文章目录
- 14、Linux下软件安装
- 2 简介
- 2.1 先体验一下
- 2.2 apt 包管理工具介绍
- 2.3 apt-get
- 2.4 安装软件包
- 2.5 软件升级
- 2.6 卸载软件
- 2.7 软件搜索
- 3、使用 dpkg
- 3.1 dpkg 介绍
- 3.2 使用 dpkg 安装 deb 软件包
- 3.3 查看已安装软件包的安装目录
- 4、从二进制包安装
- 15、Linux 进程概念
- 2、概念的理解
- 3、进程的属性
- 3.2 进程的衍生
- 3.3 进程组与 Sessions
-
- 16、 Linux 进程管理
- 2、 进程的查看
- 2.1 top 工具的使用
- 2.2 ps 工具的使用
- 2.3 pstree 工具的使用
- 3、进程的管理
- 3.1 kill 命令的掌握
- 3.2 进程的执行顺序
- 17、Linux 日志系统
-
14、Linux下软件安装
通常 Linux 上的软件安装主要有四种方式:
- 在线安装
- 从磁盘安装 deb 软件包
- 从二进制软件包安装
- 从源代码编译安装
2 简介
- 在 Linux 下,一个命令加回车,等待一下,软件就安装好了,这就是方便的在线安装软件的方式。在学习这种安装方式之前有一点需要说明的是,在不同的 linux 发行版上面在线安装方式会有一些差异包括使用的命令及它们的包管理工具,因为我们的开发环境是基于 ubuntu 的,所以这里我们涉及的在线安装方式将只适用于 ubuntu 发行版,或其它基于 ubuntu 的发行版如国内的 ubuntukylin(优麒麟),ubuntu 又是基于 debian 的发行版,它使用的是 debian 的包管理工具
dpkg,所以一些操作也适用与 debian。而在一些采用其它包管理工具的发行版如 redhat,centos,fedora 等将不适用(redhat 和 centos 使用 rpm)。
2.1 先体验一下
比如我们想安装一个软件,名字叫做 w3m(w3m 是一个命令行的简易网页浏览器),那么输入如下命令:
sudo apt-get install w3m
这样的操作你应该在前面的章节中看到过很多次了,它就表示将会安装一个软件包名为w3m的软件
$ w3m https://www.shiyanlou.com/faq
注意:如果你在安装一个软件之后,无法立即使用Tab键补全这个命令,你可以尝试先执行source ~/.zshrc,然后你就可以使用补全操作。
2.2 apt 包管理工具介绍
APT 是 Advance Packaging Tool(高级包装工具)的缩写,是 Debian 及其派生发行版的软件包管理器,APT 可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了 Unix 系统上管理软件的过程。APT 最早被设计成 dpkg 的前端,用来处理 deb 格式的软件包。现在经过 APT-RPM 组织修改,APT 已经可以安装在支持 RPM 的系统管理 RPM 包。这个包管理器包含以 apt- 开头的多个工具,如 apt-get apt-cache apt-cdrom 等,在 Debian 系列的发行版中使用。
当你在执行安装操作时,首先apt-get 工具会在本地的一个数据库中搜索关于 w3m 软件的相关信息,并根据这些信息在相关的服务器上下载软件安装,这里大家可能会一个疑问:既然是在线安装软件,为啥会在本地的数据库中搜索?要解释这个问题就得提到几个名词了:
- 软件源镜像服务器
- 软件源
我们需要定期从服务器上下载一个软件包列表,使用 sudo apt-get update 命令来保持本地的软件包列表是最新的(有时你也需要手动执行这个操作,比如更换了软件源),而这个表里会有软件依赖信息的记录,对于软件依赖,我举个例子:我们安装 w3m 软件的时候,而这个软件需要 libgc1c2 这个软件包才能正常工作,这个时候 apt-get 在安装软件的时候会一并替我们安装了,以保证 w3m 能正常的工作。
2.3 apt-get
apt-get 是用于处理 apt包的公用程序集,我们可以用它来在线安装、卸载和升级软件包等,下面列出一些apt-get包含的常用的一些工具:
| 工具 | 说明 |
|---|
| install | 其后加上软件包名,用于安装一个软件包 |
| update | 从软件源镜像服务器上下载/更新用于更新本地软件源的软件包列表 |
| upgrade | 升级本地可更新的全部软件包,但存在依赖问题时将不会升级,通常会在更新之前执行一次update |
| dist-upgrade | 解决依赖关系并升级(存在一定危险性) |
| remove | 移除已安装的软件包,包括与被移除软件包有依赖关系的软件包,但不包含软件包的配置文件 |
| autoremove | 移除之前被其他软件包依赖,但现在不再被使用的软件包 |
| purge | 与 remove 相同,但会完全移除软件包,包含其配置文件 |
| clean | 移除下载到本地的已经安装的软件包,默认保存在/var/cache/apt/archives/ |
| autoclean | 移除已安装的软件的旧版本软件包 |
下面是一些apt-get常用的参数:
| 参数 | 说明 |
|---|
| -y | 自动回应是否安装软件包的选项,在一些自动化安装脚本中使用这个参数将十分有用 |
| -s | 模拟安装 |
| -q | 静默安装方式,指定多个q或者-q=#,#表示数字,用于设定静默级别,这在你不想要在安装软件包时屏幕输出过多时很有用 |
| -f | 修复损坏的依赖关系 |
| -d | 只下载不安装 |
| –reinstall | 重新安装已经安装但可能存在问题的软件包 |
| –install-suggests | 同时安装 APT 给出的建议安装的软件包 |
2.4 安装软件包
关于安装,如前面演示的一样你只需要执行apt-get install <软件包名>即可,除了这一点,你还应该掌握的是如何重新安装软件包。 很多时候我们需要重新安装一个软件包,比如你的系统被破坏,或者一些错误的配置导致软件无法正常工作。
你可以使用如下方式重新安装:
sudo apt-get --reinstall install w3m
另一个你需要掌握的是,如何在不知道软件包完整名的时候进行安装。通常我们是使用Tab键补全软件包名,后面会介绍更好的方法来搜索软件包。有时候你需要同时安装多个软件包,你还可以使用正则表达式匹配软件包名进行批量安装。
2.5 软件升级
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade
2.6 卸载软件
如果你现在觉得 w3m 这个软件不合自己的胃口,或者是找到了更好的,你需要卸载它,那么简单!同样是一个命令加回车 sudo apt-get remove w3m ,系统会有一个确认的操作,之后这个软件便“滚蛋了”。
或者,你可以执行
sudo apt-get purge w3m
sudo apt-get autoremove
2.7 软件搜索
当自己刚知道了一个软件,想下载使用,需要确认软件仓库里面有没有,就需要用到搜索功能了,命令如下:
sudo apt-cache search softname1 softname2 softname3……
apt-cache 命令则是针对本地数据进行相关操作的工具,search 顾名思义在本地的数据库中寻找有关 softname1 softname2 …… 相关软件的信息。
3、使用 dpkg
使用 dpkg 从本地磁盘安装 deb 软件包。
3.1 dpkg 介绍
dpkg 是 Debian 软件包管理器的基础,它被伊恩·默多克创建于 1993 年。dpkg 与 RPM 十分相似,同样被用于安装、卸载和供给和 .deb 软件包相关的信息。
dpkg 本身是一个底层的工具。上层的工具,像是 APT,被用于从远程获取软件包以及处理复杂的软件包关系。"dpkg"是"Debian Package"的简写。
我们经常可以在网络上见到以deb形式打包的软件包,就需要使用dpkg命令来安装。
dpkg常用参数介绍:
| 参数 | 说明 |
|---|
| -i | 安装指定 deb 包 |
| -R | 后面加上目录名,用于安装该目录下的所有 deb 安装包 |
| -r | remove,移除某个已安装的软件包 |
| -I | 显示deb包文件的信息 |
| -s | 显示已安装软件的信息 |
| -S | 搜索已安装的软件包 |
| -L | 显示已安装软件包的目录信息 |
3.2 使用 dpkg 安装 deb 软件包
- 我们先使用apt-get加上-d参数只下载不安装,下载 emacs 编辑器的 deb 包:
sudo apt-get update
sudo apt-get -d install -y emacs
下载完成后,我们可以查看/var/cache/apt/archives/目录下的内容。
- 然后我们将第一个deb拷贝到 /home/shiyanlou 目录下,并使用dpkg安装
cp /var/cache/apt/archives/emacs24_24.5+1-6ubuntu1.1_amd64.deb ~
sudo dpkg -I emacs24_24.5+1-6ubuntu1.1_amd64.deb
这个包还额外依赖了一些软件包,这意味着,如果主机目前没有这些被依赖的软件包,直接使用 dpkg 安装可能会存在一些问题,因为dpkg并不能为你解决依赖关系。
sudo dpkg -i emacs24_24.5+1-6ubuntu1.1_amd64.deb
这里你可能出现了一些错误:
- 我们将如何解决这个错误呢?这就要用到
apt-get了,使用它的-f参数了,修复依赖关系的安装
sudo apt-get update
sudo apt-get -f install -y
没有任何错误,这样我们就安装成功了,然后你可以运行 emacs 程序
3.3 查看已安装软件包的安装目录
如果你依然在纠结到底 linux 将软件安装到了什么地方,那么很幸运你将可以通过dpkg找到答案
sudo dpkg -L emacs24
sudo dpkg -L python
4、从二进制包安装
二进制包的安装比较简单,我们需要做的只是将从网络上下载的二进制包解压后放到合适的目录,然后将包含可执行的主程序文件的目录添加进PATH环境变量即可,如果你不知道该放到什么位置,请重新复习第四节关于 Linux 目录结构的内容。
15、Linux 进程概念
2、概念的理解
程序(procedure):不太精确地说,程序就是执行一系列有逻辑、有顺序结构的指令,帮我们达成某个结果。就如我们去餐馆,给服务员说我要牛肉盖浇饭,她执行了做牛肉盖浇饭这么一个程序,最后我们得到了这么一盘牛肉盖浇饭。它需要去执行,不然它就像一本武功秘籍,放在那里等人翻看。
进程(process):进程是程序在一个数据集合上的一次执行过程,在早期的 UNIX、Linux 2.4 及更早的版本中,它是系统进行资源分配和调度的独立基本单位。同上一个例子,就如我们去了餐馆,给服务员说我要牛肉盖浇饭,她执行了做牛肉盖浇饭这么一个程序,而里面做饭的是一个进程,做牛肉汤汁的是一个进程,把牛肉汤汁与饭混合在一起的是一个进程,把饭端上桌的是一个进程。它就像是我们在看武功秘籍这么一个过程,然后一个篇章一个篇章地去练。
简单来说,程序是为了完成某种任务而设计的软件,比如 vim 是程序。什么是进程呢?进程就是运行中的程序。
并发:在一个时间段内,宏观来看有多个程序都在活动,有条不紊的执行(每一瞬间只有一个在执行,只是在一段时间有多个程序都执行过)
并行:在每一个瞬间,都有多个程序都在同时执行,这个必须有多个 CPU 才行
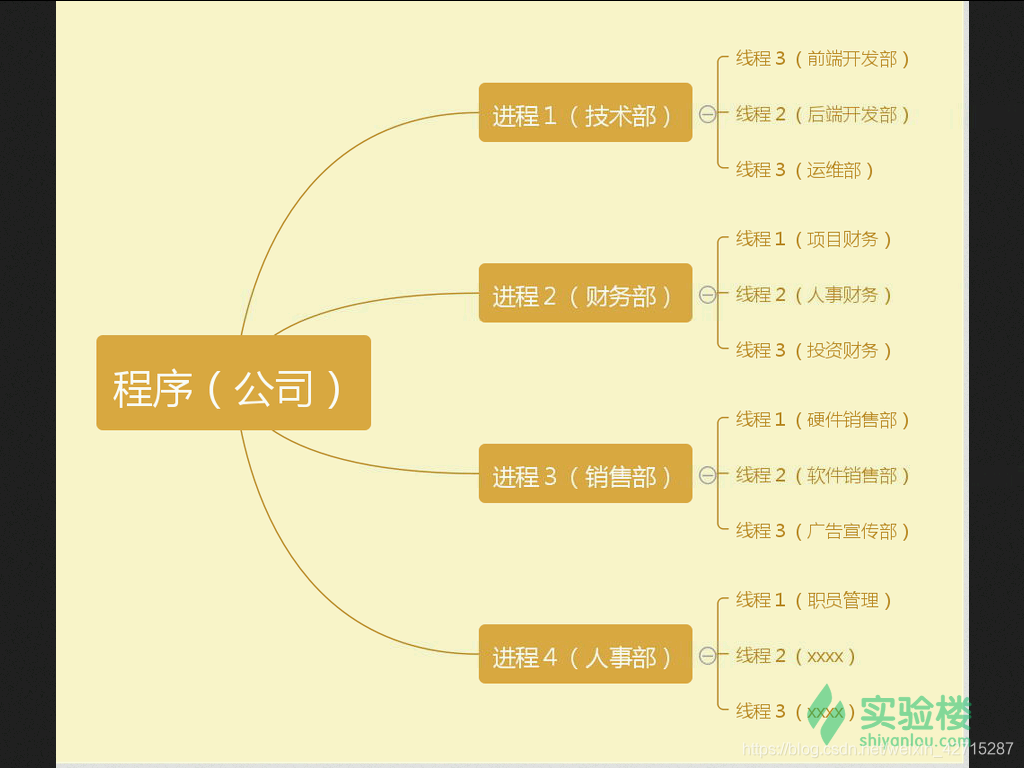
引入进程是因为传统意义上的程序已经不足以描述 OS 中各种活动之间的动态性、并发性、独立性还有相互制约性。程序就像一个公司,只是一些证书,文件的堆积(静态实体)。而当公司运作起来就有各个部门的区分,财务部,技术部,销售部等等,就像各个进程,各个部门之间可以独立运做,也可以有交互(独立性、并发性)。
- 而随着程序的发展越做越大,又会继续细分,从而引入了线程的概念,当代多数操作系统、Linux 2.6 及更新的版本中,进程本身不是基本运行单位,而是线程的容器。就像上述所说的,每个部门又会细分为各个工作小组(线程),而工作小组需要的资源需要向上级(进程)申请。
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。因为线程中几乎不包含系统资源,所以执行更快、更有效率。
简而言之,一个程序至少有一个进程,一个进程至少有一个线程。线程的划分尺度小于进程,使得多线程程序的并发性高。另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。就如下图所示:
3、进程的属性
大概明白进程是个什么样的存在后,我们需要进一步了解的就是进程分类。可以从两个角度来分:
- 以进程的功能与服务的对象来分;
- 以应用程序的服务类型来分;
第一个角度来看,我们可以分为用户进程与系统进程:
- 用户进程:通过执行用户程序、应用程序或称之为内核之外的系统程序而产生的进程,此类进程可以在用户的控制下运行或关闭。
- 系统进程:通过执行系统内核程序而产生的进程,比如可以执行内存资源分配和进程切换等相对底层的工作;而且该进程的运行不受用户的干预,即使是 root 用户也不能干预系统进程的运行。
第二角度来看,我们可以将进程分为交互进程、批处理进程、守护进程
- 交互进程:由一个 shell 终端启动的进程,在执行过程中,需要与用户进行交互操作,可以运行于前台,也可以运行在后台。
- 批处理进程:该进程是一个进程集合,负责按顺序启动其他的进程。
- 守护进程:守护进程是一直运行的一种进程,在 Linux 系统启动时启动,在系统关闭时终止。它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件。例如 httpd 进程,一直处于运行状态,等待用户的访问。还有经常用的 cron(在 centOS 系列为 crond)进程,这个进程为 crontab 的守护进程,可以周期性的执行用户设定的某些任务。
3.2 进程的衍生
进程有这么多的种类,那么进程之间定是有相关性的,而这些有关联性的进程又是如何产生的,如何衍生的?
就比如我们启动了终端,就是启动了一个 bash 进程,我们可以在 bash 中再输入 bash 则会再启动一个 bash 的进程,此时第二个 bash 进程就是由第一个 bash 进程创建出来的,他们之间又是个什么关系?
我们一般称呼第一个 bash 进程是第二 bash 进程的父进程,第二 bash 进程是第一个 bash 进程的子进程,这层关系是如何得来的呢?
关于父进程与子进程便会提及这两个系统调用 fork() 与 exec()
fork-exec是由 Dennis M. Ritchie 创造的
fork() 是一个系统调用(system call),它的主要作用就是为当前的进程创建一个新的进程,这个新的进程就是它的子进程,这个子进程除了父进程的返回值和 PID 以外其他的都一模一样,如进程的执行代码段,内存信息,文件描述,寄存器状态等等
exec() 也是系统调用,作用是切换子进程中的执行程序也就是替换其从父进程复制过来的代码段与数据段
子进程就是父进程通过系统调用 fork() 而产生的复制品,fork() 就是把父进程的 PCB 等进程的数据结构信息直接复制过来,只是修改了 PID,所以一模一样,只有在执行 exec() 之后才会不同,而早先的 fork() 比较消耗资源。后来进化成 vfork(),效率高了不少。
- 这就是子进程产生的由来。简单的实现逻辑就如下方所示:
pid_t p;
p = fork();
if (p == (pid_t) -1)
/* ERROR */
else if (p == 0)
/* CHILD */
else
/* PARENT */
既然子进程是通过父进程而衍生出来的,那么子进程的退出与资源的回收定然与父进程有很大的相关性。当一个子进程要正常的终止运行时,或者该进程结束时它的主函数 main() 会执行 exit(n); 或者 return n,这里的返回值 n 是一个信号,系统会把这个 SIGCHLD 信号传给其父进程,当然若是异常终止也往往是因为这个信号。
在将要结束时的子进程代码执行部分已经结束执行了,系统的资源也基本归还给系统了,但若是其进程的进程控制块(PCB)仍驻留在内存中,而它的 PCB 还在,代表这个进程还存在(因为 PCB 就是进程存在的唯一标志,里面有 PID 等消息),并没有消亡,这样的进程称之为僵尸进程(Zombie)。
如图中第四列标题是 S,S 表示的是进程的状态,而在下属的第三行的 Z 表示的是 Zombie 的意思。( ps 命令将在后续详解)
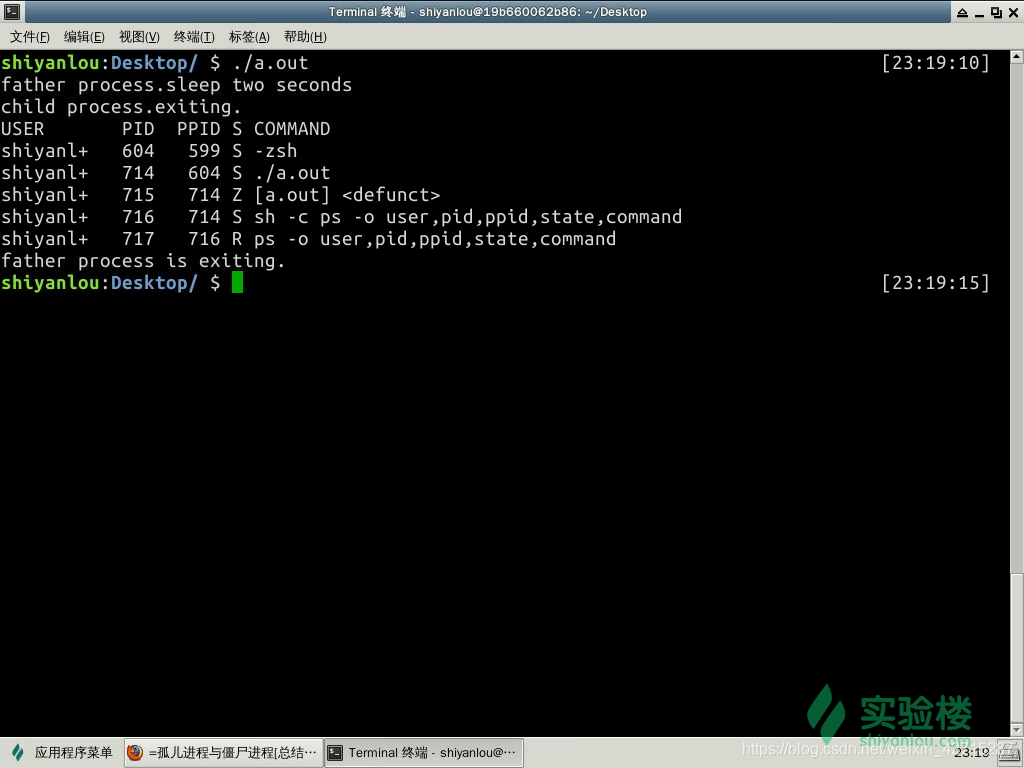
正常情况下,父进程会收到两个返回值:exit code(SIGCHLD 信号)与 reason for termination 。之后,父进程会使用 wait(&status) 系统调用以获取子进程的退出状态,然后内核就可以从内存中释放已结束的子进程的 PCB;而如若父进程没有这么做的话,子进程的 PCB 就会一直驻留在内存中,一直留在系统中成为僵尸进程(Zombie)。
虽然僵尸进程是已经放弃了几乎所有内存空间,没有任何可执行代码,也不能被调度,在进程列表中保留一个位置,记载该进程的退出状态等信息供其父进程收集,从而释放它。但是 Linux 系统中能使用的 PID 是有限的,如果系统中存在有大量的僵尸进程,系统将会因为没有可用的 PID 从而导致不能产生新的进程。
另外如果父进程结束(非正常的结束),未能及时收回子进程,子进程仍在运行,这样的子进程称之为孤儿进程。在 Linux 系统中,孤儿进程一般会被 init 进程所“收养”,成为 init 的子进程。由 init 来做善后处理,所以它并不至于像僵尸进程那样无人问津,不管不顾,大量存在会有危害。
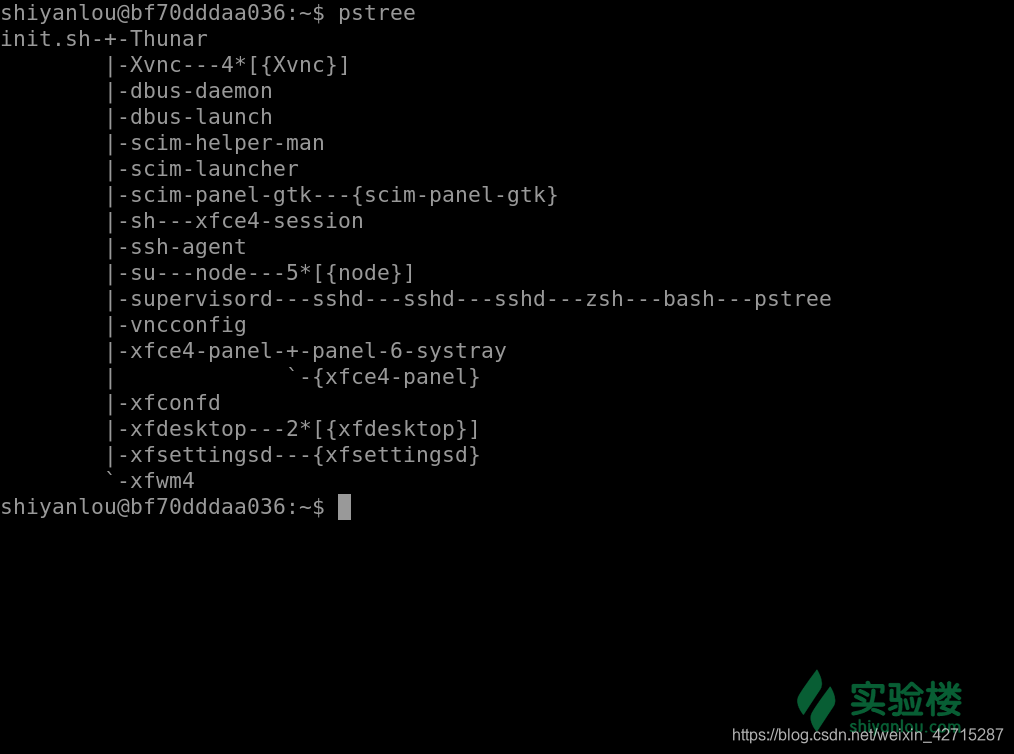
进程 0 是系统引导时创建的一个特殊进程,也称之为内核初始化,其最后一个动作就是调用 fork() 创建出一个子进程运行 /sbin/init 可执行文件,而该进程就是 PID=1 的进程 1,而进程 0 就转为交换进程(也被称为空闲进程),进程 1 (init 进程)是第一个用户态的进程,再由它不断调用 fork() 来创建系统里其他的进程,所以它是所有进程的父进程或者祖先进程。同时它是一个守护程序,直到计算机关机才会停止。
pstree
- 我们还可以使用这样一个命令来看,其中 pid 就是该进程的一个唯一编号,ppid 就是该进程的父进程的 pid,command 表示的是该进程通过执行什么样的命令或者脚本而产生的
ps -fxo user,ppid,pid,pgid,command
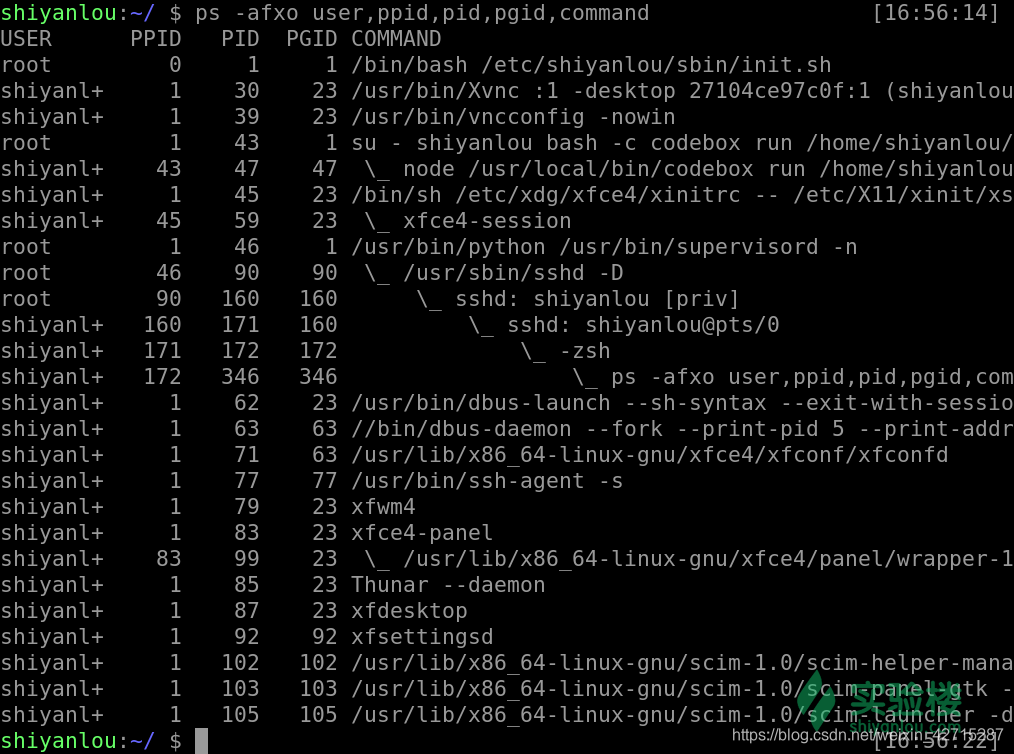
可以在图中看见我们执行的 ps 就是由 zsh 通过 fork-exec 创建的子进程而执行的
使用这样的一个命令我们也能清楚的看见 init 如上文所说是由进程 0 这个初始化进程来创建出来的子进程,而其他的进程基本是由 init 创建的子进程,或者是由它的子进程创建出来的子进程。所以 init 是用户进程的第一个进程也是所有用户进程的父进程或者祖先进程。(ps 命令将在后续课程详解)
就像一个树状图,而 init 进程就是这棵树的根,其他进程由根不断的发散,开枝散叶
3.3 进程组与 Sessions
每一个进程都会是一个进程组的成员,而且这个进程组是唯一存在的,他们是依靠 PGID(process group ID)来区别的,而每当一个进程被创建的时候,它便会成为其父进程所在组中的一员。
一般情况,进程组的 PGID 等同于进程组的第一个成员的 PID,并且这样的进程称为该进程组的领导者,也就是领导进程,进程一般通过使用 getpgrp() 系统调用来寻找其所在组的 PGID,领导进程可以先终结,此时进程组依然存在,并持有相同的 PGID,直到进程组中最后一个进程终结。
与进程组类似,每当一个进程被创建的时候,它便会成为其父进程所在 Session 中的一员,每一个进程组都会在一个 Session 中,并且这个 Session 是唯一存在的,
Session 主要是针对一个 tty 建立,Session 中的每个进程都称为一个工作(job)。每个会话可以连接一个终端(control terminal)。当控制终端有输入输出时,都传递给该会话的前台进程组。Session 意义在于将多个 jobs 囊括在一个终端,并取其中的一个 job 作为前台,来直接接收该终端的输入输出以及终端信号。 其他 jobs 在后台运行。
前台(foreground)就是在终端中运行,能与你有交互的
后台(background)就是在终端中运行,但是你并不能与其任何的交互,也不会显示其执行的过程
3.4 工作管理
bash(Bourne-Again shell)支持工作控制(job control),而 sh(Bourne shell)并不支持。
并且每个终端或者说 bash 只能管理当前终端中的 job,不能管理其他终端中的 job。比如我当前存在两个 bash 分别为 bash1、bash2,bash1 只能管理其自己里面的 job 并不能管理 bash2 里面的 job
我们都知道当一个进程在前台运作时我们可以用 ctrl + c 来终止它,但是若是在后台的话就不行了。
- 我们可以通过
& 这个符号,让我们的命令在后台中运行
ls &
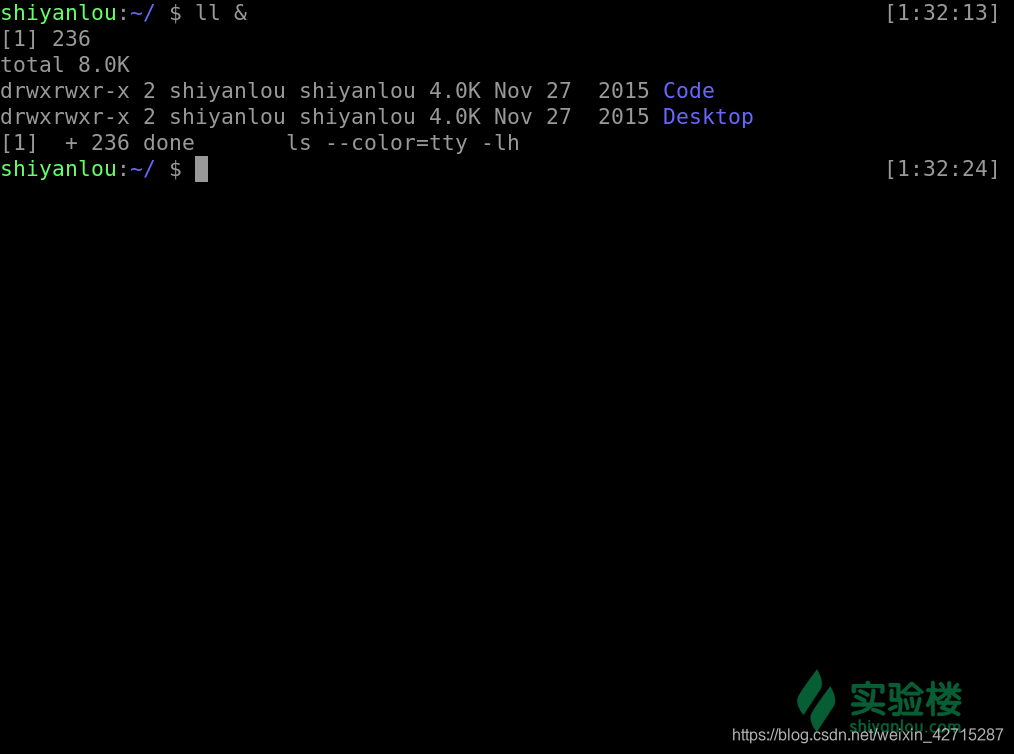
图中所显示的 [1] 236分别是该 job 的 job number 与该进程的 PID,而最后一行的 Done 表示该命令已经在后台执行完毕。
- 我们还可以通过
ctrl + z 使我们的当前工作停止并丢到后台中去
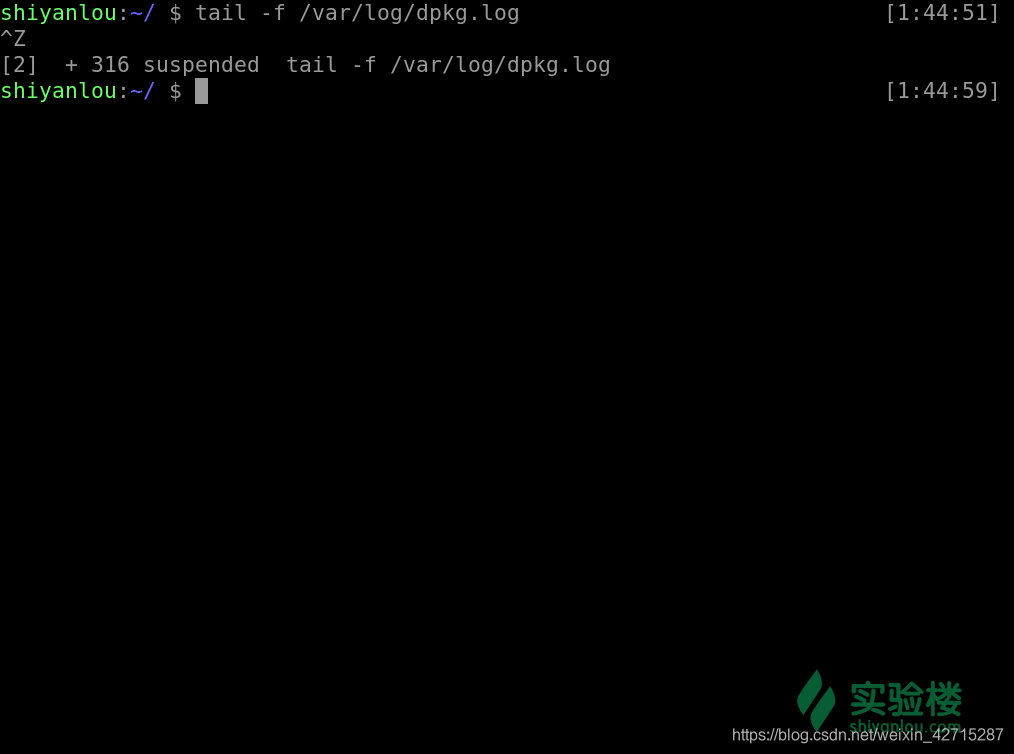
- 被停止并放置在后台的工作我们可以使用这个命令来查看
jobs
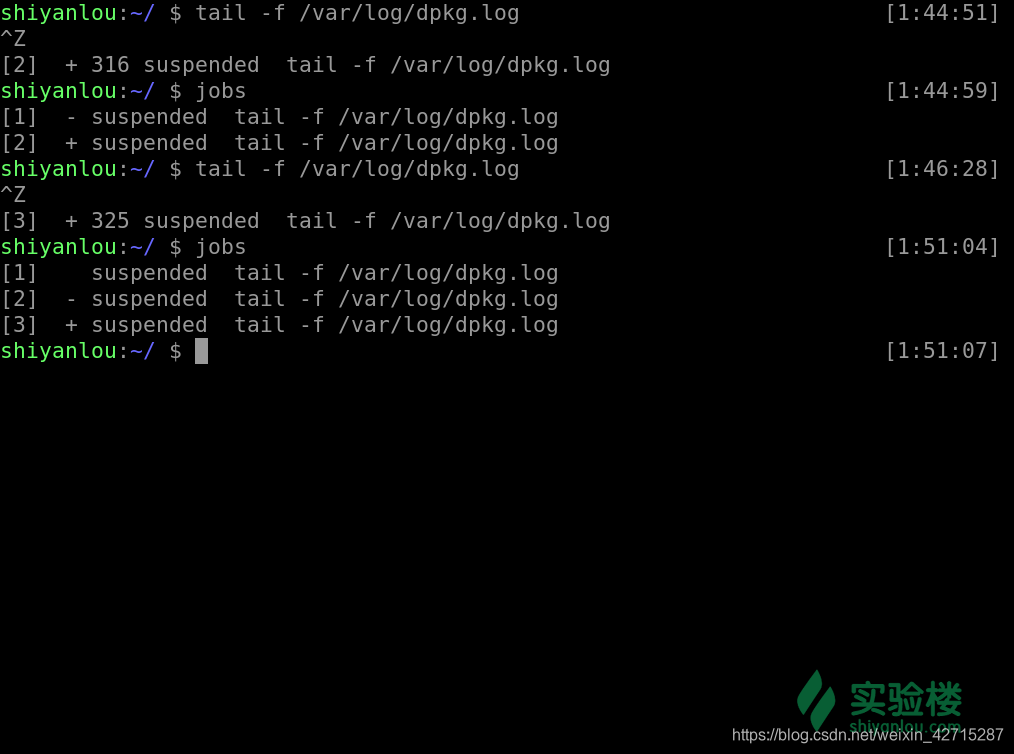
其中第一列显示的为被放置后台 job 的编号,而第二列的 + 表示最近(刚刚、最后)被放置后台的 job,同时也表示预设的工作,也就是若是有什么针对后台 job 的操作,首先对预设的 job,- 表示倒数第二(也就是在预设之前的一个)被放置后台的工作,倒数第三个(再之前的)以后都不会有这样的符号修饰,第三列表示它们的状态,而最后一列表示该进程执行的命令
fg [%jobnumber]
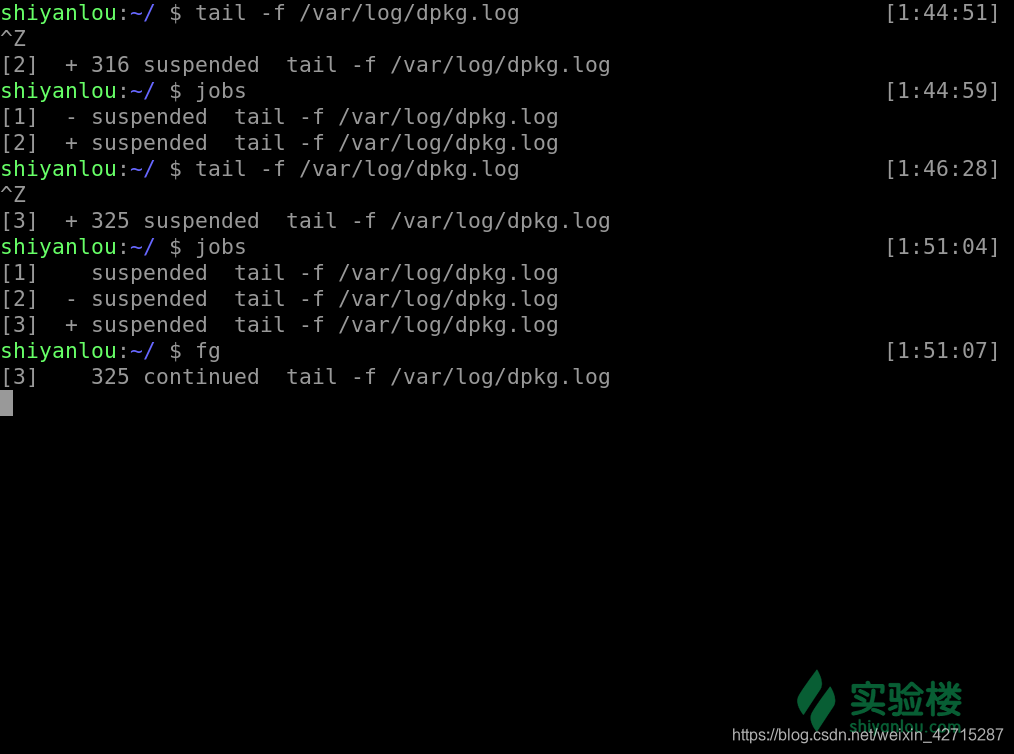
- 之前我们通过
ctrl + z 使得工作停止放置在后台,若是我们想让其在后台运作我们就使用这样一个命令
bg [%jobnumber]

- 既然有方法将被放置在后台的工作提至前台或者让它从停止变成继续运行在后台,当然也有方法删除一个工作,或者重启等等
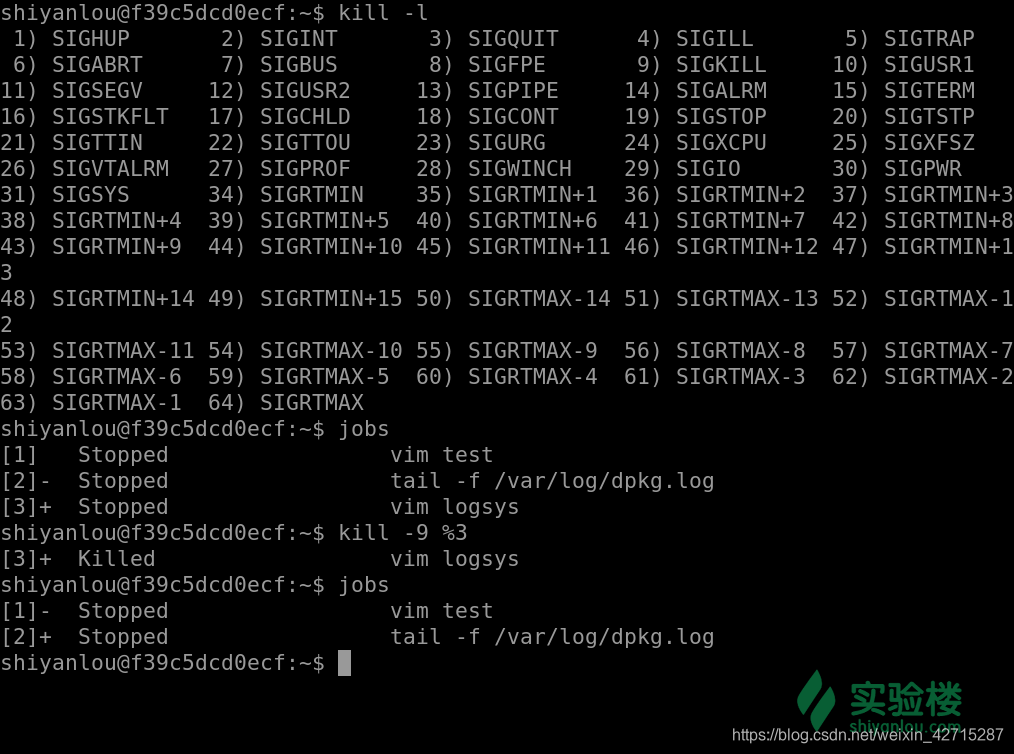
kill -signal %jobnumber
kill -l
其中常用的有这些信号值
| 信号值 | 作用 |
|---|
| -1 | 重新读取参数运行,类似与 restart |
| -2 | 如同 ctrl+c 的操作退出 |
| -9 | 强制终止该任务 |
| -15 | 正常的方式终止该任务 |
注意
若是在使用 kill +信号值然后直接加 pid,你将会对 pid 对应的进程进行操作
若是在使用 kill+信号值然后 %jobnumber,这时所操作的对象是 job,这个数字就是就当前 bash 中后台的运行的 job 的 ID
16、 Linux 进程管理
2、 进程的查看
我们可以通过 top 实时的查看进程的状态,以及系统的一些信息(如 CPU、内存信息等),我们还可以通过 ps 来静态查看当前的进程信息,同时我们还可以使用 pstree 来查看当前活跃进程的树形结构。
2.1 top 工具的使用
- top 工具是我们常用的一个查看工具,能实时的查看我们系统的一些关键信息的变化:
top
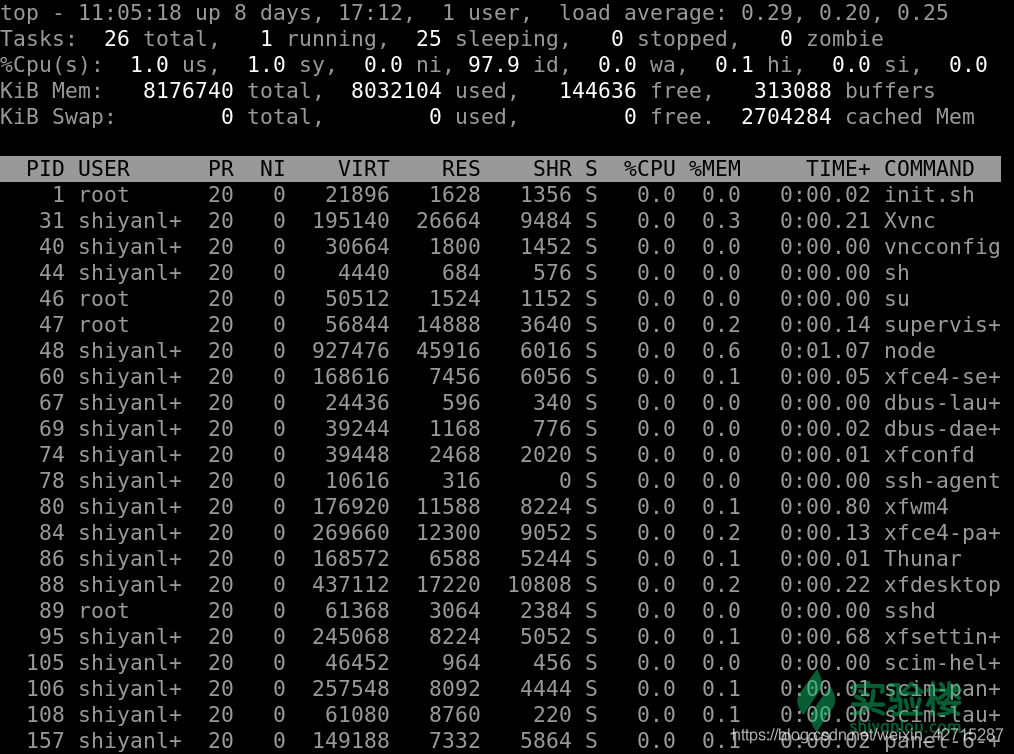
top 是一个在前台执行的程序,所以执行后便进入到这样的一个交互界面,正是因为交互界面我们才可以实时的获取到系统与进程的信息。在交互界面中我们可以通过一些指令来操作和筛选。在此之前我们先来了解显示了哪些信息。
| 内容 | 解释 |
|---|
| top | 表示当前程序的名称 |
| 11:05:18 | 表示当前的系统的时间 |
| up 8 days,17:12 | 表示该机器已经启动了多长时间 |
| 1 user | 表示当前系统中只有一个用户 |
| load average: 0.29,0.20,0.25 | 分别对应 1、5、15 分钟内 cpu 的平均负载 |
load average 在 wikipedia 中的解释是 the system load is a measure of the amount of work that a computer system is doing 也就是对当前 CPU 工作量的度量,具体来说也就是指运行队列的平均长度,也就是等待 CPU 的平均进程数相关的一个计算值。
我们该如何看待这个 load average 数据呢?
假设我们的系统是单 CPU、单内核的,把它比喻成是一条单向的桥,把 CPU 任务比作汽车。
- load = 0 的时候意味着这个桥上并没有车,cpu 没有任何任务;
- load < 1 的时候意味着桥上的车并不多,一切都还是很流畅的,cpu 的任务并不多,资源还很充足;
- load = 1 的时候就意味着桥已经被车给占满了,没有一点空隙,cpu 的已经在全力工作了,所有的资源都被用完了,当然还好,这还在能力范围之内,只是有点慢而已;
- load > 1 的时候就意味着不仅仅是桥上已经被车占满了,就连桥外都被占满了,cpu 已经在全力工作,系统资源的用完了,但是还是有大量的进程在请求,在等待。
- 若是这个值大于2、大于3,表示进程请求超过 CPU 工作能力的 2 到 3 倍。
- 而若是这个值 > 5 说明系统已经在超负荷运作了。
这是单个 CPU 单核的情况,而实际生活中我们需要将得到的这个值除以我们的核数来看。我们可以通过以下的命令来查看 CPU 的个数与核心数
cat /proc/cpuinfo |grep "physical id"|grep "0"|wc -l
通过上面的指数我们可以得知 load 的临界值为 1 ,但是在实际生活中,比较有经验的运维或者系统管理员会将临界值定为 0.7。这里的指数都是除以核心数以后的值,不要混淆了
- 若是 load < 0.7 并不会去关注他;
- 若是 0.7< load < 1 的时候我们就需要稍微关注一下了,虽然还可以应付但是这个值已经离临界不远了;
- 若是 load = 1 的时候我们就需要警惕了,因为这个时候已经没有更多的资源的了,已经在全力以赴了;
- 若是 load > 5 的时候系统已经快不行了,这个时候你需要加班解决问题了
通常我们都会先看 15 分钟的值来看这个大体的趋势,然后再看 5 分钟的值对比来看是否有下降的趋势。
- 查看 busybox 的代码可以知道,数据是每 5 秒钟就检查一次活跃的进程数,然后计算出该值,然后 load 从
/proc/loadavg 中读取的。而这个 load 的值是如何计算的呢,这是 load 的计算的源码
load *= exp; \
load += n*(FIXED_1 - exp); \
load >>= FSHIFT;
unsigned long avenrun[3];
EXPORT_SYMBOL(avenrun);
/*
* calc_load - given tick count, update the avenrun load estimates.
* This is called while holding a write_lock on xtime_lock.
*/
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count += LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
- 我们回归正题,来看 top 的第二行数据,基本上第二行是进程的一个情况统计
| 内容 | 解释 |
|---|
| Tasks: 26 total | 进程总数 |
| 1 running | 1 个正在运行的进程数 |
| 25 sleeping | 25 个睡眠的进程数 |
| 0 stopped | 没有停止的进程数 |
| 0 zombie | 没有僵尸进程数 |
- 来看 top 的第三行数据,这一行基本上是 CPU 的一个使用情况的统计了
| 内容 | 解释 |
|---|
| Cpu(s): 1.0%us | 用户空间进程占用 CPU 百分比 |
| 1.0% sy | 内核空间运行占用 CPU 百分比 |
| 0.0%ni | 用户进程空间内改变过优先级的进程占用 CPU 百分比 |
| 97.9%id | 空闲 CPU 百分比 |
| 0.0%wa | 等待输入输出的 CPU 时间百分比 |
| 0.1%hi | 硬中断(Hardware IRQ)占用 CPU 的百分比 |
| 0.0%si | 软中断(Software IRQ)占用 CPU 的百分比 |
| 0.0%st | (Steal time) 是 hypervisor 等虚拟服务中,虚拟 CPU 等待实际 CPU 的时间的百分比 |
CPU 利用率是对一个时间段内 CPU 使用状况的统计,通过这个指标可以看出在某一个时间段内 CPU 被占用的情况,而 Load Average 是 CPU 的 Load,它所包含的信息不是 CPU 的使用率状况,而是在一段时间内 CPU 正在处理以及等待 CPU 处理的进程数情况统计信息,这两个指标并不一样。
- 来看 top 的第四行数据,这一行基本上是内存的一个使用情况的统计了:
| 内容 | 解释 |
|---|
| 8176740 total | 物理内存总量 |
| 8032104 used | 使用的物理内存总量 |
| 144636 free | 空闲内存总量 |
| 313088 buffers | 用作内核缓存的内存量 |
注意
系统中可用的物理内存最大值并不是 free 这个单一的值,而是 free + buffers + swap 中的 cached 的和
- 来看 top 的第五行数据,这一行基本上是交换区的一个使用情况的统计了
内容 解释
-------- | -----
total |交换区总量
used |使用的交换区总量
free |空闲交换区总量
cached |缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖
| 列名 | 解释 |
|---|
| PID | 进程 id |
| USER | 该进程的所属用户 |
| PR | 该进程执行的优先级 priority 值 |
| NI | 该进程的 nice 值 |
| VIRT | 该进程任务所使用的虚拟内存的总数 |
| RES | 该进程所使用的物理内存数,也称之为驻留内存数 |
| SHR | 该进程共享内存的大小 |
| S | 该进程进程的状态: S=sleep R=running Z=zombie |
| %CPU | 该进程 CPU 的利用率 |
| %MEM | 该进程内存的利用率 |
| TIME+ | 该进程活跃的总时间 |
| COMMAND | 该进程运行的名字 |
注意
NICE 值叫做静态优先级,是用户空间的一个优先级值,其取值范围是-20 至 19。这个值越小,表示进程”优先级”越高,而值越大“优先级”越低。nice 值中的 -20 到 19,中 -20 优先级最高, 0 是默认的值,而 19 优先级最低
PR 值表示 Priority 值叫动态优先级,是进程在内核中实际的优先级值,进程优先级的取值范围是通过一个宏定义的,这个宏的名称是 MAX_PRIO,它的值为 140。Linux 实际上实现了 140 个优先级范围,取值范围是从 0-139,这个值越小,优先级越高。而这其中的 0 - 99 是实时进程的值,而 100 - 139 是给用户的。
其中 PR 中的 100-139 值部分有这么一个对应 PR = 20 + (-20 to +19),这里的 -20 to +19 便是 nice 值,所以说两个虽然都是优先级,而且有千丝万缕的关系,但是他们的值,他们的作用范围并不相同
VIRT任务所使用的虚拟内存的总数,其中包含所有的代码,数据,共享库和被换出 swap 空间的页面等所占据空间的总数
- 在上文我们曾经说过 top 是一个前台程序,所以是一个可以交互的
| 常用交互命令 | 解释 |
|---|
| q | 退出程序 |
| I | 切换显示平均负载和启动时间的信息 |
| P | 根据 CPU 使用百分比大小进行排序 |
| M | 根据驻留内存大小进行排序 |
| i | 忽略闲置和僵死的进程,这是一个开关式命令 |
| k | 终止一个进程,系统提示输入 PID 及发送的信号值。一般终止进程用 15 信号,不能正常结束则使用 9 信号。安全模式下该命令被屏蔽。 |
好好的利用 top 能够很有效的帮助我们观察到系统的瓶颈所在,或者是系统的问题所在。
2.2 ps 工具的使用
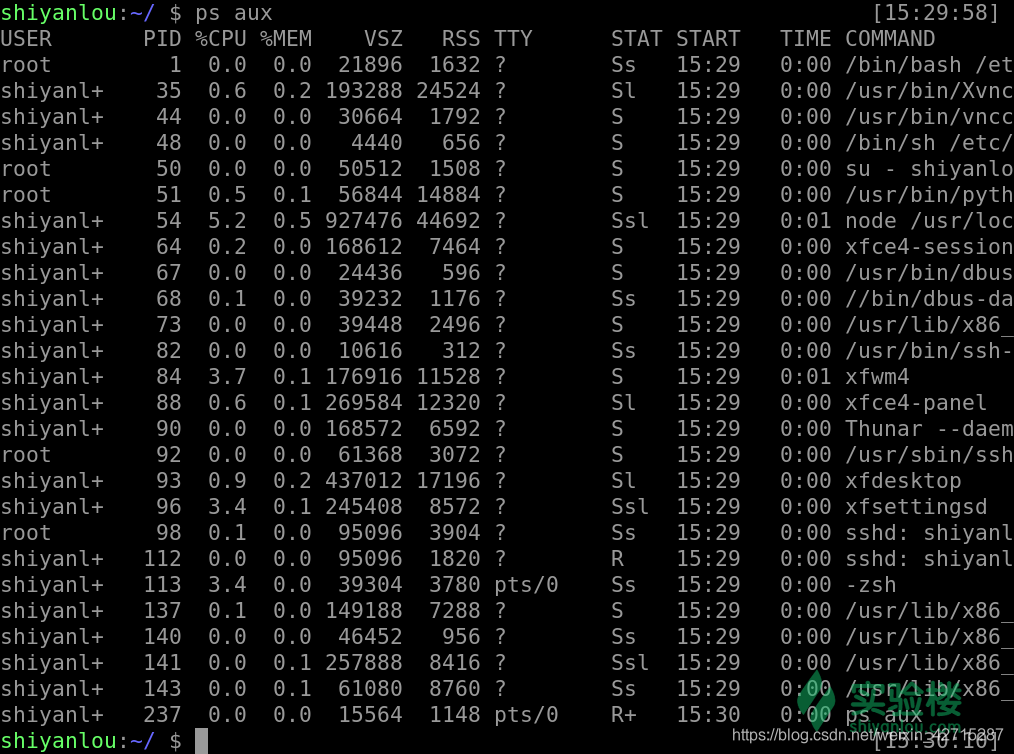
ps 也是我们最常用的查看进程的工具之一,我们通过这样的一个命令来了解一下,他能给我带来哪些信息
ps aux
ps axjf
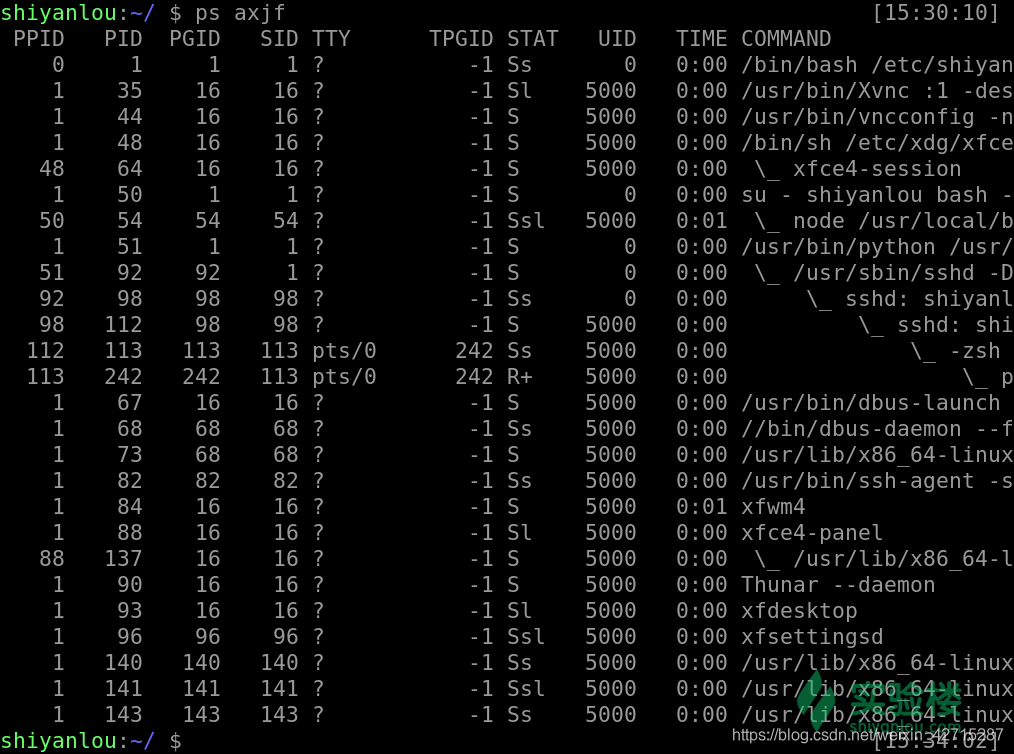
我们来总体了解下会出现哪些信息给我们,这些信息又代表着什么(更多的 keywords 大家可以通过 man ps 了解)
| 内容 | 解释 |
|---|
| F | 进程的标志(process flags),当 flags 值为 1 则表示此子程序只是 fork 但没有执行 exec,为 4 表示此程序使用超级管理员 root 权限 |
| USER | 进程的拥有用户 |
| PID | 进程的 ID |
| PPID | 其父进程的 PID |
| SID | session 的 ID |
| TPGID | 前台进程组的 ID |
| %CPU | 进程占用的 CPU 百分比 |
| %MEM | 占用内存的百分比 |
| NI | 进程的 NICE 值 |
| VSZ | 进程使用虚拟内存大小 |
| RSS | 驻留内存中页的大小 |
| TTY | 终端 ID |
| S or STAT | 进程状态 |
| WCHAN | 正在等待的进程资源 |
| START | 启动进程的时间 |
| TIME | 进程消耗 CPU 的时间 |
| COMMAND | 命令的名称和参数 |
TPGID栏写着-1 的都是没有控制终端的进程,也就是守护进程
STAT表示进程的状态,而进程的状态有很多,如下表所示
| 状态 | 解释 |
|---|
| R | Running.运行中 |
| S | Interruptible Sleep.等待调用 |
| D | Uninterruptible Sleep.不可中断睡眠 |
| T | Stoped.暂停或者跟踪状态 |
| X | Dead.即将被撤销 |
| Z | Zombie.僵尸进程 |
| W | Paging.内存交换 |
| N | 优先级低的进程 |
| < | 优先级高的进程 |
| s | 进程的领导者 |
| L | 锁定状态 |
| l | 多线程状态 |
| + | 前台进程 |
其中的 D 是不能被中断睡眠的状态,处在这种状态的进程不接受外来的任何 signal,所以无法使用 kill 命令杀掉处于 D 状态的进程,无论是 kill,kill -9 还是 kill -15,一般处于这种状态可能是进程 I/O 的时候出问题了。
ps 工具有许多的参数,下面给大家解释部分常用的参数
- 使用
-l 参数可以显示自己这次登录的 bash 相关的进程信息罗列出来
ps -l
- 相对来说我们更加常用下面这个命令,他将会罗列出所有的进程信息
ps aux
- 若是查找其中的某个进程的话,我们还可以配合着 grep 和正则表达式一起使用
ps aux | grep zsh
- 此外我们还可以查看时,将连同部分的进程呈树状显示出来
ps axjf
- 当然如果你觉得使用这样的此时没有把你想要的信息放在一起,我们也可以是用这样的命令,来自定义我们所需要的参数显示
ps -afxo user,ppid,pid,pgid,command
2.3 pstree 工具的使用
通过 pstree 可以很直接的看到相同的进程数量,最主要的还是我们可以看到所有进程之间的相关性。
pstree
pstree -up
3、进程的管理
3.1 kill 命令的掌握
上个实验中我们讲诉了进程之间是如何衍生,之间又有什么相关性,我们来回顾一下,当一个进程结束的时候或者要异常结束的时候,会向其父进程返回一个或者接收一个 SIGHUP 信号而做出的结束进程或者其他的操作,这个 SIGHUP 信号不仅可以由系统发送,我们可以使用 kill 来发送这个信号来操作进程的结束或者重启等等。
上节课程我们使用 kill 命令来管理我们的一些 job,这节课我们将尝试用 kill 来操作下一些不属于 job 范畴的进程,直接对 pid 下手
ps aux
kill -9 1608
ps aux | grep gedit
3.2 进程的执行顺序
我们在使用 ps 命令的时候可以看到大部分的进程都是处于休眠的状态,如果这些进程都被唤醒,那么该谁最先享受 CPU 的服务,后面的进程又该是一个什么样的顺序呢?进程调度的队列又该如何去排列呢?
当然就是靠该进程的优先级值来判定进程调度的优先级,而优先级的值就是上文所提到的 PR 与 nice 来控制与体现了
而 nice 的值我们是可以通过 nice 命令来修改的,而需要注意的是 nice 值可以调整的范围是 -20 ~ 19,其中 root 有着至高无上的权力,既可以调整自己的进程也可以调整其他用户的程序,并且是所有的值都可以用,而普通用户只可以调制属于自己的进程,并且其使用的范围只能是 0 ~ 19,因为系统为了避免一般用户抢占系统资源而设置的一个限制
nice -n -5 vim &
ps -afxo user,ppid,pid,stat,pri,ni,time,command | grep vim
我们还可以用 renice 来修改已经存在的进程的优先级,同样因为权限的原因在实验环境中无法尝试
renice -5 pid
17、Linux 日志系统
日志数据可以是有价值的信息宝库,也可以是毫无价值的数据泥潭。它可以记录下系统产生的所有行为,并按照某种规范表达出来。我们可以使用日志系统所记录的信息为系统进行排错,优化系统的性能,或者根据这些信息调整系统的行为。收集你想要的数据,分析出有价值的信息,可以提高系统、产品的安全性,还可以帮助开发完善代码,优化产品。日志会成为在事故发生后查明“发生了什么”的一个很好的“取证”信息来源。日志可以为审计进行审计跟踪。
2、常见的日志
日志是一个系统管理员,一个运维人员,甚至是开发人员不可或缺的东西,系统用久了偶尔也会出现一些错误,我们需要日志来给系统排错,在一些网络应用服务不能正常工作的时候,我们需要用日志来做问题定位,日志还是过往时间的记录本,我们可以通过它知道我们是否被不明用户登录过等等。
在 Linux 中大部分的发行版都内置使用 syslog 系统日志,那么通过前期的课程我们了解到常见的日志一般存放在 /var/log 中,我们来看看其中有哪些日志
ll /var/log
我们可以根据服务对象粗略的将日志分为两类
系统日志主要是存放系统内置程序或系统内核之类的日志信息如 alternatives.log 、btmp 等等,
应用日志主要是我们装的第三方应用所产生的日志如 tomcat7 、apache2 等等。
接下来我们来看看常见的系统日志有哪些,他们都记录了怎样的信息
| 日志名称 | 记录信息 |
|---|
| alternatives.log | 系统的一些更新替代信息记录 |
| apport.log | 应用程序崩溃信息记录 |
| apt/history.log | 使用 apt-get 安装卸载软件的信息记录 |
| apt/term.log | 使用 apt-get 时的具体操作,如 package 的下载、打开等 |
| auth.log | 登录认证的信息记录 |
| boot.log | 系统启动时的程序服务的日志信息 |
| btmp | 错误的信息记录 |
| Consolekit/history | 控制台的信息记录 |
| dist-upgrade | dist-upgrade 这种更新方式的信息记录 |
| dmesg | 启动时,显示屏幕上内核缓冲信息,与硬件有关的信息 |
| dpkg.log | dpkg 命令管理包的日志。 |
| faillog | 用户登录失败详细信息记录 |
| fontconfig.log | 与字体配置有关的信息记录 |
| kern.log | 内核产生的信息记录,在自己修改内核时有很大帮助 |
| lastlog | 用户的最近信息记录 |
| wtmp | 登录信息的记录。wtmp 可以找出谁正在进入系统,谁使用命令显示这个文件或信息等 |
| syslog | 系统信息记录 |
而在本实验环境中没有 apport.log 是因为 apport 这个应用程序需要读取一些内核的信息来收集判断其他应用程序的信息,从而记录应用程序的崩溃信息。而在本实验环境中我们没有这个权限,所以将 apport 从内置应用值剔除,自然而然就没有它的日志信息了。
只闻其名,不见其人,我们并不能明白这些日志记录的内容。首先我们来看 alternatives.log 中的信息,在本实验环境中没有任何日志输出是因为刚刚启动的系统中并没有任何的更新迭代。我可以看看从其他地方截取过来的内容
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/x-www-browser x-www-browser /usr/bin/google-chrome-stable 200
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/gnome-www-browser gnome-www-browser /usr/bin/google-chrome-stable 200
update-alternatives 2016-07-02 13:36:16: run with --install /usr/bin/google-chrome google-chrome /usr/bin/google-chrome-stable 200
我们可以从中得到的信息有程序作用,日期,命令,成功与否的返回码
我们用这样的命令来看看 auth.log 中的信息
less auth.log
在 apt 文件夹中的日志信息,其中有两个日志文件 history.log 与 term.log,两个日志文件的区别在于 history.log 主要记录了进行了哪个操作,相关的依赖有哪些,而 term.log 则是较为具体的一些操作,主要就是下载包,打开包,安装包等等的细节操作。
我们通过这样的例子就可以很明显的看出区别,在本实验环境中因为是刚启动的环境,所以两个日志中的信息都是空的
less /var/log/apt/history.log
less /var/log/apt/term.log
其他的日志格式也都类似于之前我们所查看的日志,主要便是时间,操作。而这其中有两个比较特殊的日志,其查看的方式比较与众不同,因为这两个日志并不是 ASCII 文件而是被编码成了二进制文件,所以我们并不能直接使用 less、cat、more 这样的工具来查看,这两个日志文件是 wtmp,lastlog
我们查看的方法是使用 last 与 lastlog 工具来提取其中的信息
3、配置的日志
这些日志是如何产生的?通过上面的例子我们可以看出大部分的日志信息似乎格式都很类似,并且都出现在这个文件夹中。
这样的实现可以通过两种方式:
- 一种是由软件开发商自己来自定义日志格式然后指定输出日志位置;
- 一种方式就是 Linux 提供的日志服务程序,而我们这里系统日志是通过 syslog 来实现,提供日志管理服务。
syslog 是一个系统日志记录程序,在早期的大部分 Linux 发行版都是内置 syslog,让其作为系统的默认日志收集工具,虽然随着时代的进步与发展,syslog 已经年老体衰跟不上时代的需求,所以他被 rsyslog 所代替了,较新的 Ubuntu、Fedora 等等都是默认使用 rsyslog 作为系统的日志收集工具
rsyslog 的全称是 rocket-fast system for log,它提供了高性能,高安全功能和模块化设计。rsyslog 能够接受各种各样的来源,将其输入,输出的结果到不同的目的地。rsyslog 可以提供超过每秒一百万条消息给目标文件。
这样能实时收集日志信息的程序是有其守护进程的,如 rsyslog 的守护进程便是 rsyslogd
- 因为一些原因本实验环境中默认并没有打开这个服务,我们可以手动开启这项服务,然后来查看
sudo apt-get update
sudo apt-get install -y rsyslog
sudo service rsyslog start
ps aux | grep syslog
既然它是一个服务,那么它便是可以配置,为我们提供一些我们自定义的服务
首先我们来看 rsyslog 的配置文件是什么样子的,而 rsyslog 的配置文件有两个,
- 一个是
/etc/rsyslog.conf - 一个是
/etc/rsyslog.d/50-default.conf。
第一个主要是配置的环境,也就是 rsyslog 加载什么模块,文件的所属者等;而第二个主要是配置的 Filter Conditions
vim /etc/rsyslog.conf
vim /etc/rsyslog.d/50-default.conf
- rsyslog 的结构框架,数据流的走向
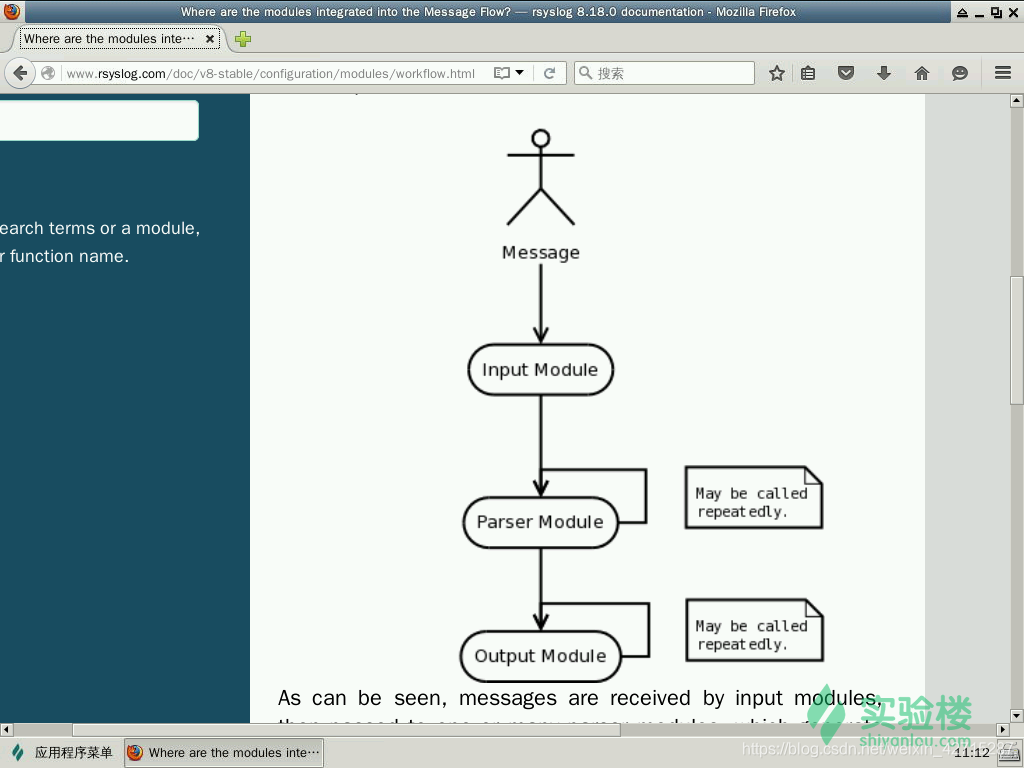
通过这个简单的流程图我们可以知道 rsyslog 主要是由 Input、Output、Parser 这样三个模块构成的,并且了解到数据的简单走向,首先通过 Input module 来收集消息,然后将得到的消息传给 Parser module,通过分析模块的层层处理,将真正需要的消息传给 Output module,然后便输出至日志文件中。
上文提到过 rsyslog 号称可以提供超过每秒一百万条消息给目标文件,怎么只是这样简单的结构。我们可以通过下图来做更深入的了解
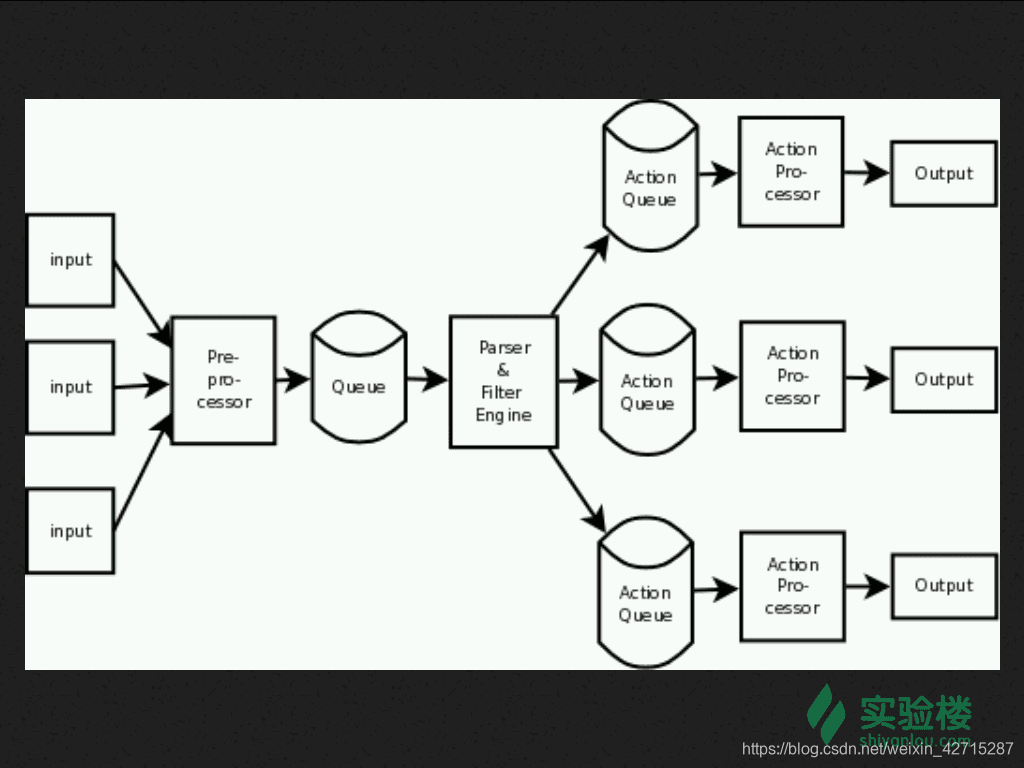
Rsyslog 架构如图中所示,从图中我们可以很清楚的看见,rsyslog 还有一个核心的功能模块便是 Queue,也正是因为它才能做到如此高的并发。
第一个模块便是 Input,该模块的主要功能就是从各种各样的来源收集 messages,通过这些接口实现:
| 接口名 | 作用 |
|---|
| im3195 | RFC3195 Input Module |
| imfile | Text File Input Module |
| imgssapi | GSSAPI Syslog Input Module |
| imjournal | Systemd Journal Input Module |
| imklog | Kernel Log Input Module |
| imkmsg | /dev/kmsg Log Input Module |
| impstats | Generate Periodic Statistics of Internal Counters |
| imptcp | Plain TCP Syslog |
| imrelp | RELP Input Module |
| imsolaris | Solaris Input Module |
| imtcp | TCP Syslog Input Module |
| imudp | UDP Syslog Input Module |
| imuxsock | Unix Socket Input |
4、转储的日志
在本地的机器中每天都有成百上千条日志被写入文件中,更别说是我们的服务器,每天都会有数十兆甚至更多的日志信息被写入文件中,如果是这样的话,每天看着我们的日志文件不断的膨胀,那岂不是要占用许多的空间,所以有个叫 logrotate 的东西诞生了。
logrotate 程序是一个日志文件管理工具。用来把旧的日志文件删除,并创建新的日志文件。我们可以根据日志文件的大小,也可以根据其天数来切割日志、管理日志,这个过程又叫做“转储”。
大多数 Linux 发行版使用 logrotate 或 newsyslog 对日志进行管理。logrotate 程序不但可以压缩日志文件,减少存储空间,还可以将日志发送到指定 E-mail,方便管理员及时查看日志。
显而易见,logrotate 是基于 CRON 来运行的,其脚本是 /etc/cron.daily/logrotate;同时我们可以在 /etc/logrotate 中找到其配置文件
cat /etc/logrotate.conf
weekly //设置每周转储一次(daily、weekly、monthly当然可以使用这些参数每天、星期,月 )
rotate 4 //最多转储4次
create //当转储后文件不存在时创建它
compress //通过gzip压缩方式转储(nocompress可以不压缩)
include /etc/logrotate.d //其他日志文件的转储方式配置文件,包含在该目录下
/var/log/wtmp { //设置/var/log/wtmp日志文件的转储参数
monthly //每月转储
create 0664 root utmp //转储后文件不存在时创建它,文件所有者为root,所属组为utmp,对应的权限为0664
rotate 1 //最多转储一次
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)