两个例子:调度问题与投资问题
例1:调度问题
问题
有 n 项任务,每项任务加工时间已知.从 0时刻开始陆续安排到一台机器上加工. 每个任务的完成时间是从 0 时刻到任务加工截止的时间.
求: 总完成时间(所有任务完成时间之和)最短的安排方案.
实例
任务集 S = {1, 2, 3, 4, 5},
加工时间: t 1 =3, t 2 =8, t 3 =5, t 4 =10, t 5 =15
贪心法的解
算法 :按加工时间 (3,8,5,10,15) 从小到大安排
解 :1, 3, 2, 4, 5

总完成时间:
t = 3+(3+5)+(3+5+8)+(3+5+8+10)+(3+5+8+10+15)
= 3 × 5 + 5 × 4 + 8 × 3 + 10 × 2 + 15
= 94
问题建模
输入 : 任务集: S= {1, 2, … , n } ,
第 j 项任务加工时间: t j ∈Z + , j =1,2,…, n.
输出: 调度 I , S 的排列 i 1 , i 2 , …, i n ,
目标函数: I 的完成时间, 
解 I *:使得 t ( I *) 达到最小,即
t ( I ***** )= min{ t ( I )| I 为 S 的排列}
贪心算法
设计策略 :加工时间短的先做
算法 :根据加工时间从小到大排序 , 依次加工
证:假如调度 f 第 i, j 项任务相邻且有逆序,
即 t i > t j . 交换任务 i 和 j 得到调度 g ,

总完成时间 t ( g ) − t ( f ) = t j − t i < 0
直觉不一定是正确的
反例
有4 件物品要装入背包, 物品重量和价值如下:

背包重量限制是 6,问如何选择物品,使得不超重的情况下装入背包的物品价值达到最大?
实例的解
贪心法 :单位重量价值大的优先,总重不超 6
按照 v *i / *w i 从大到小排序:1, 2, 3, 4

贪心法的解: { 1, 4 } ,重量 5 ,价值为 9.
更好的解:{ 2, 4 },重量 6,价值 11.
算法设计
1. 问题建模
2. 选择什么算法?如何描述这个方法?
3. 这个方法是否对所有实例都得到最优解?如何证明?
4. 如果不是,能否找到反例?
例2:投资问题
问题:
m 元钱,投资 n 个项目. 效益函数 f i ( x ),
表示第 i 个项目投 x 元的效益, i =1, 2, …, n.
求如何分配每个项目的钱数使得总效益最大?
实例 :
5 万元,投资给 4 个项目,效益函数:

问题建模
输入 : n , m , f i ( x ), i =1,2, …, n, x = 1,2, …, m
解 : n 维向量 < x 1 , x 2 , … , x n >, x i 是第 i 个
项目的钱数,使得下述条件满足:

蛮力算法
对所有满足下述条件的向量 < x 1 , x 2 ,…, x n >
x 1 + x 2 + … + x n = m
x i 为非负整数, i = 1, 2 , …, n
计算相应的效益 f 1 ( x 1 ) + f 2 ( x 2 ) + … + f n ( x n ) 从中确认效益最大的向量.
实例计算

解: s =<1,0,3,1>, 最大效益:11+30+20 = 61
蛮力算法的效率
方程 x 1 + x 2 + … + x n = m 的非负整数解
< x 1 , x 2 , …, x n > 的个数估计:
可行解表示成 0-1 序列: m 个 1, n -1 个 0

n =4, m =7
可行解 <1, 2, 3, 1>
⇔ 序列 1 0 1 1 0 1 1 1 0 1
序列个数是输入规模的指数函数
C ( m + n − 1, m )
= ( m + n − 1)!
m !( n − 1)!
= Ω((1 + ε ) m + n −1 )
小结
问题求解的关键
• 建模:对输入参数和解给出形式化或半形式化的描述
• 设计算法:
采用什么算法设计技术
正确性——是否对所有的实例都得到正确的解
• 分析算法——效率
问题计算复杂度的界定:排序问题
例3 排序算法的效率
以元素比较作基本运算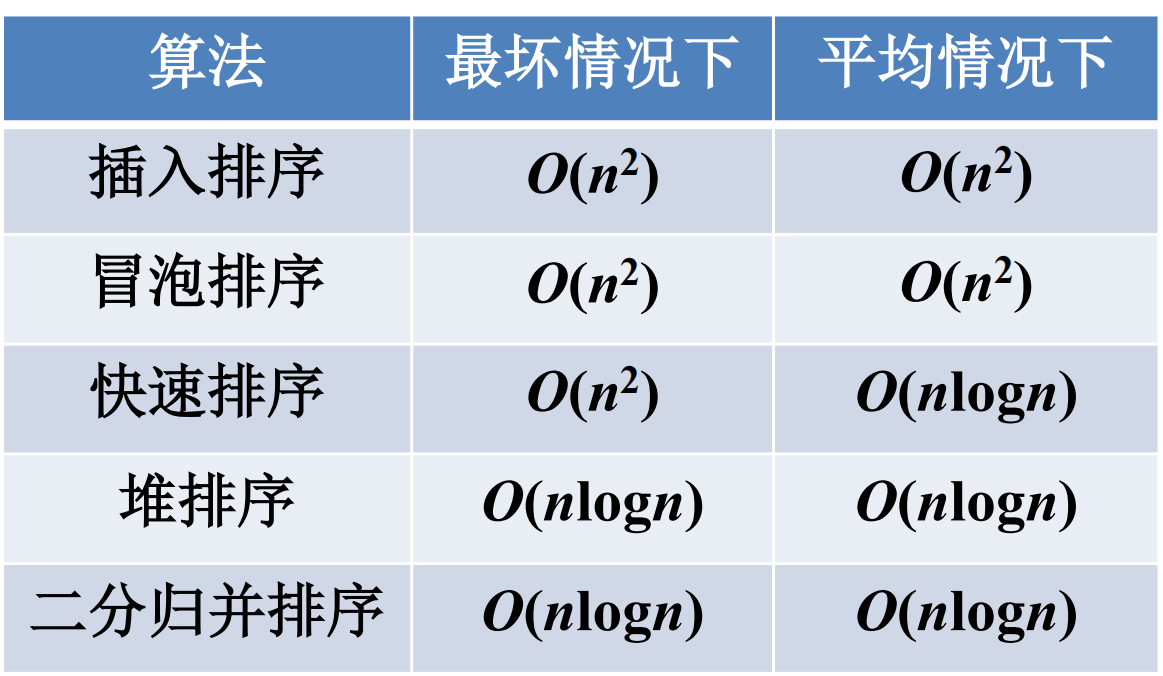
插入排序的插入操作
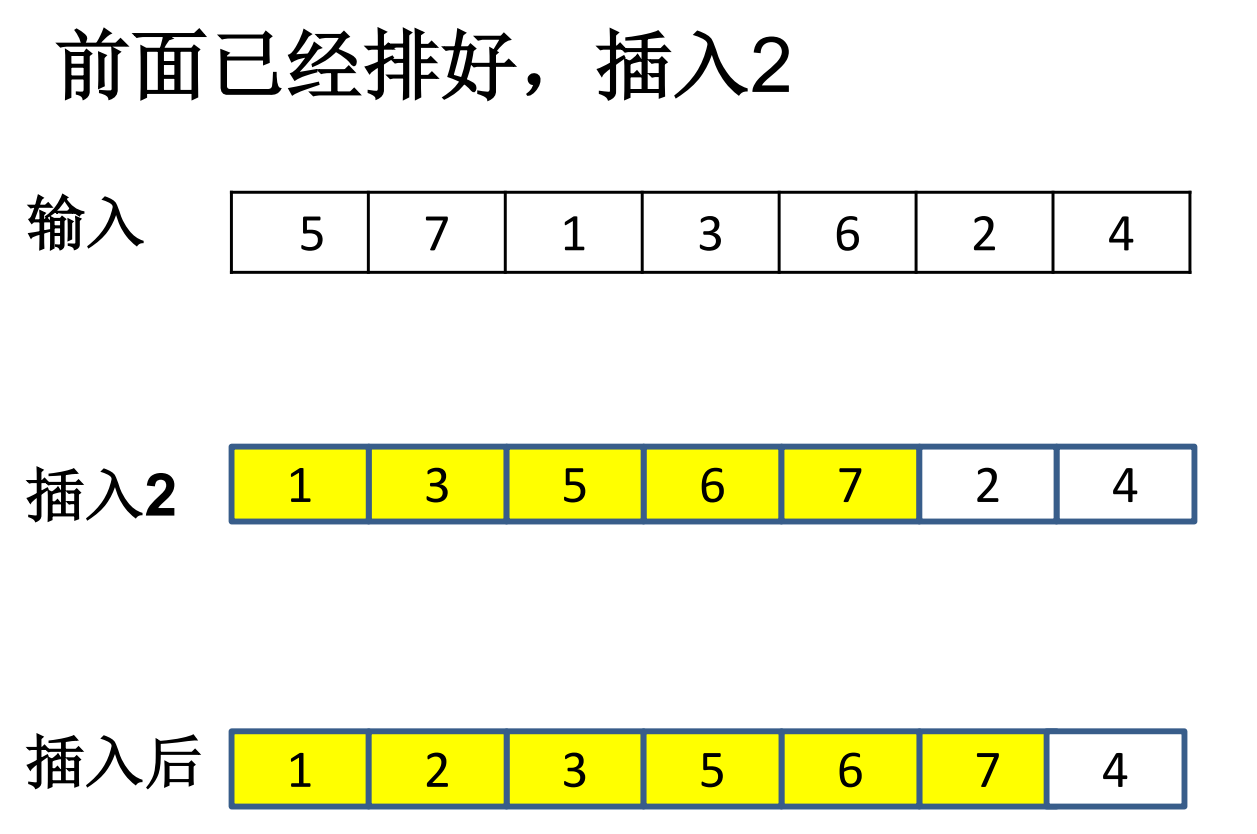
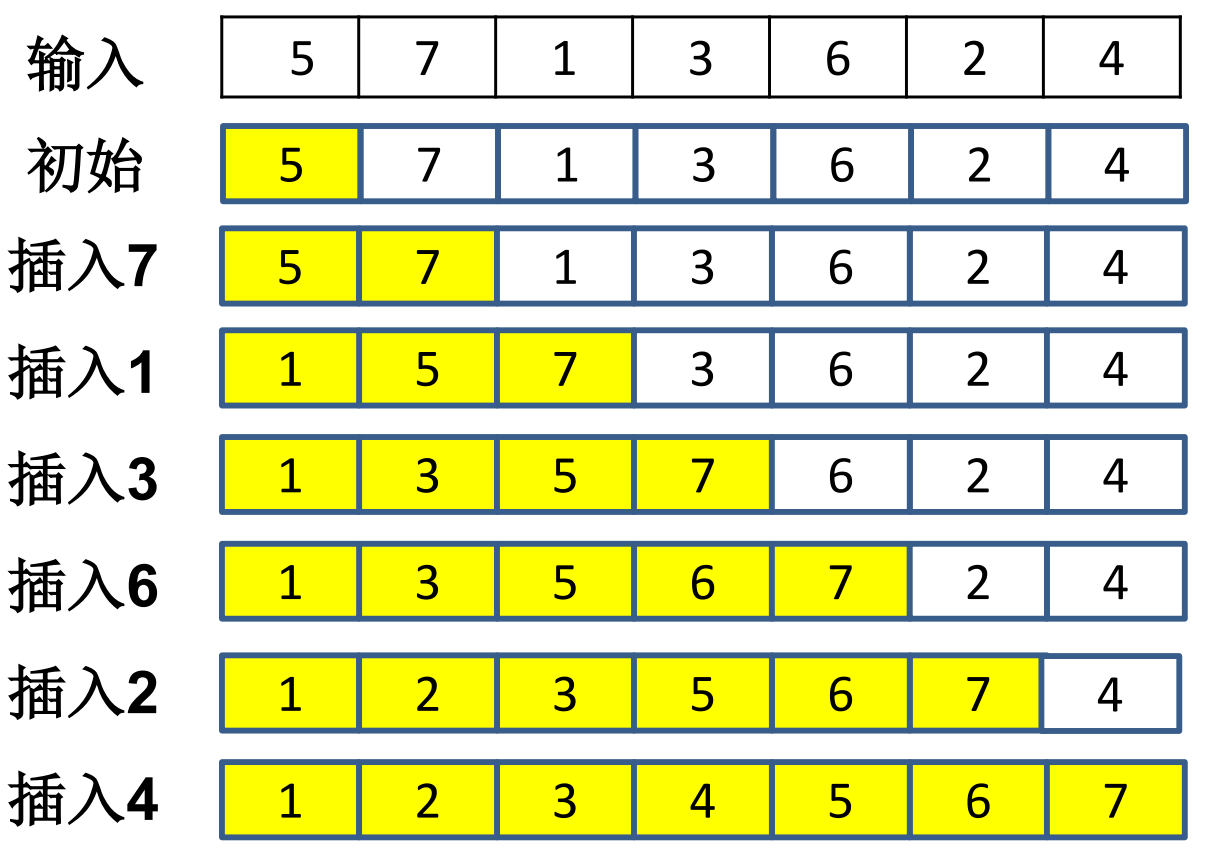
插入排序运行实例
冒泡排序的一次巡回

冒泡排序运行实例

快速排序一次递归运行

二分归并排序运行实例

问题的计算复杂度分析

小结
几种排序算法简介
插入排序
冒泡排序
快速排序
归并排序
• 排序问题的难度估计——界定什么是最好的排序算法
货郎问题与计算复杂性理论
例4 货郎问题
问题:
有 n 个城市,已知任两个城市之间的距
离 . 求一条每个城市恰好经过 1 次的回路,
使得总长度最小.
建模与算法
• 输入
有穷个城市的集合 C = { c 1 , c 2 , …, c n },
距离 d ( c i , c j ) = d ( c j , c i ) ∈ Z + , 1 ≤ i < j ≤ n
• 解 :1, 2 …, n 的排列 k 1 , k 2 , …, k n 使得:
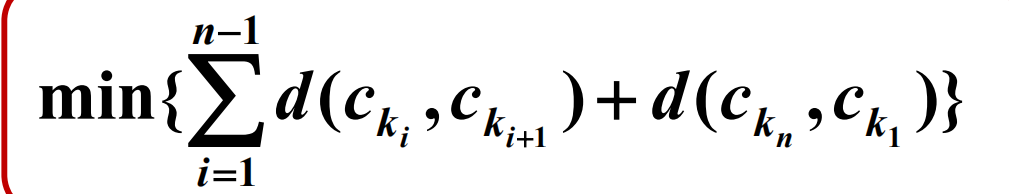
• 现状 :至今没找到有效的算法
0-1背包问题
有 n 个件物品要装入背包, 第 i 件物品的重量 w i , 价值 v i , i =1,2,…, n . 背包最多允许装入的重量为 B , 问如何选择装 入背包的物品,使得总价值达到最大?
实例 : n =4, B =6,物品的重量和价值如下

0-1背包问题建模
问题的 解 : 0-1 向量 < x 1 , x 2 , …, x n >
x i =1 ⇔ 物品 i 装入背包
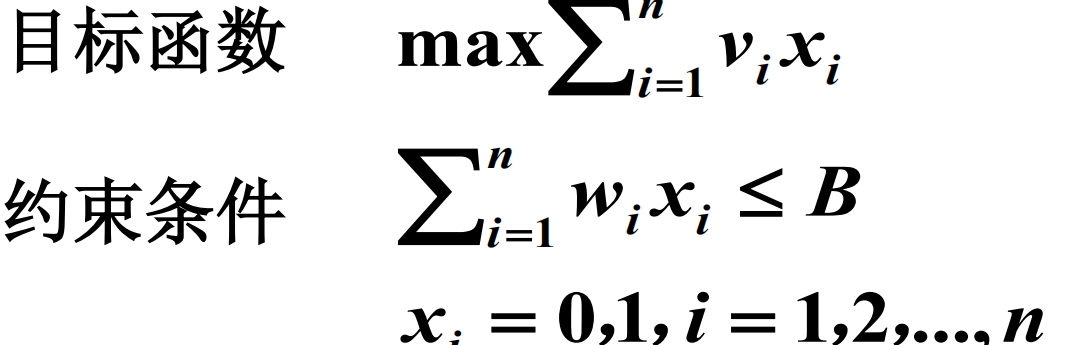
双机调度
双机调度问题 :
有 n 项任务, 任务 i 的加工时间为 t i , t i ∈Z + , i =1,2,…, n . 用两台相同的机器加工,从0时刻开始计时,完成时间是后停止加工机器的停机时间. 问如何把这些任务分配到两台机器上,使得完成时间达到最小?
实例 :
任务集 S ={1,2,3,4,5,6}
t 1 =3, t 2 =10, t 3 =6, t 4 =2, t 5 =1, t 6 =7
解:机器 1 的任务: 1, 2, 4
机器 2 的任务:3, 5, 6
完成时间 : max{ 3+10+2, 6+1+7 }=15
双机调度建模
解 : 0-1 向量 < x 1 , x 2 , …, x n >, x i =1 表示任务 i
分 配到第一台机器, i =1,2,…, n .
不妨设机器 1 的加工时间 ≤ 机器 2 的加工时
间令 T = t 1 + t 2 +…+ t n , D = T /2 ,机器 1 的加工
时间不超过 D ,且达到最大
如何对该问题建模?目标函数与约束条件是什么?
NP-hard问题
这样的问题有数千个,大量存在于各
个应用领域 .
NP-hard问题
• 至今没有人能够证明对于这类问题不存在多项式时间的算法.
• 至今没找到有效算法:现有的算法的运行时间是输入规模的指数或更高阶函数.
• 从是否存在多项式时间算法的角度看,这些问题彼此是等价的. 这些问题的难度处于可有效计算的边界.

课程主要内容

算法研究的重要性
算法设计与分析技术在计算机科学与技术领域有着重要的应用背景算法设计分析与计算复杂性理论研究是计算机科学技术的核心研究领域
1966-2005期间,Turing奖获奖50人, 其中10人以算法设计, 7人以计算理论、自动机和复杂性研究领域的杰出贡献获奖
计算复杂性理论的核心课题“P=NP?”是本世纪 7个最重要的数学问题之一 提高学生素质和分析问题解决问题的能力,培养计算思维
小结
• NP-hard问题的几个例子:货郎问题0-1背包问题、双机调度问题等
• NP-hard问题的计算现状
• 计算复杂性理论的核心—— NP完全理论
• 算法研究的主要内容及重要意义
算法及其时间复杂度
问题研究及实例
• 问题
需要回答的一般性提问,通常含若干参数
• 问题描述
定义问题参数(集合,变量,函数,序列等)说明每个参数的取值范围及参数间的关系定义问题的解说明解满足的条件(优化目标或约束条件)
• 问题实例
参数的一组赋值可得到问题的一个实例
算法
• 算法
有限条指令的序列
这个指令序列确定了解决某个问题的一系列运算或操作
• 算法 A 解问题 P
把问题 P 的任何实例作为算法 A 的输入每步计算是确定性的 A 能够在有限步停机输出该实例的正确的解
基本运算与输入规模
• 算法时间复杂度 :
针对指定 基本运算 ,计数算法所做运算次数
• 基本运算 :
比较, 加法, 乘法, 置指针, 交换…
• 输入规模 :
输入串编码长度通常用下述参数度量:数组元素多少,调度问题的任务个数,图的顶点数与边数等.
• 算法基本运算次数可表为输入规模的函数
• 给定问题和基本运算就决定了一个算法类
输入规模
• 排序:数组中元素个数 n
• 检索:被检索数组的元素个数 n
• 整数乘法:两个整数的位数 m, n
• 矩阵相乘:矩阵的行列数 i, j, k
• 图的遍历:图的顶点数 n , 边数 m
…
基本运算
• 排序 : 元素之间的 比较
• 检索 : 被检索元素 x 与数组元素的 比较
• 整数乘法: 每位数字相乘(位乘) 1 次 m 位和 n 位整数相乘要做 mn 次 位乘
• 矩阵相乘: 每对 元素乘 1 次 i × j 矩阵与 j × k 矩阵相乘要做 i jk 次乘法
• 图的遍历 : 置指针
…
算法的两种时间复杂度
对于相同输入规模的不同实例,算法的基本
运算次数也不一样,可定义两种时间复杂度
最坏情况下的时间复杂度 W ( n )
算法求解输入规模为 n 的实例所需要的最长
时间
平均情况下的时间复杂度 A ( n )
在给定同样规模为 n 的输入实例的概率分布
下,算法求解这些实例所需要的平均时间
A ( n ) 计算公式
平均情况下的时间复杂度 A ( n )
设 S 是规模为 n 的实例集
实例 I ∈ S 的概率是 P I
算法对实例 I 执行的基本运算次数是 t I

在某些情况下可以假定每个输入实例概
率相等
例子:检索

顺序检索算法
j =1, 将 x 与 L [ j ]比较. 如果 x = L [ j ],则算法停止,输出 j ;如果不等,则把 j 加1,继续 x 与 L [ j ]的比较,如果 j > n ,则停机并输出0.

x = 4 ,需要比较 4 次
x = 2.5,需要比较 5 次
改进顺序检索算法
j =1, 将 x 与 L [ j ]比较. 如果 x = L [ j ],则算法停 止,输出 j ;如果 x > L [ j ],则把 j 加1,继续 x 与 L [ j ]的比较;如果 x < L [ j ],则停机并输出0. 如果 j > n ,则停机并输出 0.

x = 4 ,需要比较 4 次
x = 2.5,需要比较 3 次
最坏情况的时间估计
不同的输入有 2 n + 1 个,分别对应:
x = L [1], x = L [2], … , x = L [ n ]
x < L [1], L [1]< x < L [2], L [2]< x < L [3], … , L [ n ]< x
最坏情况下时间: W ( n ) = n
最坏的输入: x 不在 L 中或 x = L [ n ]要做 n 次比较
平均情况的时间估计

时间估计
最坏情况下: W ( n ) = n
平均情况下
输入实例的概率分布:假设 x 在 L 中每个
位置与空隙的概率都相等
改进检索算法平均时间复杂度是多少?
小结:
• 算法最坏和平均情况下的时间复杂度定义
• 如何计算上述时间复杂度
算法的伪码表示
算法的伪码描述
赋值语句: ←
分支语句: if …then … [else…]
循环语句: while, for,repeat until
转向语句: goto
输出语句: return
调用:直接写过程的名字
注释: //…
例:求最大公约数
算法 Euclid ( m, n )
输入:非负整数 *m, n, *其中 m 与 n 不全为 0
输出: m 与 n 的最大公约数
1. while m > 0 do
2. r ← n mod m
3. n ← m
4. m ← r
5. return n
运行实例: n =36, m =15

例:改进的顺序检索
算法 Search ( L, x )
输入:数组 L [1… n ], 元素从小到大排列 , 数 x.
输出:若 x 在 L 中,输出 x 的位置下标 j ;
否则输出 0.
1. j ← 1
2. while j ≤ n and x > L [ j ] do j ← j +1
3. if x < L [ j ] or j > n then j ← 0
4. return j
例:插入排序
算法 Insert Sort ( A, n )
输入: n 个数的数组 A
输出:按照递增顺序排好序的数组 A
1. for j ← 2 to n do
2. x ← A [ j ]
3. i ← j −1 //3-7 行把 A [ j ] 插入 A [1… j −1]

运行实例

例:二分归并排序
MergeSort ( A , p , r )
输入:数组 A [ p … r ]
输出:按递增顺序排序的数组 A
1. if p < r
2. then q ← ( p+r )/2
3. MergeSort ( A , p , q )
4. MergeSort ( A , q +1, r )
5. Merge ( A , p , q , r )
MergeSort有递归调用,也调用Merge过程
例:算法A的伪码


小结
用伪码表示算法
• 伪码不是程序代码,只是给出算法的
主要步骤
• 伪码中有哪些关键字?
• 伪码中允许过程调用
函数的渐近的界
大 O 符号
定义 : 设 f 和 g 是定义域为自然数集
N 上的函数 . 若存在正数 c 和 n 0 ,使得
对一切 n n 0 有
0 f ( n ) c g ( n )
成立 , 则称 f ( n ) 的渐近的上界是 g ( n ) ,
记作
f ( n ) = O ( g ( n ))
例子
设 f ( n ) = n 2 + n ,
则 f ( n )= O ( n 2 ),取 c = 2, n 0 =1 即可
f ( n )= O ( n 3 ),取 c = 1, n 0 =2 即可
1. f ( n ) = O ( g ( n )) , f ( n )的阶不高于 g ( n )的阶.
2. 可能存在多个正数 c ,只要指出一个即可 .
3. 对前面有限个值可以不满足不等式 .
4. 常函数可以写作 O (1).
大 符号
定义 :设 f 和 g 是定义域为自然数集
N 上的函数 . 若存在正数 c 和 n 0 ,使
得对一切 n n 0 有
0 cg ( n ) f ( n )
成立 , 则称 f ( n ) 的渐近的下界是 g ( n ),
记作
f ( n ) = ( g ( n ))
例子
设 f ( n ) = n 2 + n ,则
f ( n ) = ( n 2 ), 取 c = 1, n 0 =1 即可
f ( n ) = (100 n ), 取 c =1/100, n 0 =1 即可
1. f ( n )= ( g ( n )) , f ( n ) 的阶不低于 g ( n ) 的阶 .
2. 可能存在多个正数 c ,指出一个即可 .
3. 对前面有限个 n 值可以不满足上述不等式.
小 o 符号
定义 设 f 和 g 是定义域为自然数集 N 上
的函数 . 若对于任意正数 c 都存在 n 0 ,使
得对一切 n n 0 有
0 f ( n ) < c g ( n )
成立 , 则记作
f ( n ) = o ( g ( n ))
例子

小 W 符号
定义 :设 f 和 g 是定义域为自然数集 N 上
的函数 . 若对于任意正数 c 都存在 n 0 ,使
得对一切 n n 0 有
0 cg ( n ) < f ( n )
成立 , 则记作
f ( n ) = ( g ( n ))
例子

符号

例子:素数测试

小结

有关函数渐近的界的定理
定理1

证明定理1(1) 
例:估计函数的阶

一些重要结果

一些重要结果(续)

定理 2
定理 设函数 f, g, h 的定义域为自然数集合,
(1) 如果 f = O ( g ) 且 g = O ( h ) ,那么 f = O ( h ).
(2) 如果 f = Ω ( g ) 且 g = Ω ( h ) *, *那么 f = Ω ( h ).
(3) 如果 f = Θ ( g ) 和 g = Θ ( h ) *, *那么 f = Θ ( h ) .
函数的阶之间的关系具有传递性
例子
按照阶从高到低排序以下函数:
f ( n )=( n 2 + n )/2 , g ( n )=10 n
h ( n )=1.5 n , t ( n )= n 1/2
h ( n ) = ω ( f ( n )) ,
f ( n ) = ω ( g ( n )),
g ( n ) = ω ( t ( n )),
排序 h ( n ), f ( n ), g ( n ), t ( n )
定理3
定理 假设函数 f 和 g 的定义域为自然数集,
若对某个其它函数 h , 有 f = O ( h ) 和 g = O ( h ) ,
那么 f + g = O ( h ).
该性质可以推广到有限个函数 .
算法由有限步骤构成 . 若每一步的时间复
杂度函数的上界都是 h ( n ) ,那么该算法的
时间复杂度函数可以写作 O ( h ( n ))
小结
• 估计函数的阶的方法:
计算极限
阶具有传递性
• 对数函数的阶低于幂函数的阶,多项
式函数的阶低于指数函数的阶 .
• 算法的时间复杂度是各步操作时间之
和,在常数步的情况下取最高阶的函
数即可.
几类重要的函数
基本函数类
阶的高低
至少指数级: 2 n , 3 n , n !, …
多项式级: n , n 2 , n log n , n 1/2 , …
对数多项式级: log n , log 2 *n, *loglog n, …
对数函数
符号:
log n = log 2 n
log k n = (log n ) k
loglog n = log(log n )
性质:
(1) log 2 n = Θ (log l n )
(2) log b n = o ( n α ) α > 0
(3) a log b n = n log b a
有关性质(1)的证明

有关性质(2)(3)的说明

指数函数与阶乘
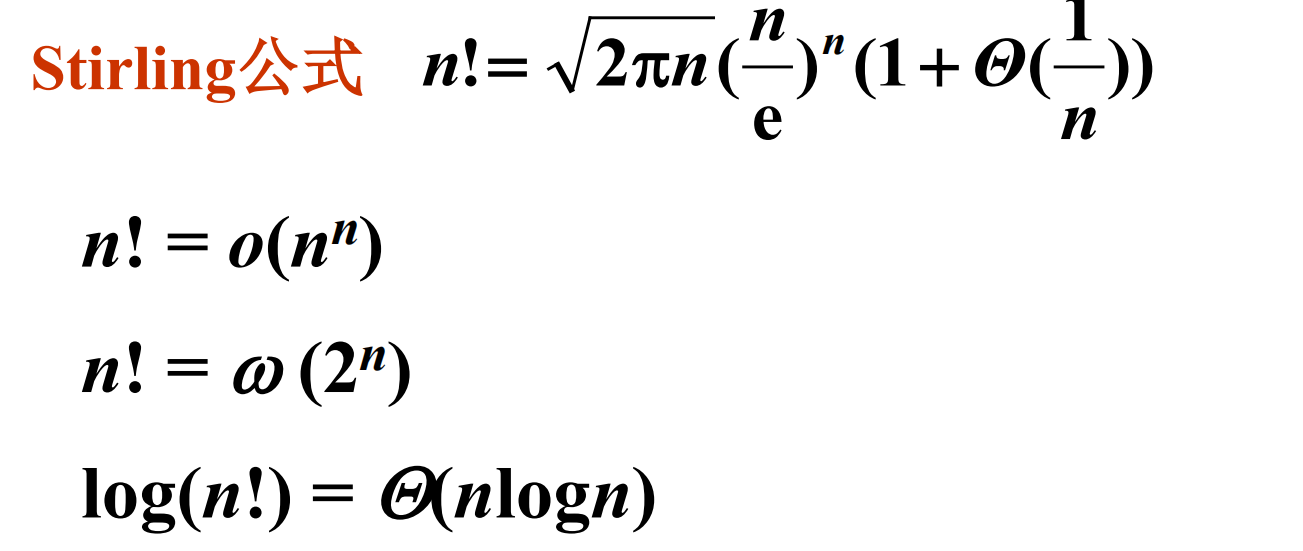
应用:估计搜索空间大小

log( n !) = Ω ( n log n )的证明

log( n !) = O ( n log n )的证明

取整函数

取整函数的性质


例:按照阶排序

例:按照阶排序
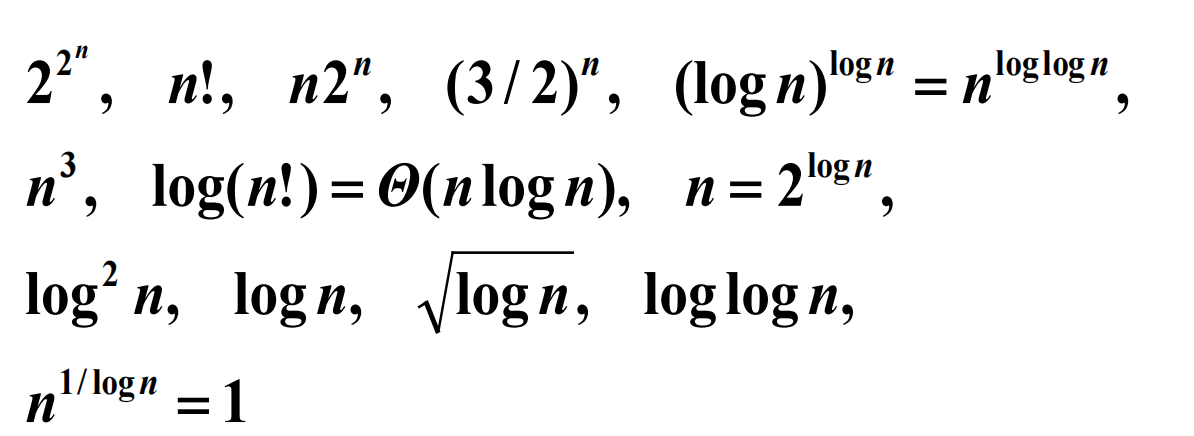
小结
• 几类常用函数的阶的性质
对数函数
指数函数
阶乘函数
取整函数
• 如何利用上述性质估计函数的阶?
基
有关基本概
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)