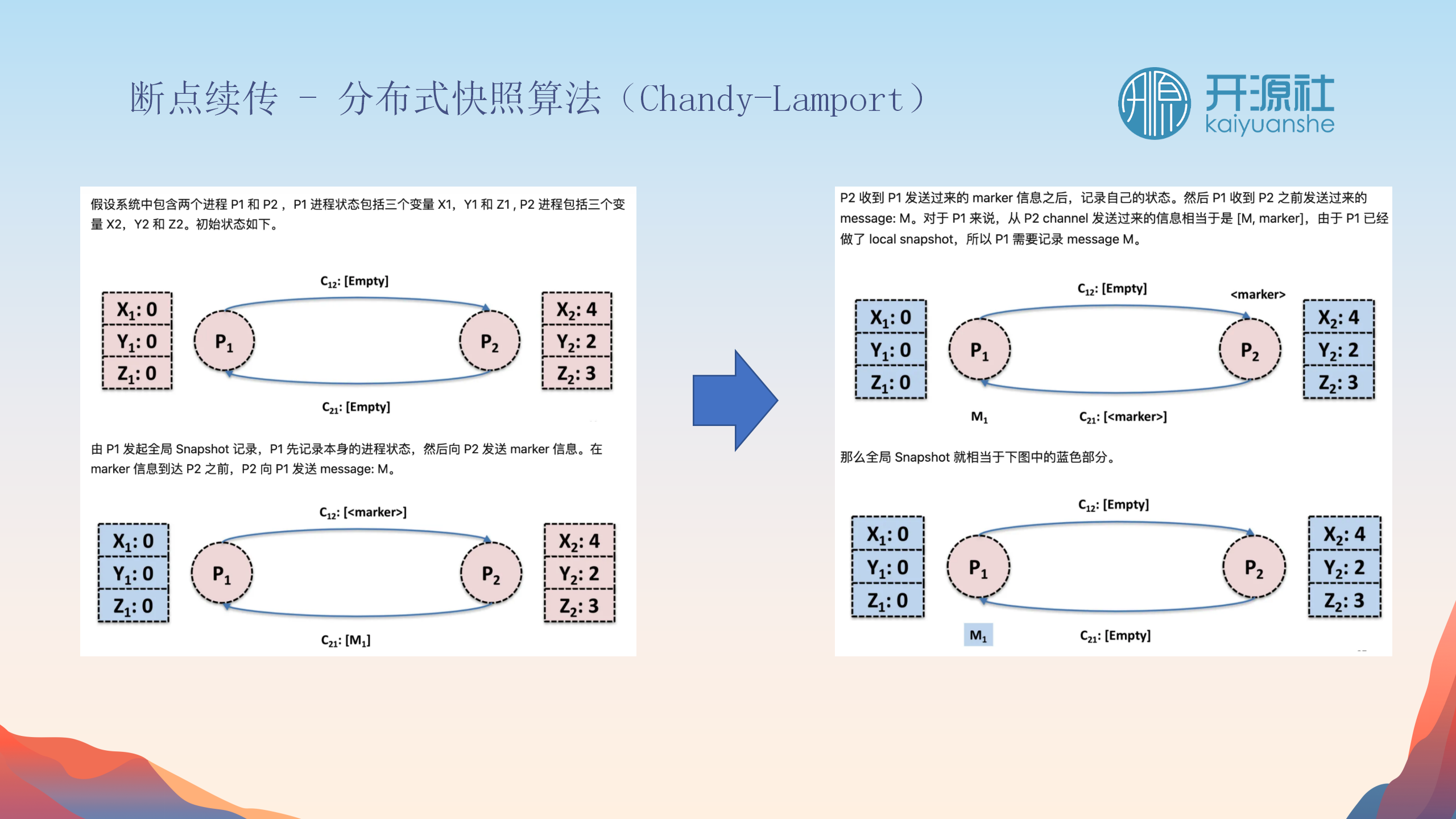
分布式状态对齐
-
进程间状态同步
:处理多个进程内的不同内存状态,确保它们在一个时间点达到一致状态。
-
信号传播与保存
:从一个进程发起分布式快照信号,其余进程根据信号保存自己的状态并传递信号,直至所有节点状态对齐。
-
实际应用
:在CDC任务中,枚举器节点、读取节点、写入节点均参与这一过程,保证整个数据同步过程的状态一致性。
DDL同步的深入探讨
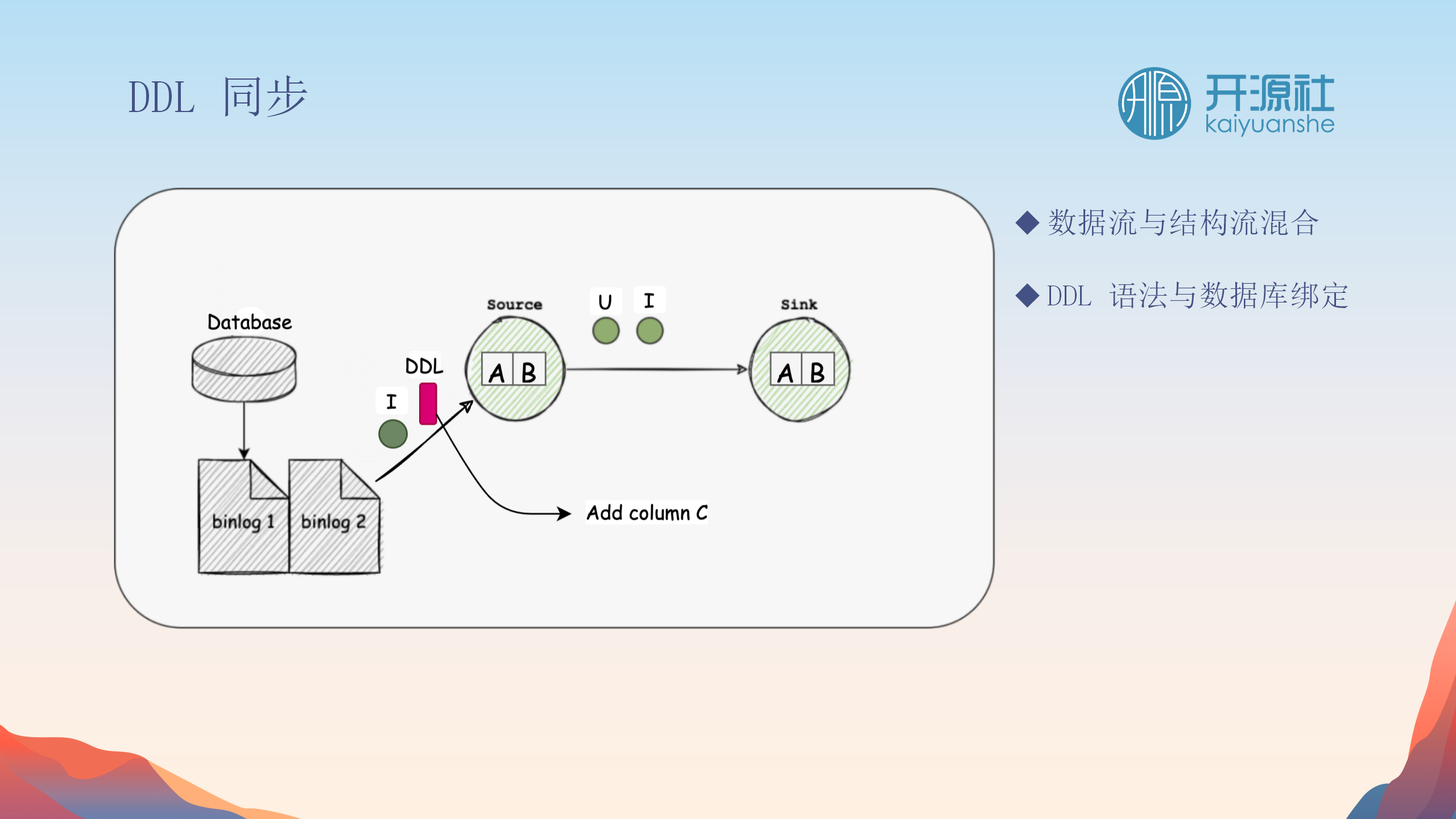
在Apache SeaTunnel CDC中,DDL同步是一个关键的挑战。由于数据库结构可能在数据流处理过程中发生变化,因此必须谨慎处理这些变更。
DDL解析与抽象化
-
DDL事件解析
:DDL事件首先被解析并转换为结构化的抽象形式,这样做的目的是将DDL处理过程与特定数据库的语法细节解耦。
-
结构化事件处理
:例如,添加列的操作被转换为一个通用的结构化事件,不再依赖于具体数据库的语法。
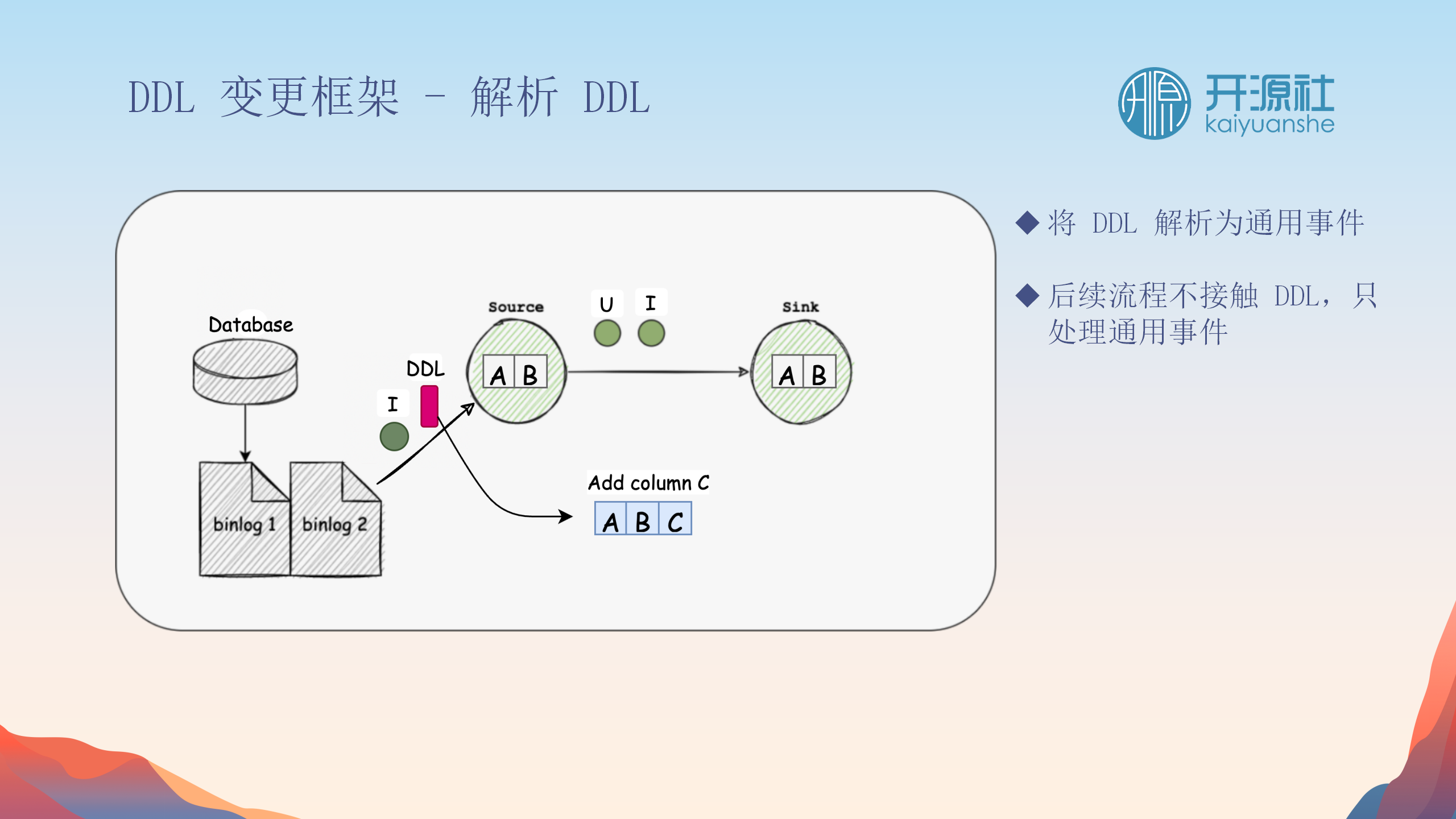
数据流与结构流的分离
-
信号插入
:在DDL操作前后,系统会插入特定的信号以分离结构流和数据流。这样做允许在DDL操作期间暂停数据处理,避免在结构变更期间发生数据混乱。
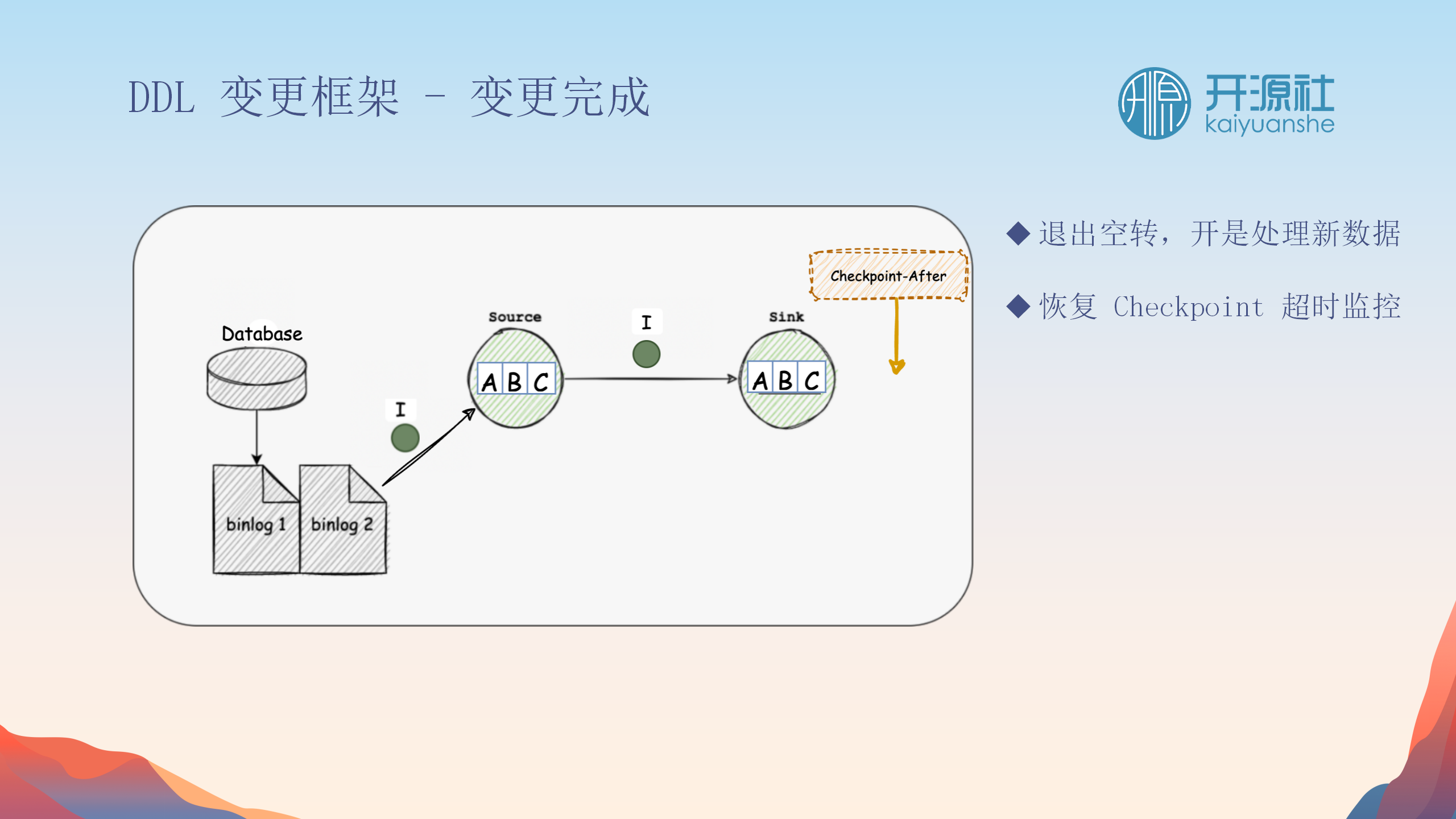
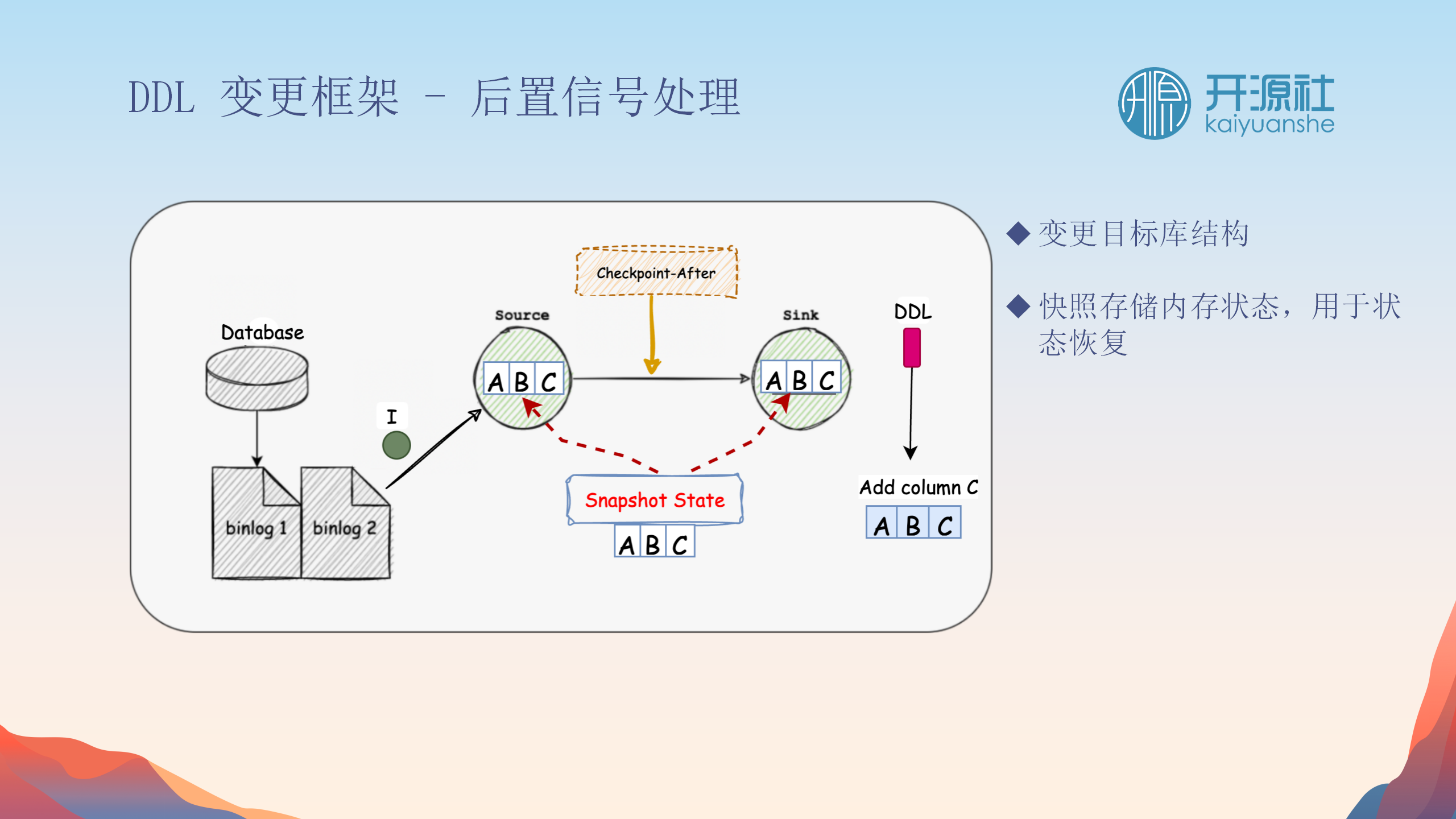
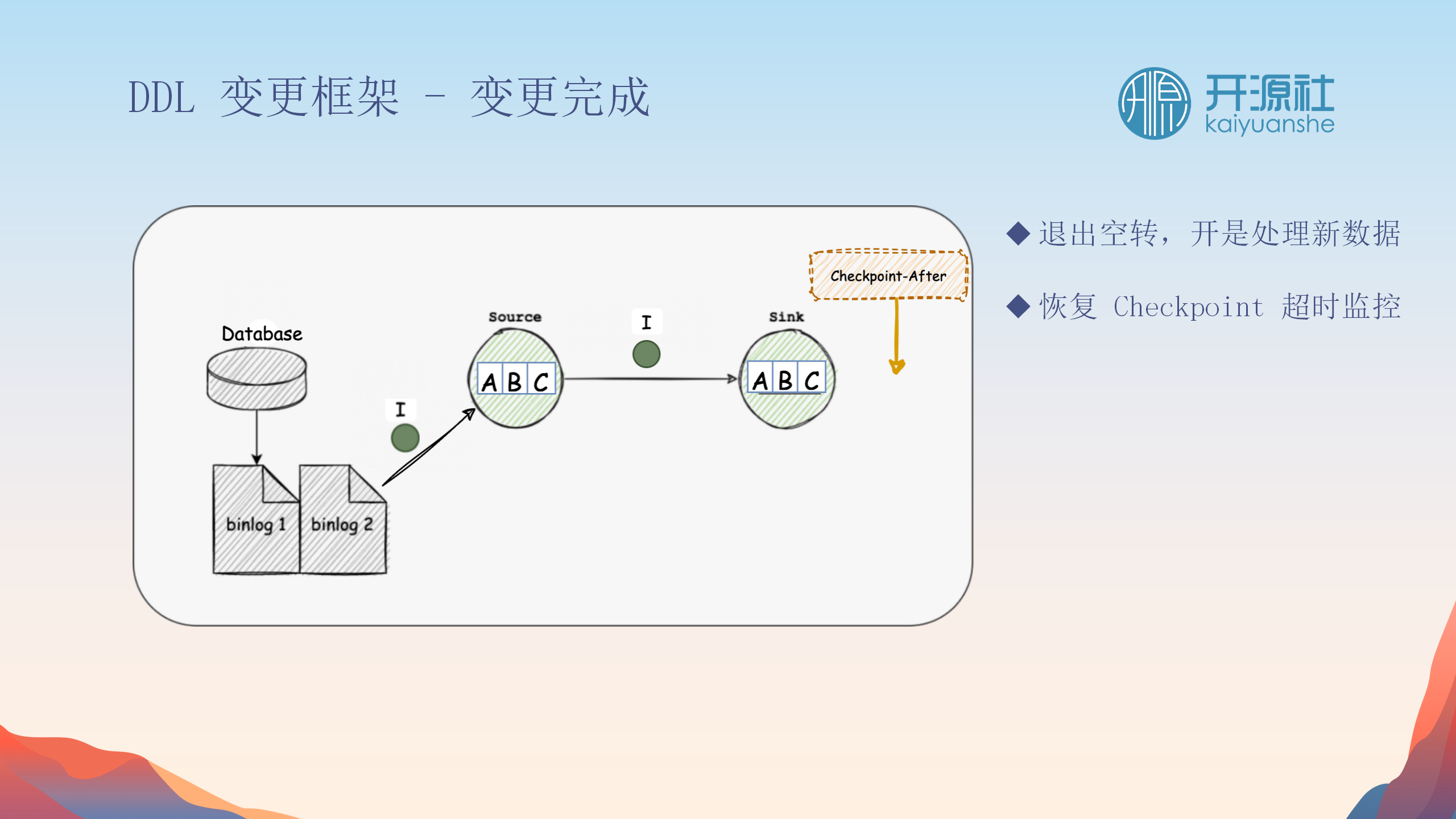
前置与后置信号处理
-
前置信号
:在DDL操作前,清空内存中的数据状态,并暂停数据处理,以确保结构变更前的数据完整性。
-
后置信号
:DDL操作完成后,系统恢复数据处理,并继续之后的数据同步。
数据传输的细节优化
 在数据传输方面,Apache SeaTunnel CDC通过一系列优化,确保数据同步的效率和一致性。
在数据传输方面,Apache SeaTunnel CDC通过一系列优化,确保数据同步的效率和一致性。
数据操作的类型化处理
-
插入(Insert)
:处理新增数据,仅涉及操作后的状态。
-
更新(Update)
:涉及操作前后的状态变化,需要精确处理以确保数据一致性。
-
删除(Delete)
:只关注操作前的状态,因为数据在操作后不再存在。
高效的数据流管理
为了提高效率,CDC在数据流管理方面做了大量优化:
-
表级数据拆分
:保证同一表内的数据处理的有序性。
-
键级数据排序
:同一键的数据操作按顺序处理,保证数据状态的正确性。
-
并行数据写入
:同一表内的数据可以并行写入,提高了数据处理的速度。
更新优化
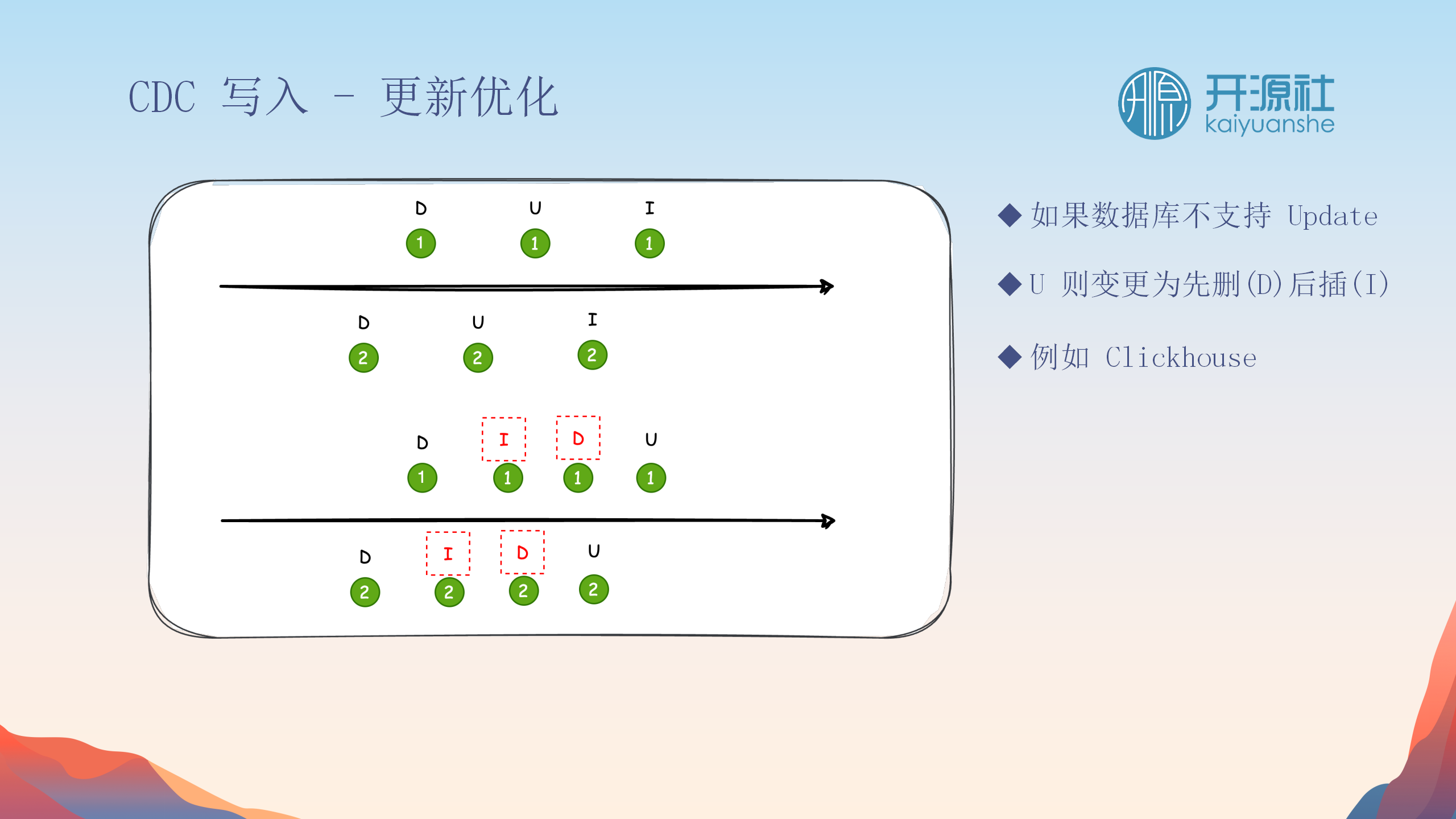
对于不支持更新操作的目标存储,CDC采取了一种优化策略:将更新操作转换为先删除后插入操作,从而绕过存储的限制。
共享挖掘与多目标写入
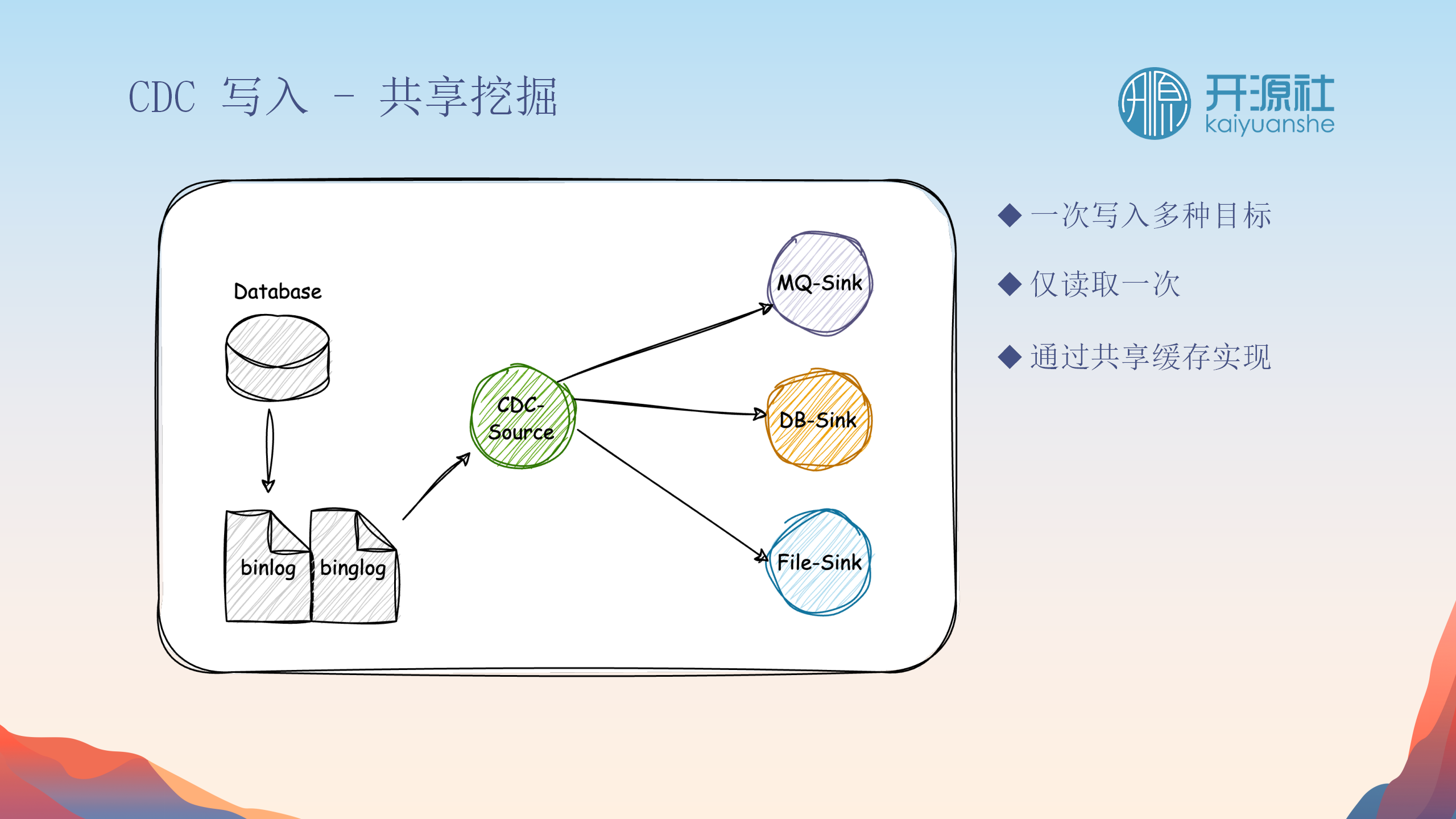
为了减少对原始数据源的负担,CDC采用共享挖掘机制。这意味着数据被一次读取,然后共享给多个写入插件,允许数据被写入到多个目标存储。这种方法有效地整合了原本分散的数据读写流程,提升了整体效率。
自动建表
目的
-
自动转换
:将原库的表结构自动转换到目标库,适用于不熟悉业务库表结构或表数量庞大的场景。
实现过程
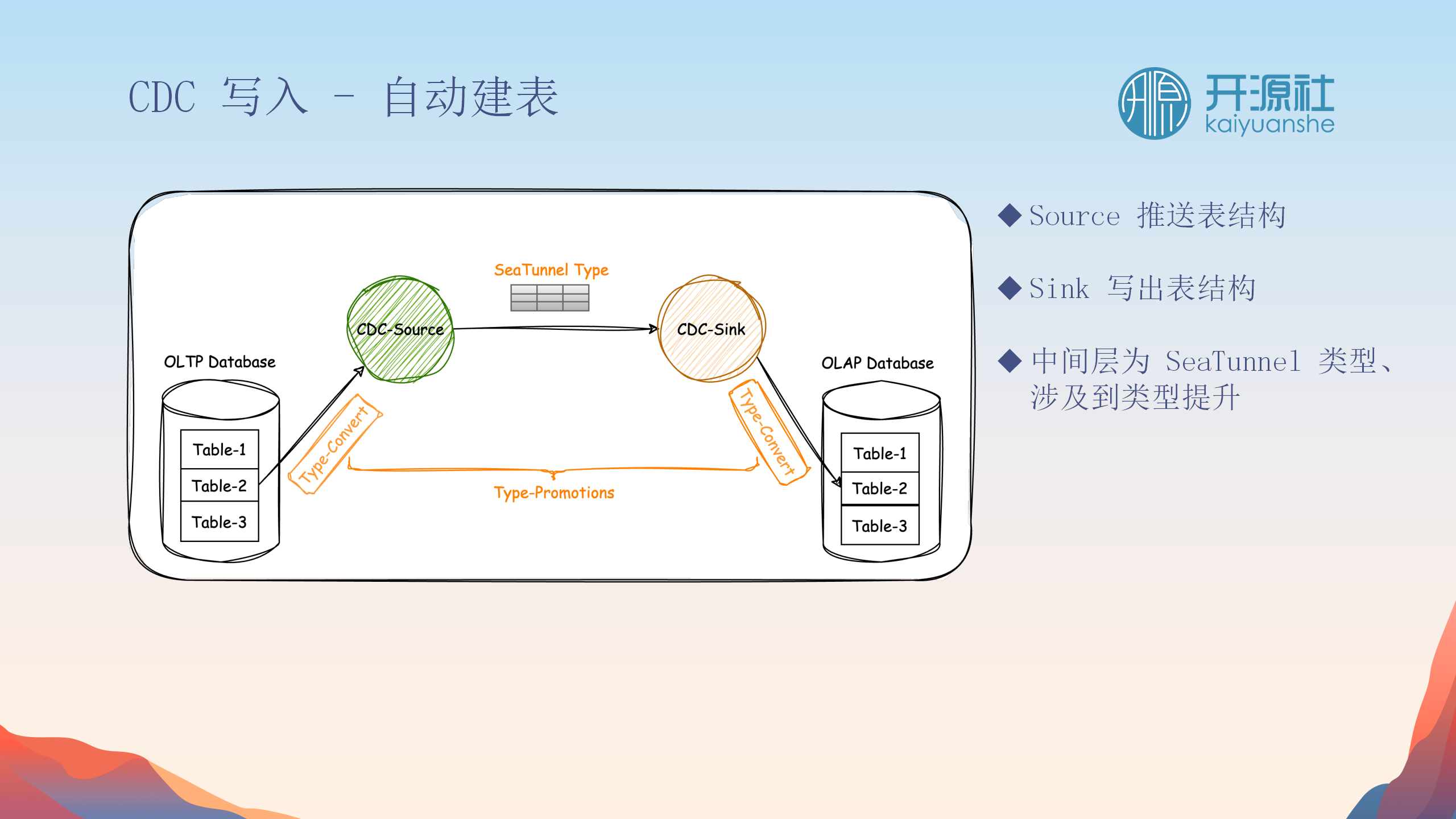
-
表结构推送
:将配置的所有表转换为通用的数据类型和表结构。
-
与写入插件的交互
:启动时,插件接收表结构,检查并在目标库创建或更新表。
-
类型提升
:处理异构数据库中的类型不匹配问题,如将小类型提升到大类型。
社区发展与参与

当前发展
-
多表读写
:推进多表和多引擎支持。
-
API推广
:将自动建表等API推广到社区,实现在各插件中。
-
连接器升级
:升级连接器以支持新的多表读写功能。
-
DDL解析
:开发支持目标端表结构的DDL解析功能。
Web界面
-
发布与完善
:发布并持续完善,支持不同数据库的数据查询和同步任务配置。
社区参与
-
加入社区
:通过官方微信公众号或加入中文用户群获取更多支持。
-
在线资源
:通过项目的issue系统、Slack频道或官网获取资源和支持。
-
贡献与沟通
:下载试用、报告bug、查看新手任务,或通过邮件列表和Slack进行沟通。

本文由
白鲸开源科技
提供发布支持!