在Python中使用代理进行爬虫操作可以有效地隐藏用户的真实IP地址,防止被封禁或者限制访问。下面是设置代理的示例代码:
import requests
proxies = {
"http": "http://127.0.0.1:8888",
"https": "http://127.0.0.1:8888",
}
response = requests.get('http://www.example.com', proxies=proxies)
其中,proxies字典中的键http和https分别表示http协议和https协议,值为代理服务器地址和端口号。在使用requests库发起请求时,通过proxies参数传入代理设置即可。这里的代理服务器地址为127.0.0.1,端口号为8888,你可以将其替换为你自己的代理服务器地址和端口号。
爬虫编写
需求
做一个通用爬虫,根据github的搜索关键词进行全部内容爬取。
代码
首先开启代理,在设置中修改HTTP端口。

在爬虫中根据设置的系统代理修改proxies的端口号:
import requests
from lxml import html
import time
etree = html.etree
def githubSpider(keyword, pageNumberInit):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62',
}
keyword = keyword
pageNum = pageNumberInit
url = 'https://github.com/search?p=%d&q={}'.format(keyword)
proxies = {'http': 'http://127.0.0.1:1087', 'https': 'http://127.0.0.1:1087'}
status_code = 200
while True and pageNum:
new_url = format(url % pageNum)
response = requests.get(url=new_url, proxies=proxies, headers=headers)
status_code = response.status_code
if status_code == 404:
print("===================================================")
print("结束")
return
if (status_code == 429):
print("正在重新获取第" + str(pageNum) + "页内容....")
if (status_code == 200):
print("===================================================")
print("第" + str(pageNum) + "页:" + new_url)
print("状态码:" + str(status_code))
print("===================================================")
page_text = response.text
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="js-pjax-container"]/div/div[3]/div/ul/li')
for li in li_list:
name = li.xpath('.//a[@class="v-align-middle"]/@href')[0].split('/', 1)[1]
link = 'https://github.com' + li.xpath('.//a[@class="v-align-middle"]/@href')[0]
try:
stars = li.xpath('.//a[@class="Link--muted"]/text()')[1].replace('\n', '').replace(' ', '')
except IndexError:
print("名称:" + name + "\t链接:" + link + "\tstars:" + str(0))
else:
print("名称:" + name + "\t链接:" + link + "\tstars:" + stars)
pageNum = pageNum + 1
if __name__ == '__main__':
githubSpider("hexo",1)
爬取结果如下,包含搜索结果的名称、链接以及stars:
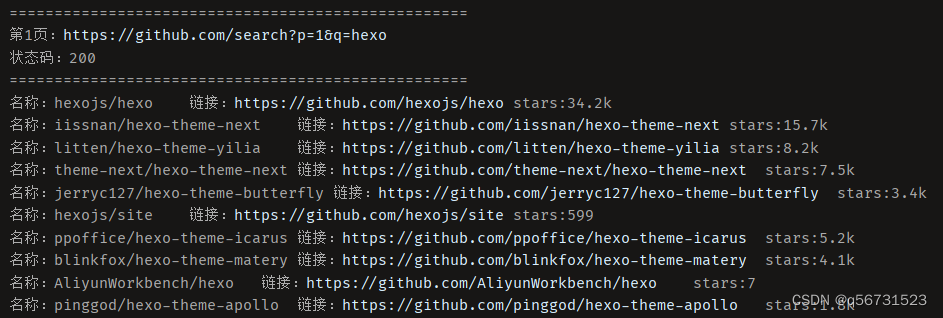
后记
爬取公网的简单测试,状态码:
import requests
proxies={'http': 'http://127.0.0.1:1087', 'https': 'http://127.0.0.1:1087'}
response = requests.get('https://www.baidu.com/',proxies=proxies)
print(response.status_code)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)