准备训练的数据集
相关代码已整理至github:https://github.com/whisperLiang/efficientnet_pytorch.git
相关代码已整理至码云:https://gitee.com/whisperliang/efficientnet_pytorch.git
精度更高代码github链接(star走起):https://github.com/whisperLiang/Efficientnet_pytorch_cbam_gui.git
精度更高代码码云链接(star走起):https://gitee.com/whisperliang/Efficientnet_pytorch_cbam_gui.git
精度更高代码使用博客说明:Train you own dataset with Efficientnet
论文:Classification of fine-grained species of marine organisms based on multi-scale fusion
数据集下载链接:https://pan.baidu.com/s/1qcUomiTYHCKsnq6pFcwgvA
提取码:mwdq
最近私聊的人有一点多,如果实在自己不懂部署的,本人有偿帮忙。
由于我原本的数据集是没有经过任何处理的,格式如图所示:
data文件夹对应的图像集:
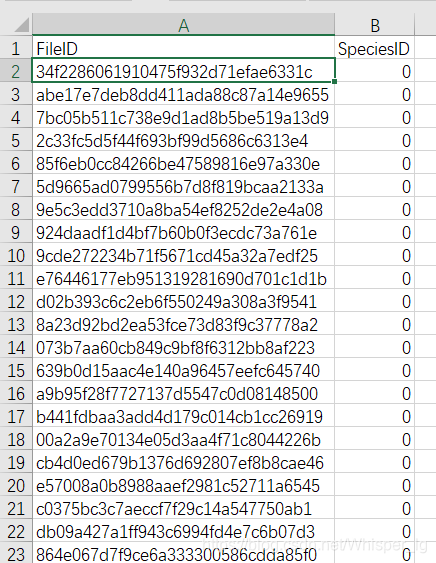
图像的标签在training.csv文件夹中,如图所示:
而输入的图像文件却需要满足ImageFolder的格式:
class ImageFolder(DatasetFolder):
"""A generic data loader where the images are arranged in this way: ::
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
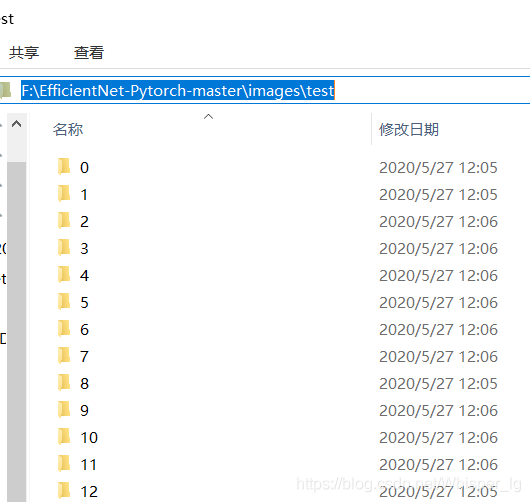
我通过convert_dataset.py文件对图像格式进行转化。
import pandas as pd
import shutil
import os
def convert_dataset(csv_filename, pre_path, root_path):
path_lst = []
data_file = pd.read_csv(csv_filename)
id_tuple = tuple(data_file["FileID"].values.tolist())
classes_tuple = tuple(data_file["SpeciesID"].values.tolist())
try:
for i in range(len(id_tuple)):
new_path = os.path.join(root_path, str(classes_tuple[i]))
if not os.path.exists(new_path):
os.makedirs(new_path)
shutil.copy(os.path.join(pre_path, id_tuple[i]+".jpg"),os.path.join(new_path,id_tuple[i]+".jpg"))
except:
print("match error")
pre_path = "af2020cv-2020-05-09-v5-dev/data"
train_root_path = "images/train"
test_root_path = "images/test"
train_filename = 'af2020cv-2020-05-09-v5-dev/training.csv'
test_filename = 'af2020cv-2020-05-09-v5-dev/annotation.csv'
if __name__ == '__main__':
convert_dataset(train_filename, pre_path, train_root_path)
convert_dataset(test_filename, pre_path, test_root_path)
print("dataset converting is finished!")
处理结果如图所示:
训练自己的数据集及绘制acc_loss图像
训练和预测模型代码参考两篇博客:
- EfficientNet 训练测试自己的分类数据集
- EfficientNet训练自己的烟火识别算法
基于上述两篇博客,我得到自己的模型代码:underwater_classify.py
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, models, transforms
import time
import os
import json
from efficientnet_pytorch.model import EfficientNet
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
image_dir = './tests/fe803d232e3c959f95e4df9b9b383432.jpg'
use_gpu = torch.cuda.is_available()
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
data_dir = 'images'
batch_size = 64
lr = 0.01
momentum = 0.9
num_epochs = 80
input_size = 224
class_num = 20
net_name = 'efficientnet-b3'
def loaddata(data_dir, batch_size, set_name, shuffle):
data_transforms = {
'train': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in [set_name]}
dataset_loaders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=shuffle, num_workers=1) for x in [set_name]}
data_set_sizes = len(image_datasets[set_name])
return dataset_loaders, data_set_sizes
def train_model(model_ft, criterion, optimizer, lr_scheduler, num_epochs=50):
train_loss = []
loss_all = []
acc_all = []
since = time.time()
best_model_wts = model_ft.state_dict()
best_acc = 0.0
model_ft.train(True)
for epoch in range(num_epochs):
dset_loaders, dset_sizes = loaddata(data_dir=data_dir, batch_size=batch_size, set_name='train', shuffle=True)
print('Data Size', dset_sizes)
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
optimizer = lr_scheduler(optimizer, epoch)
running_loss = 0.0
running_corrects = 0
count = 0
for data in dset_loaders['train']:
inputs, labels = data
labels = torch.squeeze(labels.type(torch.LongTensor))
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
outputs = model_ft(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if count % 30 == 0 or outputs.size()[0] < batch_size:
print('Epoch:{}: loss:{:.3f}'.format(epoch, loss.item()))
train_loss.append(loss.item())
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dset_sizes
epoch_acc = running_corrects.double() / dset_sizes
loss_all.append(int(epoch_loss*100))
acc_all.append(int(epoch_acc*100))
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model_ft.state_dict()
if epoch_acc > 0.999:
break
save_dir = data_dir + '/model'
model_ft.load_state_dict(best_model_wts)
model_out_path = save_dir + "/" + net_name + '.pth'
torch.save(best_model_wts, model_out_path)
x1 = list(range(len(acc_all)))
x2 = list(range(len(loss_all)))
y1 = acc_all
y2 = loss_all
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-', label="Train_Accuracy")
plt.title('train acc vs. iter')
plt.ylabel('train accuracy')
plt.legend(loc='best')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-', label="Train_Loss")
plt.xlabel('train loss vs. iter')
plt.ylabel('train loss')
plt.legend(loc='best')
plt.savefig(save_dir + "/"+"acc_loss.png")
plt.show()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
return train_loss, best_model_wts
def test_model(model, criterion):
model.eval()
running_loss = 0.0
running_corrects = 0
cont = 0
outPre = []
outLabel = []
dset_loaders, dset_sizes = loaddata(data_dir=data_dir, batch_size=16, set_name='test', shuffle=False)
for data in dset_loaders['test']:
inputs, labels = data
labels = torch.squeeze(labels.type(torch.LongTensor))
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
if cont == 0:
outPre = outputs.data.cpu()
outLabel = labels.data.cpu()
else:
outPre = torch.cat((outPre, outputs.data.cpu()), 0)
outLabel = torch.cat((outLabel, labels.data.cpu()), 0)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
cont += 1
print('Loss: {:.4f} Acc: {:.4f}'.format(running_loss / dset_sizes,
running_corrects.double() / dset_sizes))
def exp_lr_scheduler(optimizer, epoch, init_lr=0.01, lr_decay_epoch=10):
"""Decay learning rate by a f# model_out_path ="./model/W_epoch_{}.pth".format(epoch)
# torch.save(model_W, model_out_path) actor of 0.1 every lr_decay_epoch epochs."""
lr = init_lr * (0.8**(epoch // lr_decay_epoch))
print('LR is set to {}'.format(lr))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
return optimizer
pth_map = {
'efficientnet-b0': 'efficientnet-b0-355c32eb.pth',
'efficientnet-b1': 'efficientnet-b1-f1951068.pth',
'efficientnet-b2': 'efficientnet-b2-8bb594d6.pth',
'efficientnet-b3': 'efficientnet-b3-5fb5a3c3.pth',
'efficientnet-b4': 'efficientnet-b4-6ed6700e.pth',
'efficientnet-b5': 'efficientnet-b5-b6417697.pth',
'efficientnet-b6': 'efficientnet-b6-c76e70fd.pth',
'efficientnet-b7': 'efficientnet-b7-dcc49843.pth',
}
model_ft = EfficientNet.from_name('efficientnet-b3')
num_ftrs = model_ft._fc.in_features
model_ft._fc = nn.Linear(num_ftrs, class_num)
criterion = nn.CrossEntropyLoss()
if use_gpu:
model_ft = model_ft.cuda()
criterion = criterion.cuda()
optimizer = optim.SGD((model_ft.parameters()), lr=lr,
momentum=momentum, weight_decay=0.0004)
train_loss, best_model_wts = train_model(model_ft, criterion, optimizer, exp_lr_scheduler, num_epochs=num_epochs)
print('-' * 10)
print('Test Accuracy:')
model_ft.load_state_dict(best_model_wts)
criterion = nn.CrossEntropyLoss().cuda()
test_model(model_ft, criterion)
运行以上代码,得到的训练好的模型存储在images/model路径中
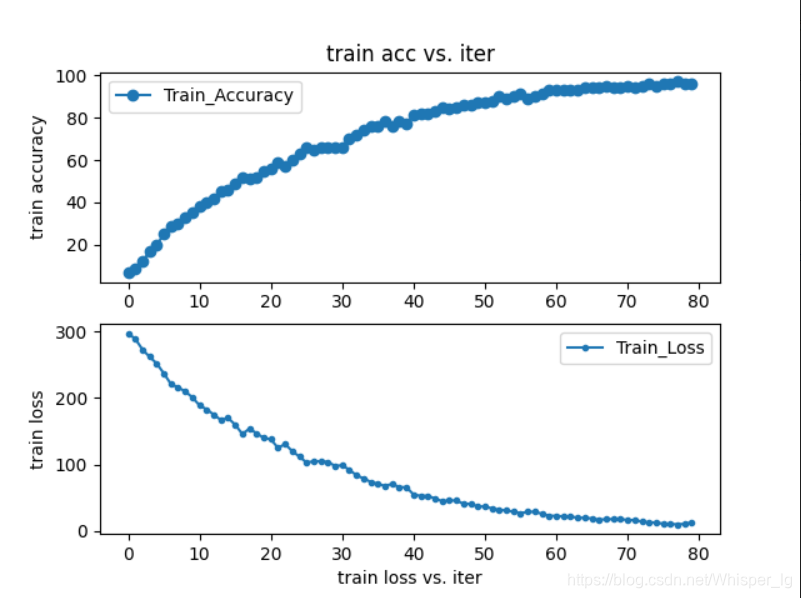
绘制得到的acc_loss图像也存储在images/model中,图像如图所示:
此外我们还得到了一个整体分类评估结果:

分类自己的数据集
生成label_map
- 由于分类的时候需要得到每一张图片的labels,这样我们通过预测的准确率和对应的labels就可以知道对输入图片的分类的结果,因此首先我们需要生成自己的labels_map,其格式为json。
- 运行
create_map.py
import pandas as pd
import os
import json
def create_map(csv_filename, txt_name):
data_file = pd.read_csv(csv_filename)
id_list = data_file["ID"].values.tolist()
classes_list = data_file["ScientificName"].values
dict_map = dict(zip(id_list, id_list))
json_map = json.dumps(dict_map)
with open(txt_name, 'w', encoding='utf8') as f:
f.write(json_map)
if __name__ == "__main__":
csv_filename = "af2020cv-2020-05-09-v5-dev/species.csv"
txt_name = "underwater.txt"
create_map(csv_filename, txt_name)
通过以上代码,便得到了标签,如图所示:
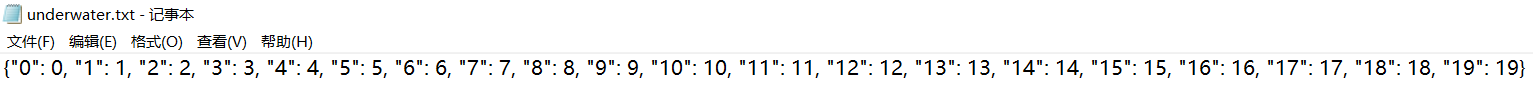
分类自己的数据集
- 训练的时候也得到了一个分类结果,但是那个不属于完整意义的分类,可以理解为对认为分类好的结果的整体评估。
- 因此如何实现模型自动分类呢?
对单张图片实现分类
运行test_prediction.py
from __future__ import print_function, division
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
import numpy as np
import torch.nn.functional as FUN
import os
from scipy import io
import json
from efficientnet_pytorch.model import EfficientNet
from PIL import Image, ImageDraw, ImageFont
input_size = 224
class_num = 20
image_dir = './images/test/10/0b38a8ed01e51cd614bc8ffb0197a598.jpg'
use_gpu = torch.cuda.is_available()
def test_model(model):
model.eval()
tfms = transforms.Compose([transforms.Resize(224), transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),])
image = Image.open(image_dir)
img = tfms(image).unsqueeze(0)
img = Variable(img.cuda())
labels_map = json.load(open('examples/simple/underwater.txt'))
labels_map = [labels_map[str(i)] for i in range(20)]
with torch.no_grad():
outputs = model(img)
print('-----')
cout = 0
for idx in torch.topk(outputs, k=20).indices.squeeze(0).tolist():
cout += 1
prob = torch.softmax(outputs, dim=1)[0, idx].item()
print('{label:<75} ({p:.2f}%)'.format(label=labels_map[idx], p=prob*100))
if __name__ == '__main__':
model_ft = EfficientNet.from_name('efficientnet-b1')
num_ftrs = model_ft._fc.in_features
model_ft._fc = nn.Linear(num_ftrs, class_num)
if use_gpu:
model_ft = model_ft.cuda()
print('-' * 10)
print('Test Accuracy:')
model_ft.load_state_dict(torch.load("./images/model/efficientnet-b1.pth"))
test_model(model_ft)
分类结果如图所示:
结果中我只打印了准确度前五的物体标签,测试的图片就是标签为0,对应的物体是Eretmochelys imbricata。百度信息如下:

而我输入的图片为下图:

因此此次预测单张图片的分类结果是准确的,准确度为95.03%!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)