日志收集介绍
日志收集的目的:
- 分布式日志数据统一收集,实现集中式查询和管理
- 故障排查
- 安全信息和事件管理
- 报表统计及展示功能
日志收集的价值:
- 日志查询、问题排查、故障恢复和故障自愈
- 应用日志分析,错误报警
- 性能分析,用户行为分析
k8s常用的日志收集方式:
- 在节点上进行收集,基于daemonset部署日志收集容器,实现json-file类型(标准输出/dev/stdout,错误输出/dev/stderr)日志收集
- 使用sidecar容器收集当前Pod内一个或多个业务容器的日志,通常基于emptyDir实现业务容器与sidecar容器之间的日志共享
- 在容器内内置日志收集进程
ES集群部署
使用主机如下:
| IP | 主机名 | 角色 |
|---|
| 192.168.122.30 | es-1.linux.io | elasticsearch、kibana |
| 192.168.122.31 | es-2.linux.io | elasticsearch |
| 192.168.122.32 | es-3.linux.io | elasticsearch |
下载安装
先下载Elastic安装包,下载地址:https://www.elastic.co/cn/downloads/elasticsearch
可以选择下载源码包,也可以选择下载rpm或deb包直接安装。这里选择下载deb包,然后使用dpkg进行安装
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.6-amd64.deb
dpkg -i elasticsearch-7.17.6-amd64.deb
修改elasticsearch配置文件
node1:
root@es-1:~
cluster.name: log-cluster1
node.name: node1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.30
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.32"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-1:~
node2:
root@es-2:~
cluster.name: log-cluster1
node.name: node2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.31
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.33"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-2:~
node3:
root@es-3:~
cluster.name: log-cluster1
node.name: node3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.122.32
http.port: 9200
discovery.seed_hosts: ["192.168.122.30", "192.168.122.31", "192.168.122.32"]
cluster.initial_master_nodes: ["node1", "node2", "node3"]
action.destructive_requires_name: true
root@es-3:~
启动服务
在3个节点分别启动elastic服务
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
systemctl status elasticsearch
检查集群状态
部署kibana
下载deb包,下载地址:https://www.elastic.co/cn/downloads/kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.6-amd64.deb
dpkg -i kibana-7.17.6-amd64.deb
修改kibana配置文件
root@es-1:~
server.port: 5601
server.host: "192.168.122.30"
server.name: "kibana"
elasticsearch.hosts: ["http://192.168.122.30:9200", "http://192.168.122.31:9200", "http://192.168.122.32:9200"]
i18n.locale: "zh-CN"
root@es-1:~
启动kibana
systemctl enable kibana
systemctl start kibana
systemctl status kibana
访问kibana测试
部署zookeeper
使用主机如下
| IP | hostname | 角色 |
|---|
| 192.168.122.33 | kafka-1.linux.io | zookeeper、kafka |
| 192.168.122.34 | kafka-2.linux.io | zookeeper、kafka |
| 192.168.122.35 | kafka-3.linux.io | zookeeper、kafka |
先在3个节点配置java环境
mkdir /usr/local/java
tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/java/
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
java -version
下载安装包,下载地址:https://zookeeper.apache.org/releases.html
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
mkdir /apps
tar xf apache-zookeeper-3.6.3-bin.tar.gz -C /apps/ && cd /apps
ln -s apache-zookeeper-3.6.3-bin zookeeper
修改zookeeper配置,3个节点操作一致,只有myid不同
mkdir -p /data/zookeeper/{data,logs}
cd /apps/zookeeper/
cp conf/zoo_sample.cfg conf/zoo.cfg
cat conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
clientPort=2181
server.0=192.168.122.33:2288:3388
server.1=192.168.122.34:2288:3388
server.2=192.168.122.35:2288:3388
echo 0 >/data/zookeeper/data/myid
启动服务
cat /etc/systemd/system/zookeeper.service
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
ExecStart=/apps/zookeeper/bin/zkServer.sh start
ExecStop=/apps/zookeeper/bin/zkServer.sh stop
ExecReload=/apps/zookeeper/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target
system daemon reload
systemctl restart zookeeper
systemctl status zookeeper
检查zookeeper集群状态
/apps/zookeeper/bin/zkServer.sh status
3个节点,一个为leader,其余两个为follower



部署kafka
和zookeeper部署在相同的主机
下载安装包,下载地址:https://kafka.apache.org/downloads
wget https://archive.apache.org/dist/kafka/3.2.1/kafka_2.12-3.2.1.tgz
tar xf kafka_2.12-3.2.1.tgz -C /apps/ && cd /apps
ln -s kafka_2.12-3.2.1 kafka
修改kafka配置
node1:
mkdir -p /data/kafka/kafka-logs
cd /app/kafka
vim config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.122.33:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
node2:
mkdir -p /data/kafka/kafka-logs
cd /apps/kafka
vim config/server.properties
broker.id=1
listeners=PLAINTEXT://192.168.122.34:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
node3:
mkdir -p /data/kafka/kafka-logs
cd /apps/kafka
vim config/server.properties
broker.id=2
listeners=PLAINTEXT://192.168.122.35:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.122.33:2181,192.168.122.34:2181,192.168.122.35:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
启动kafka
cat /etc/systemd/system/kafka.service
[Unit]
Description=kafka.service
After=network.target remote-fs.target zookeeper.service
[Service]
Type=forking
Environment=JAVA_HOME=/usr/local/java/jdk1.8.0_131
ExecStart=/apps/kafka/bin/kafka-server-start.sh -daemon /apps/kafka/config/server.properties
ExecStop=/apps/kafka/bin/kafka-server-stop.sh
ExecReload=/bin/kill -s HUP $MAINPID
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start kafka
systemctl status kafka
使用Kafka 客户端管理工具 Offset Explorer查看验证kafka集群状态,关于此工具的使用可以参考:https://blog.csdn.net/qq_39416311/article/details/123316904
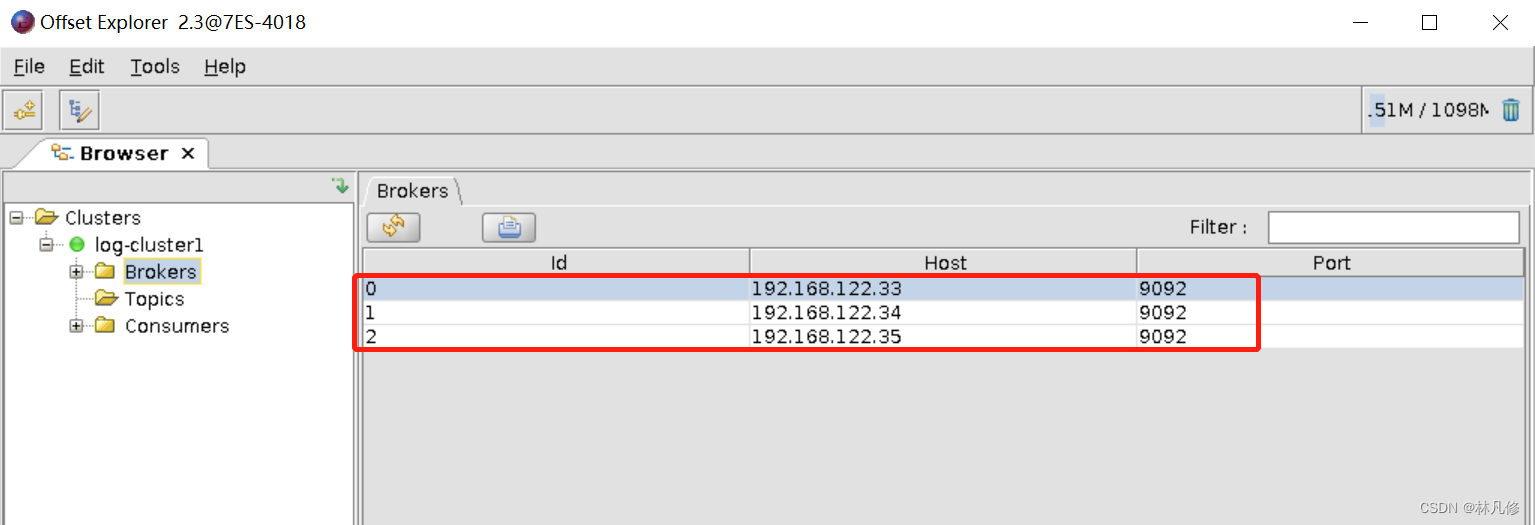
部署Logstash
使用主机如下:
| IP | hostname | 角色 |
|---|
| 192.168.122.36 | logstash-1.linux.io | logstash |
此logstash是用于从kafka获取日志然后写入es
下载安装包,下载地址:https://www.elastic.co/cn/downloads/logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.17.6-amd64.deb
dpkg -i logstash-7.17.6-amd64.deb
启动logstash
systemctl startlogstash
配置日志收集
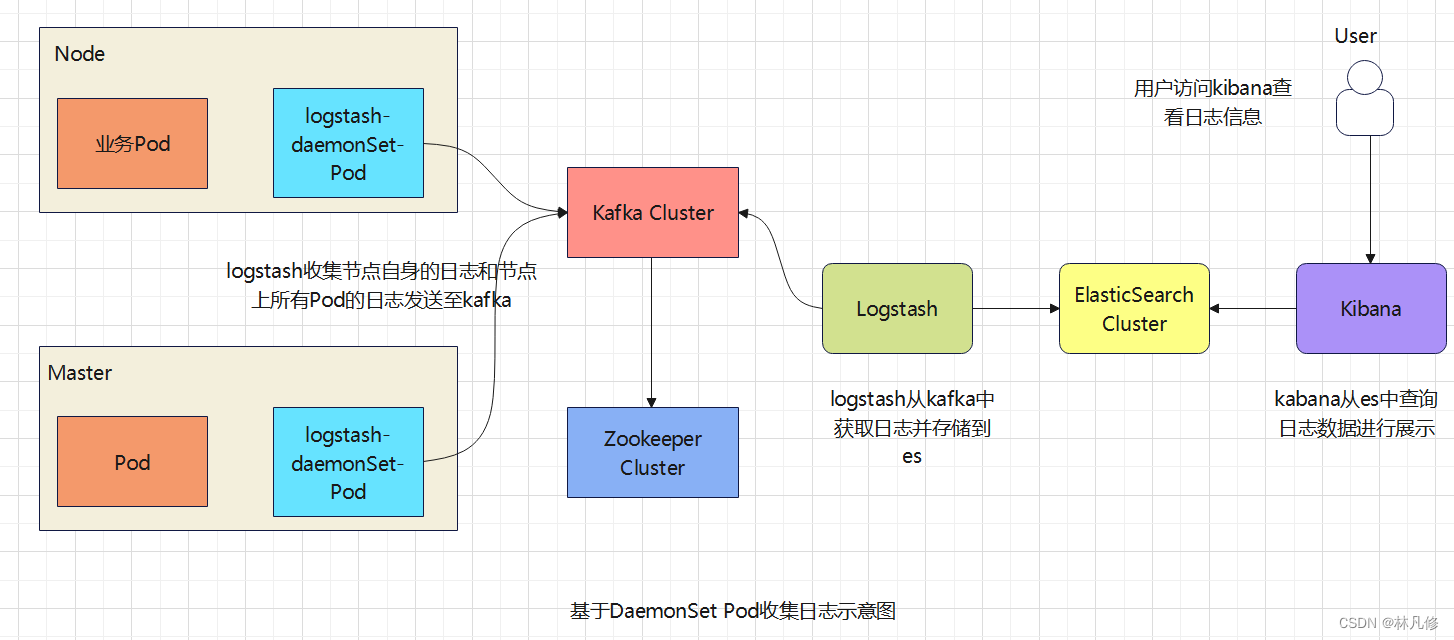
基于daemonset的日志收集
具体流程如下图:
构建logstash镜像
Dockerfile如下:
FROM logstash:7.17.6
LABEL author="admin@163.com"
WORKDIR /usr/share/logstash
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
USER root
RUN usermod -a -G root logstash
logstash.yml内容如下:
http.host: "0.0.0.0"
logstash.conf内容如下:
input {
file {
path => "/var/log/pods/*/*/*.log"
start_position => "beginning"
type => "applog"
}
file {
path => "/var/log/*.log"
start_position => "beginning"
type => "syslog"
}
}
output {
if [type] == "applog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
} }
if [type] == "syslog" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
}}
}
执行构建,上传镜像到harbor
nerdctl build -t harbor-server.linux.io/n70/logstash-daemonset:7.17.6 .
harbor-server.linux.io/n70/logstash-daemonset:7.17.6
部署logstash daemonset
部署文件如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: logstash-daemonset
namespace: log
spec:
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: harbor-server.linux.io/n70/logstash-daemonset:7.17.6
imagePullPolicy: Always
env:
- name: KAFKA_SERVER
value: "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
- name: TOPIC_ID
value: "jsonfile-log-topic"
- name: CODEC
value: "json"
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: False
- name: varlogpods
mountPath: /var/log/pods
readOnly: False
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlogpods
hostPath:
path: /var/log/pods
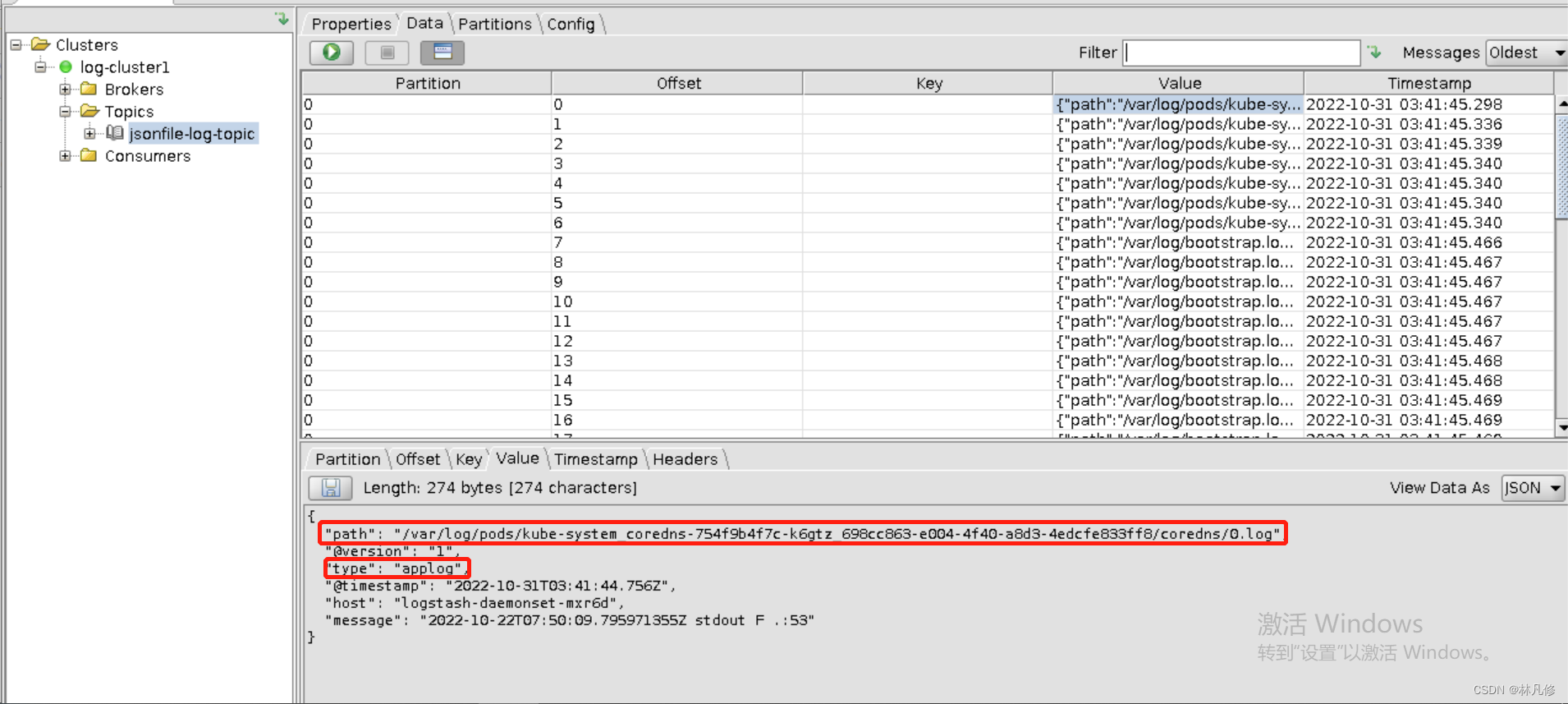
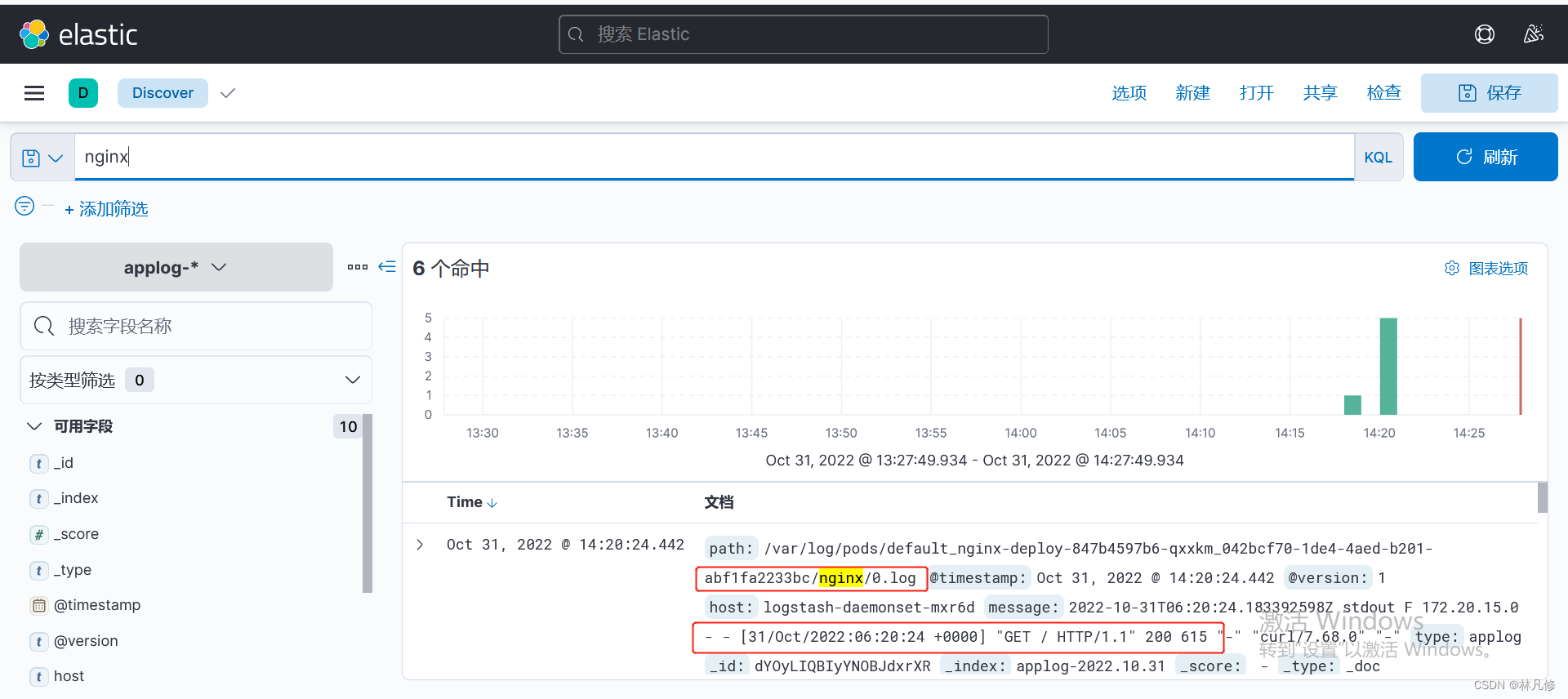
在kafka中进行查看,可以看到日志已经发送到kafka
修改logstash配置
这里的logstash是之前部署在主机上的logstash,而不是Pod。配置其从kafka读取日志然后发送到es
cat /etc/logstash/conf.d/logstash-daemonset-kafka-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["jsonfile-log-topic"]
codec => "json"
}
}
output {
if [type] == "applog" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "applog-%{+YYYY.MM.dd}"
}}
if [type] == "syslog" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}}
}
systemctl restart logstash
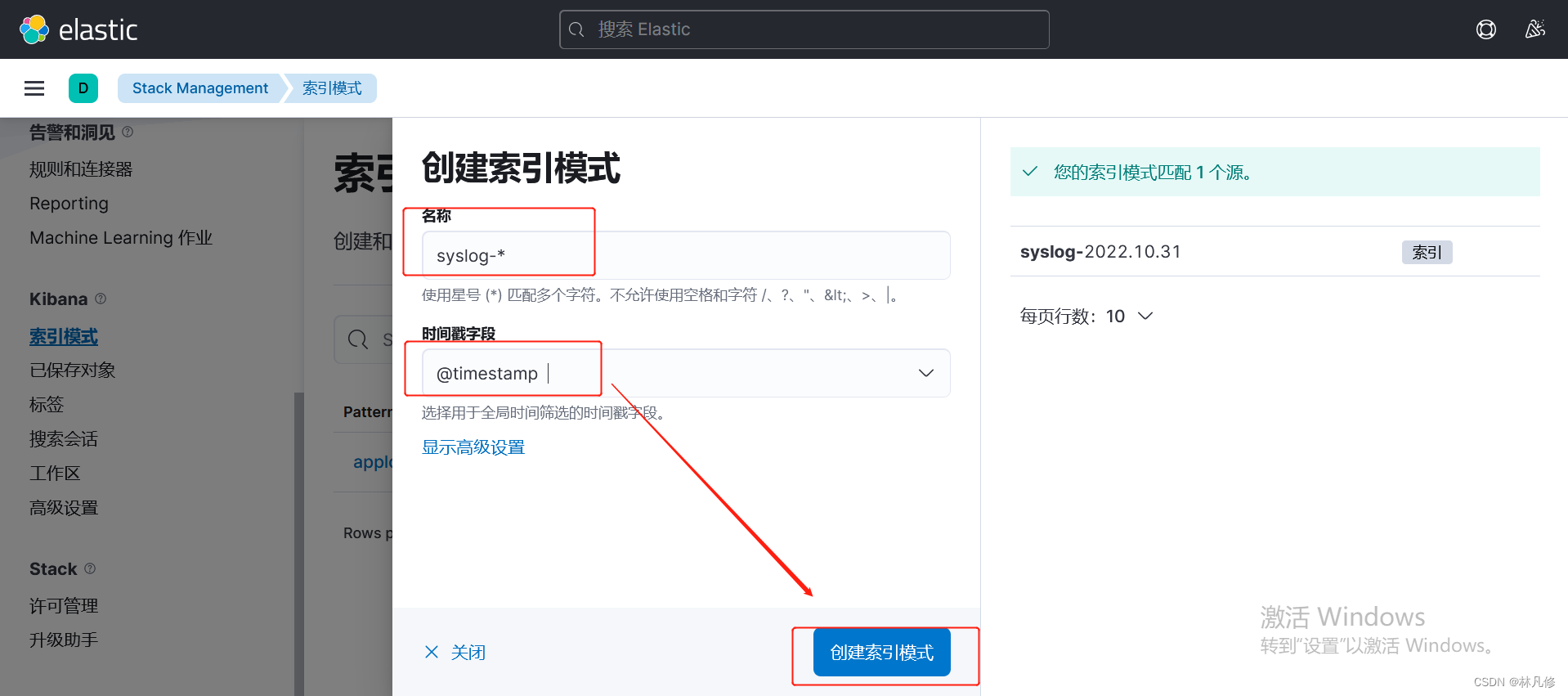
配置kibana展示日志
分别为applog和syslog创建日志索引模式


然后就可以在Discovery页面查看日志
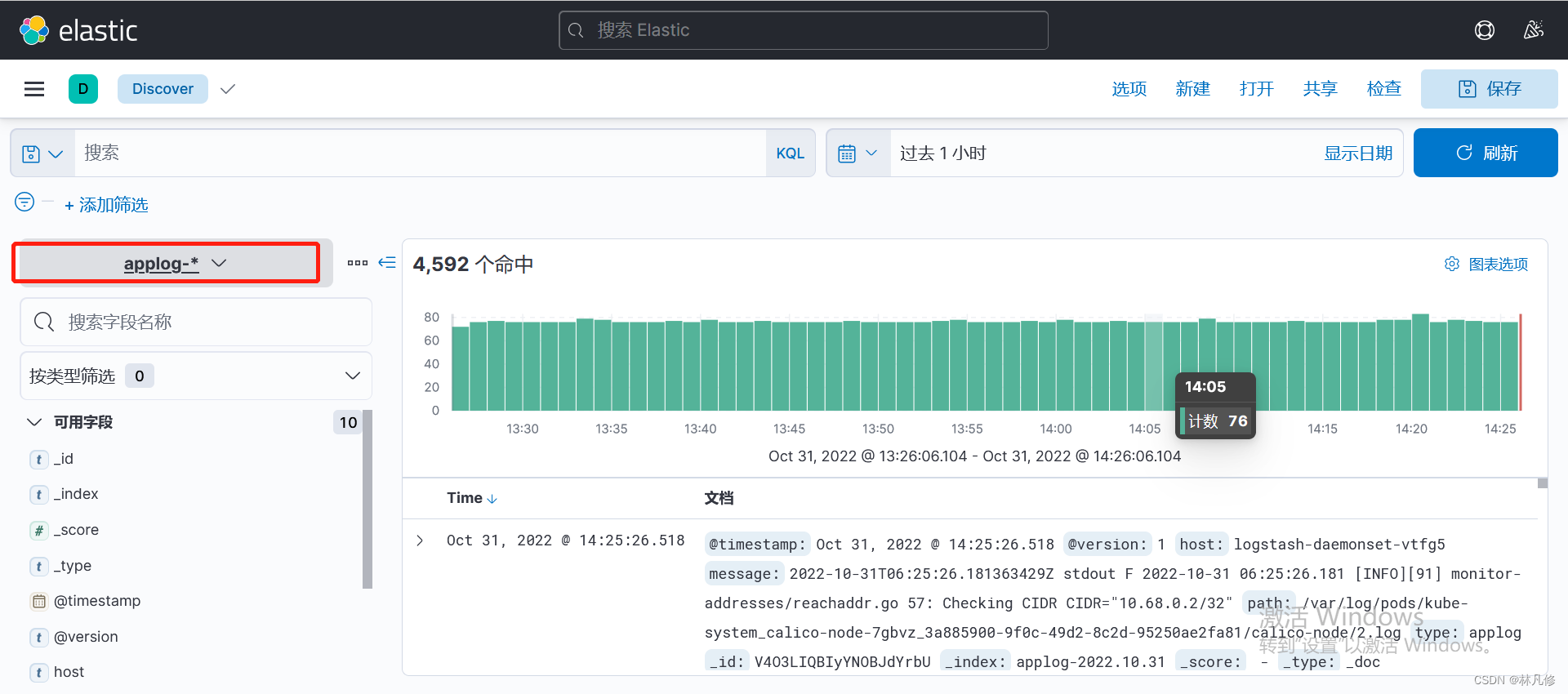
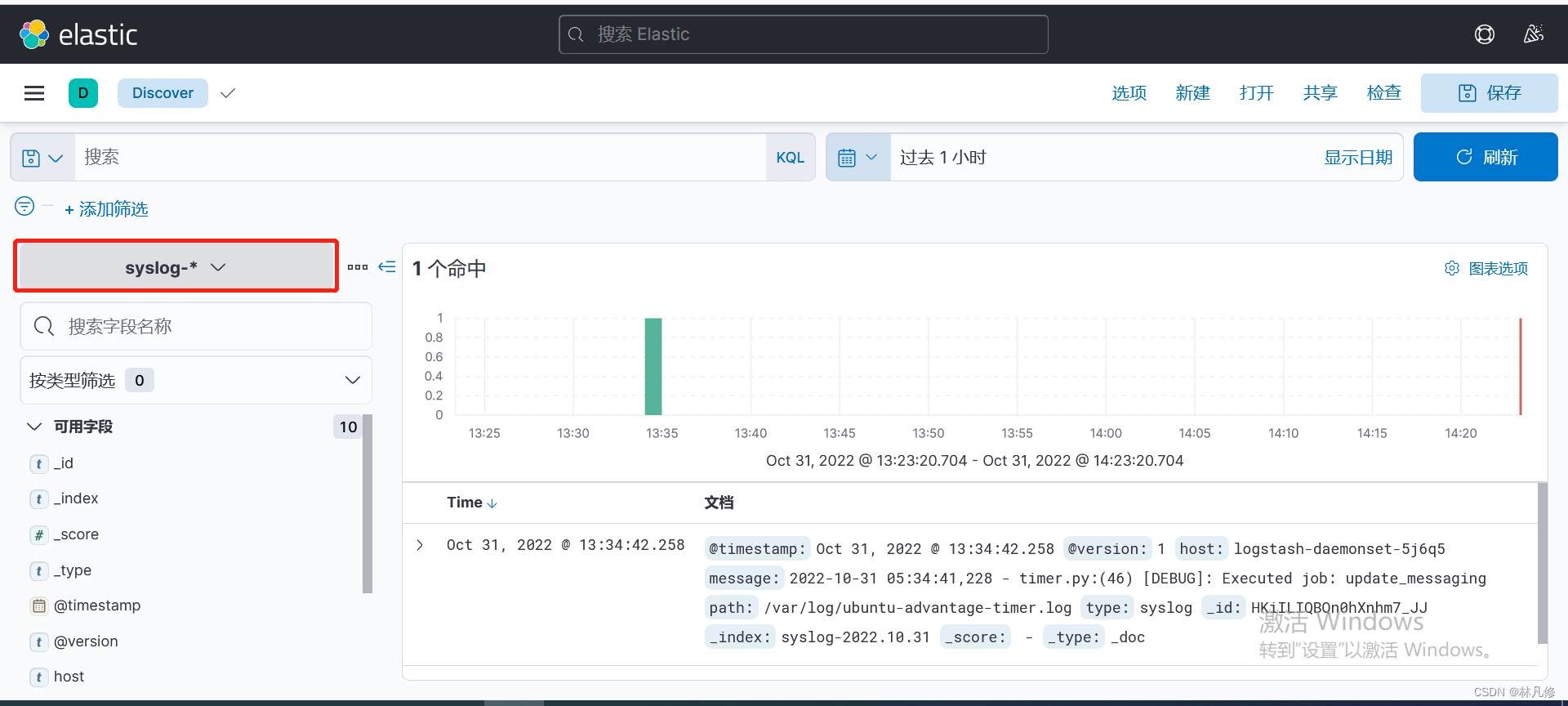
访问nginx Pod产生一些日志,然后使用关键字搜索,如下图,可以看到新产生的容器日志
基于sidecar容器的日志收集
整体流程如下图:
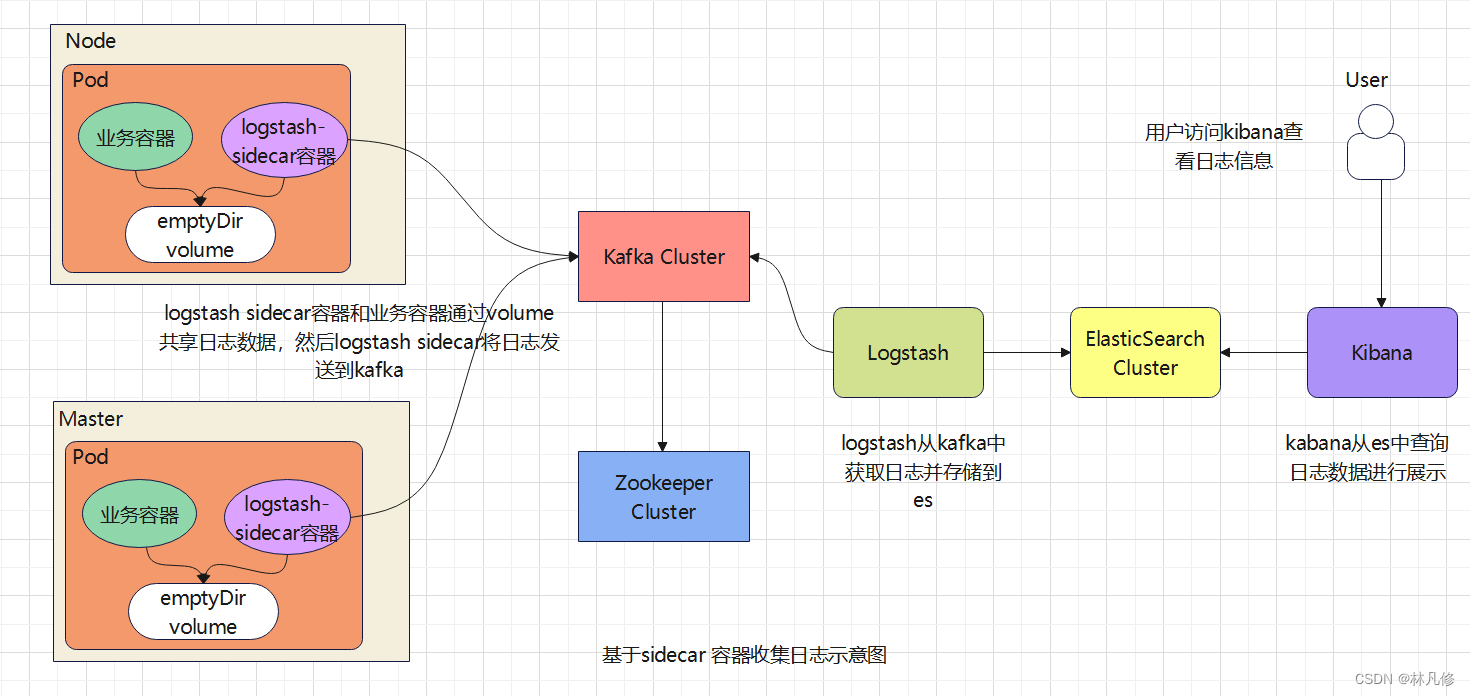
在这种方式下node节点上的日志还是需要部署额外的服务去收集
构建sidecar镜像
sidecar容器也是基于官方logstash镜像构建,Dockerfile如下:
FROM logstash:7.17.6
LABEL author="admin@163.com"
WORKDIR /usr/share/logstash
ADD logstash.yml /usr/share/logstash/config/logstash.yml
ADD logstash.conf /usr/share/logstash/pipeline/logstash.conf
USER root
RUN usermod -a -G root logstash
logstash.yaml内容如下:
http.host: "0.0.0.0"
logstash.conf内容如下:
input {
file {
path => "/var/log/applog/catalina.*.log"
start_position => "beginning"
type => "tomcat-app1-catalina-log"
}
file {
path => "/var/log/applog/localhost_access_log.*.txt"
start_position => "beginning"
type => "tomcat-app1-access-log"
}
}
output {
if [type] == "tomcat-app1-catalina-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
} }
if [type] == "tomcat-app1-access-log" {
kafka {
bootstrap_servers => "${KAFKA_SERVER}"
topic_id => "${TOPIC_ID}"
batch_size => 16384
codec => "${CODEC}"
}}
}
构建镜像,上传到harbor
nerdctl build -t harbor-server.linux.io/n70/logstash-sidecar:7.17.6 .
nerdctl push harbor-server.linux.io/n70/logstash-sidecar:7.17.6
部署业务容器和sidecar容器
部署文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-app1
spec:
replicas: 2
selector:
matchLabels:
app: tomcat-app1
template:
metadata:
labels:
app: tomcat-app1
spec:
containers:
- name: logstash-sidecar
image: harbor-server.linux.io/n70/logstash-sidecar:7.17.6
imagePullPolicy: Always
env:
- name: KAFKA_SERVER
value: "192.168.122.33:9092,192.168.122.34:9092,192.168.122.34:9092"
- name: TOPIC_ID
value: "tomcat-app1-log"
- name: CODEC
value: "json"
volumeMounts:
- name: applog
mountPath: /var/log/applog
- name: tomcat
image: harbor-server.linux.io/n70/tomcat-myapp:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: applog
mountPath: /app/tomcat/logs
volumes:
- name: applog
emptyDir: {}

在kafka中查看,sidecar容器已经将日志发送到kafka
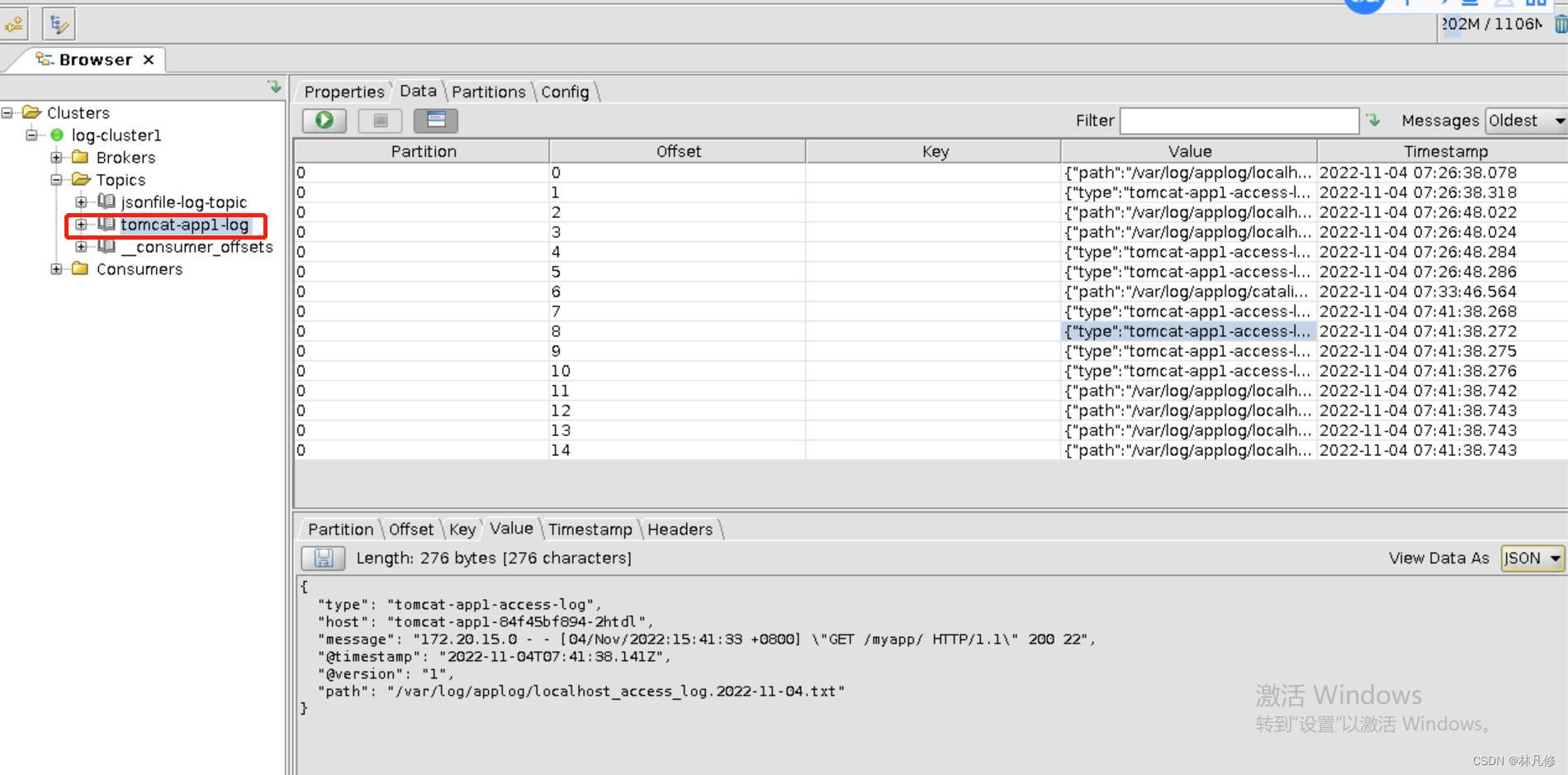
配置logstash
cat logstash-sidercat-kafka-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["tomcat-app1-log"]
codec => "json"
}
}
output {
if [type] == "tomcat-app1-access-log" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32"]
index => "tomcat-app1-accesslog-%{+YYYY.MM.dd}"
}
}
if [type] == "tomcat-app1-catalina-log" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32"]
index => "tomcat-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
}
systemctl restart logstash
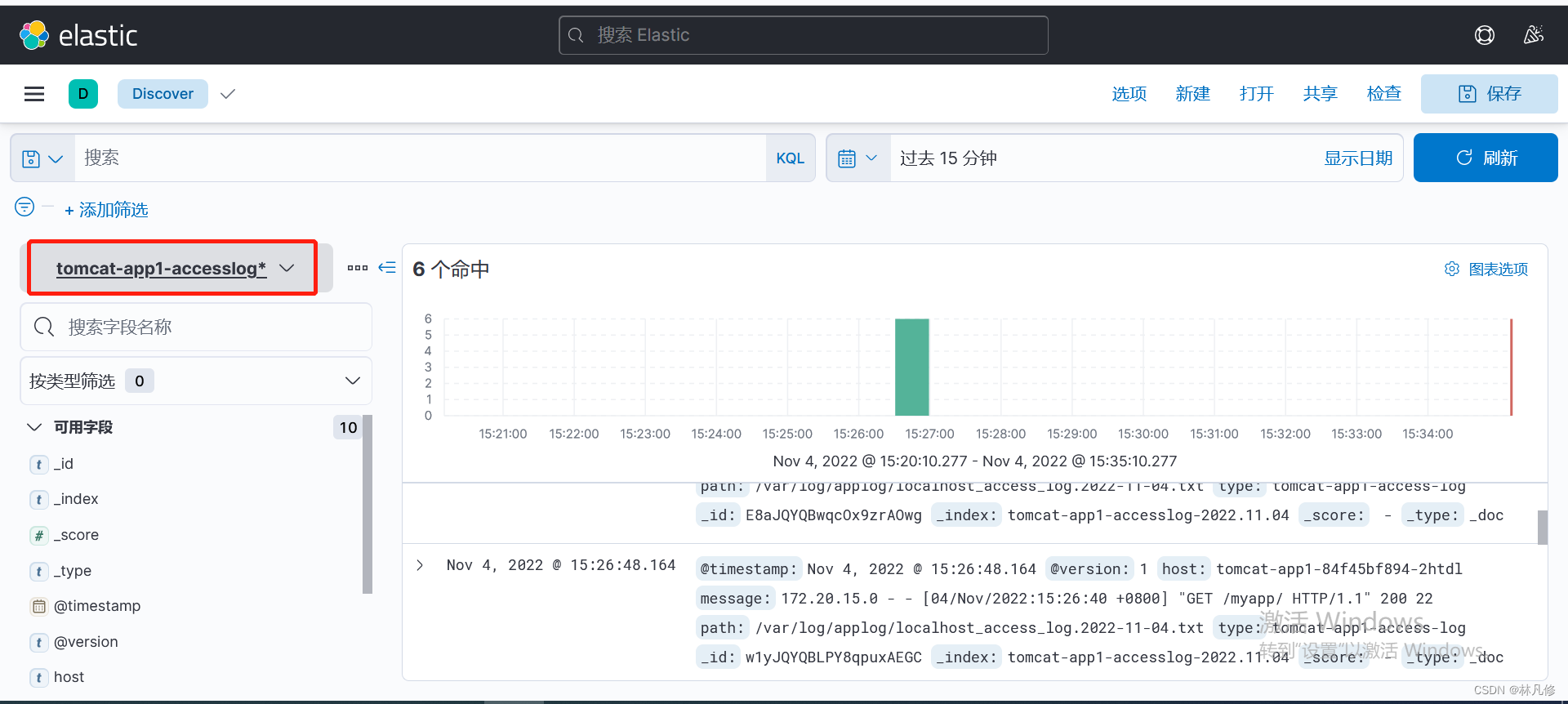
kibana查询日志验证
为tomcat-app1-catalinalog和tomcat-app1-accesslog创建索引
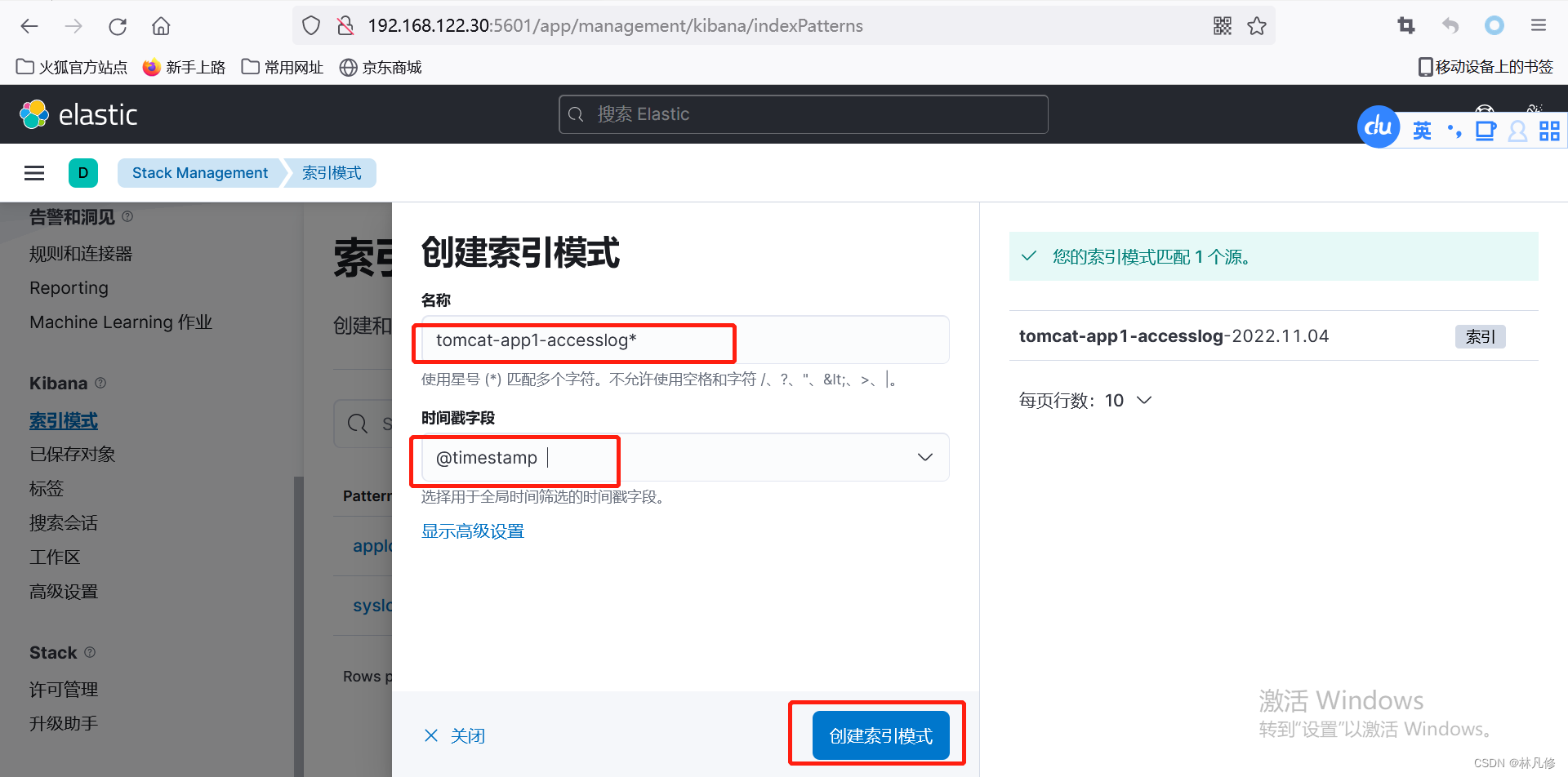
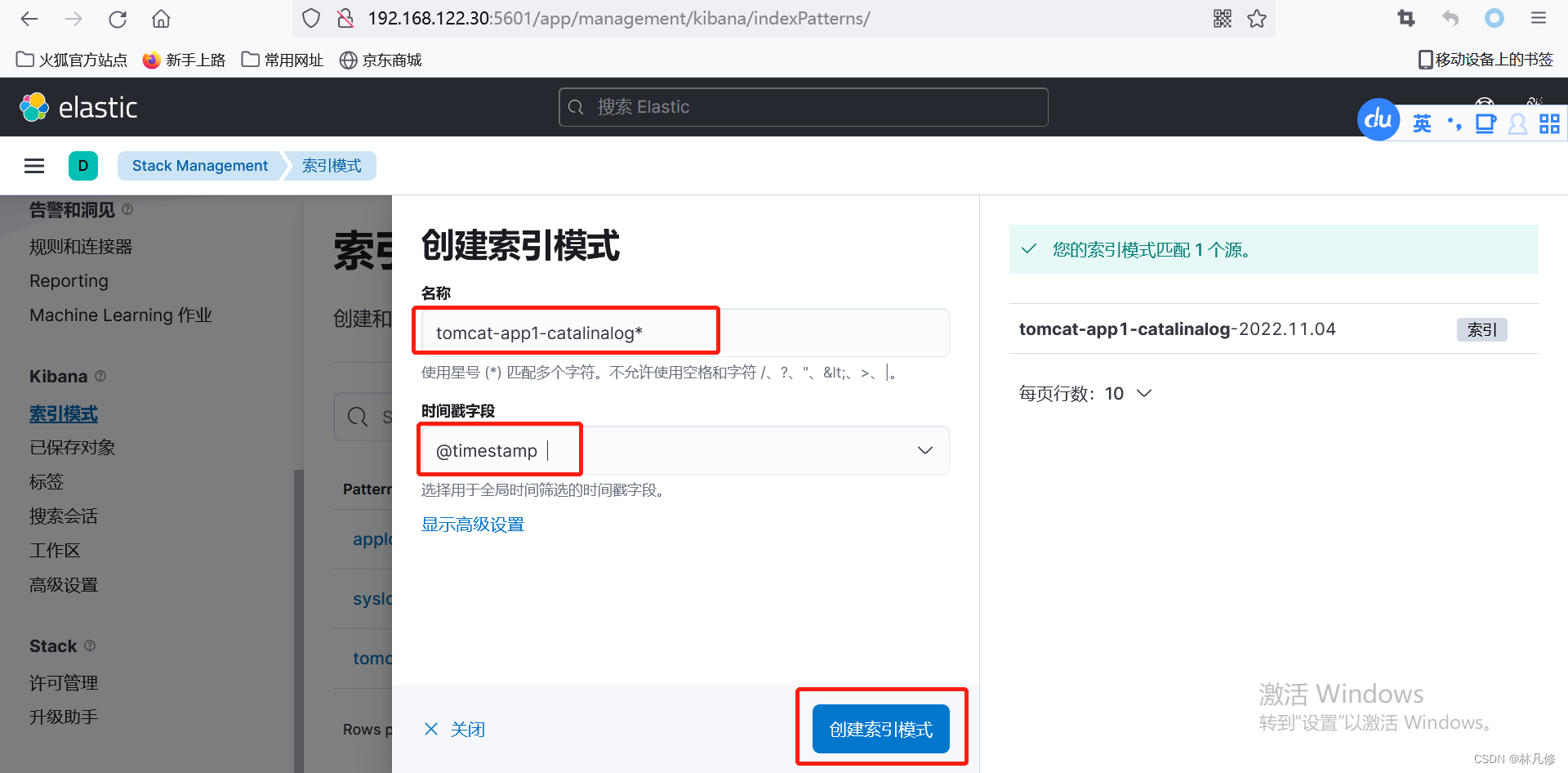
然后就可以在Discovery页面查看相关日志

基于容器内置的日志收集进程的日志收集
整体流程如下图:
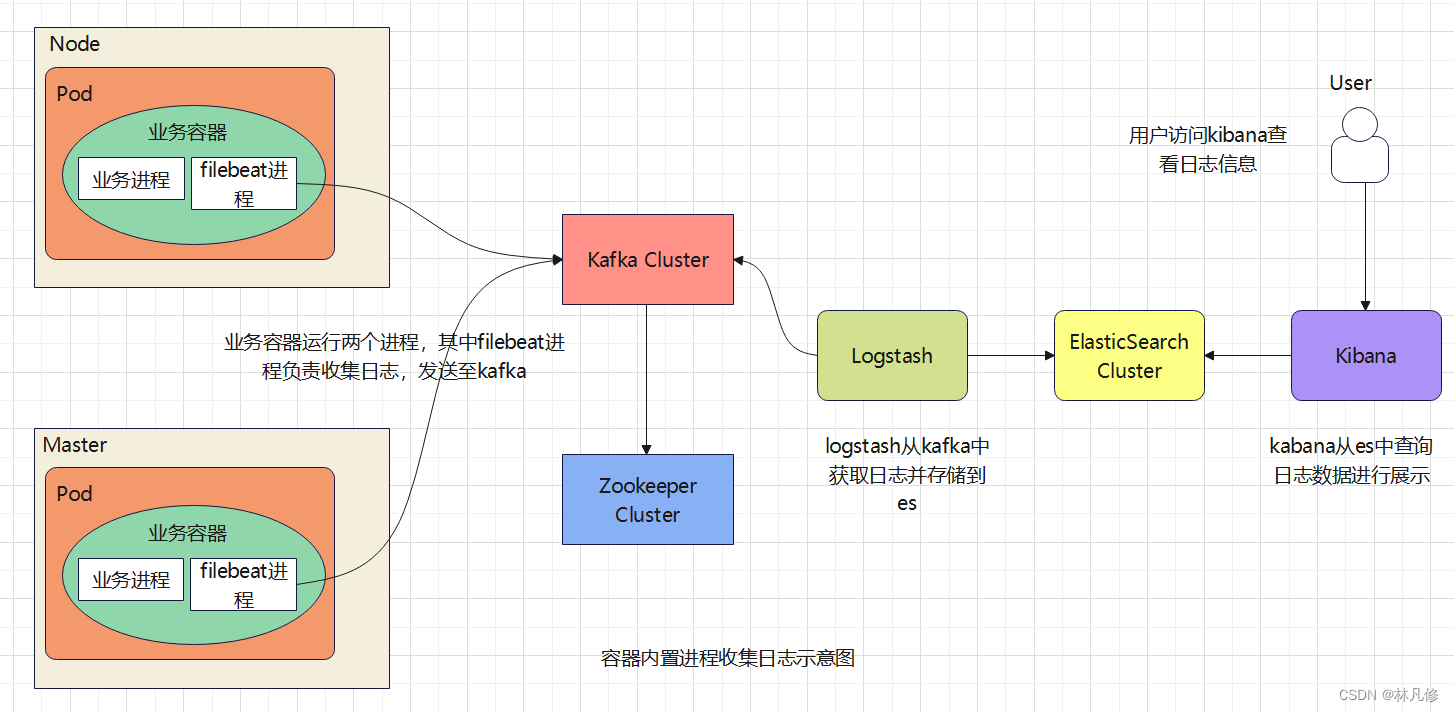
构建业务镜像
业务镜像内需要运行两个进程,一个是tomcat提供web服务,另一个是filebeat负责收集日志。Dockerfile如下:
FROM harbor-server.linux.io/n70/tomcat-myapp:v1
LABEL author="admin@163.com"
ADD filebeat-7.17.6-amd64.deb /tmp/
RUN cd /tmp/ && dpkg -i filebeat-7.17.6-amd64.deb && rm -f filebeat-7.17.6-amd64.deb
ADD filebeat.yml /etc/filebeat/
ADD run.sh /usr/local/bin/
EXPOSE 8443 8080
CMD ["/usr/local/bin/run.sh"]
filebeat.yml内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /apps/tomcat/logs/catalina.*.log
fields:
type: filebeat-tomcat-catalina
- type: log
enabled: true
paths:
- /apps/tomcat/logs/localhost_access_log.*.txt
fields:
type: filebeat-tomcat-accesslog
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.kafka:
hosts: ["192.168.122.33:9092", "192.168.122.34:9092", "192.168.122.35:9092"]
required_acks: 1
topic: "filebeat-tomcat-app1"
compression: gzip
max_message_bytes: 1000000
run.sh内容如下:
#!/bin/bash
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml --path.home /usr/share/filebeat --path.config /etc/filebeat --path.data /var/lib/filebeat --path.logs /var/log/filebeat &
su - tomcat -c "/apps/tomcat/bin/catalina.sh run"
执行构建,上传镜像
nerdctl build -t harbor-server.linux.io/n70/tomcat-myapp:v2 .
nerdctl push harbor-server.linux.io/n70/tomcat-myapp:v2
部署业务容器
部署文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-myapp
spec:
replicas: 3
selector:
matchLabels:
app: tomcat-myapp
template:
metadata:
labels:
app: tomcat-myapp
spec:
containers:
- name: tomcat-myapp
image: harbor-server.linux.io/n70/tomcat-myapp:v2
imagePullPolicy: Always
ports:
- name: http
containerPort: 8080
- name: https
containerPort: 8443

配置logstash
cat /etc/logstash/conf.d/filebeat-process-kafka-to-es.conf
input {
kafka {
bootstrap_servers => "192.168.122.33:9092,192.168.122.34:9092,192.168.122.35:9092"
topics => ["filebeat-tomcat-app1"]
codec => "json"
}
}
output {
if [fields][type] == "filebeat-tomcat-catalina" {
elasticsearch {
hosts => ["192.168.122.30:9200","192.168.122.31:9200","192.168.122.32:9200"]
index => "filebeat-tomcat-catalina-%{+YYYY.MM.dd}"
}}
if [fields][type] == "filebeat-tomcat-accesslog" {
elasticsearch {
hosts => ["172.31.2.101:9200","172.31.2.102:9200"]
index => "filebeat-tomcat-accesslog-%{+YYYY.MM.dd}"
}}
}
systemctl restart logstash
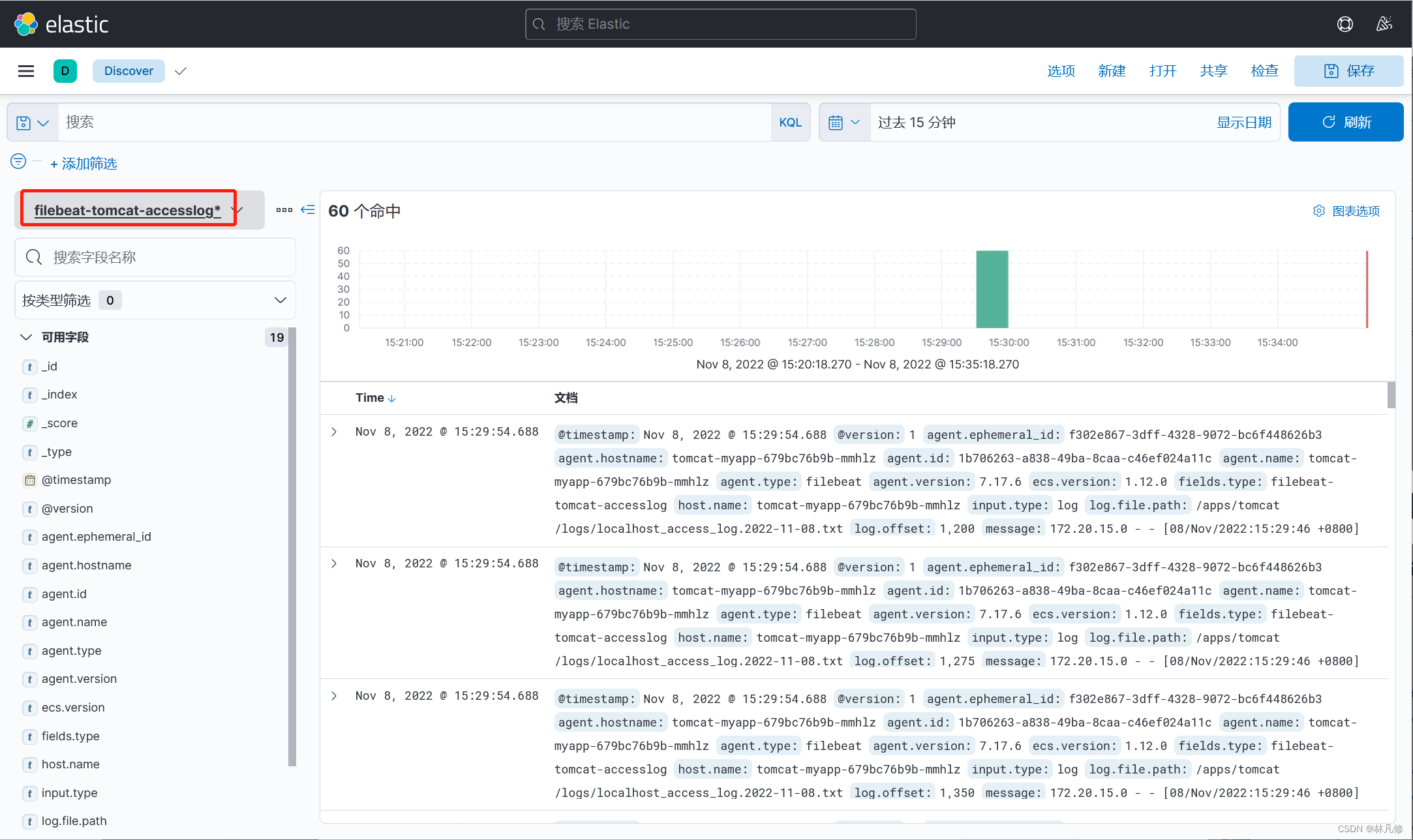
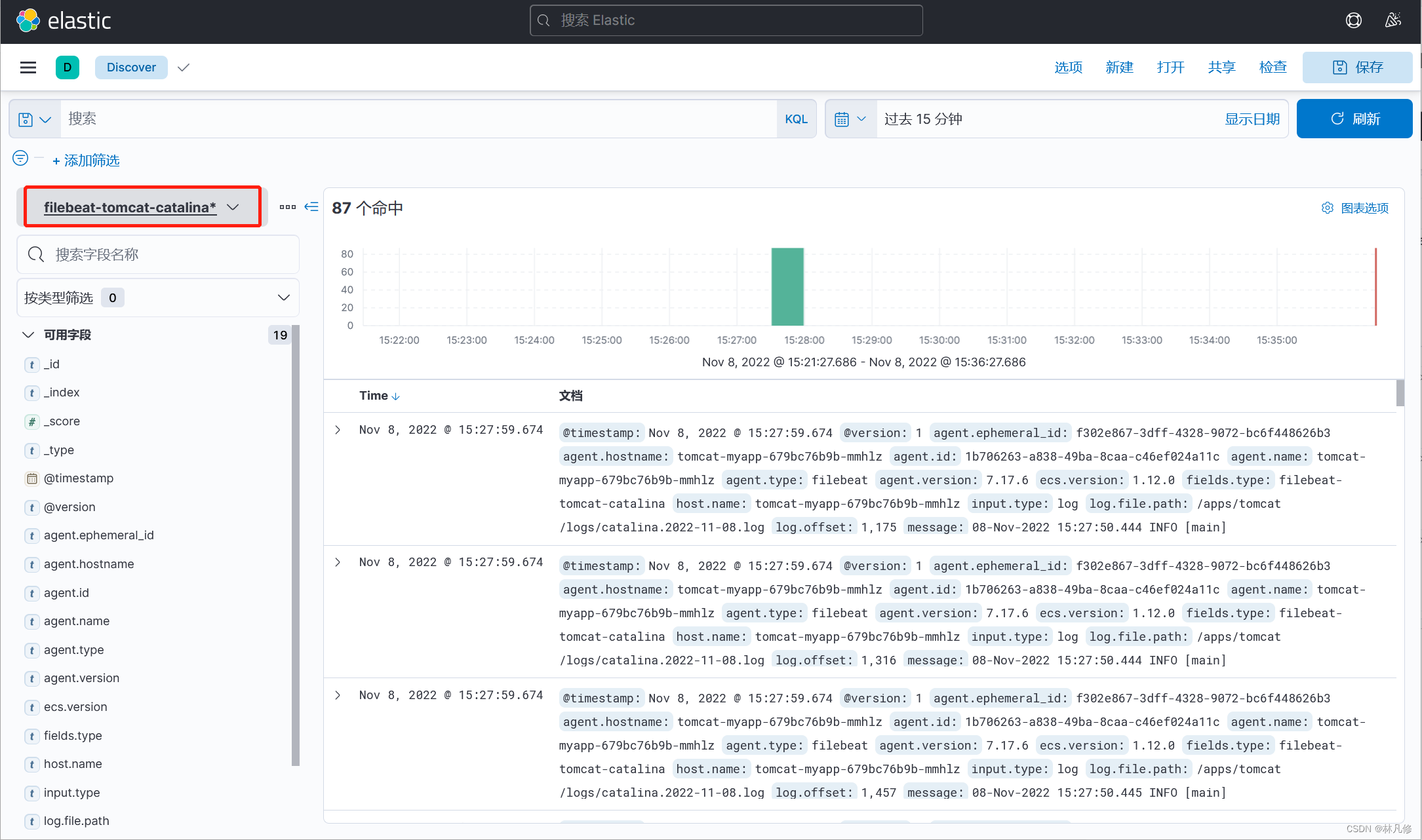
kibana查询日志验证
创建索引模式
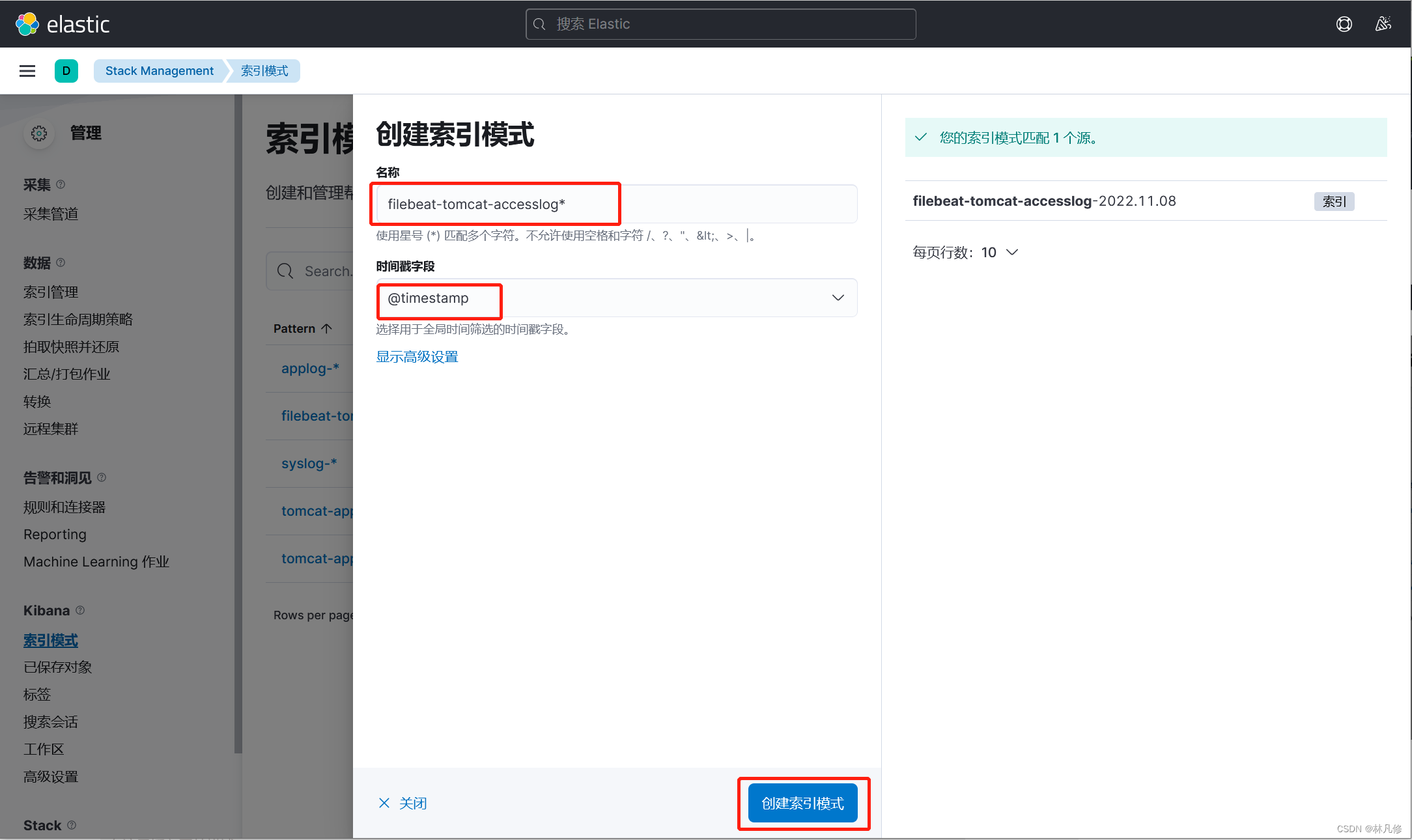
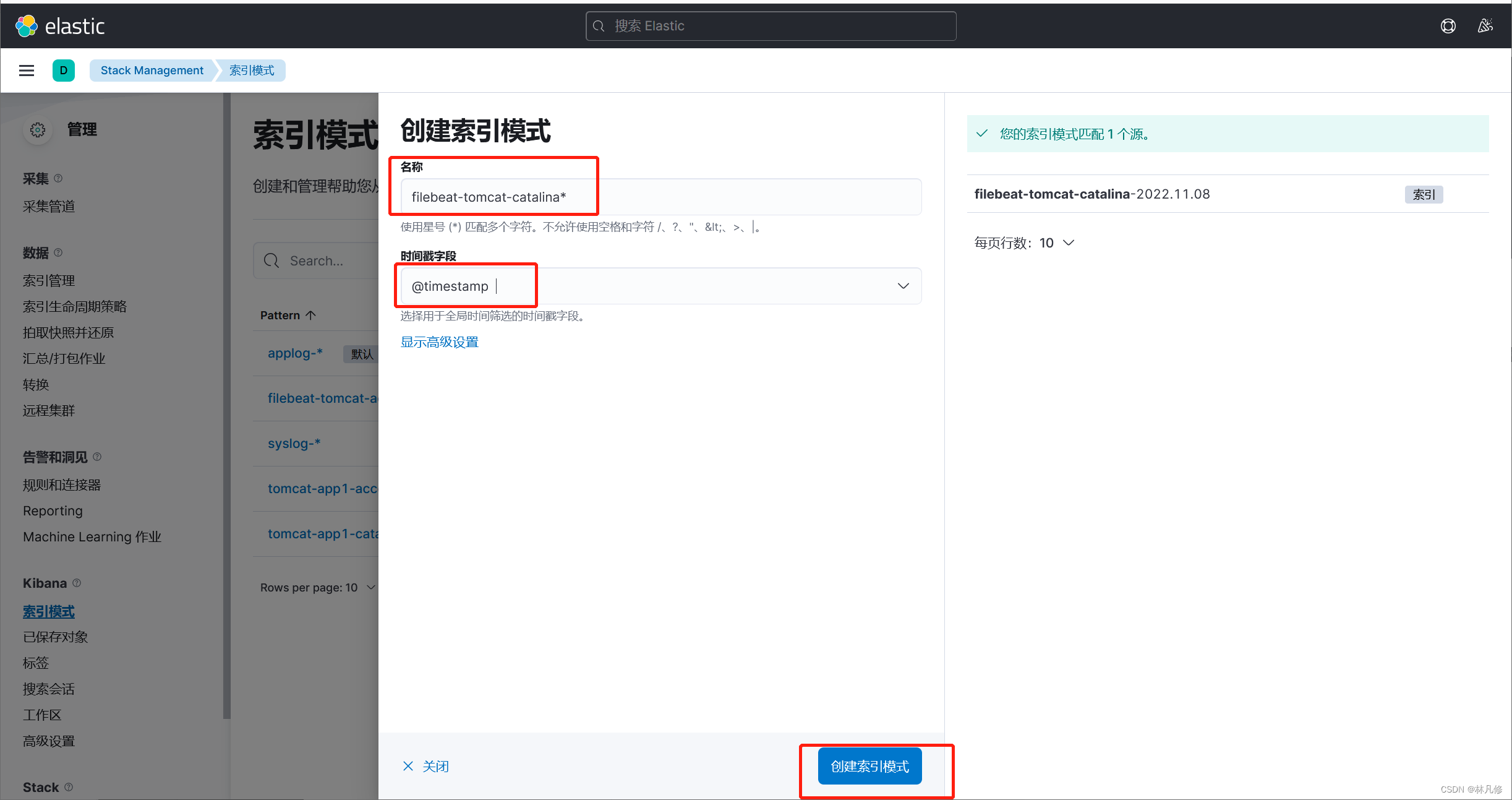
在Discovery界面查看日志
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)