题目类型:
判断20分(10题)
单选20分(10题)
简答30分(5题)
问答/计算30分(3题)
1. ARPANET的主要设计原则
1.1 最基本目标:连接不同的网络
1.1.1 不同网络连接的需求
(1)无线分组网络介入并使用ARPANET中的计算资源
(2)连接不同类型(传输介质)的局域网络
(3)连接具有不同管理机构的网络
1.1.2 协议设计采用ARPANET中已证明有效的技术
(1)分组交换,而不是电路交换,更加适合远程登陆应用
(2)基于存储转发的网关设备
1.2 二级目标(基于优先级排列)
(1)在网络和网关失效情况下保持通信的持续性
(2)支持多种类型的通信服务
(3)支持多种类型的物理网络
(4)允许资源的分布式管理
(5)高性价比
(6)方便地支持主机接入
(7)资源使用是可统计的
1.3 缺少的设计目标
(1)安全性
(2)移动性
(3)可扩展性
(4)服务质量保证
2. 知识平面(KP)和知识定义网络(KDN)原理及实现挑战
2.1 知识平面
(1)分布式认知系统,赋予网络“思维能力”
①分布式组成架构+多尺度全局视野
②解决网络故障的自动修复、复杂网络的自动配置、深层次安全威胁的发现等问题
(2)技术途径
通过传感器(sensor)来收集网络状态信息,智能处理,通过执行器(actuator)来改变网络的行为,如更改路由表或者开关链路等
(3)局限性
网络带宽和计算能力难以支撑进一步研究和发展
2.1.1 知识平面实现思路
(1)网络需要知道设计者,用户和应用的高层次的需求
对于应用相关的网络,需要在核心设计时嵌入领域相关知识,例如电话网、互联网,不能限定应用的类型,不能嵌入任何应用相关的知识,不能破坏简单和透明的传输层机制
(2)在互联网上建立的独立平面,用于产生和维护上述高层的视图,向网络的其他构件提供服务或者建议
2.1.2 知识平面构建原则
(1)边缘参与
①端到端的原则使得当前互联网大量的知识在网络边缘产生,管理和使用
②知识平面覆盖的范围比传统网络管理要宽泛,需要延伸到端系统
(2)全局视图
①现在管理员只管理自己的网络,一些问题定位需要全局的信息
②KP需要全局的视图(与分布管理原则的冲突)
(3)KP可组合
①两个分离网络的KP,在两个网络连接后,可以组成一个KP
②能够在不完全和冲突的信息下工作,不能假设异构网络享有相同的利益和相同的信息。不同区域的利益冲突这也是网络管理需要经验丰富专家的主要原因。
(4)统一方法
①自下而上的方式,针对具体问题(task)采用具体的解决方法对解决每个问题来说是简单的,但对于KP不可行,KP对知识具有统一的标准和框架,因为现实世界的知识并不与具体的task对应
②基于知识构建,而不是基于task构建。可能比基于task复杂,但有利于长期发展
(5)采用认知框架,使用认知的方法进行表示、学习和推理,使得KP能够理解网络,以及自己对网络的操作
①需要利用部分,或者相互冲突的知识决策
②根据目标和策略解决这些冲突
③比人更快的解决问题和抑制攻击
④在多维环境中解决人和解析工具难以进行优化
⑤自动执行当前只有领域专家才能进行的操作
2.2 知识定义网络
3. 交换芯片和网络处理器的特点和实现方法的差异
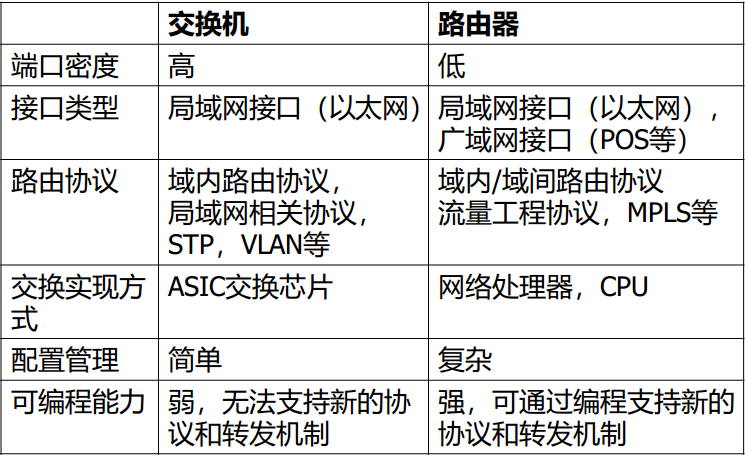
3.1 交换芯片
ACL关键字可由分组L2-L4的内容,以及交换状态域(如输入端口)组成。处理行为包括丢弃,修改VLAN头,修改分组颜色(流量标记),送CPU等。
3.2 网络处理器
3.2.1 模型
(1)Run-to-Completion 模型
①每个线程可以访问所有的指令空间和片上资源
②负责整个报文的处理流程
③基于SMP的处理结构,到达分组分派到空闲PE或负载最轻的PE
(2)Pipeline模型
①每个PE实现处理流程的一部分功能
②需要进行代码功能的划分,实现比较困难
4. SDN体系架构的特点,Openflow原理及SDN控制器的主要功能
4.1 SDN体系架构的特点
(1)控制层与转发层解耦
(2)网络控制的集中化
(3)开放接口,网络可编程
4.2 Openflow原理
4.2.1 设计思想
(1)商用交换机和路由器内部都有“流表”
用于NAT、防火墙、QoS和流量统计功能,基于TCAM等器件线速实现
(2)寻找不同设备中流表实现的共同点
匹配的字段,如输入端口,五元组;动作域,如丢弃,转发,送软件处理
(3)设计协议对设备中的流表进行编程
实验流量的流表由新的路由协议生成,正常流量的流表由现有的机制生成
4.2.2 OpenFlow交换机组成
(1)Flow table
(2)交换机和外部控制器之间的安全通道
(3)Openflow协议
流表不匹配的报文送外部的控制器转发,并形成新的流表规则下载到硬件流表中
4.3 SDN控制器主要功能
(1)设备管理
(2)拓扑管理
(3)事件管理
(4)策略管理
(5)南向接口传输
(6)北向接口API
5. 时间敏感网络(TSN)的基本特点和实现挑战
5.1 实现挑战
(1)发送任务的全局规划
①分组什么时候发出,什么时候进入交换机,什么时候到达接收端
②类似于编制“全国列车时刻表”
(2)时间触发的分组交换控制
①时间同步
②预定时间调度输出
(3)面向业务的故障冗余控制
5.2 TSN关键技术
(1)时间同步技术
(2)确定性分组转发机制
(3)帧复制与冗余消除
6. IEEE 1588 PTP协议的工作原理
6.1 PTP协议介绍
IEEE 1588协议,又称PTP(Precise Time Protocol,精确时间协议),可以达到亚微妙级别时间同步精度。PTP协议中的Delay Request-Response Machanism(延时响应机制)如下图所示。
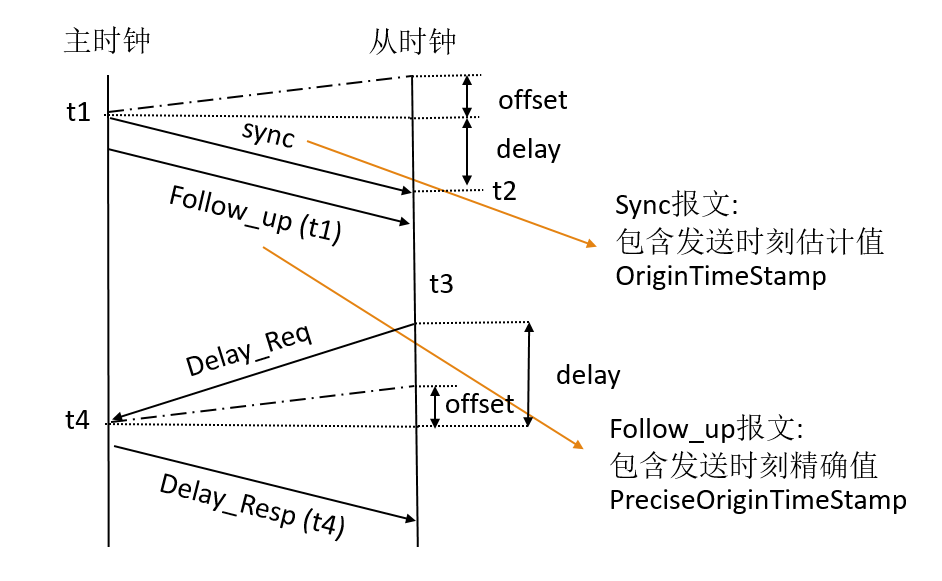
图中所描述的PTP报文为以下几种:
(1)sync同步报文
(2)Follow_up跟随报文
(3)Delay_req延迟请求报文
(4)Delay_resp延迟响应报文
6.2 延时响应同步机制的报文收发流程
(1)主时钟周期性地发出sync报文,并记录下sync报文离开主时钟的精确发送时间t1
(2)主时钟将精确发送时间t1封装到Follow_up报文中,发送给从时钟
(3)从时钟记录sync报文到达从时钟的精确到达时间t2
(4)从时钟发送Delay_req报文并记录下精确发送时间t3
(5)主时钟记录下Delay_req报文到达主时钟的精确时间t4
(6)主时钟发送携带精确时间戳信息t4的Delay_resp报文给从时钟
6.3 时钟偏差和网络延时计算
offset:时钟间偏差,主从时钟之间存在时间偏差,偏离值就是offset,上图中主从时钟之间虚线连接时刻,就是两时钟时间一致点。
delay:网络延时,报文在网络中传输带来的延迟
从时钟可以通过t1,t2,t3,t4四个精确时间戳信息,得到主从时钟偏差和传输延时:
$delay = \frac{(t_2-t_1)+(t_4-t_3)}{2} \quad offset = \frac{(t_2-t_1)-(t_4-t_3)}{2}$
7. 以交换机和服务器为中心的两类数据中心网络拓扑构造方法
7.1 以交换机为中心
(1)服务器通过1个端口连接网络
(2)互联和路由能力完全依靠交换机
(3)Fat-Tree,PortLand,VL2
7.2 以服务器为中心
(1)服务器通过多个端口连接网络
(2)服务器参与分组转发
(3)DCell,FiConn,BCube,MDCube,CamCube
8. 数据中心网络三类拥塞控制方法(源端控制、接收端控制和集中式控制)特点及典型算法(DCTCP、NDP和FASTPASS)
8.1 源端控制
(1)反压
通知前边的上游路由器减少输出报文的速率
(2)阻塞点Choke point
①路由器向源发送的报文,通知它发生拥塞
②类似于ICMP source quench packet
(3)隐式的信号Implicit signaling
检测到隐式的信号,警告拥塞,减小发送速率,如接收到延迟的ACK
(4)显式的信号Explicit signaling
路由器正在用塞,可以发送显式的信号,在发给发送者或接收者的报文中置位
8.2 接收端控制
8.2.1 目标:低延迟高负载的数据中心传输机制
①对于短消息接近硬件极限延迟
②高带宽利用率
③面向商用网络实际设计
8.2.2 核心思想:有效使用网络优先级
①接收方动态指派优先级
②接收方驱动的报文调度
③根据接收方下行链路控制超额认购
8.3 集中式控制
(1)“零”网络队列
(2)高利用率
(3)多资源分配目标
8.4 DCTCP
8.4.1 特点
(1)首次系统解决尾延迟
(2)根据拥塞程度调节发送速率
(3)短的尾延迟,不是Deadline敏感的
8.4.2 基本原理
(1)拥塞检测
①队列长度超过阈值
②可用带宽小于阈值
③Port/Flow超过了链路容量
(2)目标流标识
①使用DSCP来标识
②检测Elephant/Mice Flow
(3)拥塞控制修改
①减少发送速率
②减少队列需求
③根据实时队列长度进行标记
8.4.3 特点
(1)高突发容忍
(2)低延迟
(3)高吞吐率
8.5 D2TCP
基于DCTCP的deadline感知的处理fan-in突发问题
8.5.1 核心思想
(1)分布式:在端系统中使用每条流的状态
(2)被动式响应:发送方对拥塞做出相应,不需要其他流的信息
8.5.2 特点
(1)不影响长流
(2)与TCP共存,支持增量式部署
(3)无需改变交换机硬件
8.6 FastPass
(1)端系统全局时间同步
(2)控制器时隙仲裁
9. 两种QoS模型(区分服务和集成服务)的特点
9.1 集成服务
对于特定的用户报文流,路由器能够预留资源,来提供特定的QoS。在IP网络中,未单独的应用会话提供QoS保证。依赖于资源预留,路由器需要维护分配资源的状态信息,并对新的建立请求做出响应。
集成服务模型组成:信令协议(如RSVP)、访问控制、分类器、报文调度器
集成服务的问题
(1)扩展性差
①路由器花费巨大的存储和处理开销
②状态信息量随流数目增加而增加
(2)对路由器要求比较高,所有路由器必须实现RSVP,访问控制、分类和调度
9.2 区分服务
为了解决集成服务状态管理问题,增强可扩展性,提供灵活的服务模型,采用简单的信令来实现。定义了4类PHB(per-hop behavior),EF、AF、CS和BE。
边缘路由器:流量调节(监管、标记、丢弃),SLA协商,根据协商的服务和观察到的流量设置IP头中的DS
内部路由器:流量分类和转发,使用DS作为转发表的索引。
区分服务功能性元素
(1)报文分类分类器根据报文头域值选择报文,将报文分派到合适的标记函数
(2)限速器计算流量级别,与客户合约/服务级别约定的特征来比较
(3)标记按照需要将DS值设置为正确的码,来标记报文
(4)整形整形器监管流量,通过延迟报文的发送,使得报文不超过类特征确定的流量速率
(5)丢弃当某类报文的速率超过了类特征确定的速率,丢弃该报文
(6)逐跳行为PHB定义了类之间性能差异
10. MPLS标签分配原理及MPLS-TE的处理流程
10.1 多协议标签交换
在标签交换路由器LSR网络层路由协议中集成了标签交换方式,ATM和IP的结合,短的固定长度的标签带来高速交换。
10.1.1 组成
(1)转发等价类FEC
FEC(Forwarding Equivalence Class,转发等价类)是MPLS中的一个重要概念。MPLS是一种分类转发技术,它将具有相同特征(目的地相同或具有相同服务等级等)的报文归为一类,称为FEC。属于相同FEC的报文在MPLS网络中将获得完全相同的处理。
(2)基于标签交换的路由器LSR和LER参与LSP建立的高速路由器设备。LSR(Label Switch Router,标签交换路由器)是具有标签分发能力和标签交换能力的设备。LER(Label Edge Router,标签边缘路由器)位于MPLS网络边缘,用于连接其他网络的LSR。
(3)标签交换路径LSPLSR序列,报文需要跟随的路径。属于同一个FEC的报文在MPLS网络中经过的路径称为LSP(Label Switched Path,标签交换路径)。LSP是从MPLS网络的入口到出口的一条单向路径。在一条LSP上,沿数据传送的方向,相邻的LSR分别称为上游LSR和下游LSR。
(4)标签报文已经编码写入标签的报文
10.1.2 MPLS标签
(1)短的,固定长度的标识(32bit)
(2)随每个报文发送
(3)在相邻两个路由器之间本地有效
(4)如果从不同的路由器进入,可以有不同的标签
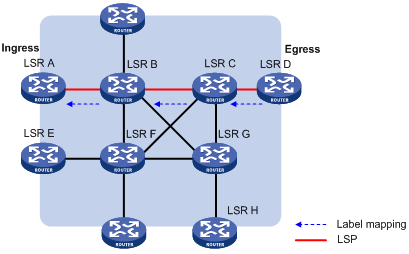
LSP的建立过程实际就是将FEC和标签进行绑定,并将这种绑定通告相邻LSR,以便在LSR上建立标签转发表的过程。LSP既可以通过手工配置的方式静态建立,也可以利用标签分发协议动态建立。利用标签发布协议动态建立LSP的过程如下图所示。下游LSR根据目的地址划分FEC,为特定FEC分配标签,并将标签和FEC的绑定关系通告给上游LSR;上游LSR根据该绑定关系建立标签转发表项。报文传输路径上的所有LSR都为该FEC建立对应的标签转发表项后,就成功地建立了用于转发属于该FEC报文的LSP。
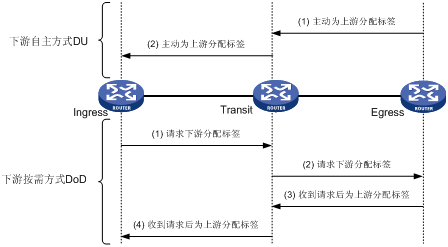
标签发布就是将为FEC分配的标签通告给其他LSR。根据标签发布条件、标签发布顺序的不同,LSR通告标签的方式分为DU(Downstream Unsolicited,下游自主方式)和DoD(Downstream On Demand,下游按需方式)、独立标签控制方式(Independent)和有序标签控制方式(Ordered)几种。
DU:对于一个特定的FEC,下游LSR自动为该FEC分配标签,并主动将标签分发给上游LSR。
DoD:对于一个特定的FEC,上游LSR请求下游LSR为该FEC分配标签,下游LSR收到请求后,为该FEC分配标签并向上游LSR通告该标签。
10.2 MPLS-TE
MPLS本身具有一些不同于IGP的特性,其中就有实现流量工程所需要的,例如:
(1)MPLS支持显式LSP路由;
(2)LSP较传统单个IP分组转发更便于管理和维护;
(3)基于MPLS的流量工程的资源消耗较其它实现方式更低。
MPLS TE结合了MPLS技术与流量工程,通过建立到达指定路径的LSP隧道进行资源预留,使网络流量绕开拥塞节点,达到平衡网络流量的目的。在资源紧张的情况下,MPLS TE能够抢占低优先级LSP隧道带宽资源,满足大带宽LSP或重要用户的需求。同时,当LSP隧道故障或网络的某一节点发生拥塞时,MPLS TE可以通过备份路径和FRR(Fast Reroute,快速重路由)提供保护。使用MPLS TE,网络管理员只需要建立一些LSP和旁路拥塞节点,就可以消除网络拥塞。随着LSP数量的增长,还可以使用专门的离线工具进行业务量分析。
11. SDN对数据中心网络交换机设计实现的影响
通过集中控制,支持对网络细粒度的管控,管理策略可以方便的集成到交换机的流表中,主机SDN交换实现服务器上多个虚拟机之间的交换,推动了虚拟化技术的发展,交换机(数据平面)对流表进行抽象,基于程序的网络控制,控制器向应用屏蔽网络的动态性,支持网络运维管理的自动化。也推动了厂商的设备从封闭走向开放。交换机设计研究,即设计可扩展的快速转发设备,它既可以灵活匹配规则,又能快速转发数据流,有效支持计算和网络基础设施增长的需求,交换机设备发展,从白牌交换机:具有灵活和高效的特点,并且可以显著降低了网络部署成本,同时让用户对交换机的功能有了更多的选择
(1)白牌交换机可以通常是通过使用ONOS控制器来编程,而传统的交换机的功能十分有限;
(2)数据中心通常需要部署大量交换机,并且交换机的端口必须具有高密度的特点,而白牌交换机不仅端口密度高,成本也比较低,因此被公认为是最佳选择。
(3)数据中心重视交换机平台的灵活性和开放性,由于白牌交换机不受传统的L2/L3协议的限制,从而具有更多的扩展可能性,并且它支持任何基于SDN的网络。
软件交换机:
OpenSwitch NOS 聚焦于数据中心交换机,支持 OCP 兼容交换机,通过 ONIE 安装/卸载,系统提供完备的 L2 与 L3 层网络协议。
OpenvSwitch 以其丰富的功能,作为多层虚拟交换机,已经广泛应用于云环境中。Open vSwitch的主要功能是为物理机上的VM提供二层网络接入,和云环境中的其它物理交换机并行工作在Layer 2。
12. 典型数据中心网络虚拟化协议(VEPA,VxLAN)处理流程及特点
12.1 VEPA
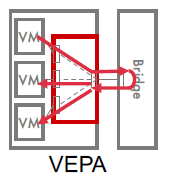
VEPA模式是一种简单修改了VEB功能的模式,如上所示,VEPA组件从VM接收到数据后,首先将数据转发到上行接口,即外部网络接口上去,如此充分利用外部网络的硬件能力和高级特性。如果是服务器内部同一VLAN内的VM间通信,数据也需要先转发出去,再从网络转发回服务器内寻找对应的目的VM。这种方式简化了服务器的vSwitch功能,并使VEPA与外部网络的硬件处理结合起来,使内外网络相关联,内部网络从逻辑上作为外部端口的扩展器,看起来似乎是外部网络的功能延伸到了服务器内,所有VM对应到一个物理的网络端口。这种方式下对广播/组播的处理相对复杂,数据从网络进入服务器后,由VEPA部件进行广播和组播的复制。
特点
(1)虚拟机流量发送到邻接桥
(2)在外部桥之间中间流量
(3)使VM到VM流量给邻接桥可视
(4)策略不需要分配到VEPA
12.2 VxLAN
12.2.1 VxLAN简介
(1)支持大量的租户
①使用24位的标识符,最多可支持2的24次方(16777216)个VXLAN
②解决了传统二层网络VLAN资源不足的问题
(2)易于维护
①基于IP网络组建大二层网络,使得网络部署和维护更加容易,并且可以充分地利用现有的IP网络技术,利用等价路由进行负载分担
②只有IP核心网络的边缘设备需要进行VXLAN处理,网络中间设备只需根据IP头转发报文,降低了网络部署的难度和费用
12.2.2 VxLAN基本概念
(1)VXLAN 层叠网
①由VNID标识的L2层广播域/VXLAN段
②从VTEP到VTEP的扩展或者流量隧道
(2)VTEP(VXLAN Tunnel End Point)
①提供典型以太网帧的封装和VXLAN报文解封装
②形成VXLAN段
③VTEP 接口
本地LAN交换机接口:连接本地端节点
3层接口:到其他网络接口
(3)VXLAN Gateway
VTEP,在VXLAN段之间桥接
(4)VxLAN网络标识符
①VXLAN标准使用一个名为VXLAN网络标识符(VNI)的24位标识符,将与应用程序关联的VLAN分组到一个片段中
②每一个管理域能够定义多达1600万个VNI,而每一个VNI可能最多包含4,094个VLAN。客户数据会保证分离,因为只有运行在同一个VNI的VM可以进行通信
12.2.3 VxLAN泛洪和学习过程
(1)VNI映射到VTEP组播组
(2)VTEP通过VLAN (VNI) 学习本地MAC
(3)广播,未知的单播和组播(BUM Traffic)以泛洪的方式发送到VNI组播组
(4)相同组播组远端VTEP学习主机MAC、VNI和源VTEP映射关系(泛洪帧主机MAC)(5)到主机MAC的单播报文以VXLAN封装格式发送给源VTEP
12.2.4 基于BGP的VxLAN控制
(1)控制平面学习端系统Layer-2和Layer-3可达信息,并构建健壮的可扩展的VXLAN层叠网络
(2)利用成熟的MP-BGP VPN技术,来支持可扩展的多租户的的VXLAN层叠网络
(3)EVPN地址族携带Layer-2和Layer-3可达信息,在VXLAN中提供了一体式桥接和路由
12.2.5 基于BGP的VxLAN控制的优点
(1)通过协议驱动的主机MAC/IP路由发布和基于本地VTEP的ARP抑制,减少网络泛洪
(2)通过分布式任意转发功能,提供了对于东西向和南北向流量的优化的转发
(3)提供了VTEP对端发现认证机制,减小了VxLAN层叠网络中伪装VTEP的风险
13. P2P Overlay的概念和特点
P2P是一种网络计算技术。网络计算指的是将应用从单机转移到网络上来,把应用功能和负载合理地分配到联网的机器上。P2P技术强调参与网络计算的各个节点地位平等。
Overlay是在物理网络之上构建的(应用级)网络,提供一些新的性质,解决或缓解底层网络的一些问题。P2P系统就是一个没有中心控制的系统,对等实体之间的每条连接都包括一个或多个IP连接(P2P systems are overlay networks without central control. Each link between peers consists of one or more IP links)。在物理IP网络之上,提供应用级编址、拓扑构建、查询路由等功能。
14. 典型P2P系统(BitTorrent和Gnutella)的特性
14.1 BitTorrent简介及特点
BitTorrent采用集中式拓扑,资源分散,设有集中服务器。其中服务器协助通信和管理。它仍是P2P的,客户端用户直接交换共享资源(hybrid P2P)。
(1)下载的同时必须为他人提供上载服务,即“人人为我,我为人人”
(2)文件分段,并行下载。某一文件同时下载的人越多,速度越快
(3)适于热门大文件的分发或共享
14.2 Gnutella简介及特点
Gnutella采用松散式拓扑。它没有集中服务器,各个结点地位平等,结点间的P2P网络拓扑关系以及资源的放置都没有很严格精确的控制。网络拓扑形成较为随意,路由方式包括泛洪、随机转发、有选择性转发。它适于松散性要求的应用,没有服务质量保障。
(1)没有中央索引服务器,每个结点地位平等,称为servant
(2)新结点加入到Gnutella网络时,先选择一个或多个已在Gnutella网络中的已知结点,与这些结点建立连接关系
15. 典型DHT算法(Chord、CAN和Pastry)的原理,包括路由表设计和路由算法等
太多,略。