原文符号有点乱,直接引用前文的分析结论,详见: 序列模型(3)—— LLM的参数量和计算量 。首先给出符号约定
| 参数 | 符号 | 说明 |
|---|---|---|
| Decoder 层数 | l l l | |
| Token 嵌入维度 | d d d | |
| Attention 层嵌入维度 | d d d | |
| MLP 隐藏层维度 | 4 d 4d 4 d | 通常设置为嵌入维度4倍 |
| Attention head 数量 | n n n | 要求其整除 d d d |
| 词表尺寸 | V V V | |
| 模型输入长度 | s s s | 代表模型处理的上下文长度 |
| 训练 batch data | x \pmb{x} x | 张量尺寸 R B × s × d \mathbb{R}^{B\times s\times d} R B × s × d |
| 训练步数 | S S S | 即模型参数更新次数 |
| 交叉熵损失 | L L L | 本文中主要指测试损失,可用于指示模型性能 |
| batch_size | B B B | |
| 模型参数量 | N N N | |
| 训练数据量(Token) | D D D | |
| 训练计算量(FLOPs) | C C C | |
| 损失的幂律指数 | α X \alpha_X α X | Scaling Laws 就是 L ( X ) ∝ 1 / X α x L(X)\propto1/X^{\alpha x} L ( X ) ∝ 1/ X αx ,其中 X X X 可以是 N , D , C N,D,C N , D , C 之中的任意一个 |
Decoder-only Transformer 模型的参数量 N N N 、计算量 C C C 和数据量 D D D 之间有以下关系

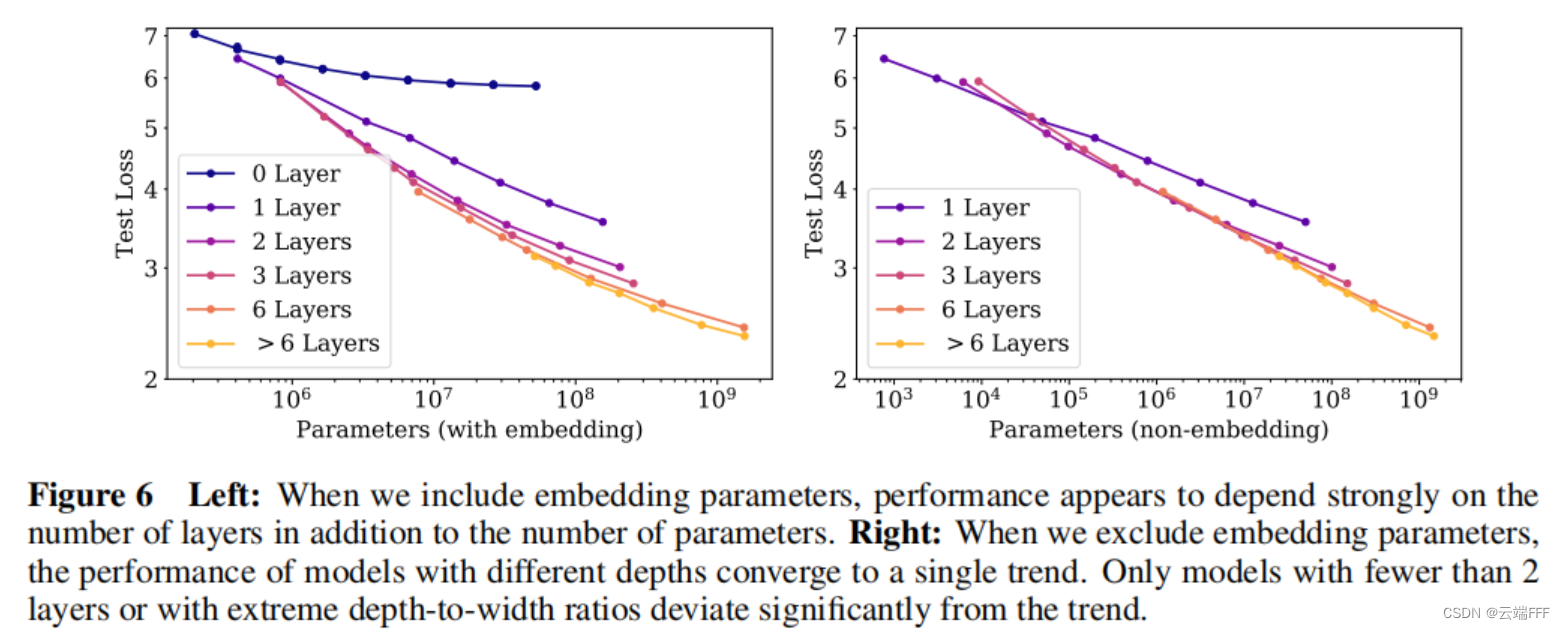
- 作者进一步考察了其他序列模型以及模型的泛化性能
- 作者验证了 LSTM 和 Encoder-Decoder 类模型都服从以上幂律关系
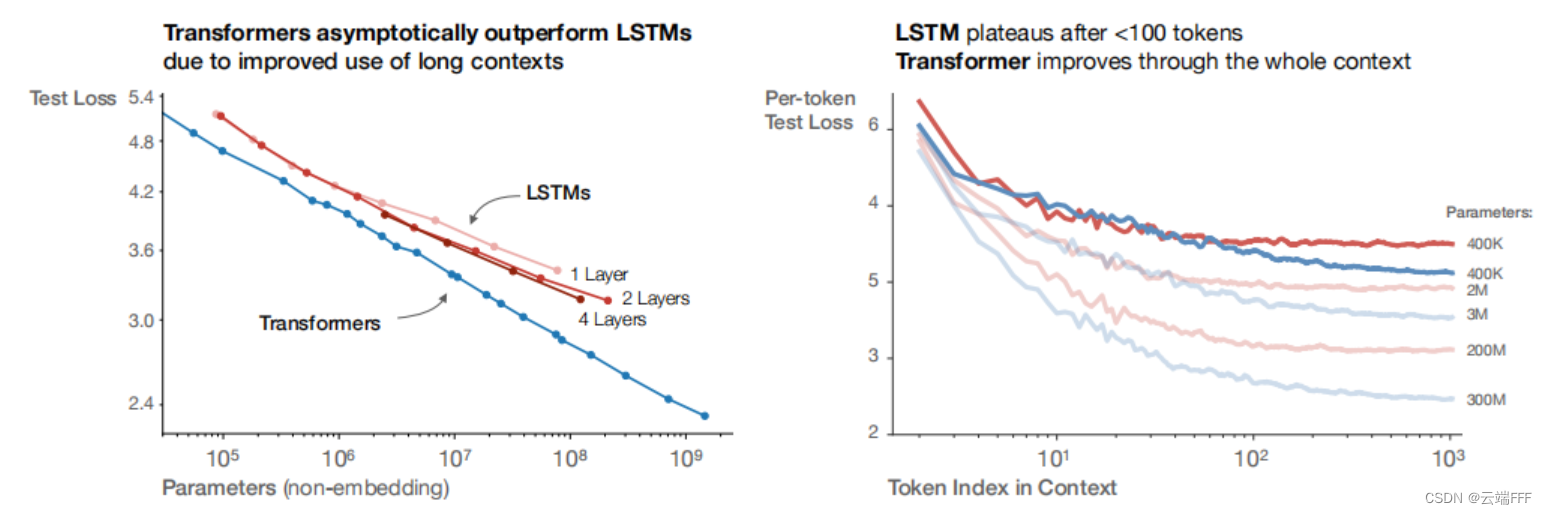
左图显示了 LSTM/Transformer 模型的参数规模与性能间的幂律关系,从中也可发现 Transformer 模型总能用较少的参数量实现更好的性能;右图显示了上下文长度和预测性能的关系,可见 LSTM 仅在早期 Token 部分和 Transformer 模型性能类似,长跨度下性能不如 Transformer
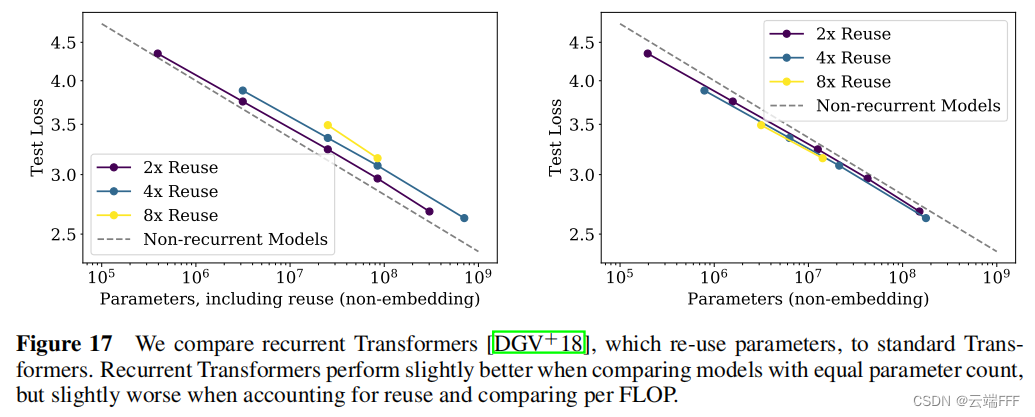
这里考察的是带有递归循环和参数复用结构的 Encoder-Decoder Transformer 模型 Universal Transformers,可见参数量和性能间也满足幂律关系- 作者验证了 模型泛化性能也服从以上幂律关系
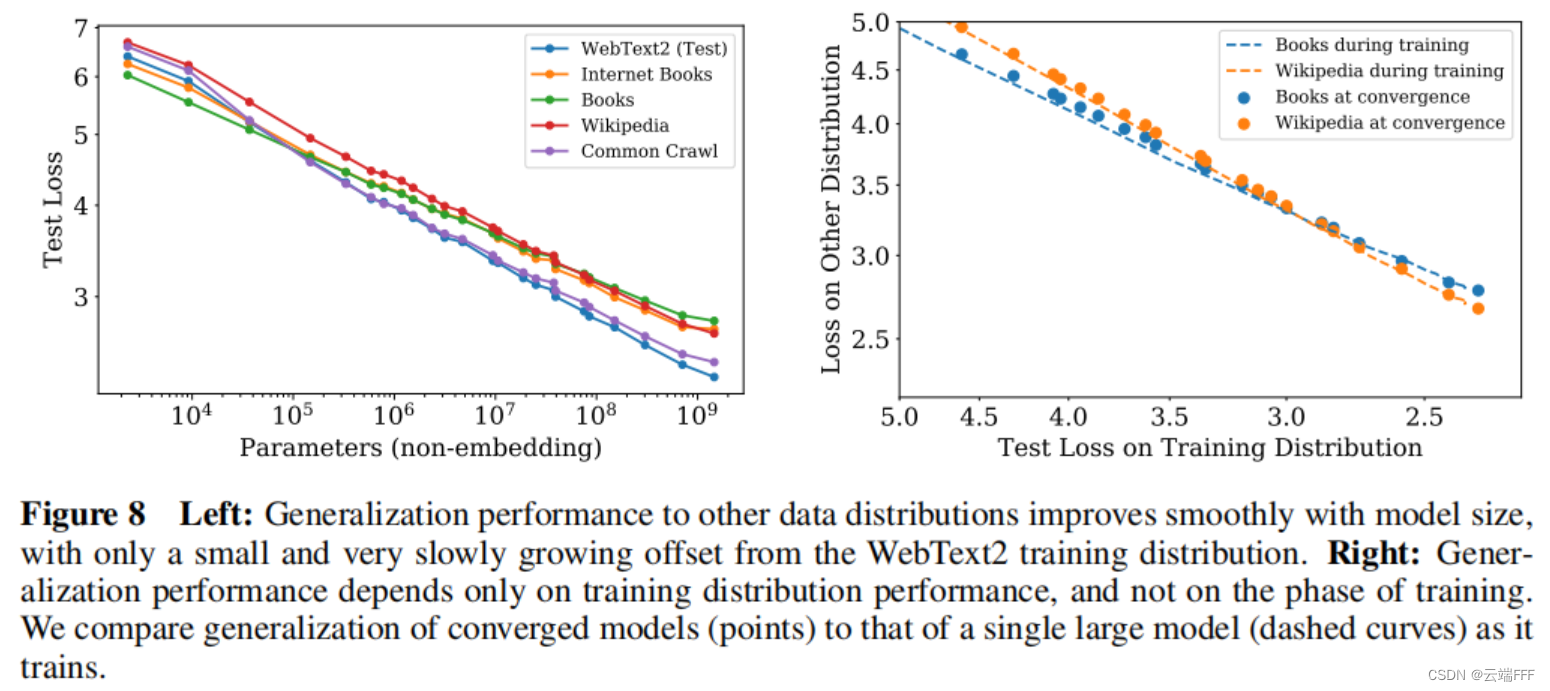
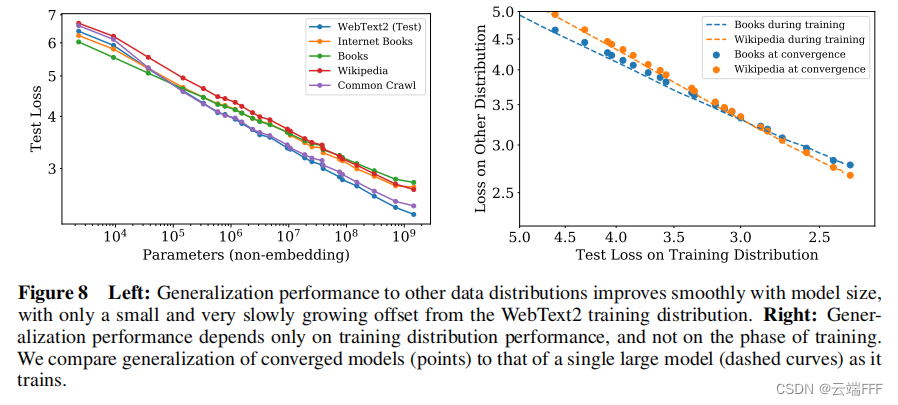
左图显示了在 WebText2 上训练模型,然后在多种数据集上测试的泛化性能表现,显示出一致的幂律关系;右图说明泛化性能仅取决于训练分布上的性能,而与训练阶段无关

考察计算量
C
C
C
与性能的关系时(左图),作者先用充足的数据训练多种不同参数规模
N
N
N
的模型只收敛,然后对任意给定的
C
C
C
,考察所有模型,找到第
S
=
C
6
N
B
S=\frac{C}{6NB}
S
=
6
NB
C
步时最优的模型性能绘制(为此需保持所有模型训练时
B
B
B
不变,我们将在第 4 节进一步讨论更高效的训练方案)。注意到幂律关系
L
(
C
)
≈
(
C
c
C
)
α
C
L(C) \approx \left(\frac{C_c}{C}\right)^{\alpha_C}
L
(
C
)
≈
(
C
C
c
)
α
C
- 值得注意的时,以上幂律关系在 LLM 多模态任务中依然存在
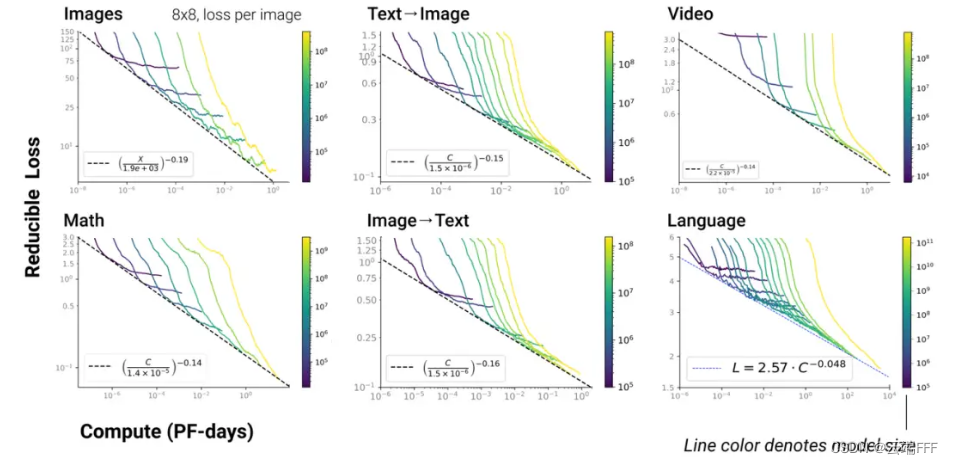
考察数据量
D
D
D
与性能的关系时(中图),作者训练规模为
(
l
,
d
)
=
(
36
,
1280
)
(l,d)=(36,1280)
(
l
,
d
)
=
(
36
,
1280
)
的模型直到收敛。注意到幂律关系
L
(
D
)
≈
(
D
c
D
)
α
D
L(D) \approx \left(\frac{D_c}{D}\right)^{\alpha_D}
L
(
D
)
≈
(
D
D
c
)
α
D
该设计中我们可以通过调节 N c , D c N_c,D_c N c , D c 来适应这些变化
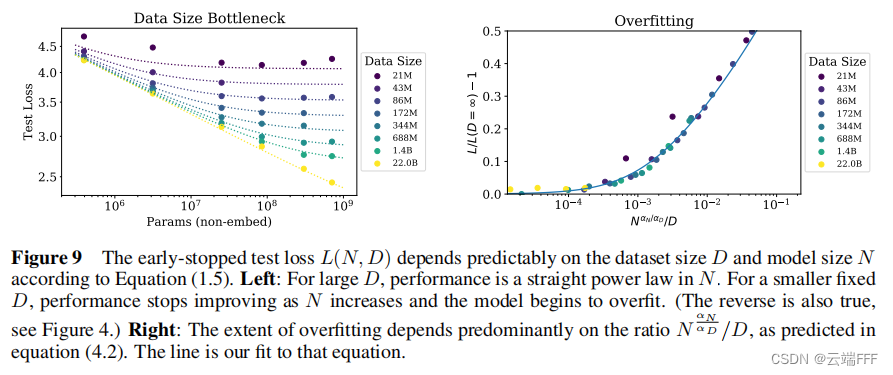
有限的 D D D 下,任何模型都无法接近最佳损失(即文本的熵);同样固定大小 N N N 的模型将受到容量限制。另一方面,有 L ( ∞ , D ) = L ( D ) , L ( N , ∞ ) = L ( N ) L(\infin,D)= L(D), \space\space L(N,\infin)= L(N) L ( ∞ , D ) = L ( D ) , L ( N , ∞ ) = L ( N )
这个原则更具推测性,由于过拟合应该与数据集的方差或信噪比相关,而它们按 1 D \frac{1}{D} D 1 成比例缩放,所以我们通常期望过拟合在非常大的 D D D 下也成比例于 1 D \frac{1}{D} D 1 进行缩放。这个期望对于任何平滑的损失函数都应该成立。然而,这假设 1 D \frac{1}{D} D 1 的修正项在方差的其他来源(如有限 batch size)上占主导地位,这还没有经验证实


现在我们讲起 Scaling Laws 时,主要关注的通常就是前两节(特别是第一节)所述内容。但是原始论文中还进行了进一步分析,使其更符合现实情况。在进一步分析之前,首先引入一些新符号
| 参数 | 符号 | 说明 |
|---|---|---|
| 关键 batch size | B crit B_{\text{crit}} B crit | 以此 batch size 进行训练大致上在时间和计算效率之间提供了一个最优的折衷 |
| 最小计算量 | C min C_{\min} C m i n | 达到给定损失值最小计算量,这是模型以远小于 B crit B_{\text{crit}} B crit 的 batch size 训练时的计算量 |
| 最小训练步骤 | S min S_{\min} S m i n | 达到给定损失值的最小训练步数。这是模型以远大于 B crit B_{\text{crit}} B crit 的 batch size 训练时的步数 |
| 最小处理数据量(Token) | E min E_{\min} E m i n | 达到给定损失值所处理的最小数据量 |
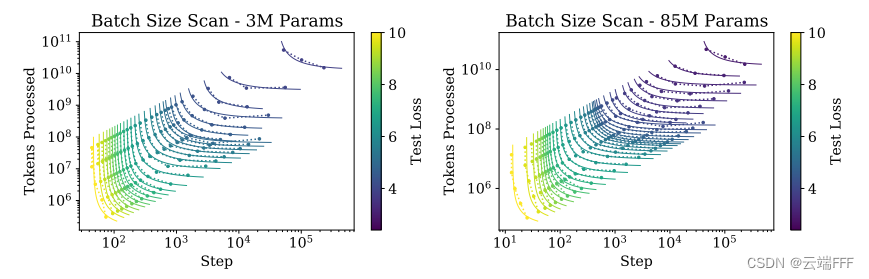
设置过大的 batch size 会影响计算效率,因为足够大的 batch size 下计算的梯度方向已经足够准确,继续加大的意义不大。一般认为训练过程中存在一个临界 batch size B crit B_{\text{crit}} B crit :当 B ≤ B crit B\leq B_{\text{crit}} B ≤ B crit 时,加大 B B B 对计算效率无明显影响;当 B > B crit B > B_{\text{crit}} B > B crit 时,加大 B B B 会使得计算效率下降。



第 1 节已经分析了,在不考虑
N
N
N
和
D
D
D
限制的情况下,计算量
C
C
C
与性能的之间存在幂律关系
L
(
C
)
≈
(
C
c
C
)
α
C
L(C) \approx \left(\frac{C_c}{C}\right)^{\alpha_C}
L
(
C
)
≈
(
C
C
c
)
α
C
但是这个结果的前提是以固定 batch size
B
B
B
进行训练,事实上,我们可以按第 3 节所述的
B
crit
B_{\text{crit}}
B
crit
进行训练,从而提高训练效率。本节中我们进一步分析这种情况
作者首先对性能和
C
min
C_{\min}
C
m
i
n
的关系进行拟合(不考虑
N
N
N
和
D
D
D
的约束),如下所示

这里作者使用远低于 B crit B_{\text {crit }} B crit 的 batch size 训练以考察性能和 C min C_{\min} C m i n 的关系。注意到 C min C_{\min} C m i n 同样和性能间存在幂律关系 L ( C min ) L(C_{\min}) L ( C m i n ) ,但是具体的表达式和 C C C 的幂律关系 L ( C ) L(C) L ( C ) 有所区别
作者进一步考察可以最高效训练的最优模型参数量
N
(
C
min
)
N(C_{\min})
N
(
C
m
i
n
)
,拟合结果如下所示

如左图所示,最优参数量和最小计算量之间也存在幂律关系,拟合结果约为
N
(
C
min
)
∝
C
min
0.73
N(C_{\min})\propto C_{\min}^{0.73}
N
(
C
m
i
n
)
∝
C
m
i
n
0.73
进一步地,注意到
(
3.1
节拟合结果
)
B
crit
∝
L
−
4.8
(
4.1
节拟合结果
)
L
∝
C
min
−
0.05
⇒
B
crit
∝
C
min
0.24
\begin{aligned} &(3.1 节拟合结果) &&B_{\text {crit }} \propto L^{-4.8} \\ &(4.1节拟合结果) &&L\propto C_{\min}^{-0.05} \end{aligned} \Rightarrow B_{\text {crit }} \propto C_{\min}^{0.24}
(
3.1
节拟合结果
)
(
4.1
节拟合结果
)
B
crit
∝
L
−
4.8
L
∝
C
m
i
n
−
0.05
⇒
B
crit
∝
C
m
i
n
0.24
又根据定义
C
min
≡
6
N
(
C
min
)
B
crit
S
C_{\min} \equiv 6N(C_{\min}) {B_{\text {crit }}}S
C
m
i
n
≡
6
N
(
C
m
i
n
)
B
crit
S
,可以推出
C
min
∝
6
C
min
0.73
C
min
0.24
S
⇒
S
min
∝
C
min
0.03
C_{\min} \propto 6C_{\min}^{0.73} C_{\min}^{0.24}S \Rightarrow S_{\min} \propto C_{\min}^{0.03}
C
m
i
n
∝
6
C
m
i
n
0.73
C
m
i
n
0.24
S
⇒
S
m
i
n
∝
C
m
i
n
0.03
这个结果也和拟合结果相吻合,如上右图所示
PS:这里说根据定义我觉得有点问题,因为根据定义 C min C_{\min} C m i n 应该是在用远小于 B crit B_{\text{crit}} B crit 的 batch size 训练得到的,这里应该是假设了这个小 batch size 仍然和 B crit B_{\text{crit}} B crit 有相同的数量级
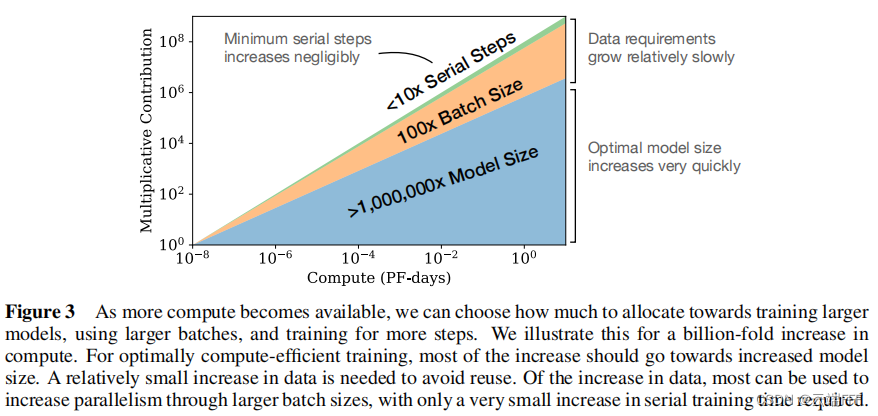
总之我们可以得出结论:当不受训练数据量限制时,随着总计算量的提高,存在有对应的最优模型规模(训练效率最高)

我们应该以最佳的计算分配来扩大语言模型,即

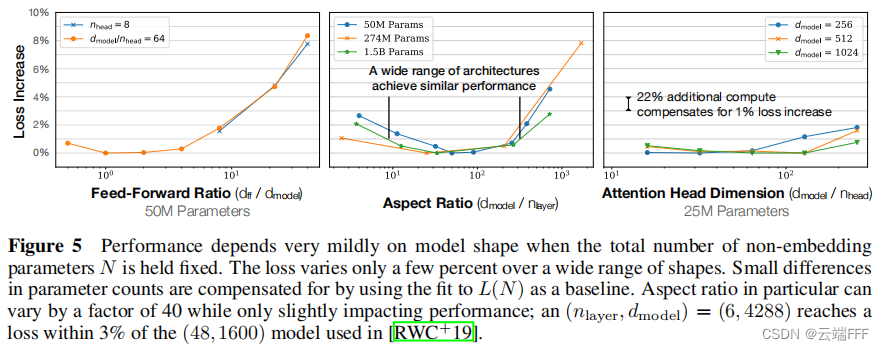
模型性能与规模密切相关,与模型形状关系较弱 :模型性能主要取决于 模型参数量(不包括嵌入) N N N 、数据集(Token)大小 D D D 以及训练计算量(FLOPs) C C C 。在合理范围内,性能对其他超参数(如深度与宽度的比例、训练学习率调度方案)的依赖程度很低
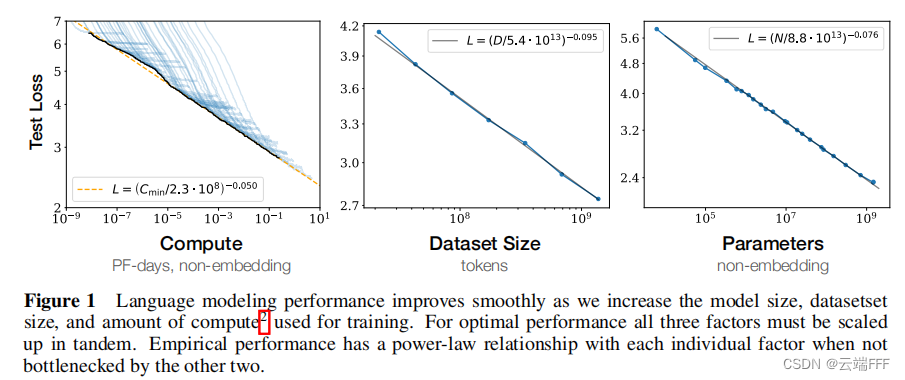
平滑的幂律关系 :当不被其他两个因素限制时,模型性能与 N N N 、 D D D 、 C C C 之间存在幂律关系,这种关系在很大范围内一直保持(跨越六个以上数量级)。这种幂律关系在 Decoder-Only Transformer、Encoder-Decoder Transformer、LSTM 等多种序列模型上都有体现,对于 NLP 以外的多模态任务也成立。
通过在小模型上拟合以下幂律关系,可以外推预测大模型、大数据量和大计算量下的性能表现
过度拟合的普遍规律 :在不考虑训练数据量 C C C 的限制时,只要同时扩大 N N N 和 D D D ,性能就会可预测地提高,但如果固定 N N N 或 D D D 中的一个而增加另一个,就会进入回报递减的领域。 过拟合程度和 N α N α D / D N^{\frac{\alpha_N}{\alpha_D}}/D N α D α N / D 之间存在幂律关系。这意味着每当模型大小 N N N 增加 8 倍,将数据量 D D D 增加 8 α N α D 8^{\frac{\alpha_N}{\alpha_D}} 8 α D α N 倍就可以维持过拟合程度不增加
不考虑训练计算量限制时,性能受到
N
N
N
和
D
D
D
的联合影响
L
(
N
,
D
)
=
[
(
N
c
N
)
α
N
α
D
+
D
c
D
]
α
D
L(N,D) = \left[\left(\frac{N_c}{N}\right)^{\frac{\alpha_N}{\alpha_D}} + \frac{D_c}{D}\right]^{\alpha_D}
L
(
N
,
D
)
=
[
(
N
N
c
)
α
D
α
N
+
D
D
c
]
α
D
过拟合程度可以表示为
δ
L
(
N
,
D
)
≡
L
(
N
,
D
)
L
(
N
,
∞
)
−
1
≈
(
1
+
(
N
N
c
)
α
N
α
D
D
c
D
)
α
D
−
1
\begin{aligned} \delta L(N, D) &\equiv \frac{L(N, D)}{L(N, \infty)}-1 \\ &\approx\left(1+\left(\frac{N}{N_{c}}\right)^{\frac{\alpha_{N}}{\alpha_{D}}} \frac{D_{c}}{D}\right)^{\alpha_{D}}-1 \end{aligned}
δ
L
(
N
,
D
)
≡
L
(
N
,
∞
)
L
(
N
,
D
)
−
1
≈
(
1
+
(
N
c
N
)
α
D
α
N
D
D
c
)
α
D
−
1
这意味着过拟合程度和
N
α
N
α
D
/
D
N^{\frac{\alpha_N}{\alpha_D}}/D
N
α
D
α
N
/
D
成幂律关系
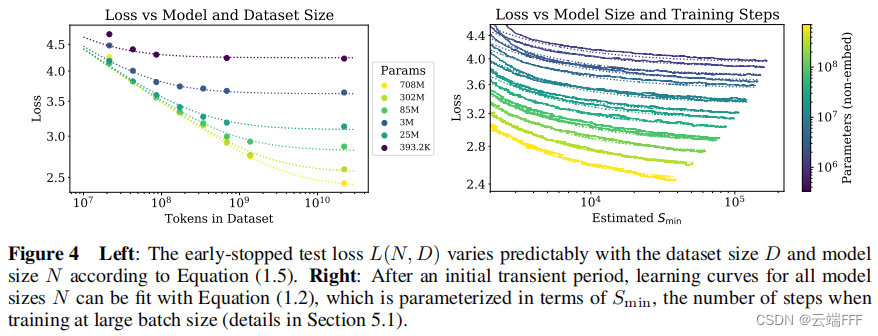
训练的普遍规律 :训练曲线遵循可预测的幂律,通过外推训练曲线的早期部分,我们可以大致预测如果我们训练更长时间会达到的损失
在无数据限制的情况下,对参数量为
N
N
N
的模型训练
S
S
S
步后得到的性能可以用下式拟合
L
(
N
,
S
)
=
(
N
c
N
)
α
N
+
(
S
c
S
min
(
S
)
)
α
S
L\left(N, S\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min}(S)}\right)^{\alpha_{S}}
L
(
N
,
S
)
=
(
N
N
c
)
α
N
+
(
S
m
i
n
(
S
)
S
c
)
α
S
其中
S
min
(
S
)
≡
S
1
+
B
crit
(
L
)
/
B
(
minimum steps, at
B
≫
B
crit
)
S_{\min }(S) \equiv \frac{S}{1+B_{\text {crit }}(L) / B} \quad\left(\text { minimum steps, at } B \gg B_{\text {crit }}\right)
S
m
i
n
(
S
)
≡
1
+
B
crit
(
L
)
/
B
S
(
minimum steps, at
B
≫
B
crit
)
迁移随着测试性能的提高而提高 :当我们使用与训练数据不同的分布对文本进行模型评估时,结果与训练验证集上的结果高度相关,损失大致恒定。换句话说,迁移到不同的分布会导致恒定的损失,但其他方面会大致与训练集上的性能保持一致
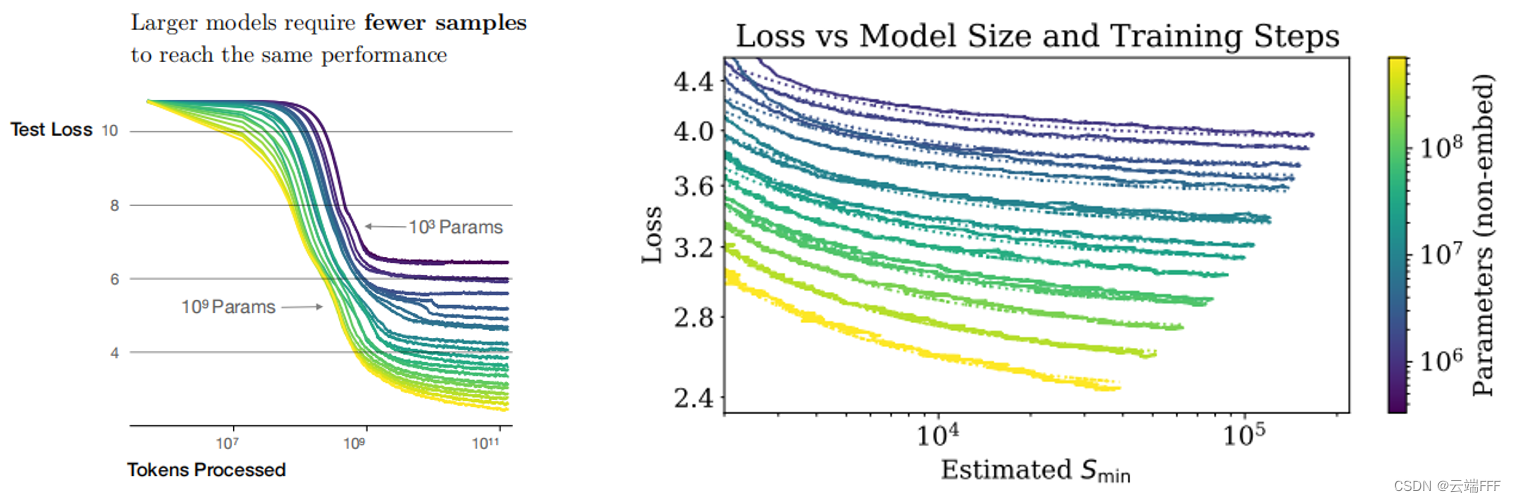
样本效率 :大型模型比小型模型更具样本效率,使用更少的优化步数和更少的数据点就能达到相同的性能水平
收敛效率低 : 随着 C C C 的增大,为了达成最高训练效率,数据 D D D 的增量要显著小于模型参数量 N N N 的增量 。因此当固定计算量预算 C C C 而不限制模型大小 N N N 和可用数据 D D D 时,可以通过训练非常大的模型并在明显缺乏收敛性时停止来获得最佳性能,这比将小模型训练至收敛的训练效率高很多
当固定训练总计算量
C
C
C
而没有其他任何限制时,可以基于
L
(
N
,
S
)
=
(
N
c
N
)
α
N
+
(
S
c
S
min
(
S
)
)
α
S
L\left(N, S\right)=\left(\frac{N_{c}}{N}\right)^{\alpha_{N}}+\left(\frac{S_{c}}{S_{\min}(S)}\right)^{\alpha_{S}}
L
(
N
,
S
)
=
(
N
N
c
)
α
N
+
(
S
m
i
n
(
S
)
S
c
)
α
S
预测最优模型大小
N
N
N
、最优批量大小
B
B
B
、最优步骤数
S
S
S
和数据集大小
D
D
D
应按如下方式增长
N
∝
C
C
α
C
min
/
α
N
,
B
∝
C
α
C
min
/
α
B
,
S
∝
C
C
α
C
min
/
α
S
,
D
=
B
⋅
S
N \propto C_{C}^{\alpha_{C}^{\min } / \alpha_{N}},\quad B \propto C^{\alpha_{C}^{\min } / \alpha_{B}}, \quad S \propto C_{C}^{\alpha_{C}^{\min } / \alpha_{S}}, \quad D=B \cdot S
N
∝
C
C
α
C
m
i
n
/
α
N
,
B
∝
C
α
C
m
i
n
/
α
B
,
S
∝
C
C
α
C
m
i
n
/
α
S
,
D
=
B
⋅
S
其中
α
C
min
=
1
/
(
1
/
α
S
+
1
/
α
B
+
1
/
α
N
)
\alpha_{C}^{\min }=1 /\left(1 / \alpha_{S}+1 / \alpha_{B}+1 / \alpha_{N}\right)
α
C
m
i
n
=
1/
(
1/
α
S
+
1/
α
B
+
1/
α
N
)
作者拟合的最优结果为
N
(
C
min
)
∝
C
min
0.73
,
B
crit
∝
C
min
0.24
,
S
min
∝
C
min
0.03
N(C_{\min})\propto C_{\min}^{0.73}, \space\space B_{\text {crit }} \propto C_{\min}^{0.24}, \space\space S_{\min} \propto C_{\min}^{0.03}
N
(
C
m
i
n
)
∝
C
m
i
n
0.73
,
B
crit
∝
C
m
i
n
0.24
,
S
m
i
n
∝
C
m
i
n
0.03
,这意味着随着计算量预算
C
C
C
的提高,应该更多地增加模型参数量
N
N
N
,较少地增加训练数据量
D
D
D
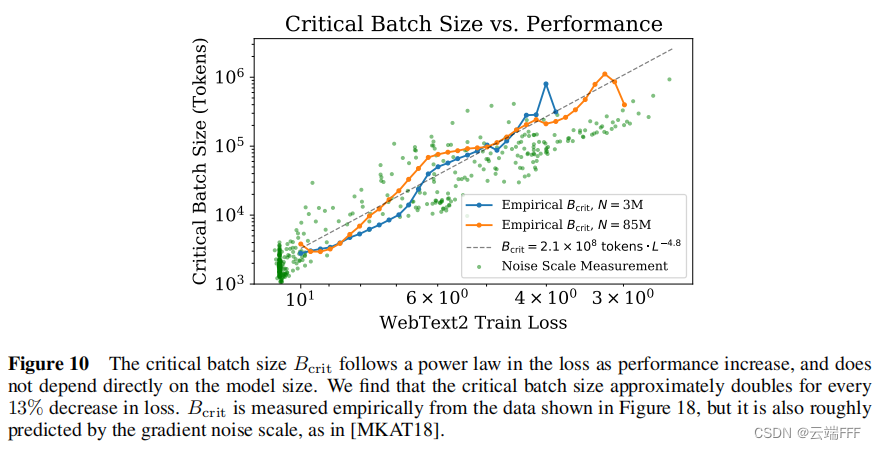
最优 batch size :使用合适的 batch size 进行训练可以实现最高的训练效率,关键 batch size 的大小 B crit B_{\text{crit}} B crit 可以通过测量梯度噪声规模来确定,作者进一步验证了它仅和目标性能(损失值)有关,且呈现幂律关系,而与模型规模等其他因素无关
最佳 batch size
B
crit
(
L
)
B_{\text {crit }}(L)
B
crit
(
L
)
仅和性能
L
L
L
相关,而与模型规模等其他因素无关。幂律关系表示为为
B
crit
(
L
)
≈
B
∗
L
1
/
α
B
B_{\text {crit }}(L) \approx \frac{B_{*}}{L^{1 / \alpha_{B}}}
B
crit
(
L
)
≈
L
1/
α
B
B
∗
其中
B
∗
B_*
B
∗
和
α
B
\alpha_B
α
B
是需要拟合的参数,这种表示可以使
B
crit
(
L
)
B_{\text {crit }}(L)
B
crit
(
L
)
的估计值在
L
→
0
L\to 0
L
→
0
时发散,以保持和另一种估计方法 “噪声梯度度量” 的一致性