本文分三部分讲述 python 中常用的语法糖,为什么分三部分,因为考虑到大家可能对 python 中的一些特有的数据结构不太熟悉,所以首先介绍;文章的最后将会介绍一些经典的函数语法糖。
首先解释一下语法糖是什么意思,其实就是简化我们的代码,让那些复杂的操作交给解释器来完成,这些语法糖刚开始学的时候觉得很难记住,如果看别人写的语法糖更容易蒙圈,还会嘀咕别人装什么装,但是一旦自己掌握,啧啧啧,一发不可收拾,可谓真香。
语法糖(Syntactic sugar):
计算机语言中特殊的某种语法
这种语法对语言的功能并没有影响
对于程序员有更好的易用性
能够增加程序的可读性
简而言之,语法糖就是程序语言中提供[]的一种手段和方式而已。 通过这类方式编写出来的代码,即好看又好用,好似糖一般的语法。固美其名曰:语法糖
一、数据结构
这里主要介绍常用语语法糖的数据结构,熟悉的小伙伴可以跳过。
序列类型
在序列中元素类型可以不同,通过下标访问元素。
字符串类型、列表类型、元组类型都属于序列。
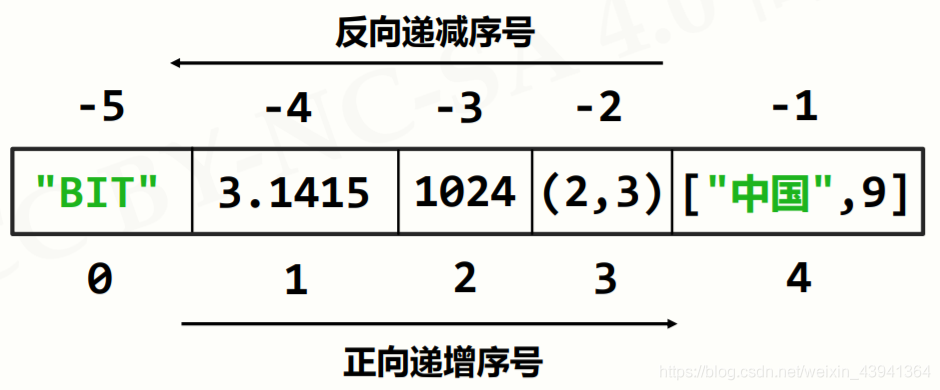
序列类型是双向索引,如上图所示。
序列类型常用的操作:
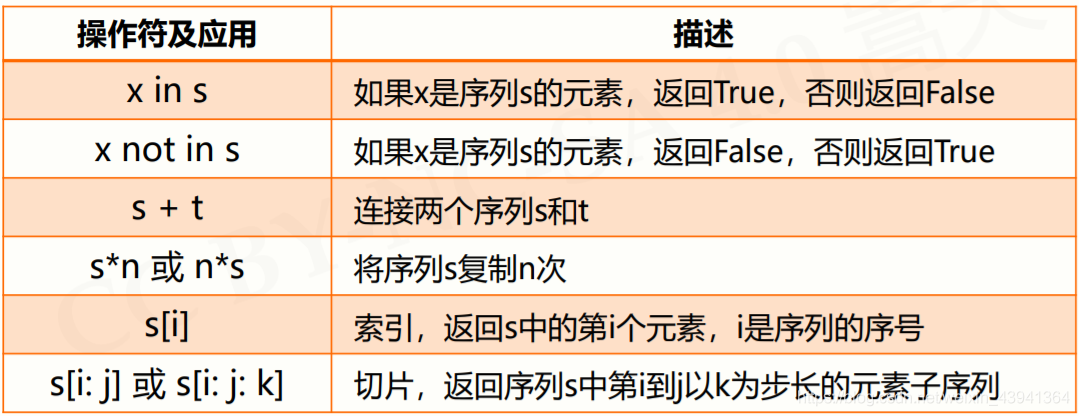
序列类型的函数与方法:
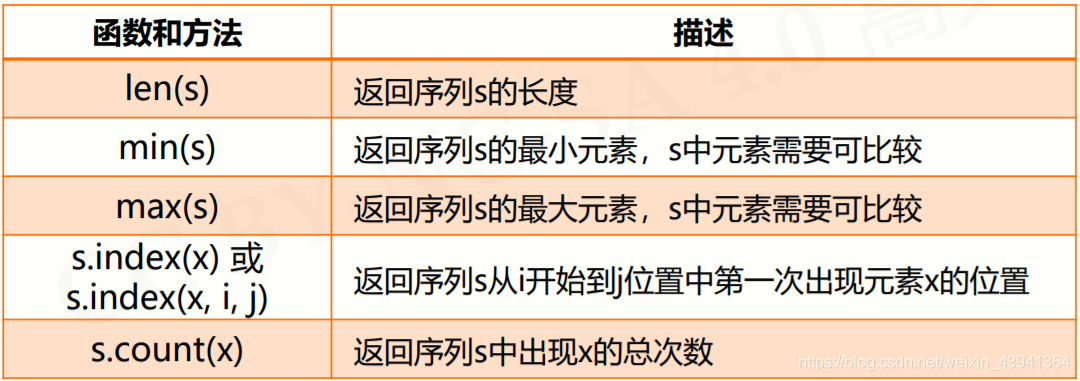
下面介绍
元组类型
:
元组类型是序列类型的一种扩展,但是元组一旦创建就不能修改,元组使用
()
或者
tuple()
创建。
接下来是
列表类型
,列表类型可谓是最常用的一种数据结构,该序列创建之后可以随意修改,使用
[]
或者
list()
创建,列表类型特有的函数和方法如下:
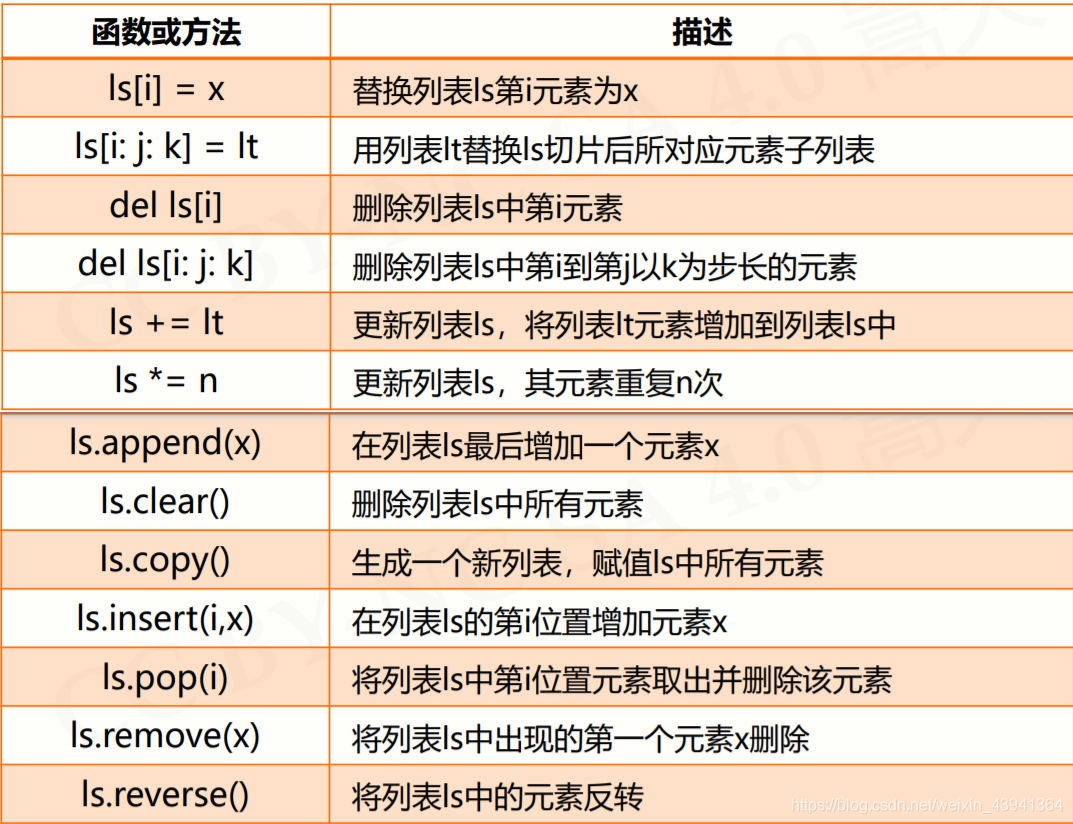
值得一提的是列表中使用
[::-1]
表示反转字符串。
集合类型
集合是多个元素的无序组合,特点是元素不重复。创建使用
{}
或者
set()
;
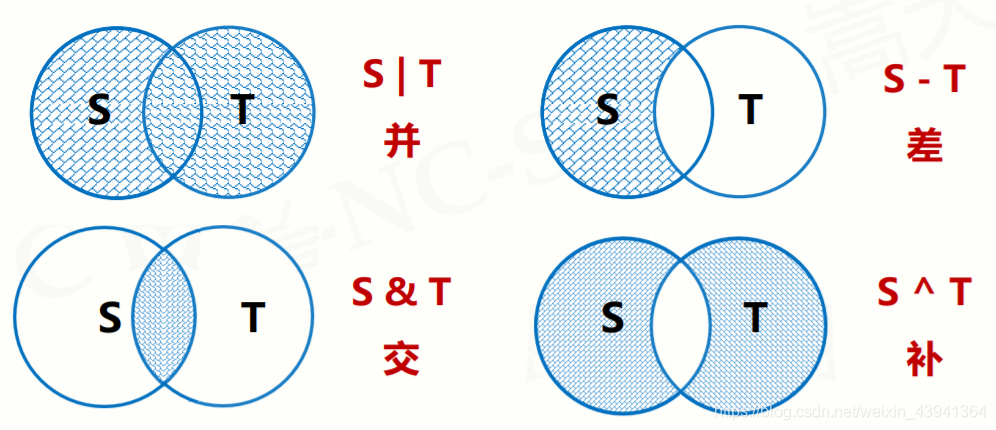
集合操作符:
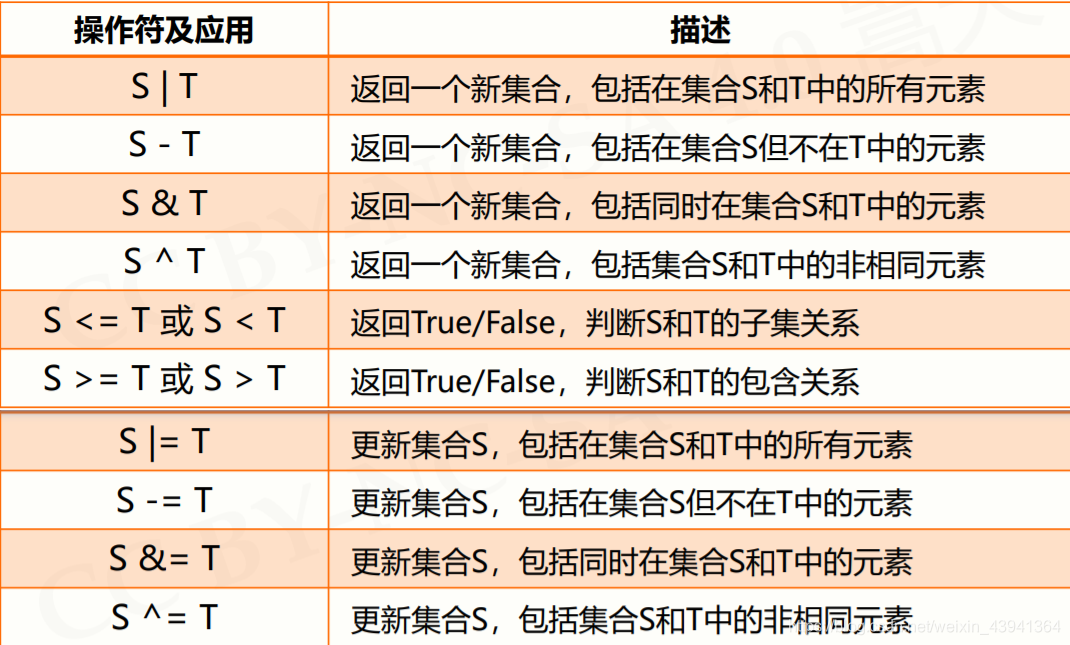
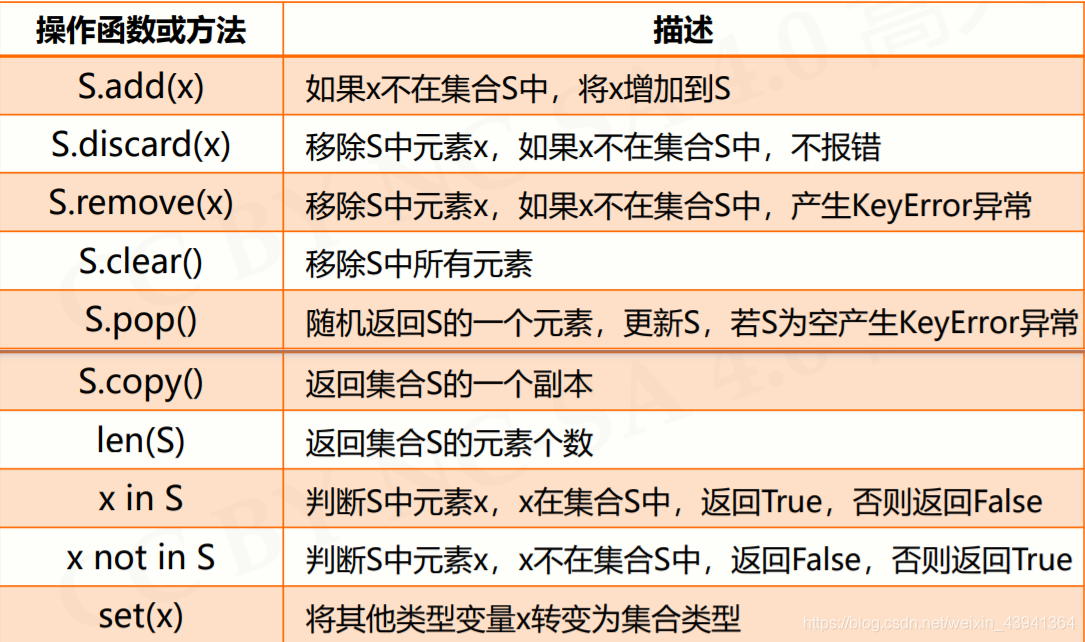
集合中常用的方法与函数:
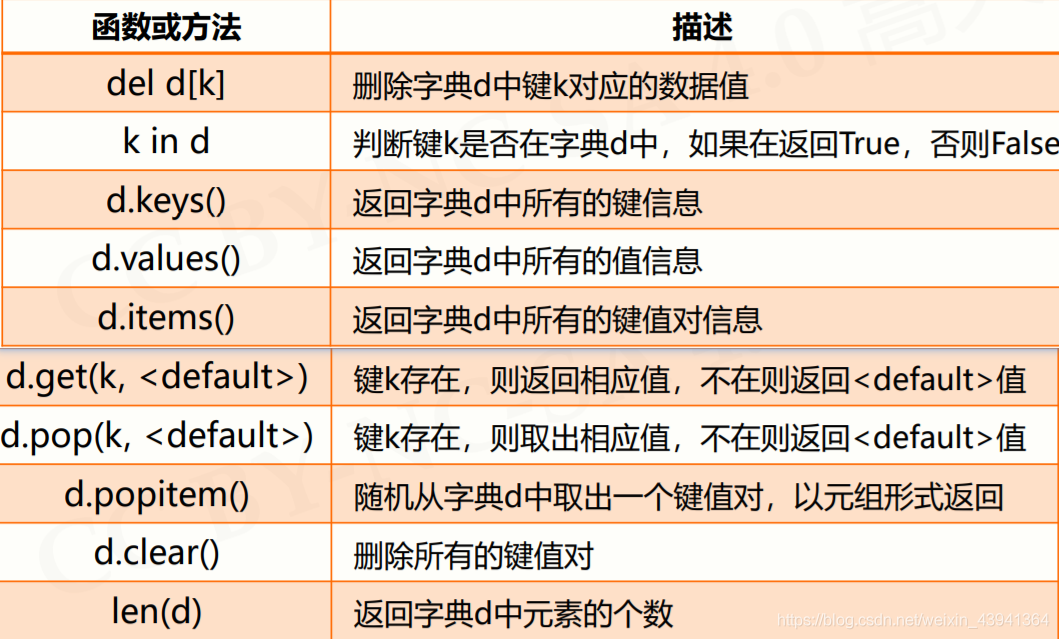
字典类型
字典类型相当于
java
中的
Map
,即映射关系类型的数据结构:
使用
{}
和
dict()
创建,使用冒号
:
表示键值关系。
二、语法糖
先说一个实用的技巧,就是字符串类型和列表类型互相转换的几种方法:
首先是字符串类型到列表类型,使用
list()
或者
split()
然后是列表转字符串:如果列表元素都为字符串可以使用
"".join(ls)
,如果不全是则使用
map(str,ls)
然后再
join
。
//交换数字
a, b = b, a
//表示从b和c取一个较大的值赋值给a
a = [b, c][c > b]
// 我们希望把正的放前面,负的放后面,并且分别按绝对值从小到大
lst = [1, -2, 10, -12, -4, -5, 9, 2]
// 这样即可
lst.sort(key=lambda x: (x < 0, abs(x)))
// Lambda 表达式
f=lambda x:x+1
//
关于列表的列表推导式:
// 生成奇数序列
l=[2*x+1 for x in range(10)]
for 的嵌套
[(x,y) for x in range(3) for y in range(3)]
[(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
还可以使用 if 语句:
new_list = [expression(i) for i in old_list if condition(i)]
不过可读性极差,让别人来阅读你的代码是很痛苦的一件事。
三、函数语法
三大函数,很有用:
filter,map,reduce
首先是
filter
函数,
filter
函数接受两个参数,第一个是过滤函数,第二个是可遍历的对象,用于选择出所有满足过滤条件的元素,返回一个可迭代对象。
// 去除小写字母
s=filter(lambda x:not str(x).islower(),"asdasfAsfBsdfC")
map
函数接受的参数类型与filter类似,它用于把函数作用于可遍历对象的每一个元素。类似于数学中映射的概念。
// 求y=2x+1
s=map(lambda x:2*x+1,range(6))
reduce
函数对每个元素作累计操作,它接受的第一个参数必须是有两个参数的函数。
// 求和
from functools import reduce
s=reduce(lambda x,y:x+y,range(1,6))
元组拆包:
t=(1,2,3)
x,y,z=t
当然还有很多语法糖,欢迎留言补充。
参考链接: