论文:ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric
Convolution Blocks
论文链接:https://arxiv.org/abs/1908.03930
代码链接:https://github.com/DingXiaoH/ACNet
图像分类领域,从VGG到DenseNet那几年是比较活跃的,最近两年这个领域的论文越来越少见了,要做出有影响力的工作也越来越难。而这两年这个领域的主要方向集中在:1、网络结构搜索,比如EfficientNet算目前效果比较好的代表作。2、更好的特征表达,这部分跟第一部分并不是完全独立的,主要是把特征复用、特征细化做得更加极致,代表作有HRNet、Res2Net等。
当然,以上这些不是这篇博客要讲的内容,这篇博客要介绍的是ICCV2019上的一篇论文:ACNet,全称是Asymmetric Convolution Net,翻译过来就是非对称卷积网络。这篇论文也是从更好的特征表达角度切入实现效果提升,不过更重要的是:没有带来额外的超参数,而且在推理(或者叫验证、部署,本质上都是只执行前向计算)阶段没有增加计算量,在我看来后者更有吸引力。
在开始介绍ACNet之前,先来看一个关于卷积计算的式子,式子中I表示一个二维矩阵,可以看做是卷积层的输入,也就是输入特征图,K(1)和K(2)分别表示2个二维卷积核,这2个卷积核的宽和高是一样的,那么下面这个式子的意思就是:先进行K(1)和I卷积,K(2)和I卷积后再对结果进行相加,与先进行K(1)和K(2)的逐点相加后再和I进行卷积得到的结果是一致的。这是ACNet能够在推理阶段不增加任何计算量的原因。
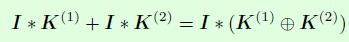
接下来直接通过Figure1来看ACNet的思想。整体上ACNet的思想分为训练和推理阶段,训练阶段重点在于强化特征提取,实现效果提升;推理阶段重点在于卷积核融合,实现0计算量增加。
训练阶段:因为3
×
\times
× 3尺寸的卷积核是目前大部分网络的标配,所以这篇论文的实验都是针对3
×
\times
× 3尺寸进行的。训练阶段简单来说就是将现有网络(假设用Net_origin表示,比如ResNet)中每一个3
×
\times
× 3卷积层替换成3
×
\times
× 3+1
×
\times
× 3+3
×
\times
× 1共3个卷积层,如Figure1左图所示,最后将这3个卷积层的计算结果进行融合得到卷积层输出。因为引入的1
×
\times
× 3和3
×
\times
× 1卷积核尺寸是非对称的,所以取名Asymmetric Convolution。
推理阶段:这部分主要就是做3个卷积核的融合。依据就是前面我们介绍的公式:先分别对输入进行卷积后融合结果,与先融合卷积核再对输入进行卷积,结果是一样的。这部分在实现上是用融合后的卷积核参数初始化现有网络:Net_origin,因此在推理阶段,网络结构和原始网络是一模一样的(没有1
×
\times
× 3和3
×
\times
× 1卷积层了),只不过网络参数采用特征提取能力更强的参数(融合后的卷积核参数),因此在推理阶段不会增加计算量。

到此其实ACNet的内容就基本介绍完了,总结下来就是训练阶段强化特征提取能力,推理阶段融合卷积核达到不增加计算量的目的,虽然训练时间会增加一些,但推理阶段不费一兵一卒就能提升效果,方便且适用于现有的分类网络,何乐而不为。
当然,我觉得这篇论文的精彩之处不仅仅是以上这些思想,论文中关于训练阶段将1个3
×
\times
× 3卷积层替换成3
×
\times
× 3、1
×
\times
× 3和3
×
\times
× 1这3个卷积层的组合可以提升效果的讨论依然言之有理。
在公开数据集上其实ACNet并没有非常明显的效果提升,比如Table3,对于常用的ResNet和DenseNet而言,提升不到1个百分点,只不过至少是白赚的:

但正如论文中所述,ACNet有一个特点在于提升了模型对图像翻转和旋转的鲁棒性。
Figure4从理论上解释这种鲁棒性,当在训练阶段引入1
×
\times
× 3卷积核时,即便在验证阶段将输入图像进行上下翻转,这个训练好的1
×
\times
× 3卷积核仍然能够提取正确的特征(如Figure4左图所示,2个红色矩形框就是图像翻转前后的特征提取操作,在输入图像的相同位置处提取出来的特征还是一样的)。
假如训练阶段只有3
×
\times
× 3卷积核,那么当图像上下翻转后,(如Figure4右图所示,2个红色矩形框就是图像翻转前后的特征提取操作,在输入图像的相同位置处提取出来的特征是不一样的)。
因此,引入类似1
×
\times
× 3这样的水平卷积核可以提升模型对图像上下翻转的鲁棒性,竖直方向卷积核同理。

Table4从实验上解释这种鲁棒性。需要注意的是rotate 180°和左右翻转是不一样的,rotate 180°实际上是上下翻转+左右翻转,所以个人认为Table4中加上上下翻转的实验会更完整一些。

有一个点比较有意思,在论文中提到具体的融合操作是和BN层一起的,如Figure3所示,注意融合操作是在BN之后。但假其实也可以把融合操作放在BN之前,也就是3个卷积层计算完之后就进行融合。论文中关于这二者的实验可以参考Table4,在Table4中BN in branch这一列有√的话表示融合是在BN之后,可以看到效果上确实是在BN之后融合要更好一些(AlexNet的56.18% vs 57.44%,ResNet-18的70.82% vs 71.14%)。
不过论文中没有看到这部分的原理讨论,个人理解这部分效果的差异是因为增加了不同尺寸卷积核的权重导致的,统一的BN层没有更细化的针对每个特征图的BN来得极致。
另外即便融合操作放在BN层之前,相比原始网络仍有一定提升(AlexNet的56.18% vs 55.92%,ResNet-18的70.82% vs 70.36%%),这部分的原因个人理解是来自梯度差异化,原来只有一个3
×
\times
× 3卷积层,梯度可以看出一份,而添加了1
×
\times
× 3和3
×
\times
× 1卷积层后,部分位置的梯度变为2份和3份,也是更加细化了。而且理论上可以融合无数个卷积层不断逼近现有网络的效果极限,融合方式不限于相加(训练和推理阶段一致即可),融合的卷积层也不限于1
×
\times
× 3或3
×
\times
× 1尺寸。

整体上ACNet的创新点还是很棒的,相信对很多领域都会有启发意义,期待后面更多意思的工作。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)