因为想申请 CSDN 博客认证需要一定的粉丝量,而我写了五年博客才 700 多粉丝,本文开启关注才可阅读全文,很抱歉影响您的阅读体验
- 参考:
- Richard S.Sutton 《Reinforce Learning》第3章
- 魏宁《深度强化学习落地指南》第4章
文章目录
- 1. 奖励函数的本质:向智能体传达目标
- 2. 主线奖励和稀疏奖励问题
-
- 3. 完善奖励函数设置
- 3.1 三种辅助奖励函数
- 3.2 奖励函数设计的困境
- 3.3 奖励设定实验
- 3.3.1 常见问题
- 3.3.2 对比几种可行的鼓励方式
- 4. 站在更高的角度上
1. 奖励函数的本质:向智能体传达目标
-
强化学习的标准交互过程如下:每个时刻,智能体根据根据其 策略(policy),在当前所处 状态(state) 选择一个 动作(action),环境(environment) 对这些动作做出相应的相应的响应,转移到新状态,同时产生一个 奖励信号 (reward),这通常是一个数值,奖励的折扣累加和称为 收益/回报 (return),是智能体在动作选择过程中想要最大化的目标

在这个过程中,“奖励 & 收益” 其实是智能体目标的一种形式化、数值化的表征。可以把这种想法非正式地表述为 “收益假设”
智能体所有的 “目标” 或 “目的” 都可以归结为:最大化智能体收到的标量奖励信号的累计和(称之为“收益”)的概率期望值 —— Richard S.Sutton
使用收益来形式化目标是强化学习最显著的特征之一
-
注意,收益是通过奖励信号计算的,而奖励函数是我们提供的,奖励函数起到了人与算法沟通的桥梁作用
某种程度上,奖励函数设计可以看作 “面向强化学习的编程”,算法工程师根据特殊 “语法”,将期望的任务和目标 “翻译” 成奖励函数,由强化学习算法进行 “编译”,最后在 agent 与 environment 的交互过程中 “运行”(指导算法训练)。“编译器”(RL算法)的性能和 “编程质量”(奖励函数质量)共同决定了策略的性能
-
需要注意的是,智能体只会学习如何最大化收益,如果想让它完成某些指定任务,就必须保证我们设计的奖励函数可以使得智能体最大化收益的同时也能实现我们的目标
2. 主线奖励和稀疏奖励问题
2.1 主线奖励
-
主线事件:强化学习的任务目标通常可以分为两类
- 定性目标的达成,比如二维平面导航任务中agent到达终点、下棋获胜、游戏通关等
- 定量目标的极值化,比如最大化投资收益、最小化电量消耗等
这是所有强化学习任务的 根本目标,可以把上述定性目标的达成和定量目标的改善成为 主线事件
-
主线奖励:根据主线事件可以相应地定义 主线奖励,这通常是简单的
- 对于定性任务,无论任务多么复杂,判断任务是否完成通常是比较简单的,可以在定性目标达成时给予 agent 一个正向奖励
- 对于定量任务,我们通常可以观测到目标本身或它的某种度量,可以将其本身或经过某种形式的变换后作为回报
主线回报相对于任务目标而言往往是无偏的,因此只包含主线回报的奖励函数往往是最简单也最理想(从指向性来看)的形式
2.2 稀疏奖励问题
- 主线奖励很稀疏,如果仅使用主线奖励,往往导致稀疏奖励问题
- 看一个简单的例子,下面是一个 grid world 平面导航任务,agent要从左上角移动到右下角,动作集为上下左右运动,到达终点时可以获取25的奖励,其他情况下没有奖励。这是一个确定性环境,且仅有终止状态有奖励。下图右侧是使用 value iteration 直接求出的状态价值分布;左侧是使用 model-free 方法 Q-learning 学习的效果,可以看到价值函数的学习过程以及 agent 策略逐步确定的过程


- 由于仅有一个定性任务完成奖励,在早期通过随机探索获取有效转移的概率很低;由于大部分状态下反馈信号的缺失,agent 难以发现应该向右下方向移动,也就无从通过主动增加右下移动动作来触发更多的主线事件
- 任务简单,状态动作空间较小时:如上例所示,agent 容易通过
ε
\varepsilon
ε-greedy 随机探索的方法探索到主线事件,从而保证有效转移至少占据一定的比例,使得 RL 算法最终能够收敛
- 随着任务复杂度提升、状态动作空间增大,通过随机方式探索到主线事件的概率变得很小,稀缺的反馈信号无法为 agent 指明探索方向,难以形成局部知识,而盲目探索又导致有效转移无法出现或数量极少,二者相互作用导致样本效率极低,RL算法难以收敛
- 反馈信号稀疏,训练早期难以形成局部知识,难以给出局部指导,导致盲目探索;训练晚期只能给出片面指导,导致片面利用,样本效率低下甚至无法收敛,学习困难,这就是
稀疏奖励问题 - 稀疏奖励会影响强化学习样本效率,关于样本效率的讨论,请参考:
强化学习拾遗 —— 强化学习的样本效率
3. 完善奖励函数设置
3.1 三种辅助奖励函数
-
要从奖励函数设置角度克服稀疏奖励问题,直观的想法就是在主线回报的基础上增加其他的奖励项或惩罚项,使得奖励函数变得稠密,给与Agent足够强的指导,从而加快 DRL 算法收敛速度并提升性能。这些主线奖励以外的奖励称为 辅助奖励,通常有三类
子目标奖励:这是辅助奖励的主要形式,其设计方法是把任务目标进一步分解为子目标,然后按照各自在促进主线事件实现过程中的贡献大小和作用方向分别给予适当的奖励或惩罚,这个操作也称为 贡献度分配。子目标总体上分为 “鼓励型” 和 “回避型” 两类。理想情况下,贡献度分配是由RL算法在主线目标引导下自行完成的。塑形奖励:塑形奖励的基本思想就是向没有定义奖励信号的状态添加奖励信号,早期,添加奖励的具体方式缺少理论指导,往往会导致偏离任务初衷的行为。吴恩达在20世纪末提出了 Potential-Based Reward Shaping 技术,给出了一种在维持最优策略不变前提下加速算法收敛的奖励塑形方法,现在的 “塑形奖励” 通常指这种方法及基于其思想的变体。Potential-Based Reward Shaping 方法给每个状态设定一个势能函数
ϕ
(
s
)
\phi(s)
ϕ(s),代表着当前状态与目标之间的距离,这样转移
(
s
,
a
,
a
′
)
(s,a,a')
(s,a,a′) 就有了额外的塑形奖励
γ
ϕ
(
s
′
)
−
ϕ
(
s
)
\gamma \phi(s')-\phi(s)
γϕ(s′)−ϕ(s),即
r
ˉ
(
s
,
a
,
a
′
)
=
r
(
s
,
a
,
a
′
)
+
γ
ϕ
(
s
′
)
−
ϕ
(
s
)
\bar{r}(s,a,a') = r(s,a,a') + \gamma \phi(s')-\phi(s)
rˉ(s,a,a′)=r(s,a,a′)+γϕ(s′)−ϕ(s)
这使得奖励函数变得稠密,从而对 agent 的探索起到了高效的引导作用。吴恩达的工作还证明了,理论上最优的势能函数是最优状态价值估计函数
v
∗
v_*
v∗,直接获取
v
∗
v_*
v∗ 是不现实的(如果能拿到,贪心就得到
π
∗
\pi_*
π∗ 了),但是只要充分利用任务的 domain-knowledge,即使
ϕ
(
s
)
\phi(s)
ϕ(s) 与
v
∗
(
s
)
v_*(s)
v∗(s) 差距很大,也能显著加快算法收敛。实践中也常常使用基于这个思想的一种不基于势能的变体,每个状态直接给一个奖励,越接近目标越大,相当于将势能函数直接作为塑形回报,为了避免正的额外奖励导致 reward hacking 问题,通常改为施加负反馈塑形回报,即越接近终点给予的惩罚越小,迫使agent尽快移动到终点位置。这种方式比较简单,但是不能保证最优策略不变内驱奖励:这种奖励意在模仿自然生物的好奇心,它不针对任何具体的目标,而是无差别地鼓励 agent 探索未知状态,借此增加有效转移发生概率,这种方法主要用于在复杂任务中加强探索。实践中,若前两种辅助奖励效果已经够好,则不需要内驱奖励
-
用一张图来表示这些奖励函数,上侧图代表对 “鼓励型” 子目标施加正向奖励,对 “回避型” 子目标施加惩罚;下侧图代表对两类子目标都施加负奖励,通过减少惩罚的形式激励 “鼓励型” 子目标,这种方法可以避免 Reward Hacking,但是可能导致 “懦弱” 行为


-
所有这些辅助奖励的设计都需要对任务逻辑有深入了解,且需要 domain-knowledge。越复杂任务,动作空间、状态空间越大,就越难通过奖励函数向 agent 清楚传达我们的目标,设计奖励函数的成本就越高。如果去看一些复杂任务的奖励函数,往往会感到一头雾水,比如下面这个后空翻任务

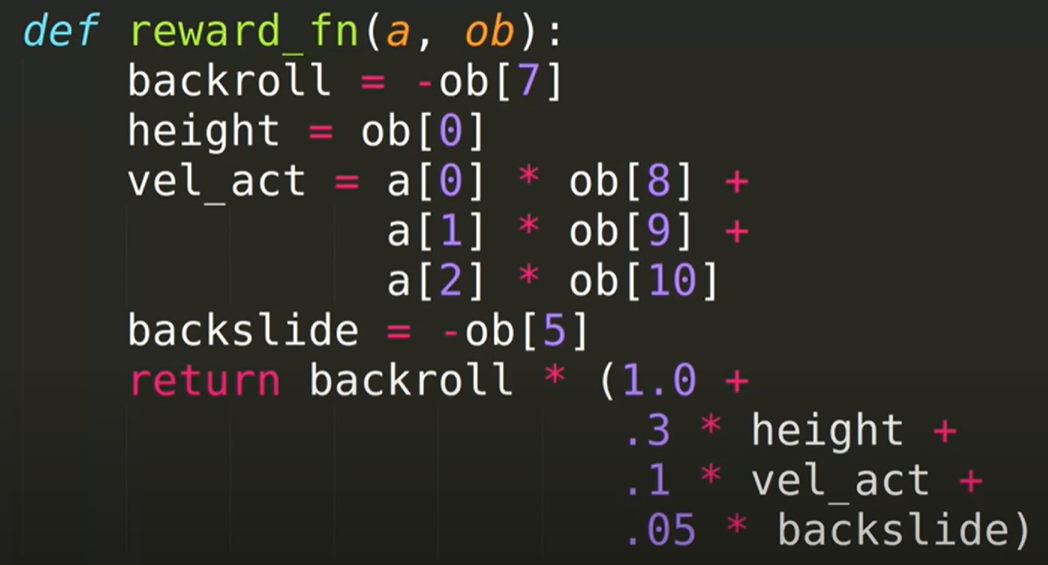
这个任务来自论文 《Deep Reinforcement Learning from Human Preferences》,为了用RL方法实现它,研究人员花费5个小时设计了右侧的奖励函数。可见,其中 backroll = -ob[7] 应该是一个定性型的主线奖励,其他都是各种辅助奖励
3.2 奖励函数设计的困境
- 主线奖励针对性地地鼓励主线事件发生,只有在定性目标达成或定量目标得到优化时才会得到奖励,因此优化收益就等价于促进定性目标达成、定量目标极值化,这通常是无偏的,但是奖励比较稀疏
- 随着辅助奖励的加入,虽然 agent 得到了更多指导,但也导致最大化收益时连带实现的目标发生偏移,使得 agent 出现异常行为。这些异常行为主要可以分三类
鲁莽:如果奖励函数中没有对某个不希望出现的行为设置惩罚,或者惩罚力度过小,会导致agent无法学会规避此事件,或是权衡利弊后选择承担此事件的惩罚以换取更大的收益。比如二维平面导航任务中,如果没有对碰撞和电量过低设置惩罚,可能导致agent为了避免绕路试图 “穿过” 墙壁,或无视自身电量不足的现状只顾驶向终点,直至半路停车抛锚贪婪:贪婪行为主要分为 Wireheading 和 Reward Hacking 两类。Wireheading 主要指由于动作空间设置不合理,导致 agent 学会通过执行特殊动作改变其对环境信息进行感知与加工的过程,以获取超额回报、屏蔽惩罚的问题。比如玩俄罗斯方块的 agent,可能学会在游戏结束前按下暂停键以避免扣分,或者通过使用作弊码直接加分,为了避免这类问题,应当设计合理的动作空间。Reward Hacking 主要指由于由于奖励函数片面奖励某个子目标而又缺乏制衡时,agent 可能反复攫取局部收益而忽略初始目标的问题,比如二维平面导航任务,要求agent从一个房间的起点走到另一个房间的终点,为了鼓励穿过门,在门位置施加奖励,这可能导致 agent 反复来回穿过门以攫取局部奖励。为了避免这类问题,应该通过减少惩罚的形式鼓励agent实现子目标,除了主线奖励和内驱奖励外,尽量避免对子目标施加正向奖励,除非某个鼓励类子目标的达成是一次性的或数量可控懦弱:懦弱行为常见于辅助惩罚项很多且绝对值相对与主线奖励过大的情形。agent在训练初期收到大量的负反馈阻碍了其进一步探索到主线事件并获取奖励,从而陷入局部最优,可以看作一种特殊的 reward hachking 问题。比如在 Atria 游戏 PitFall 中,Agent为了躲避密集的惩罚信号而选择停在起始位置不动
- 总的来看,设计奖励函数的过程,就是在主线奖励的基础上加入辅助奖励的过程,这一方面可以加强对agent的指导,促进算法收敛;另一方面也会引入目标偏差,如果想减少偏差,就要面对高昂的成本

3.3 奖励设定实验
- 下面在直线地图进行一系列实验,起点在最左侧,终点在最右侧,使用 Q-learning +
ε
\varepsilon
ε-greedy 探索方法。如果不加说明,动作空间都是左移或右移,为了突出效果,
ε
\varepsilon
ε 设为 0 或极小。以下所有实验设定下,最优策略
π
∗
\pi_*
π∗ 都是一直右移到终点
- 3.3.2 节的名字都是我自己起的,不是术语
3.3.1 常见问题
- Reward Hacking 演示 1:除了终止状态50的奖励外,试图在中间状态设置一个正奖励来鼓励右移动,但这导致中间处出现一个局部高价值区域,吸引 agent 在此来回运动,忽略目标。即使调高
ε
\varepsilon
ε,也无法避免此问题

- Reward Hacking 演示 2:除了终止状态50的奖励外,为了鼓励向右移动,给其他状态都设置辅助奖励,奖励是从 -9 到 +9 的等差数列。这里其实糅合了两种思想,左侧负奖励区域是使用减小惩罚的方式鼓励 “靠近右侧” 这一子目标;右侧正奖励区域是基于势能的奖励塑造的变形。可见左边基于减小惩罚思想的辅助奖励工作良好,但右边由于正奖励导致了 reward hacking。如果调高
ε
\varepsilon
ε,让 agent 有机会更新右侧状态价值,正奖励区鼓励移动的目的才能达到

- cowardice (懦弱) 演示:上面的实验说明了减小惩罚思想的有效性,但在环境中施加过多的负奖励将导致懦弱行为。下面的环境中,agent 任意一步移动会得到 -1 的奖励,而终点处有 2000 奖励。动作空间除了上下左右移动外,还允许 agent 原地不动(不动奖励为0)。虽然按照状态真实价值贪心就能直达终点,但这种情况下很难建立好的价值估计,agent发现不管怎么走都是扣分,于是选择原地不动。这个环境比较难,即使把
ε
\varepsilon
ε 调得很高,也几乎不可能让 agent 试探到终点并完善价值估计

3.3.2 对比几种可行的鼓励方式
- 四种鼓励方式
- ind:设定和 2.2 节类似,agent 左右移动没有奖励,只有在终止状态会得到 +100 的主线奖励(奖励的绝对大小不重要,相对大小才重要,这里设+100和+1没有本质区别)。这种情况下,agent 早期会盲目探索,试探到奖励后,随着价值逐渐传播,agent 的动作会越来越有方向性

- zero:移动一步会获得 -1 的奖励,终止位置奖励为 0(这里禁止 agent 原地不用以避免 cowardice 问题)。这种设定下,agent 左右运动会导致价值估计下降,这就让未试探区初始化的 0 价值变得相对高,从而鼓励 agent 右移

- ind+zero:前面两种方法的结合,移动一步会获得 -1 的奖励,终点处奖励为 +100

- neg+ind:ind 方法和 3.3.1 节第二个试验中减小惩罚思想相结合。终点前的奖励从 -19 等差增大到 -1,终点处奖励为 +100

- 四种奖励设定方法下,算法都能收敛到最短路径长度 19,收敛过程对比如下

总的来说还是比较符合预期的
4. 站在更高的角度上
-
在强化学习的标准设定中,我们通过奖励函数给予 agent 指导,但是 从奖励函数到任务目标的关系是间接的、抽象的,对奖励函数稍加改变,最后优化得到的策略就很可能天差地别。事实上,我们很难通过奖励函数准确地向 agent 传达我们想实现的目标。比如对于定性目标任务,在终止状态上,我们可以有把握地说,没错,我们要鼓励到达这里,给与高奖励,但是在其他状态下,我们对于给予不同奖励的后果其实很难有一个良好的估计,但如果想在这些状态也对 agent 有强力的指导,就必须要设置奖励,这样就很容易引入偏差,要想减少偏差,就要上各种 trick 迭代实验,导致成本飙升
-
还原到本质来看,奖励函数的存在的意义就是向 agent 指明任务目标,根据前文分析,当任务比较复杂时,奖励函数实现这个任务的能力其实是有限的,这不是说不存在一个好的奖励函数,而是奖励函数的设计空间太大了,好的奖励函数太难找了,这已经是一个学术问题,称为 “最优奖励问题(Optimal Reward Problem)”
-
一个自然的想法是,我们可以使用其他方式向 agent 传递目标,这样就引出了各种方法
- 设置好的初始价值(常用这种方式向 agent 传递关于环境的先验知识;结合 IL 和 RL 时,也常用此方法对 RL 进行初始化)
- 使用专家示范数据传递目标:模仿学习
- 使用人类偏好传递目标:可参考论文《Deep Reinforcement Learning from Human Preferences》【全文翻译】【理解分析】
- …
再看回来,奖励函数的数学形式其实还是很好的,描述能力强,而且可以很方便地形式化问题,因此大部分这些方法最后还是转变为找一个好的奖励函数
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)