错误
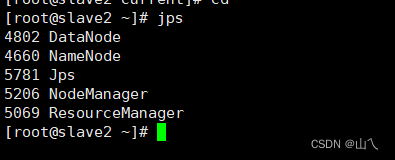
启动服务,发现没有DataNode没有启动
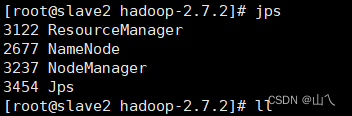
此原因是namenode和datanode的clusterID不一致导致datanode无法启动.
产生的原因
是多次hdfs namenode -format而造成的 , 每一次格式化,namenode都会生成新的clusterID , 而datanode还是保持原来的clusterID.
解决办法
-
关闭集群 stop-all.sh 必须关闭,切记,勿忘。
-
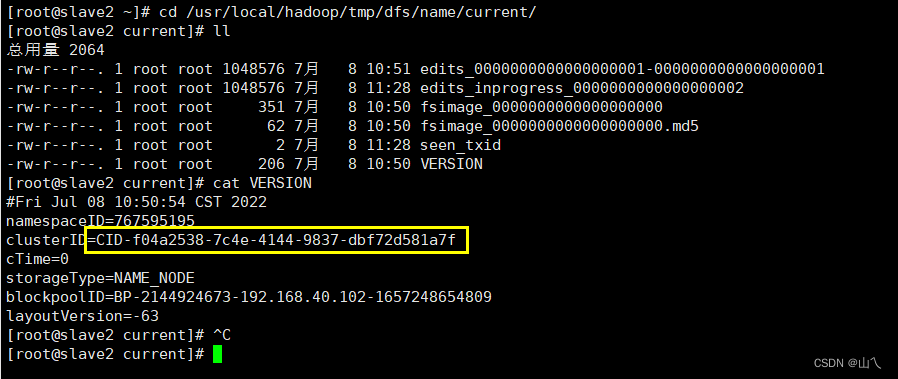
找到namenode的元数据存储目录并进入查看VERSION ,复制clusterID中的内容,元数据存储目录可以查看自己配置的hdfs-site.xml,我的目录在 /usr/local/hadoop/tmp/dfs/name/
cd /usr/local/hadoop/tmp/dfs/name/current/
cat VERSION
-
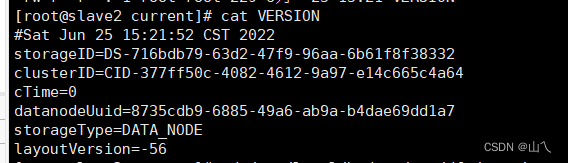
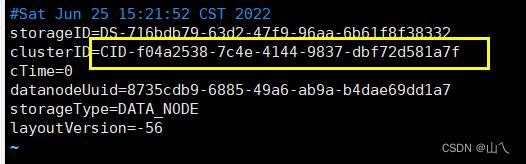
找到datanode的元数据存储目录并进入查看VERSION ,修改clusterID中的内容,使内容与namenode中的clusterID一致,元数据存储目录可以查看自己配置的hdfs-site.xml,我的目录在 /usr/local/hadoop/tmp/dfs/data/
cd /usr/local/hadoop/tmp/dfs/data/current/
cat VERSION
vim VERSION
-
重新启动 start-all.sh
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)