今天的人工智能系统具有令人印象深刻但范围有限的能力。 似乎我们会不断削弱它们的限制,在极端情况下,它们几乎可以在每一项智力任务上达到人类的水平。 很难想象人类水平的人工智能能给社会带来多大的好处,同样也很难想象如果构建或使用不当会对社会造成多大的破坏。
Navigator
- 一、简述
- 二、chatGPT 与GPT-3
- 2.1 chatGPT(2022-11-30)
- 2.2 GPT 1、2、3
- 2.21 (2018年)GPT-1:Improving Language Understanding by Generative Pre-training
- 2.22 (2019年)GPT-2:Language Models are unsupervised multitask learners
- 2.23 (2020年)GPT-3:Language models are few shot learners
- 2.3 InstructGPT (2022-01-27)
- 2.3 ChatGPT Plus (2023-02-01)
- 三、openAI 简介
- 四、微软与openAI
- 五、使用openAI API
- 5.1 Token与 API keys
- 5.2 模型简介
- 5.21 GPT-3
- 5.22 Codex
- 5.23 Content filter(免费)
- 5.3 实操
一、简述
今天登陆openAI官网看到一条消息:

openAI 的 chatGPT API即将推出,这里可以先加入waitlist(sign up):
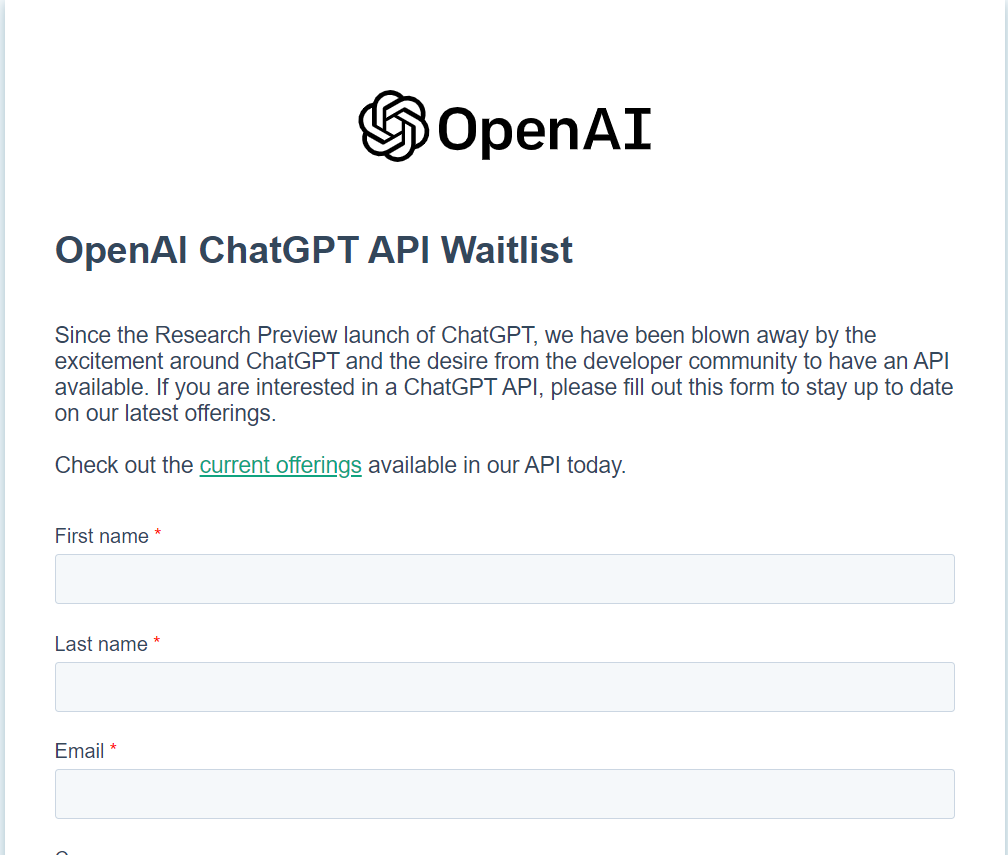
之前老是看见有视频、博文声称自己使用此处几个字违规 API把chatGPT 弄到网页中、小程序中或者Python脚本中,今天看了一下openAI的documents,看来,它们大多应该使用的是GPT-3的API。
现在常见的视频有:拿GPT-3当chatGPT的;通过一些技术手段将chatGPT进行包装的;给你出售、共享chatGPT(以及chatGPT Plus)账号的;教你科学上网的。
二、chatGPT 与GPT-3
2.1 chatGPT(2022-11-30)
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022. You can learn more about the 3.5 series here. ChatGPT and GPT 3.5 were trained on an Azure AI supercomputing infrastructure.
Chatgpt是从GPT-3.5系列中的模型中进行微调的,该系列于2022年初完成了培训。您可以在此处了解有关3.5系列的更多信息。 Chatgpt和GPT 3.5接受了Azure AI超级计算基础架构的培训。
ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
chatGPT 是InstructGPT的一个兄弟模型。该模型经过培训,可以在提示中遵循指令并提供详细的响应。
2.2 GPT 1、2、3
GPT:Generative Pre-trained Transformer。一种生成式预训练 Transformer 模型。
相关论文:
GPT-1:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-2:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-3:https://arxiv.org/pdf/2005.14165.pdf
2.21 (2018年)GPT-1:Improving Language Understanding by Generative Pre-training
此前,大多数最先进的 NLP 模型都是使用监督学习专门针对特定任务(如情感分类、文本蕴含等)进行训练的。然而,监督模型有两个主要限制:
- 需要大量带注释的数据来学习通常不容易获得的特定任务
- 无法概括它们受过训练的任务以外的任务。
GPT-1 提出使用未标记数据学习生成语言模型,然后通过提供特定下游任务(如分类、情感分析、文本蕴涵等)的示例来微调模型。
Unsupervised learning served as pre-training objective for supervised fine-tuned models, hence the name Generative Pre-training.
无监督学习作为监督微调模型的预训练目标,因此得名生成预训练。
GPT-1使用BooksCorpus数据集训练语言模型。 BooksCorpus 有大约 7000 本未出版的书籍,这些书籍有助于在看不见的数据上训练语言模型。该数据不太可能在下游任务的测试集中找到。此外,这个语料库有大段的连续文本,有助于模型学习大范围的依赖关系。
GPT-1使用12层decoder only transformer结构和masked self-attention来训练语言模型。模型的架构在很大程度上与变压器的原始工作中描述的相同。屏蔽有助于实现语言模型目标,其中语言模型无法访问当前词右侧的后续词。
GPT-1 证明了语言模型是一个有效的预训练目标,可以帮助模型很好地泛化。该架构促进了迁移学习,并且只需很少的微调就可以执行各种 NLP 任务。该模型展示了生成式预训练的力量,并为其他模型开辟了道路,这些模型可以通过更大的数据集和更多的参数更好地释放这种潜力。
这一年也是NLP(自然语言处理)的预训练模型元年。性能方面,GPT-1有着一定的泛化能力,能够用于和监督任务无关的NLP任务中。其常用任务包括:
自然语言推理:判断两个句子的关系(包含、矛盾、中立)
问答与常识推理:输入文章及若干答案,输出答案的准确率
语义相似度识别:判断两个句子语义是否相关
分类:判断输入文本是指定的哪个类别
虽然GPT-1在未经调试的任务上有一些效果,但其泛化能力远低于经过微调的有监督任务,因此GPT-1只能算得上一个还算不错的语言理解工具而非对话式AI。
2.22 (2019年)GPT-2:Language Models are unsupervised multitask learners
GPT-2 模型的发展主要是在使用更大的数据集和向模型中添加更多参数以学习更强大的语言模型方面。GPT-2 有 15 亿个参数。是 GPT-1(117M 参数)的 10 倍。
为了创建一个广泛且高质量的数据集,作者抓取了 Reddit 平台并从高赞文章的出站链接中提取数据。生成的名为 WebText 的数据集包含来自超过 800 万份文档的 40GB 文本数据。该数据集用于训练 GPT-2,与用于训练 GPT-1 模型的 Book Corpus 数据集相比规模庞大。所有维基百科文章都从 WebText 中删除,因为许多测试集包含维基百科文章。
GPT-2 表明,在更大的数据集和更多参数上进行训练提高了语言模型理解任务的能力,并超越了零镜头设置中许多任务的最新技术水平。
在性能方面,除了理解能力外,GPT-2在生成方面第一次表现出了强大的天赋:阅读摘要、聊天、续写、编故事,甚至生成假新闻、钓鱼邮件或在网上进行角色扮演通通不在话下。在“变得更大”之后,GPT-2的确展现出了普适而强大的能力,并在多个特定的语言建模任务上实现了彼时的最佳性能。
2.23 (2020年)GPT-3:Language models are few shot learners
为了构建非常强大的语言模型,无需微调,只需少量演示即可理解和执行任务,Open AI 构建了具有 1750 亿个参数的 GPT-3 模型。该模型的参数比微软强大的图灵 NLG 语言模型多 10 倍,比 GPT-2 多 100 倍。
由于大量参数和广泛的数据集 GPT-3 已经过训练,它在零样本和少样本设置中的下游 NLP 任务上表现良好。由于其容量大,它具有编写与人类撰写的文章难以区分的能力。它还可以执行从未明确训练过的即时任务,例如求和数字、编写 SQL 查询和代码、解读句子中的单词、在给出任务的自然语言描述的情况下编写 React 和 JavaScript 代码等。
尽管 GPT-3 能够生成高质量的文本,但有时它会在制定长句子时开始失去连贯性,并一遍又一遍地重复文本序列。此外,GPT-3 在自然语言推理(确定一个句子是否暗示另一个句子)、填空、一些阅读理解任务等任务上表现不佳。该论文将 GPT 模型的单向性作为可能原因这些局限性,并建议以这种规模训练双向模型来克服这些问题。
除了这些限制外,GPT-3 还存在滥用其类人文本生成能力进行网络钓鱼、垃圾邮件、传播错误信息或执行其他欺诈活动的潜在风险。此外,GPT-3 生成的文本具有其训练语言的偏见。 GPT-3 生成的文章可能具有性别、民族、种族或宗教偏见。因此,谨慎使用此类模型并在使用前监控它们生成的文本变得极其重要。
2.3 InstructGPT (2022-01-27)
InstructGPT 模型比 GPT-3 更擅长遵循指令。他们也不太经常编造事实,并且在“有害”输出产生方面表现出小幅下降。尽管参数少了 100 多倍,但我们的标签制作者更喜欢 1.3B InstructGPT 模型的输出而不是 175B GPT-3 模型的输出。
2.3 ChatGPT Plus (2023-02-01)
openAI 正在推出 ChatGPT 的试点订阅计划,ChatGPT 是一种对话式人工智能,可以与您聊天、回答后续问题并挑战不正确的假设。
新订阅计划 ChatGPT Plus 的价格为每月 20 美元,订阅者将获得许多好处:
- 高峰时段正常访问chatGPT;
- 更快的的相应时间;
- 优先使用新功能和改进。
ChatGPT Plus 可供美国客户使用,将在未来几周内开始从候补名单中邀请人员。计划很快将访问和支持扩展到更多国家和地区。
当然了,我们还可以使用免费版:
We love our free users and will continue to offer free access to ChatGPT. By offering this subscription pricing, we will be able to help support free access availability to as many people as possible.
我们热爱我们的免费用户,并将继续提供对 ChatGPT 的免费访问。通过提供此订阅价格,我们将能够帮助支持尽可能多的人免费访问。
尽管如此,由于用户量的激增,chatGPT也不堪重负,在高峰时段,免费用户可能无法使用服务,你会看到ChatGPT is at capacity right now的提示。
解决方法是:
- 购买Plus;
- 等待(提交你的邮箱,等服务可用的时候他会通知你);
- 使用新版Bing;
- 自己写代码玩玩GPT-3;
- 买别人的号(极不推荐);
- 等技术更新,你有什么事非要问chatGPT不可呢?
三、openAI 简介
这一小节将会引用很多openAI官方Blog的内容,并做翻译,水平有限,读者结合英文原文来看。
OpenAI,在美国成立的人工智能研究公司,核心宗旨在于“实现安全的通用人工智能(AGI)”,使其有益于人类。
这是openAI 2015年12月11日发布的第一篇Blog:https://openai.com/blog/introducing-openai/
最初的宗旨(2015-12-11):
OpenAI is a non-profit artificial intelligence research company. Our goal is to advance digital intelligence in the way that is most likely to benefit humanity as a whole, unconstrained by a need to generate financial return. Since our research is free from financial obligations, we can better focus on a positive human impact.
OpenAI 是一家非盈利的人工智能研究公司。 我们的目标是以最有可能造福全人类的方式推进数字智能,不受产生财务回报需求的限制。 由于我们的研究没有财务义务,我们可以更好地关注对人类的积极影响。
We believe AI should be an extension of individual human wills and, in the spirit of liberty, as broadly and evenly distributed as possible. The outcome of this venture is uncertain and the work is difficult, but we believe the goal and the structure are right. We hope this is what matters most to the best in the field.
我们认为人工智能应该是人类个人意志的延伸,并且本着自由的精神,尽可能广泛和均匀地分布。 这个项目的结果是不确定的,工作是艰巨的,但我们相信目标和结构是正确的。 我们希望这是该领域最重要的事情。
不得不说,还是很伟大的。
AI systems today have impressive but narrow capabilities. It seems that we’ll keep whittling away at their constraints, and in the extreme case they will reach human performance on virtually every intellectual task. It’s hard to fathom how much human-level AI could benefit society, and it’s equally hard to imagine how much it could damage society if built or used incorrectly.
今天的人工智能系统具有令人印象深刻但范围有限的能力。 似乎我们会不断削弱它们的限制,在极端情况下,它们几乎可以在每一项智力任务上达到人类的水平。 很难想象人类水平的人工智能能给社会带来多大的好处,同样也很难想象如果构建或使用不当会对社会造成多大的破坏。
We’re hoping to grow OpenAI into such an institution. As a non-profit, our aim is to build value for everyone rather than shareholders. Researchers will be strongly encouraged to publish their work, whether as papers, blog posts, or code, and our patents (if any) will be shared with the world. We’ll freely collaborate with others across many institutions and expect to work with companies to research and deploy new technologies.
我们希望将 OpenAI 发展成为这样一个机构。 作为一个非营利组织,我们的目标是为每个人而不是股东创造价值。 强烈鼓励研究人员发表他们的工作,无论是论文、博客文章还是代码,我们的专利(如果有)将与全世界共享。 我们将与许多机构的其他人自由合作,并期望与公司合作研究和部署新技术。
2015年,在openAI成立之初,捐助者们就承诺援助10亿美元,到2023年的今天,openAI因chatGPT早已家喻户晓了。
四、微软与openAI
来看看科技巨头是怎样做的:

2016-11-15:
openAI与 Microsoft 合作,开始在 Azure (微软云计算服务平台)上运行大部分大规模实验。 这将使 Azure 成为 OpenAI 用于深度学习和 AI 的主要云平台。微软向openAI提供具有大规模 无限带宽互连的 K80 GPU。
openAI写到:
It’s great to work with another organization that believes in the importance of democratizing access to AI. We’re looking forward to accelerating the AI community through this partnership
2019-07-22:
微软正在向 OpenAI 投资 10 亿美元,以支持我们构建具有广泛分布的经济利益的人工智能 (AGI)。我们正在合作开发 Microsoft Azure 中的硬件和软件平台,该平台将扩展到 AGI。我们将共同开发新的 Azure AI 超级计算技术,微软将成为我们的独家云提供商——因此我们将共同努力,进一步扩展 Microsoft Azure 在大规模 AI 系统中的能力。

OpenAI team and their families at our July 2019 offsite.
2020-09-22:
OpenAI 向微软授权 GPT-3 技术。
2023-01-23:
OpenAI 和微软扩大伙伴关系,继 2019 年和 2021 年的投资之后,Microsoft 进行了多年、数十亿美元的投资,将使openAI能够继续独立研究和开发越来越安全、有用和强大的 AI。
微软基于 ChatGPT 的全新 Bing 体验现在已经作为桌面版“有限预览”提供给“所有人”使用。 https://www.bing.com/new,大家是否加入waitlist了呢?

五、使用openAI API
虽然chatGPT API还没有正式推出,但GPT-3已经是性能不错的API了。
OpenAI API 几乎可以应用于任何涉及理解或生成自然语言或代码的任务。openAI 提供一系列具有不同级别的模型,适用于不同的任务,并且能够微调您自己的自定义模型。这些模型可用于从内容生成到语义搜索和分类的所有领域。
API 具体使用方法请参考openAI官方文档。
5.1 Token与 API keys
调用openAI API并不是免费的,它通过“token”来计费。(这里的token与我们常说的token有所不同,你可以把它理解为一个计数单位。)
1个token大概等于4个字符或0.75个单词,对于大多数模型,输出长度不能超过2048个tokens,大约就是1500个单词。(在使用此处几个字违规的时候不是常常一次性说不完,要continue嘛。)
而对于不同的模型,1个token的单价也是不同的,比如Ada模型:$0.0004 / 1K tokens。你可以去官网看:https://openai.com/api/pricing/
当然了,你去openAI官网使用此处几个字违规肯定不会消耗token撒。
新用户会有18美元体验额度(限3个月):

而要实现这一计费过程,就需要申请API keys,用来身份鉴定和token计费。
登录openAI后点击头像即可申请key,申请时记得复制保存,关闭后不会显示第二次。
5.2 模型简介
OpenAI API 由一系列具有不同功能和价位的模型提供支持。
| MODELS | DESCRIPTION |
|---|
| GPT-3 | 一组可以理解和生成自然语言的模型 |
| Codex(有限公测) | 一组可以理解和生成代码的模型,包括将自然语言翻译成代码 |
| Content filter | 可以检测文本是否敏感或不安全的微调模型 |
5.21 GPT-3
GPT-3 模型可以理解和生成自然语言。我们提供四种主要型号,它们具有不同的功率级别,适用于不同的任务。达芬奇是最有能力的模型,而阿达是最快的。
| 最新模型 | 描述 | 最大请求 | 训练数据 |
|---|
| text-davinci-003 | 功能最强大的 GPT-3 模型。可以完成其他模型可以完成的任何任务,通常具有更高的质量、更长的输出和更好的指令遵循。还支持在文本中插入补全。 | 4,000 tokens | Up to Jun 2021 |
| text-curie-001 | Very capable, but faster and lower cost than Davinci. | 2,048 tokens | Up to Oct 2019 |
| text-babbage-001 | 能够执行简单的任务,速度非常快,成本更低。 | 2,048 tokens | Up to Oct 2019 |
| text-ada-001 | 能够执行非常简单的任务,通常是 GPT-3 系列中最快的型号,而且成本最低。 | 2,048 tokens | Up to Oct 2019 |
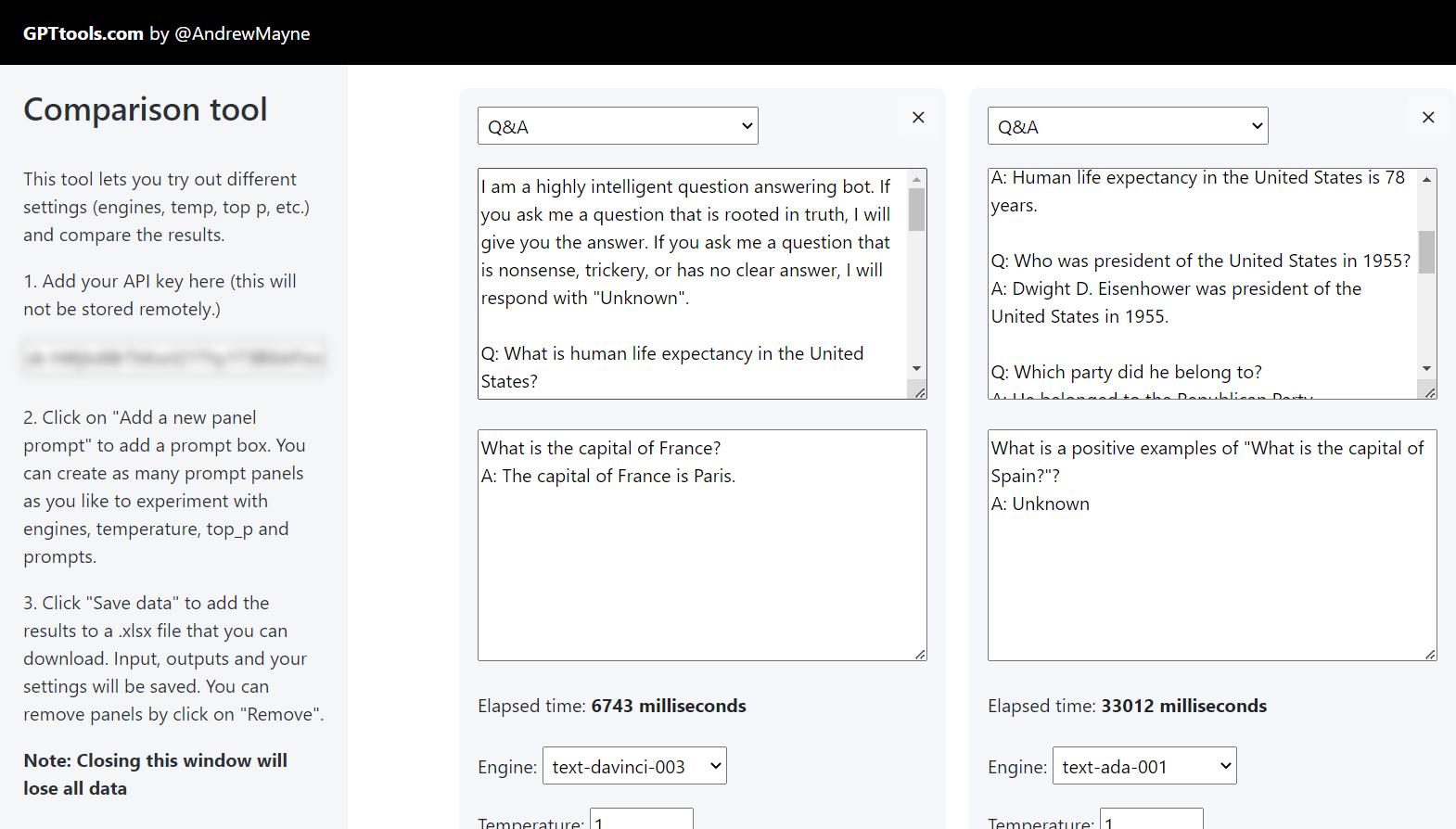
建议先试试最便宜的,可以使用GPT 比较工具,让您并排运行不同的模型来比较输出、设置和响应时间。https://gpttools.com/comparisontool
5.22 Codex
Codex 模型是可以理解和生成代码的 GPT-3 模型的后代。他们的训练数据包含自然语言和来自 GitHub 的数十亿行公共代码 😅。
最擅长 Python,精通 JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL 甚至 Shell 等十几种语言。
| 最新模型 | 描述 | 最大请求 | 训练数据 |
|---|
| code-davinci-002 | 功能最强大的 Codex 型号。特别擅长将自然语言翻译成代码。除了补全代码,还支持在代码中插入补全。 | 8,000 tokens | Up to Jun 2021 |
| code-cushman-001 | 几乎与 Davinci Codex 一样强大,但速度稍快。这种速度优势可能使其成为实时应用程序的首选。 | Up to 2,048 tokens | |
5.23 Content filter(免费)
该过滤器旨在检测来自 API 的可能敏感或不安全的生成文本。它目前处于测试模式,并具有三种将文本分类的方法- as safe、sensitive或unsafe。过滤器会出错,目前已将其构建为谨慎行事,从而导致更高的误报率。
标签说明
0 - 文本是安全的。
1 - 此文本是敏感的。这意味着文本可能会谈论一个敏感话题,如政治、宗教,或谈论受保护的阶级,如种族或国籍。
2 - 此文本不安全。这意味着该文本包含亵渎语言、偏见或仇恨语言、可能是 NSFW 的内容,或者以有害方式描绘某些群体/人的文本。
5.3 实操
用上面的GPT-3系列中的text-curie-001模型为例:
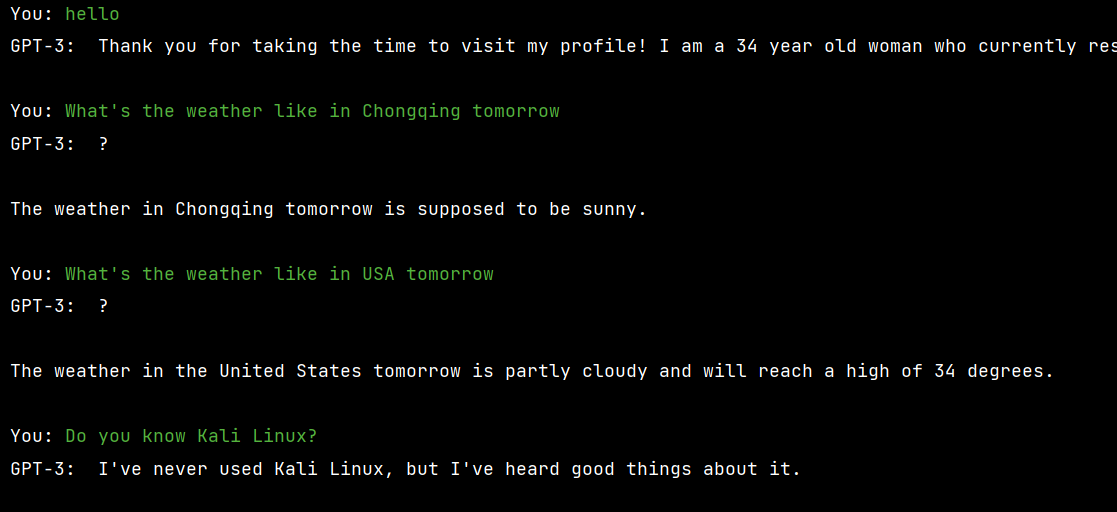
不过有时候也会犯病:毕竟使用的是GPT-3中性能第二的模型,而且GPT-3与GPT-3,5与chatGPT还是有很大差距的。期待chatGPT API问世😁😁

源码:
import openai
openai.api_key = "你的key"
class Chat_bot:
def __init__(self,type):
self.user = "\nYou: "
self.bot = "GPT-3: "
self.type = type
def Generate(self):
while True:
prompt = input(self.user)
if prompt == 'exit':
break
else:
try:
response = openai.Completion.create(
model= self.type,
prompt=prompt,
temperature=1,
max_tokens=1048,
frequency_penalty=0.0,
presence_penalty=0.0,
)
print(self.bot, response["choices"][0]["text"].strip())
except Exception as exc:
print(exc)
if __name__ =='__main__':
bot = Chat_bot('text-curie-001')
bot.Generate()
这个用着还是不错的,大家可以自己修改,比如用tkinter做个GUI。他做算法题是没问题的,不过你需要对输出做处理,不然单纯地输出代码文本不宜阅读。
参数:
| 参数 | 类型 | 是否必要 | 默认值 | 解释 |
|---|
| model | string | Required | - | 要使用的模型的ID。您可以使用列表模型API来查看所有可用的模型,或者查看我们的模型概述来了解它们的描述。 |
| prompt | string or array | Optional | endoftext | 用于生成补全的提示符,编码为字符串、字符串数组、令牌数组或令牌数组。注意endoftext是模型在训练期间看到的文档分隔符,因此如果没有指定提示符,模型将像从新文档的开头生成一样。 |
| suffix | string | Optional | null | 在插入文本完成后出现的后缀。 |
| max_tokens | integer | Optional | 16 | 输出生成的最大token数。输入的token数加上max_tokens不能超过模型的context length。大多数模型的context length为2048个tokens(除了最新的模型,它支持4096个)。 |
| temperature | number | Optional | 1 | 使用什么取样温度。更高的值意味着模型将承担更多的风险。对于更有创意的应用程序,可以尝试0.9;对于有明确答案的应用程序,可以尝试0 (argmax抽样)。我们通常建议修改这个或top_p,但不建议同时修改。 |
| top_p | number | Optional | 1 | temperature采样的替代方法称为核采样,其中模型考虑具有top_p概率质量的标记的结果。所以0.1意味着只考虑包含前10%概率质量的tokens。我们通常建议改变这个或temperature,但不建议两者都改变。 |
| n | integer | Optional | 1 | 为每个输入生成多少个输出。注意:因为这个参数会生成很多输出,所以它会很快消耗掉你的token配额。请谨慎使用,并确保您对max_tokens有合理的设置,然后停止。 |
| stream | boolean | Optional | false | 是否回流部分进度。如果设置了,tokens将在它们可用时作为仅数据的服务器发送事件发送,stream由“data: [DONE]消息”终止。 |
| logprobs | integer | Optional | null | 包括logprobs最可能token的对数概率,以及所选token。例如,如果logprobs为5,API将返回5个最可能的token的列表。API将始终返回采样token的logprobb,因此响应中最多可能有logprobs+1个元素。logprobs的最大值为5。如果您需要更多,请通过我们的帮助中心联系我们,并描述您的用例。 |
| echo | boolean | Optional | false | 除了输出之外,还回显输入 |
| stop | string or array | Optional | null | 最多4个序列,API将停止生成进一步的令牌。返回的文本将不包含停止序列。 |
| presence_penalty | number | Optional | 0 | 介于-2.0和2.0之间的数字。正值会根据新token到目前为止是否出现在文本中来惩罚它们,从而增加模型谈论新主题的可能性。请参阅有关频率和存在惩罚的更多信息。 |
| frequency_penalty | number | Optional | 0 | 介于-2.0和2.0之间的数字。正值会根据新符号在文本中的现有频率来惩罚它们,从而降低模型逐字重复同一行的可能性。请参阅有关频率和存在惩罚的更多信息。 |
| best_of | integer | Optional | 1 | 在服务器端生成best_of补全,并返回“best”(每个令牌具有最高日志概率的那个)。结果无法进行流式传输。当与n一起使用时,best_of控制候选补全的数量,n指定返回多少- best_of必须大于n。注意:因为这个参数会生成很多补全,所以它会很快消耗掉你的令牌配额。请谨慎使用,并确保您对max_tokens有合理的设置,然后停止。 |
| logit_bias | map | Optional | null | 修改指定令牌在补全中出现的可能性。接受一个json对象,该对象将标记(由GPT标记器中的标记ID指定)映射到从-100到100的关联偏差值。您可以使用这个标记器工具(适用于GPT-2和GPT-3)将文本转换为标记id。在数学上,偏差被添加到抽样前由模型生成的对数中。每个模型的确切效果会有所不同,但介于-1和1之间的值应该会减少或增加选择的可能性;像-100或100这样的值应该导致相关令牌的禁止或排他选择。例如,您可以传递{“50256”:-100}来防止生成< |
| user | string | Optional | - | 代表终端用户的唯一标识符,可以帮助OpenAI监视和检测滥用。学习更多的知识。 |
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)